一、前言
检索增强生成 (RAG) 作为人工智能 (AI) 领域的一项重要技术,近年来得到了飞速发展。它将基于检索模型和基于生成的模型相结合,利用海量外部数据,生成更具信息量、更准确、更具语境相关性的回复。检索策略是 RAG 系统的关键组成部分,它直接影响着系统的性能和效率。
在各种检索策略中,查询重写凭借其能够优化和改进检索过程,确保 AI 系统获取最相关信息的优势,成为了研究的热点。本文将深入探讨查询重写的机制、优势、挑战以及未来发展趋势,以期为相关研究和应用提供参考。
在 RAG 应用中,文档检索是保证高质量答案的关键。我们已经深入讨论过文档检索在 RAG 系统中的重要作用。然而,除了文档检索,优化用户查询同样重要。用户查询可能存在表达不清、语义模糊等问题,导致检索结果不理想。为了解决这个问题,查询重写技术应运而生。它通过对用户查询进行改造,使其更加清晰、具体,从而提高检索准确性。
例如,用户输入“《红楼梦》作者是谁?”,直接检索可能会得到大量无关信息,如“红楼梦的剧情简介”、“红楼梦的人物分析”等。而经过查询重写后,可以将查询改写为“《红楼梦》的作者是谁?”,这样就能更准确地找到答案。
因此,将用户查询的语义空间与文档的语义空间保持一致至关重要。查询重写技术可以有效解决这个问题。它在 RAG 中的作用如下图所示:
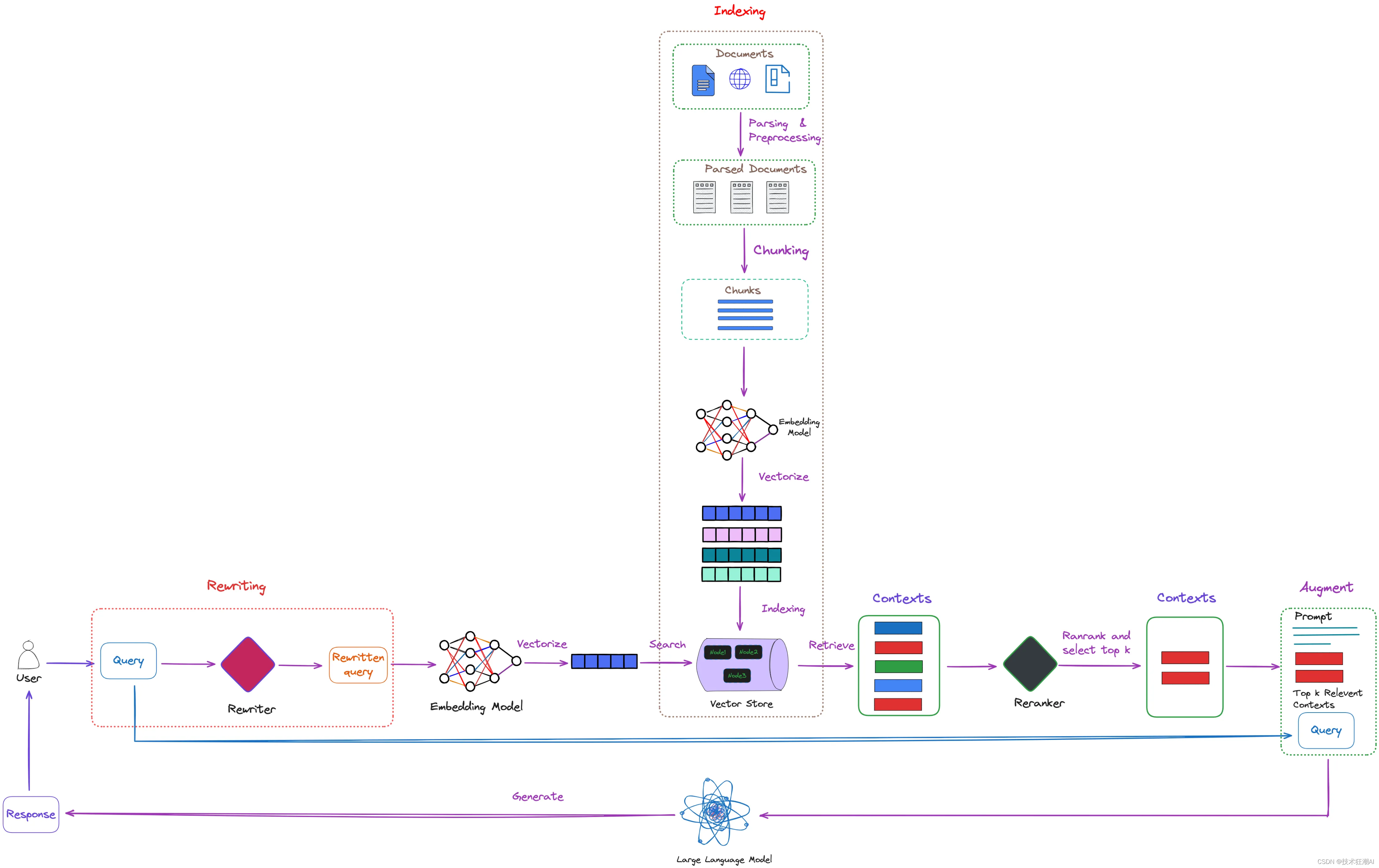
从查询检索在图中的位置上看,查询重写属于检索前的预处理步骤。图中展示了查询重写技术在 RAG 系统中的应用位置,下面我们会介绍一些能够进一步优化该过程的算法。
查询重写是使查询与文档语义一致的关键技术。例如:
- 假设文档嵌入 (HyDE) :通过创建虚拟文档来使查询和文档的语义空间保持一致。
- 重写-检索-阅读:提出了一种全新的框架,它颠覆了传统的检索-阅读顺序,将重点放在查询重写上。
- 回溯提示 (Step-Back Prompting): 允许大语言模型 (LLM) 基于高层概念进行抽象推理和检索。
- Query2Doc: 利用来自大语言模型 (LLM) 的少量提示生成伪文档,并将这些伪文档与原始查询合并,构建新的查询。
- ITER-RETGEN:提出了一种迭代式检索生成方法。它将前一次生成的结果与之前的查询相结合,然后检索相关文档并生成新的结果。这个过程会重复多次,直到最终得到理想的结果。
本文将介绍几种常用的查询重写策略,并探讨它们在实际项目中的应用场景。相信通过对查询重写的深入研究,能够进一步提升 RAG 系统的性能,为用户提供更加精准、高效的答案。
二、子问题查询
子问题策略,也称为子查询,是一种用于生成子问题的技术。其核心思想是在问答过程中生成并提出与主问题相关的子问题,以便更好地理解和回答主问题。这些子问题通常更具体,可以帮助系统更深入地理解主问题,从而提高检索准确性和提供正确的答案。

- 首先,子问题策略使用大语言模型 (LLM) 从用户查询中生成多个子问题。
- 然后,每个子问题都经过 RAG 过程以获取其自身的答案(检索生成)。
- 最后,将所有子问题的答案合并以获得最终答案。
2.1、代码示例
子问题查询已在 LlamaIndex 中实现。在检验子问题查询的有效性之前,让我们看看常规 RAG 检索在复杂问题上的表现:
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
question = "Are Harley Quinn and Thanos righteous characters in the Avengers?"
documents = SimpleDirectoryReader("./data").load_data()
node_parser = VectorStoreIndex.from_documents(documents)
query_engine = node_parser.as_query_engine()
response = query_engine.query(question)
print(f"base query result: {response}")
# Output
base query result: No, Harley Quinn and Thanos are not depicted as righteous characters in the Avengers series.
以上代码演示了使用 LlamaIndex 的常规 RAG 检索过程。我们使用了维基百科上的复仇者联盟电影情节摘要进行测试。在这里,我们问了一个涉及 2 个角色的复合问题:一个是 DC 漫画的“小丑女”,另一个是漫威电影的“灭霸”,关于他们是否在复仇者联盟中是正义的角色。尽管查询结果是正确的,但它没有说明其中一个角色不是来自漫威电影。
现在,让我们看看子问题查询的有效性:
from llama_index.core.tools import QueryEngineTool, ToolMetadata
from llama_index.core.query_engine import SubQuestionQueryEngine
query_engine_tools = [
QueryEngineTool(
query_engine=query_engine,
metadata=ToolMetadata(
name="Avengers",
description="Marvel movie The Avengers",
),
),
]
query_engine = SubQuestionQueryEngine.from_defaults(
query_engine_tools=query_engine_tools
)
response = query_engine.query(question)
print(f"子问题查询结果: {response}")
# Output
Generated 2 sub questions.
[Avengers] Q: What role does Harley Quinn play in the Avengers movie?
[Avengers] Q: What role does Thanos play in the Avengers movie?
[Avengers] A: Harley Quinn is not mentioned in the provided background of the Avengers movie.
[Avengers] A: Thanos is the primary antagonist in the Avengers movie. He is a powerful warlord who seeks to reshape the universe according to his vision. Thanos is depicted as a formidable and ruthless enemy, posing a significant threat to the Avengers and the entire universe.
子问题查询结果: Harley Quinn is not mentioned in the provided background of the Avengers movie. Thanos is the primary antagonist in the Avengers movie, depicted as a powerful and ruthless enemy.
- 首先,我们构建查询引擎工具,包括常规查询引擎,并设置它们的元数据。
- 然后,我们使用 SubQuestionQueryEngine 类构建子问题查询引擎,传入查询引擎工具。
- 查询结果显示了生成的子问题及其答案,最终答案基于所有子问题的答案。
从代码中,我们可以看到,对于复杂问题,子问题查询比常规查询能产生更准确的结果。
在提供的示例中,生成的子问题和答案作为调试信息的一部分显示。我们也可以在检索过程中检索这些数据。
from llama_index.core.callbacks import (
CallbackManager,
LlamaDebugHandler,
CBEventType,
EventPayload,
)
from llama_index.core import Settings
llama_debug = LlamaDebugHandler(print_trace_on_end=True)
callback_manager = CallbackManager([llama_debug])
Settings.callback_manager = callback_manager
# Subquestion querying code
...
for i, (start_event, end_event) in enumerate(
llama_debug.get_event_pairs(CBEventType.SUB_QUESTION)
):
qa_pair = end_event.payload[EventPayload.SUB_QUESTION]
print("Sub Question " + str(i) + ": " + qa_pair.sub_q.sub_question.strip())
print("Answer: " + qa_pair.answer.strip())
- 我们可以添加一个回调管理器来记录子问题查询的调试信息。
- 查询之后,我们通过回调管理器检索调试信息,并获取子问题和答案。
2.2、提示词
LlamaIndex 使用独立的 Python 包 llama-index-question-gen-openai 来生成子问题。它默认使用 OpenAI 模型进行子问题生成。提示模板可以在 LlamaIndex 官方仓库中找到。我们可以使用以下两种方法打印 LlamaIndex 中的提示:
第一种方法是使用 get_prompts() 方法。
prompts = query_engine.get_prompts()
for key in prompts.keys():
sub_question_prompt = prompts[key]
template = sub_question_prompt.get_template()
print(f'prompt: {template}')
- 首先,我们使用 get_prompts() 方法来检索查询引擎的提示对象,该对象对于大多数 LlamaIndex 对象都可用。
- 提示对象是一个 JSON 对象,其中每个键代表一个提示模板。
- 我们遍历提示对象的每个键,检索与每个键对应的提示模板,并将其打印出来。
- 子问题查询将包含 2 个提示模板:一个用于子问题生成,另一个用于常规 RAG。
第二种方法是使用 set_global_handler 进行全局设置:
from llama_index.core import set_global_handler
set_global_handler("simple")
在文件开头添加以上代码将在执行过程中打印出提示,显示包含特定变量值的完整提示。
三、HyDE 查询转换
论文**「Precise Zero-Shot Dense Retrieval without Relevance Labels」** 提出了一种名为假设文档嵌入 (HyDE) 的方法。HyDE (Hypothetical Document Embeddings) 的本质是使用大语言模型 (LLM) 为用户查询生成假设文档。这些文档是根据 LLM 本身的知识生成的,可能包含错误或不准确之处。但是,它们与 RAG 知识库中的文档相关联。然后,通过使用这些假设文档来检索具有相似向量的真实文档,从而提高检索的准确性。你可以在此处参考有关 HyDE 的论文。下图展示了 HyDE 的主要流程。
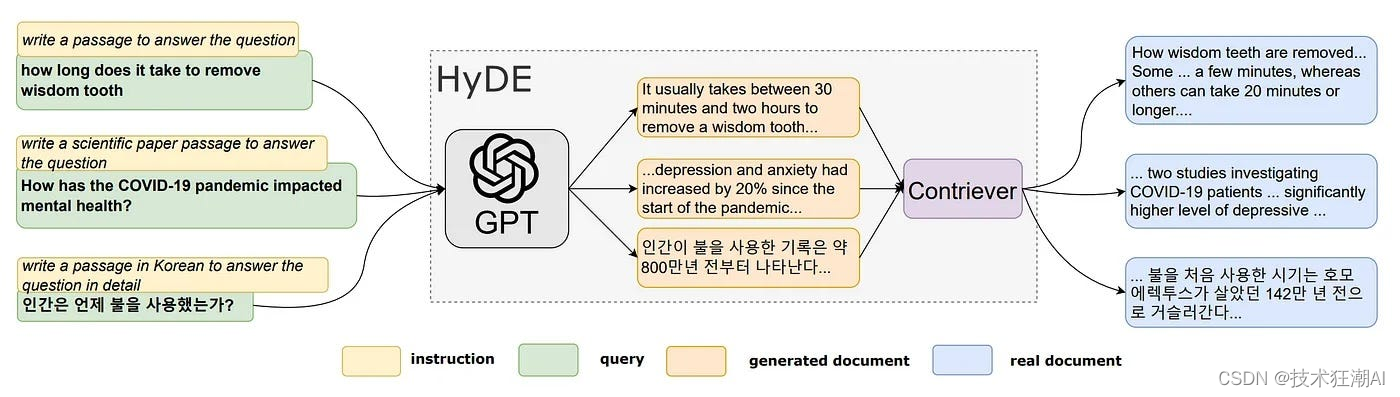
HyDE 的工作流程主要分为四个步骤:
- 生成假设文档: 使用大语言模型 (LLM) 根据用户查询生成若干个假设文档。这些假设文档可能并非完全真实,甚至可能包含错误,但它们应该与相关文档具有相似性。这一步骤旨在通过大语言模型来理解用户的查询意图。
- 文档编码: 将生成的假设文档输入到编码器中,将其转换为一个密集向量 f(dk)。编码器的作用类似于一个过滤器,能够过滤掉假设文档中的噪声。这里,dk 表示第 k 个生成的假设文档,f 代表编码器操作。
- 计算向量: 根据公式,对 k 个编码后的向量进行平均,得到一个新的向量 v。

此外,我们还可以将原始查询 q 视为一个潜在的假设文档。
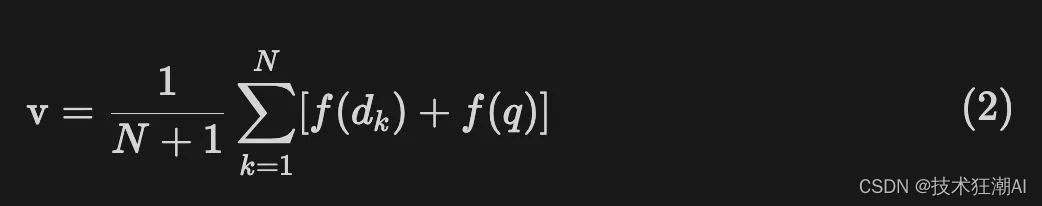
- 文档检索: 使用向量 v 从文档库中检索答案。由于向量 v 包含了用户查询和所需答案模式的信息,因此能够提高检索的召回率。
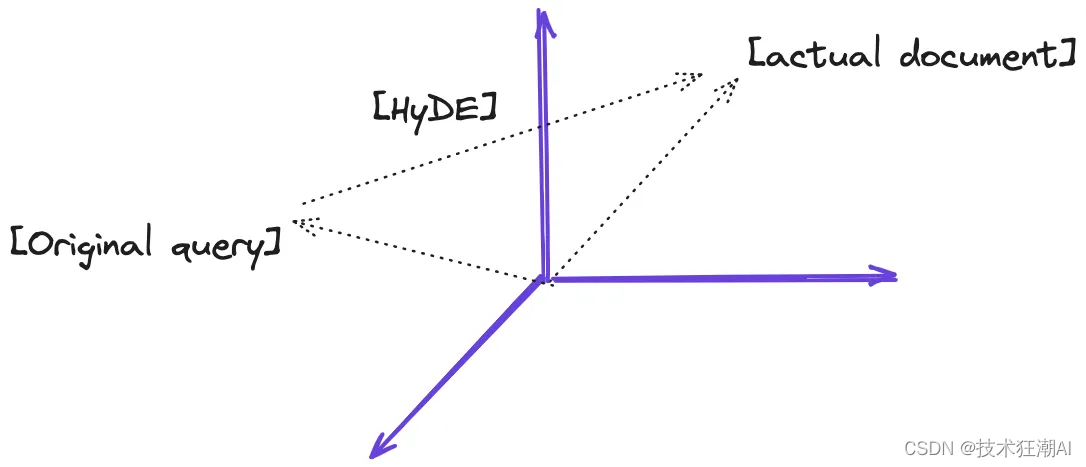
下图展示了我对 HyDE 的理解。HyDE 的目标是生成假设文档,使得最终的查询向量 v 与向量空间中的实际文档尽可能接近。
3.1、代码示例
HyDE 查询重写已在 LlamaIndex 中实现。让我们首先看看 LlamaIndex 如何生成假设文档:
from llama_index.core.indices.query.query_transform import HyDEQueryTransform
question = "What mysterious item did Loki use in an attempt to conquer Earth?"
hyde = HyDEQueryTransform(include_original=True)
query_bundle = hyde(question)
print(f"query_bundle embedding len: {len(query_bundle.embedding_strs)}")
for idx, embedding in enumerate(query_bundle.embedding_strs):
print(f"embedding {idx}: {embedding[:100]}")
# Display result
query_bundle embedding len: 2
embedding 0: Loki used the Tesseract, also known as the Cosmic Cube, in his attempt to conquer Earth. This myste...
embedding 1: What mysterious item did Loki use in an attempt to conquer Earth?
- 首先,实例化一个 HyDEQueryTransform (HyDEQueryTransform) 对象,并指定参数include_original=True,表示包含原始问题。需要注意的是,include_original 的默认值为 True,这里传递参数仅用于演示。
- 然后,用问题调用 hyde 对象,返回一个 QueryBundle 对象。
- QueryBundle 对象的 embedding_strs 属性是一个数组,其中第一个元素是生成的假设文档。如果 include_original 为 True,则数组的第二个元素将包含原始问题。
我们发现,LLM 基于其知识,为用户提问提供了很好的答案,生成的假设文档也与电影情节摘要相符。
LlamaIndex 中生成假设文档的提示模板如下。总体思路是生成一段文字来回答问题,并尽可能包含关键细节。{context_str} 表示用户的提问:
HYDE_TMPL = (
"Please write a passage to answer the question\n"
"Try to include as many key details as possible.\n"
"\n"
"\n"
"{context_str}\n"
"\n"
"\n"
'Passage:"""\n'
)
现在,让我们使用查询引擎来检索问题的答案:
from llama_index.core.query_engine import TransformQueryEngine
hyde_query_engine = TransformQueryEngine(query_engine, hyde)
response = hyde_query_engine.query(question)
print(f"hyde query result: {response}")
# Display result
hyde query result: Loki used the Tesseract in his attempt to conquer Earth. This powerful artifact, also kn...
- 构建一个基于 HyDEQueryTransform 和原始查询引擎的 TransformQueryEngine。
- 查询引擎的查询方法首先为原始问题生成假设文档,然后基于这些假设文档进行搜索并生成答案。
虽然得到了正确结果,但我们无法确定 LlamaIndex 是否在检索过程中使用了假设文档,可以通过以下代码进行验证。
from llama_index.core.retrievers.transform_retriever import TransformRetriever
retriever = node_parser.as_retriever(similarity_top_k=2)
hyde_retriever = TransformRetriever(retriever, hyde)
nodes = hyde_retriever.retrieve(question)
print(f"hyde retriever nodes len: {len(nodes)}")
for node in nodes:
print(f"node id: {node.id_}, score: {node.get_score()}")
print("=" * 50)
nodes = retriever.retrieve("\n".join(f"{n}" for n in query_bundle.embedding_strs))
print(f"hyde documents retrieve len: {len(nodes)}")
for node in nodes:
print(f"node id: {node.id_}, score: {node.get_score()}")
- 在第一部分,使用 TransformRetriever 基于原始检索器和 HyDEQueryTransform 构建一个新的检索器。
- 使用新的检索器检索用户问题,并打印出检索到的文档 ID 和得分。
- 在第二部分,使用原始检索器检索假设文档。假设文档是从 QueryBundle 对象的 embedding_strs 获取的,该对象包含两个元素:一个假设文档和原始问题。
- 打印出假设文档的文档 ID 和得分。
显示的结果如下:
hyde retriever nodes len: 2
node id: 51e9381a-ef93-49ee-ae22-d169eba95549, score: 0.8895532276574978
node id: 5ef8a87e-1a72-4551-9801-ae7e792fdad2, score: 0.8499209871867581
==================================================
hyde documents retrieve nodes len: 2
node id: 51e9381a-ef93-49ee-ae22-d169eba95549, score: 0.8842142746289462
node id: 5ef8a87e-1a72-4551-9801-ae7e792fdad2, score: 0.8460828835028101
我们可以看到,两种方法的结果几乎完全相同,说明用于检索的输入是相似的,即假设文档。如果我们将HyDEQueryTransform对象中的include_original属性设置为False,即生成的假设文档不包含原始问题,然后再次运行代码,结果如下:
hyde retriever nodes len: 2
node id: cfaea328-16d8-4eb8-87ca-8eeccad28263, score: 0.7548985780343257
node id: f47bc6c7-d8e1-421f-b9b8-a8006e768c04, score: 0.7508234876205329
==================================================
hyde documents retrieve nodes len: 2
node id: 6c2bb8cc-3c7d-4f92-b039-db925dd60d53, score: 0.7498683385309097
node id: f47bc6c7-d8e1-421f-b9b8-a8006e768c04, score: 0.7496147322045141
我们可以看到,两种方法的结果仍然相当相似,但由于缺少原始问题,检索到的文档得分较低。
3.2、HyDE 的优势与局限
HyDE 是一种无监督的方法,在训练过程中没有对模型进行任何调整,生成模型和对比编码器都保持完整。
总而言之,虽然 HyDE 提出了一种新的查询重写方法,但它也存在一些局限性。HyDE 生成的假设文档是基于 LLM 的知识,不依赖于查询嵌入的相似性,而是强调文档之间的相似性。如果语言模型对主题并不熟悉,则可能无法始终获得最佳结果,从而导致错误率增加。LlamaIndex 在其官方文档中指出,HyDE 可能会误导查询并引入偏差,因此在实际应用中使用时应谨慎。
四、回溯提示(Step-Back Prompting)
回溯提示(Step-Back Prompting)是一种高效的提示技术,它旨在辅助大语言模型(LLM)从具体细节中提炼出抽象的概念和基本原则。该技术的核心在于将用户的具体问题转化为一个更高层次的抽象问题,从而帮助模型更有效地进行信息检索和推理。
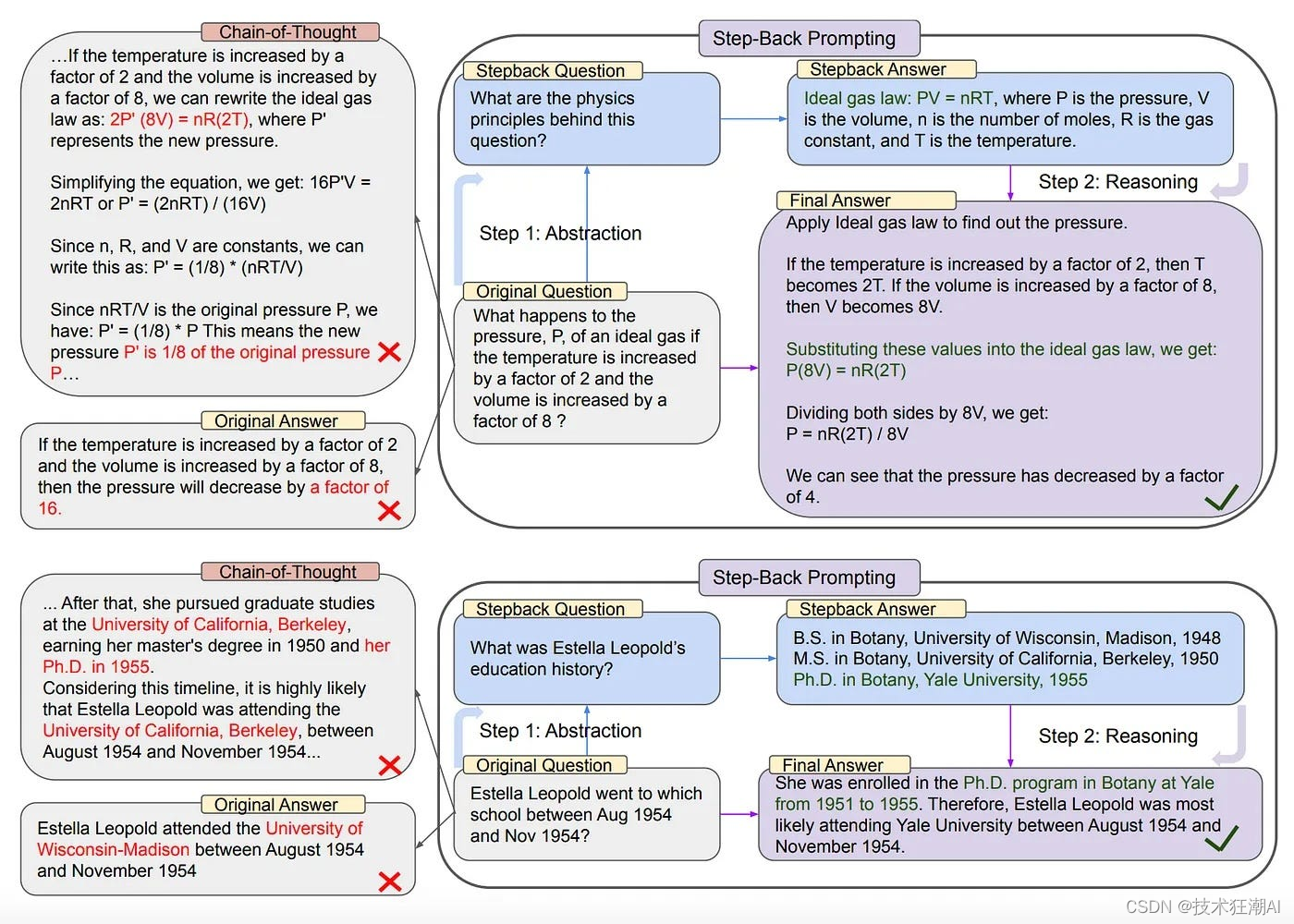
在现实应用中,用户提出的问题往往包含大量细节,这可能导致大语言模型在直接检索和推理时难以捕捉到问题的本质。例如,在解决物理问题时,如果直接询问“温度增加两倍时,理想气体的体积增加八倍,压力 P 会如何变化?”,模型可能会忽略理想气体定律的基本原则,从而无法准确回答。然而,通过回溯提示,我们首先根据原始问题生成一个更广泛的问题,例如寻找问题背后的基本物理公式。然后,我们从更广泛的问题中获得答案,最后将更广泛问题的答案和原始问题一起提交给 LLM,从而获得正确答案。
同样,对于特定历史人物的教育背景问题,如“Estella Leopold 在1954年8月至1954年11月期间就读于哪所学校?”,由于涉及特定的时间范围,模型直接回答的难度也会增加。
为了解决这些问题,回溯提示建议提出一个更广泛的问题,如“Estella Leopold 的教育经历是什么?”这样的问题不仅涵盖了原始问题,而且可以提供足够的背景信息,从而帮助模型推断出原始问题的答案。这种更广泛的问题通常比原始问题更容易回答,因为它们更容易与模型已有的知识库相匹配。
回溯提示的过程可以帮助避免在复杂推理过程中出现的错误,如下图所示的“思维链”中的中间步骤错误。
回溯提示的实施步骤
回溯提示主要包括以下两个步骤:
- 抽象化(Abstraction): 我们首先引导大语言模型提出一个更广泛的问题,关注于高级概念或原则,而非直接解答用户的查询。随后,我们检索与这些概念或原则相关的信息。
- 推理(Reasoning): 基于检索到的关于高级概念或原则的信息,大语言模型可以进行抽象推理,从而推导出原始问题的答案。
通过这种抽象化和推理的过程,回溯提示不仅提高了大语言模型在处理复杂问题时的准确性,而且增强了其在抽象思维和逻辑推理方面的能力。
4.1、代码示例
虽然 LlamaIndex 没有专门实现回溯提示,但我们可以通过原始调用将 LLM 与 LlamaIndex 结合起来进行演示。首先,让我们让 LLM 根据原始问题生成一个回溯问题:
from llama_index.core import PromptTemplate
from openai import OpenAI
client = OpenAI()
examples = [
{
"input": "Who was the spouse of Anna Karina from 1968 to 1974?",
"output": "Who were the spouses of Anna Karina?",
},
{
"input": "Estella Leopold went to whichschool between Aug 1954and Nov 1954?",
"output": "What was Estella Leopold'seducation history?",
},
]
few_shot_examples = "\n\n".join(
[f"human: {example['input']}\nAI: {example['output']}" for example in examples]
)
step_back_question_system_prompt = PromptTemplate(
"You are an expert at world knowledge."
"Your task is to step back and paraphrase a question to a more generic step-back question,"
"which is easier to answer. Here are a few examples:\n"
"{few_shot_examples}"
)
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
temperature=0.1,
messages=[
{
"role": "system",
"content": step_back_question_system_prompt.format(
few_shot_examples=few_shot_examples
),
},
{"role": "user", "content": question},
],
)
step_back_question = completion.choices[0].message.content
print(f"step_back_question: {step_back_question}")
- 首先,我们定义一些回溯问题的示例,并将它们包含在 LLM 的系统提示中,让它了解生成问题的模式。
- 然后,我们将用户问题和系统提示都提供给 LLM,让它生成一个回溯问题。
生成回溯问题后,我们分别检索与原始问题和回溯问题相关的文档:
retrievals = retriever.retrieve(question)
normal_context = "\n\n".join([f"{n.text}" for n in retrievals])
retrievals = retriever.retrieve(step_back_question)
step_back_context = "\n\n".join([f"{n.text}" for n in retrievals])
获得检索结果后,我们让 LLM 生成最终答案:
step_back_qa_prompt_template = PromptTemplate(
"Context information is below.\n"
"---------------------\n"
"{normal_context}\n"
"{step_back_context}\n"
"---------------------\n"
"Given the context information and not prior knowledge, "
"answer the question: {question}\n"
)
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
temperature=0.1,
messages=[
{
"role": "system",
"content": "Always answer the question, even if the context isn't helpful.",
},
{
"role": "user",
"content": step_back_qa_prompt_template.format(
normal_context=normal_context,
step_back_context=step_back_context,
question=question,
),
},
],
)
step_back_result = completion.choices[0].message.content
print(f"step_back_result: {step_back_result}")
在提示模板中,我们将原始问题和回溯问题相关的文档信息提供给 LLM,并结合原始问题,让 LLM 生成答案。
最后,让我们比较使用和不使用回溯提示的常规 RAG 检索结果:
question: Was there a great war on the planet Titan??
base result: No, there has not been a major war on the planet Titan. It is not known for being the site of any significant conflicts or wars.
====================================================================================================
step back question: Have there been any significant events on the planet Titan?
step back result: Yes, in the Marvel Cinematic Universe, there was a significant conflict on the planet Titan. In "Avengers: Infinity War," Titan is depicted as the destroyed homeworld of Thanos, and the battle on Titan involved a group of heroes including Iron Man (Tony Stark), Spider-Man (Peter Parker), Doctor Strange (Stephen Strange), and the Guardians of the Galaxy, as they attempted to thwart Thanos from achieving his goals.
可以看到,不使用回溯提示的结果是错误的,但使用回溯提示后,我们基于知识库文档获得了正确答案。
五、重写-检索-阅读
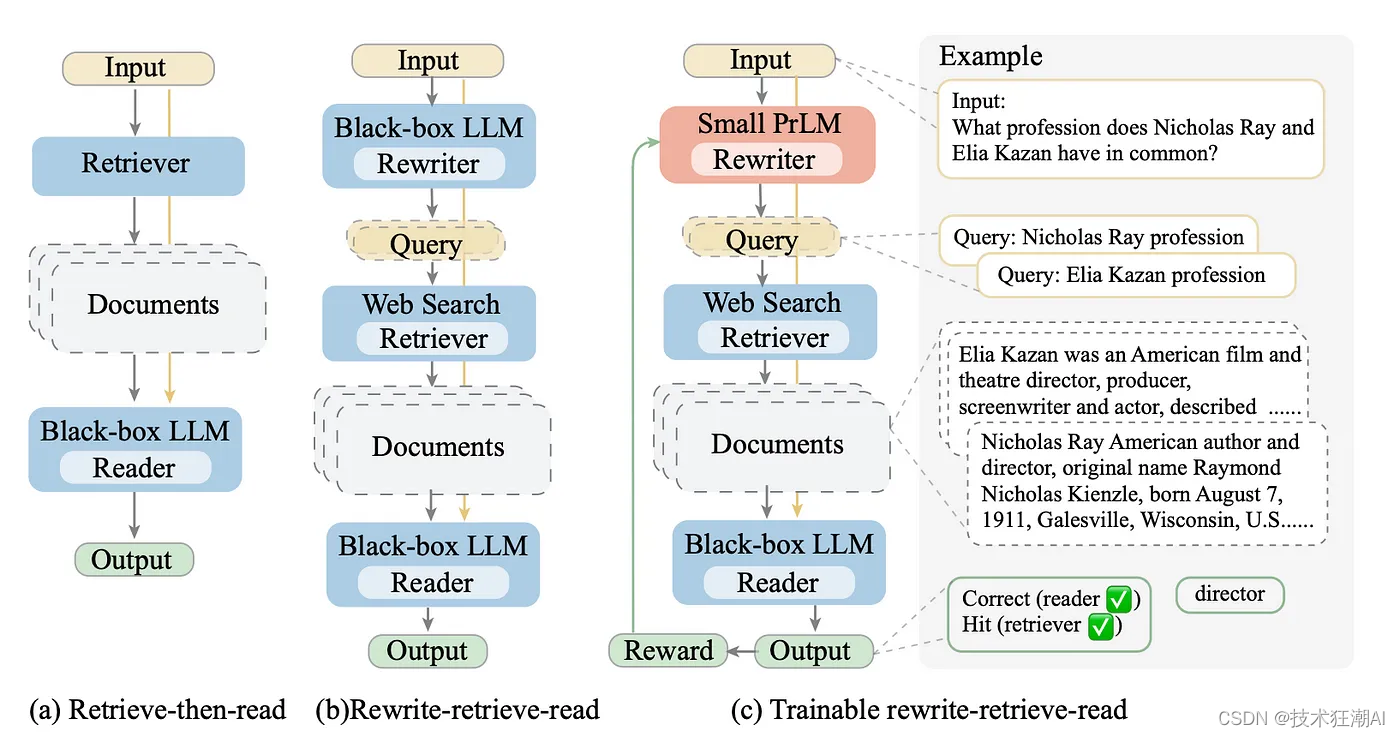
论文 「Query Rewriting for Retrieval-Augmented Large Language Models」 提出了一种新的方法:重写-检索-阅读。该方法认为,在实际应用中,原始查询并非总是最适合进行检索的。
因此,该论文建议先使用大语言模型 (LLM) 对查询进行重写,然后再进行检索和答案生成,而不是直接从原始查询中检索内容并生成答案。下图展示了这种方法的流程。
5.1、代码示例
例如,用户输入查询 “2020 年的 NBA 冠军是洛杉矶湖人队!告诉我 langchain 框架是什么?”。如果直接使用该查询进行检索,可能无法获取到关于 langchain 框架的信息。而通过查询重写,可以得到更精准的答案。
下面以 LangChain 为例,演示如何使用查询重写技术。首先,安装必要的库:
pip install langchain
pip install openai
pip install langchainhub
pip install duckduckgo-search
pip install langchain_openai
环境配置与库导入
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPEN_AI_KEY"
from langchain_community.utilities import DuckDuckGoSearchAPIWrapper
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI
构建检索链并执行简单的查询
def june_print(msg, res):
print('-' * 100)
print(msg)
print(res)
base_template = """Answer the users question based only on the following context:
<context>
{context}
</context>
Question: {question}
"""
base_prompt = ChatPromptTemplate.from_template(base_template)
model = ChatOpenAI(temperature=0)
search = DuckDuckGoSearchAPIWrapper()
def retriever(query):
return search.run(query)
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| base_prompt
| model
| StrOutputParser()
)
query = "The NBA champion of 2020 is the Los Angeles Lakers! Tell me what is langchain framework?"
june_print(
'The result of query:',
chain.invoke(query)
)
june_print(
'The result of the searched contexts:',
retriever(query)
)
结果展示
(langchain) Florian:~ Florian$ python /Users/Florian/Documents/test_rewrite_retrieve_read.py
----------------------------------------------------------------------------------------------------
The result of query:
I'm sorry, but the context provided does not mention anything about the langchain framework.
----------------------------------------------------------------------------------------------------
The result of the searched contexts:
The Los Angeles Lakers are the 2020 NBA Champions!Watch their championship celebration here!Subscribe to the NBA: https://on.nba.com/2JX5gSN Full Game Highli... Aug 4, 2023. The 2020 Los Angeles Lakers were truly one of the most complete teams over the decade. LeBron James' fourth championship was one of the biggest moments of his career. Only two players from the 2020 team remain on the Lakers. In the storied history of the NBA, few teams have captured the imagination of fans and left a lasting ... James had 28 points, 14 rebounds and 10 assists, and the Lakers beat the Miami Heat 106-93 on Sunday night to win the NBA finals in six games. James was also named Most Valuable Player of the NBA ... Portland Trail Blazers star Damian Lillard recently spoke about the 2020 NBA "bubble" playoffs and had an interesting perspective on the criticism the eventual winners, the Los Angeles Lakers, faced. But perhaps none were more surprising than Adebayo's opinion on the 2020 NBA Finals. The Heat were defeated by LeBron James and the Los Angeles Lakers in six games. Miller asked, "Tell me about ...
结果表明,根据搜索到的上下文,关于 “langchain” 的信息很少。
构建查询重写器
rewrite_template = """Provide a better search query for \
web search engine to answer the given question, end \
the queries with ’**’. Question: \
{x} Answer:"""
rewrite_prompt = ChatPromptTemplate.from_template(rewrite_template)
def _parse(text):
return text.strip("**")
rewriter = rewrite_prompt | ChatOpenAI(temperature=0) | StrOutputParser() | _parse
june_print(
'Rewritten query:',
rewriter.invoke({"x": query})
)
结果展示
----------------------------------------------------------------------------------------------------
Rewritten query:
What is langchain framework and how does it work?
构建重写-检索-阅读链并使用重写后的查询
rewrite_retrieve_read_chain = (
{
"context": {"x": RunnablePassthrough()} | rewriter | retriever,
"question": RunnablePassthrough(),
}
| base_prompt
| model
| StrOutputParser()
)
june_print(
'The result of the rewrite_retrieve_read_chain:',
rewrite_retrieve_read_chain.invoke(query)
)
结果展示
----------------------------------------------------------------------------------------------------
The result of the rewrite_retrieve_read_chain:
LangChain is a Python framework designed to help build AI applications powered by language models, particularly large language models (LLMs). It provides a generic interface to different foundation models, a framework for managing prompts, and a central interface to long-term memory, external data, other LLMs, and more. It simplifies the process of interacting with LLMs and can be used to build a wide range of applications, including chatbots that interact with users naturally.
经过查询重写,我们最终成功获得了正确的答案。
六、Query2doc
Query2doc 是一种利用大型语言模型 (LLM) 进行查询扩展的技术。它使用 LLM 生成一些伪文档,然后将这些伪文档与原始查询合并,形成一个新的查询,如下图所示:
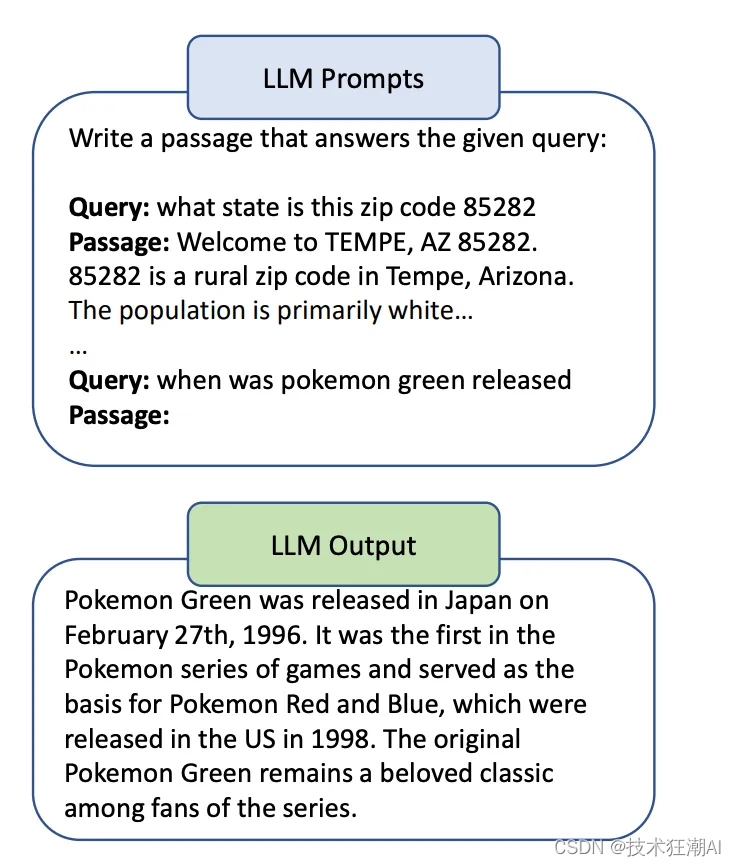
密集检索 (Dense Retrieval) 是一种利用语义向量来进行文档检索的技术。它将文档和查询都映射到一个高维向量空间中,然后根据向量之间的相似度来进行检索。
在密集检索中,新的查询表示为 q+,它将原始查询 (q) 和伪文档 (d’) 串联起来,并用 [SEP] 分隔:q+ = concat(q, [SEP], d’)。
Query2doc 认为,HyDE 方法隐含地假设了真实文档和伪文档在不同的表达方式下具有相同的语义,但这对于某些查询可能并不成立。
Query2doc 与 HyDE 方法的另一个区别在于,Query2doc 训练了一个监督密集检索器,如论文中所述。
目前,在 LangChain 或 LlamaIndex 中,尚未发现 Query2doc 的代码实现。
七、迭代检索生成
迭代检索生成(ITER-RETGEN)方法利用生成的内容来引导检索过程。它在检索-阅读-检索-阅读的循环中,迭代地执行 “检索增强生成” 和 “生成增强检索”。

如上图所示,对于给定的问题 q 和检索语料库 D = {d}(其中 d 代表一段文本),ITER-RETGEN 会持续执行 T 次检索生成操作。
在每一次迭代 t 中,首先会将前一次迭代生成的文本 yt-1 与原始问题 q 合并,然后检索出与之相关的 k 个文本段落。接下来,我们会向大语言模型 (LLM) M 提供一个提示,其中包含检索到的文本段落(表示为 Dyt-1||q)和原始问题 q。然后,大语言模型会生成一个新的输出 yt。因此,每一次迭代可以描述如下:
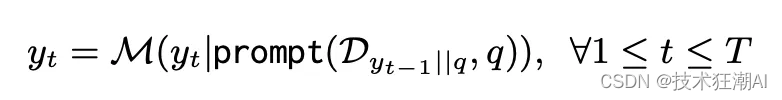
最后生成的文本 yt 将作为最终的答案。
与 Query2doc 类似,目前在 LangChain 或 LlamaIndex 中也尚未发现 ITER-RETGEN 的代码实现。
八、总结
本文深入探讨了 RAG(Retrieval-Augmented Generation)检索策略中的高级查询重写技术。其中重点介绍了子问题查询、HyDE 查询转换、Query2doc、回溯提示和迭代检索生成等五种查询重写策略。
这些策略的目的是通过重新构造查询来更准确地定位相关信息,从而提高 RAG 系统的检索效率和答案的精确度。通过 LlamaIndex 提供的代码示例,文章展示了如何实现这些策略,并分享了一些实用技巧。
在实际应用中,选择合适的查询重写方法需要根据具体问题和性能要求来权衡。虽然查询重写能够显著提升检索结果的质量,但每次调用 LLM 都会带来额外的计算成本和延迟。因此,需要在保证检索效果的同时,合理管理资源和性能。
参考资料
[1]. Luyu Gao, Xueguang Ma, Jimmy Lin, Jamie Callan, R. (2022). Precise Zero-Shot Dense Retrieval without Relevance Labels: https://arxiv.org/pdf/2212.10496.pdf
[2]. HyDE documentation:
https://docs.llamaindex.ai/en/stable/examples/query_transformations/HyDEQueryTransformDemo/?h=hyde
[3]. LlamaIndex:https://www.llamaindex.ai/
[4]. llama-index-question-gen-openai:https://github.com/run-llama/llama_index/blob/main/llama-index-integrations/question_gen/llama-index-question-gen-openai/llama_index/question_gen/openai/base.py#L18-L45
[5]. Huaixiu Steven Zheng, Swaroop Mishra, Xinyun Chen, Heng-Tze Cheng, Ed H. Chi, Quoc V Le, Denny Zhou, R.(2023). Take a Step Back: Evoking Reasoning via Abstraction in Large Language Models:https://arxiv.org/pdf/2310.06117.pdf
[6]. Xinbei Ma, Yeyun Gong, Pengcheng He, Hai Zhao, Nan Duan, R.(2023). Query Rewriting for Retrieval-Augmented Large Language Models:https://arxiv.org/abs/2305.14283
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。