问题反馈
如有问题可通过微信公众号“假装正经的程序员”反馈
前言
由于kettle设计的特殊性,kettle的处理流程均是通过插件组装的形式来进行工作,因此kettle插件开发是目前kettle二次开发的核心内容。
插件类型
- 转换步骤插件:在kettle转换中使用的步骤,用来处理数据行;
- 作业项插件:在kettle作业中使用的作业项,用来实现某个任务;
- 分区方法插件:利用输入字段的值指定自己的区分规则;
- 数据库类型插件:用来扩展不同的数据库类型;
- 资源库类型插件:可以把kettle元数据保存为自定义类型或格式;
插件id
这是一个字符串数组,用来唯一标识一个插件。因为旧的插件可以被新的插件代替,一个插件可以有多个ID。再大多数情况下,插件只使用一个单一的字符串,如TableInput是“表输入”步骤的ID,MYSQL是MYSQL数据类型的ID。
内部插件加载
当kettle环境初始化以后,插件注册系统首先加载所有的内部对象,kettle读取下面的配置文件来加载内部对象,这些配置文件位于Kettle的.jar文件中。
- kettle-steps.xml:内部转换步骤
- kettle-job-entries.xml:内部作业项
- kettle-partition-plugins.xml:内部分区类型
- kettle-database-types.xml:内部数据库类型
- kettle-repositories.xml:内部资源库类型
外部插件加载
插件注册系统加载了所有的内部对象后,就要搜索可用的外部插件。通过浏览plugins/目录的各个子目录下的.jar文件来完成。它搜索特定的Kettle annotations来判断一个类是否是插件。
因为在内部对象加载后才加载插件,所以插件会替代相同ID的已加载的内部对象。例如,你创建了插件,插件的ID是TableInput,就可以替换Kettle标准的“表输入”步骤。这个功能可以让你用插件替换Kettle内置的步骤。可以通过子类继承的方式,直接扩展已有步骤的某些功能。
转换步骤插件
转换步骤插件包括了四个Java类,它们分别实现四个接口
- StepMetaInterface:对外提供步骤的元数据并处理串行化;
- StepInterface:根据上面接口提供的元数据来实现步骤的具体功能;
- StepDataInterface:用来存储步骤的临时数据、文件句柄等;
- StepDialogInterface:Spoon里的图形界面,用来编辑步骤的元数据;
上述接口均匀对于的Base类实现了大部分功能,如BaseStepMeta、BaseStep、BaseStepData、BaseStepDialog。
StepMetaInterface
负责步骤里所有和元数据相关的任务。
基础方法
和元数据相关的工作包括:
元数据和XML(或资源库)之间的序列化和反序列化
getXML()和loadXML()
saveRep()和readRep()
描述输出字段
getFields()
检查元数据是否正确
check()
获取步骤相应的SQL语句,使步骤可以正确运行
getSQLStatements()
给元数据设置默认值
setDefault()
完成对数据库的影响分析
analyseImpact()
描述各类输入和输出流
getStepIOMeta()
searchInfoAndTargetSteps()
handleStreamSelection()
getOptionalStreams()
resetStepIoMeta()
导出元数据资源
exportResources()
getResourceDependencies()
描述使用的库
getUsedLibraries()
描述使用的数据库连接
getUsedDatabaseConnections()
描述这个步骤需要的字段(通常是一个数据库表)
getRequiredFields()
描述步骤是否具有某些功能
supportsErrorHandling()
excludeFromRowLayoutVerification()
excludeFromCopyDistributeVerification()高级方法
这个接口还定义了几个方法来说明这四个接口如何结合到一起
String getDialogClassName():用来描述实现了StepDialogInterface接口的对话框类的名字。如果这个方法返回了null,调用类会根据实现了StepMetaInterface接口的类的类名和包名来自动生成对话框类的名字。
StepInterface getStep():创建一个实现了StepDataInterface接口的类。
StepDataInterface getStepData():创建一个实现了StepDataInterface接口的类。注册方式
kettle-steps.xml
在kettle的原生插件中通过kettle-engine模块resources下目录下的kettle-steps.xml文件注册
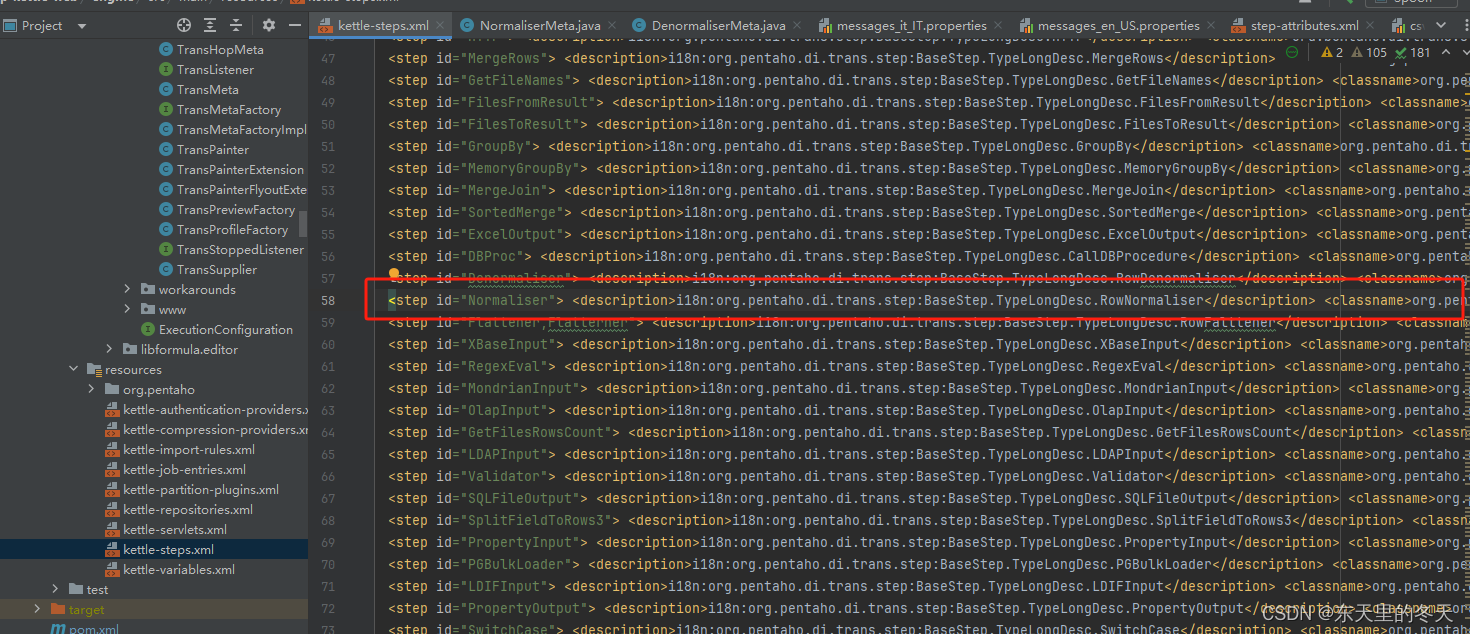
注册内容如下
<step id="Normaliser"> <description>i18n:org.pentaho.di.trans.step:BaseStep.TypeLongDesc.RowNormaliser</description> <classname>org.pentaho.di.trans.steps.normaliser.NormaliserMeta</classname> <category>i18n:org.pentaho.di.trans.step:BaseStep.Category.Transform</category> <tooltip>i18n:org.pentaho.di.trans.step:BaseStep.TypeTooltipDesc.RowNormaliser</tooltip> <iconfile>ui/images/NRM.svg</iconfile> <documentation_url>Products/Row_Normaliser</documentation_url> <cases_url/> <forum_url/> </step>
@Step
除了通过kettle-steps.xml的方式注册插件外,kettle还提供了更灵活的方式来注册插件,即通过@Step注解的方式。
kettle-steps.xml适合基于原生kettle代码改造的情况下进行内置插件处理,而@Step则更适合外置插件的处理。
@Step(id = "RowDenormaliser",name = "RowDenormaliser.name",
categoryDescription = "i18n:org.pentaho.di.trans.step:BaseStep.Category.Transform",
image= "HelloWorld.png",
i18nPackageName="com.xxx.plugin.trans.steps.rowdenomaliser")
public class RowDenormaliserStepMeta extends BaseStepMeta implements StepMetaInterface {
private static Class<?> PKG = RowDenormaliserStep.class; //for i18n
//TODO
}这段代码中的@Step注解是用来通知Kettle的插件系统的:这个类是一个步骤类型的插件。在该注解中可以指定插件的ID、图标、国际化的包、本地化的名称、类别、描述。其中后三项是资源文件里的Key,需要在资源文件里设置真正的值。i18nPackageName指定了资源文件的包名,即我们的资源文件在xxx.plugin.trans.steps.rowdenomaliser包下面。
StepDataInterface
用来维护步骤的执行状态,以及存储临时对象。例如,把输入行的元数据、数据库连接、输入输出流等存储在这个对象里。
StepDialogInterface
用来提供一个用户界面,用户通过这个界面输入元数据(转换参数)。用户界面就是一个对话框。这个接口里面包含了类型open()和setRepository()等几个简单的方法。
StepInterface
这个类读取上个步骤传来的数据行,利用StepMetaInterface对象定义的元数据,逐行转换和处理上个步骤传来的数据。Kettle引擎直接使用这个接口里的很多方法执行转换过程,但大部分方法都已经由BaseStep类实现了。
常见需要重载方法
通常开发人员只需要重载其中的几个方法。
- init():步骤初始化方法,用来初始化一个步骤。初始化的结果是一个true或者false的Boolean值。如果你的步骤没有任何初始化的工作,可以不用重载这个方法。
- dispose():如果有需要释放的资源,可以在dispose()方法里释放,例如可以关闭数据库连接、释放文件、清除缓存等。在转换的最后Kettle引擎会调用这个方法。如果没有需要释放或清除的资源,可以不用重载这个方法。
- processRow():这个方法,是步骤实际工作的地方。只要这个方法返回true,转换引擎就会重复调用这个方法。
常见功能
从上个步骤获取一行数据
- getRows():该方法从上一个步骤获取一行数据,如果没有更多要获取的数据行,这个方法就会返回null。如果前面的步骤不能及时提供数据,这个方法就会阻塞,直到有可用的数据行。这样这个步骤的速度就会降低,也会影响到转换里的其他步骤的速度。从性能上考虑,该方法不提供数据行的元数据,只提供上个步骤的输出的数据。可以使用getInputRowMeta()方法获取元数据,元数据只获取一次即可,所以在first代码块里获取元数据。
告知其他步骤无输出数据
- setOutputDone():用来通知其他的步骤,本步骤已经没有输出数据行。下个步骤如果再调用getRow()方法就会返回null,转换也不再调用processRow()方法。
数据传递到下个步骤
- putRow():如果要把数据传递到下一个步骤,要使用该方法。除了输出数据,还要输出RowMetaInterface元数据。构造输出行的元数据结构只能构造一次,因为所有输出数据行的结构都是一样的,产生了输出行以后,元数据结构就不能再变化。所以输出行的元数据结构也在first代码块里构造。
String value="demonstrate putRow"
Object[] outputRowData = RowDataUtil.allocateRowData(row,data.outputRowMeta.size(),value);
putRow(data.outputRowMeta, outputRowData);从指定步骤读取数据行
- getRowFrom():如果你想从前面的某个特定的步骤读取数据行,则可以使用该方法
RowSet inputRowSet = findInputRowSet("自定义行转列");
Object[] rowFrom = getRowFrom(inputRowSet);
logBasic("-------stepName:{0},rowFrom:{1}","自定义行转列",JacksonUtil.object2Json(rowFrom));
从上面这个方法能够看出,整个转换都是以一行一行数据来的,所以在单个步骤内获取的数据与之前步骤的数据是存在关联性的。
特定步骤中写入数据行
- putRowTo():如果你想把数据写入到某个特定的步骤,则可以使用该方法
RowSet inputRowSet = findOutputRowSet("自定义行转列");
putRowTo(getInputRowMeta(),r,inputRowSet);从本方法和上面的方法可以看出,输入和输出的RowSet对象只需要各获得一次即可,这样才更有效率。
错误处理步骤写入数据行
- putError():如果你想让你的步骤支持错误处理,而且元数据类返回的supportErrorHandling()方法返回了true,就可用把数据输出到错误处理步骤里。
try{
……
} catch (KettleException e) {
if (getStepMeta().isDoingErrorHandling()) {
errorMessage = e.toString();
putError(getInputRowMeta(), r, 1, errorMessage, errorFieldName, "ISU001");
}else{
logError(BaseMessages.getString(PKG, "InsertUpdate.Log.ErrorInStep"), e);
setErrors(1);
stopAll();
setOutputDone(); // signal end to receiver(s)
return false;
}
}从这个例子可以看到,这段代码把错误的行数、错误字段名、消息错误编码都传递给错误步骤,错误处理的其他工作都自动完成了。
识别一个步骤拷贝
因为一个步骤可以有多份拷贝同时执行,有时需要识别出正在使用的是哪个步骤拷贝,可以用下面几个方法
- getCopy():获取拷贝号。拷贝号可以唯一标识出步骤的一个拷贝,拷贝号的取值范围是0-N,N=getStepMeta().getCopies()-1。
- getUniqueStepNrAcrossSlaves():获得在集群模式下运行的步骤拷贝号。
- getUniqueStepCountAcrossSlaves():获取在集群模式下运行的步骤拷贝总数。
通过这些方法可以把一个步骤的工作分配给多份拷贝去完成。例如“CSV文件输入”和“固定宽度文件输入”步骤里都有并行读取文件的选项,这样可以把读取文件的工作放在多个拷贝里或集群里来完成。
结果反馈
在调用getRow()和putRow()方法时,引擎会自动计算两类度量值,读行数和写行数。这两类度量值可以在界面或日志中记录下来,以监控程序运行的状态。下面几个方法用来操作这两类度量值。
- incrementLinesRead():增加从前面步骤读取到的行数。
- incrementLinesWritten():增加写入到后面步骤的行数。
- incrementLinesInput():增加从文件、数据库、网络等资源读取到的行数。
- incrementLinesOutput():增加写入到文件、数据库、网络等资源的行数。
- incrementLinesUpdated():增加更新的行数。
- incrementLinesSkipped():增加跳过的数据行的行数。
- incrementLinesRejected():增加拒绝的数据行的行数。
这些度量值用来说明步骤执行的情况。可以在Spoon的转换度量面板里看到,也可以存到日志数据库表里