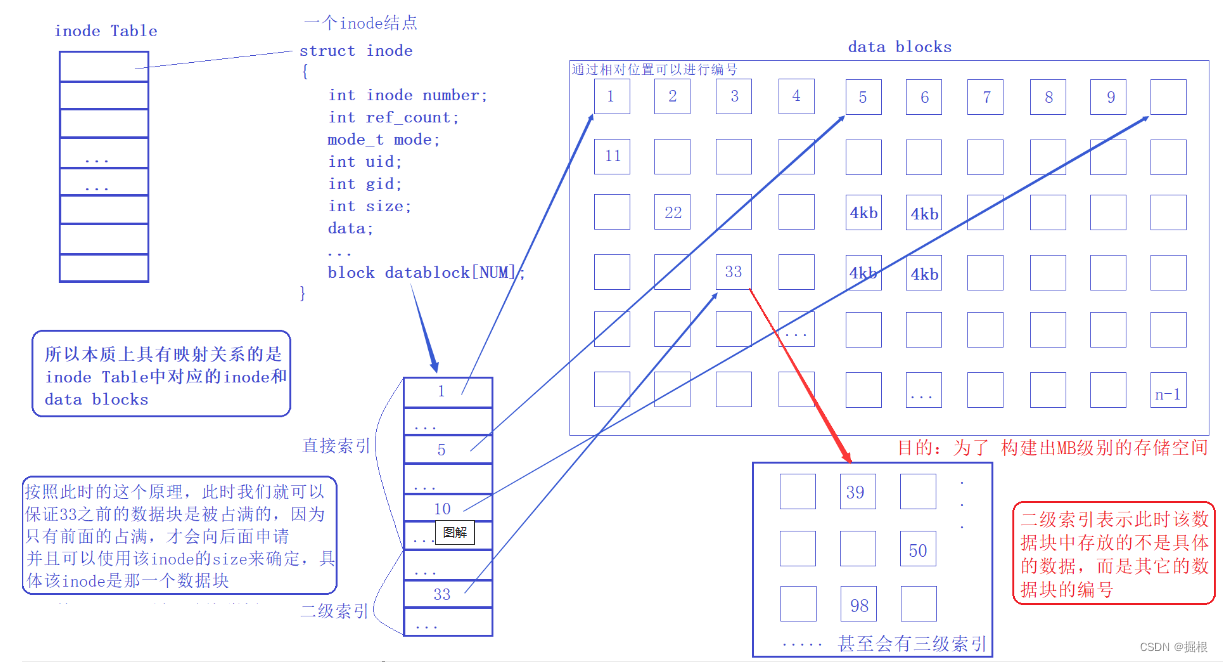
话不多说,直接上官方链接:Task3:进阶baseline详解 - 飞书云文档 (feishu.cn)Task4:持续尝试,上分! - 飞书云文档 (feishu.cn)
一、理解
- 阅读了官方发布的Task4链接内容,主要是对“特征工程”、“模型训练”、"模型验证"三大模块进行优化
- “特征工程”模块优化对InChI进行展开构建特征(即提取分子式、计算分子量、原子记数)
- “模型训练”模块优化:
- 方案一:使用lightgbm、xgboost和catboost模型依次跑完测试,取三个模型结果的平均值。
- 方案二:使用stacking分层模型集成框架
- "模型验证"模块优化,类比模型训练方案一和方案二,从而得出最终的优化后的结果
二、此次分子AI赛个人最终代码
-
# 1. 导入需要用到的相关库 import pandas as pd # 导入Pandas库,用于数据处理 import numpy as np # 导入Numpy库,用于数值计算 from xgboost import XGBClassifier # 导入XGBoost分类器 from sklearn.model_selection import train_test_split, GridSearchCV # 导入训练测试集划分和网格搜索库 from sklearn.preprocessing import LabelEncoder # 导入标签编码器 from sklearn.feature_selection import SelectFromModel # 导入基于模型的特征选择库 # 2. 读取训练集和测试集 train = pd.read_excel('./data/data280993/traindata-new.xlsx') # 读取训练集数据 test = pd.read_excel('./data/data280993/testdata-new.xlsx') # 读取测试集数据 # 3. 特征工程 # 3.1 删除train数据中的 'DC50 (nM)' 和 'Dmax (%)' 列 train = train.drop(['DC50 (nM)', 'Dmax (%)'], axis=1) # 删除不需要的列 # 3.2 处理分类数据 # 使用LabelEncoder对分类特征进行编码 label_encoders = {} # 创建一个空字典来存储编码器 for col in train.columns[2:]: # 遍历除了前两列之外的所有列 if train[col].dtype == object: # 检查列是否为对象类型(即字符串) # 合并训练集和测试集的类别 combined_data = pd.concat([train[col], test[col]]) # 合并训练集和测试集的对应列 le = LabelEncoder() # 创建LabelEncoder实例 combined_data = le.fit_transform(combined_data) # 对合并后的数据编码 train[col] = combined_data[:len(train)] # 将编码后的数据放回训练集 test[col] = combined_data[len(train):] # 将编码后的数据放回测试集 label_encoders[col] = le # 保存编码器以备后用 # 检查测试集中非数值类型的特征 non_numeric_cols = test.select_dtypes(include=['object']).columns.tolist() # 获取测试集中非数值类型的列名列表 # 处理非数值类型的特征 for col in non_numeric_cols: # 如果该特征应该在模型中,确保它是数值类型的 if col in train.columns[2:]: # 尝试将字符串转换为数值类型 test[col] = pd.to_numeric(test[col], errors='coerce') # 转换为数值类型,无法转换的变为NaN # 确保测试集中没有缺失值 test = test.fillna(0) # 用0填充测试集中的缺失值 # 分离特征和标签 X_train = train.iloc[:, 2:].values # 获取训练集的特征值 y_train = train['Label'].values # 获取训练集的标签值 X_test = test.iloc[:, 1:].values # 获取测试集的特征值 # 4. 特征选择 # 使用 XGBoost 模型进行特征选择 selector = SelectFromModel(XGBClassifier(use_label_encoder=False, eval_metric='logloss')) # 创建特征选择器 selector.fit(X_train, y_train) # 训练特征选择器 X_train_selected = selector.transform(X_train) # 应用特征选择器到训练集 X_test_selected = selector.transform(X_test) # 应用特征选择器到测试集 # 5. 模型调优 # 定义 XGBoost 模型的参数网格 param_grid = { # 定义参数网格 'n_estimators': [100, 200, 300], # 树的数量 'max_depth': [5, 7, 9], # 树的最大深度 'learning_rate': [0.006, 0.04, 0.15], # 学习率 'subsample': [0.35, 0.55, 0.95], # 子采样率 'colsample_bytree': [0.55, 0.75, 0.95], # 列采样率 } # 使用网格搜索进行模型调优 xgb_model = XGBClassifier(use_label_encoder=False, eval_metric='logloss') # 创建XGBoost模型 grid_search = GridSearchCV(estimator=xgb_model, param_grid=param_grid, cv=5) # 创建网格搜索实例 # 执行网格搜索以找到最佳参数组合 grid_search.fit(X_train_selected, y_train) # 执行网格搜索以找到最佳参数组合 # 获取最佳参数模型 best_xgb_model = grid_search.best_estimator_ # 获取最佳估计器(模型) # 6. 使用最佳模型进行预测 pred = best_xgb_model.predict(X_test_selected) # 使用最佳模型对测试集进行预测 result = pd.DataFrame({'uuid': test['uuid'], 'Label': pred}) # 创建包含预测结果的DataFrame # 7. 保存结果文件到本地 result.to_csv('submit_xgb2.csv', index=False) # 将结果保存为CSV文件,不包含索引 - 得分:0.76761

三、结语
- 还是学到了不少东西,虽然在机器学习这方面零基础但是通过官方4个Task的指引,从中学到了不少思路,尽管还是有很多东西看不懂,但是思维方式起码跟着Task有所提升
- 工作之余学习一下,对我来说还是有提升的,非常新颖的学习方式,但是想要彻底去学习透彻还是得去学习原理,慢慢的从原理到实践,得脚踏实地才行,当一个思维方式的提升吧!




![[终端安全]-4 移动终端之硬件架构安全](https://i-blog.csdnimg.cn/direct/26976abf67ba4d5f976b5dcb3c44da48.png)