在这个三部曲中,我们旨在从三个部分深入研究预训练模型:文本、图像和机器人。
我们旨在探索它们的概念、出现以及这些模型的工作原理。还将研究预训练模型的不同架构和类型。
探索哪些是最强大的,以及预训练模型和 Transformers 是否是 LLM 的主要优势。
此外,将讨论如果没有预训练模型和 Transformers,我们今天是否会拥有像 ChatGPT 这样的强大聊天机器人。如今,聊天机器人不仅限于 NLP 领域。
例如,GPT-4 是多方面的,因为它不仅限于文本生成。
我们还将探索它们是否具有与 RL 类似的功能。在机器人领域,我们将探索我们拥有哪些预训练模型,以及哪些模型更适合多模态模型。还将讨论预训练模型现在是否仅适用于 NLP。
在图像领域,我们将探索哪些模型最强大,以及如何微调或超参数调整每个模型以供使用。
加入剑和侠客三部曲,一起探索和回答这些问题。

概述
预训练模型最重要的好处之一是能够针对手头的特定任务对这些模型进行微调和应用迁移学习。迁移学习是深度学习的一个重要方面,也是其持续革命的基础要素之一。迁移学习也是人类或任何生物体学习的一个基本方面。当您阅读本文时,我正在将我关于预训练模型的知识传授给您!
为了更好地理解这个问题,我们来看一个例子。假设你想建一栋大房子。有两种方法可以实现:
第一种方法是从零开始,一步一步地建造房屋,从地基到外墙,以及所有细节。为此,您需要材料和工具,并且还需要建造完全抗震的房屋。这需要更复杂的工程,这可能导致更高的成本,并且结果可能不完全令人满意。
第二种方法是利用一家在房屋建筑方面拥有多年经验的公司的经验和专业知识。该公司建造的房屋采用预制模块化组件。这些像拼图一样的部件是可定制的,这意味着可以根据我们的喜好定制建筑物的内部和外部设计。在施工方面,工程设计的方式是使建筑物完全抗震!因此,设计和执行项目的成本和时间大大减少,我们拥有一座完全抗震的房屋,这是多年专业经验的成果!
您会选择哪种方法?
预训练模型的历史及其出现
预训练模型的出现是因为训练各种人工智能模型(尤其是深度学习)存在重大挑战和担忧,例如成本高昂以及利用大规模数据甚至收集这些数据的难度。大型数据集需要强大且昂贵的硬件。过去,非常大的数据集并不容易获得。预训练模型于 2010 年代初首次推出,最初用于自然语言处理 (NLP),它们在大型语言模型 (LLM) 的发展中继续发挥重要作用。
预训练模型最重要的特征之一是它们带有一组初始权重和偏差,因此可以针对特定任务有效地对其进行微调。虽然没有模型可以达到 100% 的准确率,但预训练模型是由更专业的人员使用更精确的工具和更强大的物流制作的,因此它们通常比从头开始构建的模型更准确、更高效。
针对各种重要任务的最著名和最广泛使用的预训练模型包括:
– 图像处理:VGG(2014)/ ResNet(2015)
– 机器翻译:Transformer(2017)/ BERT(2018)
– 音乐生成:OpenAI 的 MuseNet(2019)/ Magenta 的 Music Transformer(2018)
– 机器人技术:Dactyl(2018)/ DeepLoco(2018)
– 情感分析:BERT(2018)/ RoBERTa(2019)
– 假新闻检测:BERT(2018)/ GPT-3(2020)
预训练模型的概念到底是什么?
预训练模型的概念最初是在深度神经网络 (DNN) 的开发过程中引入的,但随着 Word2Vec 和 GloVe 等算法的发展,它得到了更多的关注。在这种情况下,预训练模型是指使用现有模型作为训练新模型的起点。特别是,针对文本的预训练模型尤其有用。让我们简要探索 Word2Vec 和 GloVe 算法,看看它们是如何工作的。让我们开始吧!
什么是词嵌入?
计算机通过数字进行交流,这就是为什么我们必须使用数字来向它们传达问题。要处理文本数据,我们需要使用各种技术(例如 Word Embedding)将其转换为数字。本质上,Word Embedding 是一种深度模型或神经网络,可以从数据集中的单词特征分布中进行学习。
Word Embedding 的概念并非源自一篇文章。它是多位研究人员随着时间的推移提出的各种想法的结晶。20 世纪 80 年代,Geoffrey Hinton 提出了 Word Embedding 和“特征表示”的概念,其中涉及将单词转换为密集向量。在 Word Embedding 中,我们将句子中的单词编码为向量,以便计算机可以处理它们。
词向量利用文本数据集中单词的含义,在密集空间中表示它们。该空间通过密集距离表达单词之间的语义关系,相似或相关的单词彼此接近。在下一节中,我们将探索使用词向量进行文本处理的预训练模型。
Word2Vec
2013 年,Tomas Mikolov、Kai Chen、Greg Corrado 和 Jeffrey Dean 等谷歌研究人员在论文中发表了 Word2Vec 模型。向量空间中词语表征的有效估计
Word2vec 算法是一种自然语言处理 (NLP) 技术,可生成单词的向量表示。要使用Gensim库的 ` gensim.models ` 子模块实例化 Word2Vec 模型,您可以按照下面的代码片段进行操作。它还演示了如何生成单词的向量表示。
from gensim.models import Word2Vec
# Example data
sentences = [["this", "is", "a", "sentence"], ["another", "sentence"]]
# Create Word2Vec model
model = Word2Vec(sentences, vector_size=100, window=5, min_count=1, workers=4)
# Display word vectors
word_vectors = model.wv
word_vectors_dict = {}
for word in word_vectors.key_to_index:
word_vectors_dict[word] = word_vectors[word]
print(word_vectors_dict)
Word2Vec 模型使用 Word Embedding 创建单词的向量表示。每个单词都链接到一个实数向量,该向量具有通过使用文本数据训练 Word2Vec 模型获得的特定维度。这种映射可确保具有相似含义的单词在向量空间中也彼此接近,从而保留它们之间的语义关系。
在一个句子中,各个组成部分聚集在一起并共同传达意义。即使某些单词不是单独存在的,它们仍然可以根据句子中建立的关系传达意义和上下文。词向量旨在使计算机更容易完成此过程。例如,在 Word2Vec 向量空间中,“bird”和“fly”等含义相似的单词彼此更接近。如果这两个词的向量在向量空间中彼此接近,则意味着它们具有语义关系。
此功能允许将语言知识从一项任务转移到另一项任务。特定数据集的学习向量可以应用于另一个数据集。例如,为机器翻译训练的向量也可用于情绪分析,因为在这些任务中保留了单词之间的相似含义。因此,Word2Vec 模型是首批利用这一想法的模型之一。
Word2Vec 方法
Word2Vec 方法通常依赖于深度神经网络 (DNN) 模型,例如 skip-gram 和连续词袋 (CBOW) 模型,因为词序并不重要。
CBOW 模型
CBOW(连续词袋)模型是一种用于自然语言处理的方法。它的工作原理是预测句子中的中心词或目标词。目标词通常是从句子中随机选择的。该模型试图通过分析目标词前后的单词来预测它。例如,如果句子是“爱,她那充满雨水的眼睛朝着蓝天”,目标是根据周围的单词(例如“她那充满雨水的眼睛朝着蓝色”)来预测目标词“爱”。换句话说,算法使用目标词周围的单词来预测它。为了预测这个句子中的单词“天空”,算法可能会接受诸如“爱”、“她”、“充满雨水”、“眼睛”、“朝着”、“这个”和“蓝色”之类的输入。
Skip-gram模型
Skip-gram 模型的运作方式与 CBOW 不同,因为它会预测给定目标词周围的单词。例如,如果目标词是某个句子中的“sky”,则该模型将尝试预测“love”、“eyes”、“rainy”、“he/she”等单词以及可能出现在其之前或之后的其他单词。本质上,该模型旨在为每个单词生成向量,以准确预测其附近的单词。
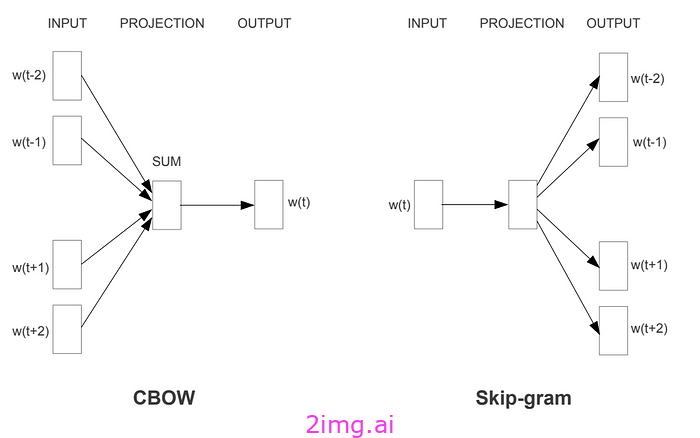
来源:此图有效地展示了 Skip-gram 和 CBOW 模型的工作原理,如 Mikolov 在 2013 年的论文中所示。
CBOW 与 Skip-gram
CBOW 模型在处理较长且多样化的文本时效果最佳。相比之下,skip-gram 模型更适合较短的文本,其目标是识别单词之间的语义关系模式。通常,skip-gram 被认为是比 CBOW 更强大的模型,因为它在学习词向量方面具有更高的准确性。Word2Vec 是许多语言模型的基础工具,包括GPT-3和BERT。然而,现代语言模型现在利用 Transformer 等先进方法来学习词向量。尽管如此,Word2Vec 仍然是训练 LLM 的强大工具。
GloVe 模型
GloVe 模型(即用于词表示的全局向量)是一种基于全局向量概念开发的分布式词表示方法。此方法类似于另一个名为 Word2Vec 的模型,但这两个模型计算这些向量的方式不同。斯坦福大学于 2014 年将 GloVe 作为开源项目推出。它是一种无监督学习算法,用于利用与文本中单词分布有关的统计信息来获取向量表示。这些信息包括各种文本中单词分布的概率、单词之间的语义关系以及从文本中提取的其他特征。所有这些数据都用于构建词向量。
在 GloVe 中,我们利用语言统计数据(例如词-词共现矩阵)来计算两个单词在文本中一起出现的相对概率。根据这些概率,更新词向量,同时保留单词之间的语义关系。
Word2Vec 与 GloVe
Word2Vec 和 GloVe 算法通常用于识别单词之间的语义相似性,例如同义词或关系,如“公司-产品”、“邮政编码-城市”等。然而,这些算法在识别同形异义词(拼写相同但含义不同的单词)方面可能并不有效,因为同形异义词的统计模式通常不同。例如,“bank”这个词通常与存钱的地方(金融机构)有关,但它也可以指存储数据的地方(数据库)。这两个“bank”的实例是同形异义词,这意味着它们拼写相同但含义不同。
然而,Word2Vec 模型基于单词之间的语义关系,在识别同形异义词方面可能更有效。尽管如此,也有混合方法或更先进的模型用于检测同形异义词,这些模型能够理解具有相同拼写的单词的不同含义。
另一个考虑因素是单词的大小写敏感性,因为 GloVe 和 Word2Vec 模型都对大写敏感,将不同大小写的单词视为不同的实体,并为每种大小写创建不同的向量。因此,最好将文本中所有单词的大小写标准化,以便正确使用这些模型。然而,这种标准化可能会导致语义信息的丢失。例如,“US”大写时指的是美国,但小写时则表示“我们”作为代词。
文本预处理技术
将所有单词转换为特定格式可以帮助模型学习语义模式并正确执行。但是,区分大小写可能是 GloVe 和 Word2Vec 等模型中的一个问题。为了解决这个问题,人们采用了一些文本预处理方法。其中一种方法是词干提取,它删除单词的前缀和后缀以找到单词的词根并标准化相似的单词。例如,“running”、“runs”、“ran”和“runner”等词都来自词根或基本形式“run”。Porter 算法是一种著名的词干提取技术,它利用一组基于模式的规则删除各种后缀并将单词转换为有意义的词根。例如,“cats”变成“cat”,“running”变成“run”。
要应用词干提取技术,我们需要安装NLTK并下载所需的数据。然后,我们可以使用以下 Python 代码:
import nltk
from nltk.stem import PorterStemmer
# Download necessary data for stemming
nltk.download('punkt')
# Create an instance of PorterStemmer class
stemmer = PorterStemmer()
# Words to be stemmed
words = ["running", "runs", "ran", "runner", "cats", "cat"]
# Stemming words and printing results
for word in words:
stemmed_word = stemmer.stem(word)
print(f"{word} -> {stemmed_word}")
此代码将“running”、“runs”、“ran”、“runner”、“cats”和“cat”转换为各自的词根并输出结果。
running -> run runs -> run ran -> ran runner -> runner cats -> cat cat -> cat [nltk_data] Downloading package punkt to /root/nltk_data... [nltk_data] Package punkt is already up-to-date!
自然语言处理中使用的第二种技术称为词形还原。在此方法中,单词被转换为其基本形式或词根形式。要执行词形还原,我们使用与词干提取方法类似的NLTK库。首先,我们需要使用 ` nltk.download(‘wordnet’) ` 命令下载所需的数据。然后,我们创建 ` WordNetLemmatizer ` 类的实例,该实例用于执行词形还原操作。要对单词进行词形还原,我们将它们放在名为 ` words ` 的列表中。使用 ` for ` 循环,从 ` words ` 列表中取出每个单词,然后使用 ` WordNetLemmatizer ` 类的` lemmatize ` 方法对其进行词形还原。
import nltk
from nltk.stem import WordNetLemmatizer
# Download necessary data for lemmatization
nltk.download('wordnet')
# Create an instance of WordNetLemmatizer class
lemmatizer = WordNetLemmatizer()
# Words to be lemmatized
words = ["running", "cats", "ate", "flying", "better"]
# Lemmatizing words and printing results
for word in words:
lemmatized_word = lemmatizer.lemmatize(word)
print(f"{word} -> {lemmatized_word}")
执行上述代码后,每个单词的词形还原结果将与原始单词一起打印为一个句子。例如,如果输入单词“running”,则此操作的输出将为“running”,因为单词“running”被视为从词根“run”派生的动词。
[nltk_data] Downloading package wordnet to /root/nltk_data... running -> running cats -> cat ate -> ate flying -> flying better -> better
以下方法可确保单词的所有变体都标准化,从而降低对大写的敏感性。通过利用这些技术,所有单词都转换为标准格式,大写不再影响文本分析的结果。值得注意的是,这两种方法采用不同的方法来标准化单词,并且根据问题的性质和目标,可以同时使用词干提取和词形还原技术。然而,这可能会导致文本处理的复杂性增加和效率降低。
GloVe 和 Word2Vec 等算法是基于文本的词向量模型,被用作预处理阶段之一,用于将BERT和GPT等模型中的单词表示为输入,但不是这些模型的主要部分。对于BERT和GPT等模型,也称为预训练语言模型,它们在使用预训练和微调的 Transformer 网络的机器翻译、文本生成、问答和自然语言处理任务等任务中表现出色。在下一节中,我们将深入研究它们。敬请期待。
LLM的力量从何而来!
GloVe 和 Word2Vec 是 NLP 的第一批模型。后来,引入了BERT、GPT-3 和 RoBERTa等预训练模型,这些模型基于带有注意力机制的基于 Transformer 的文本转换。这些模型如今更加高效和流行。2017 年,一篇彻底改变了 NLP 的论文发表。作者可能没有意识到他们的论文“注意力就是你所需要的一切”会对 NLP 产生如此大的影响。
注意力机制被认为是强大的语言模型机器 (LLM) 的重要组成部分。具体来说,在深度学习和自然语言处理 (NLP) 中,注意力的概念用于增强循环神经网络 (RNN) 并促进更好地管理较长的序列或句子。BERT和GPT -3等预训练模型建立在这些基础概念之上,并经历了重大发展。BERT利用了注意力的思想,而GPT-3使用自注意力模型。此外,GPT-3模型利用了 Transformer 架构,该架构最初是为自注意力模型设计的。
自注意力机制
自注意力机制与按顺序处理输入数据的RNN(即,每个输入,例如句子中的单词,在特定时间按顺序传输到具有特定权重的网络节点)不同,它会考虑单词在时间上(或顺序上)的关系,并连续检查随时间变化的依赖关系。在CNN中,使用卷积滤波器独立地提取输入数据的不同特征,不考虑时间依赖性,处理输入数据的各个部分,并考虑空间信息(与数据中的位置相关的信息)。
自注意力机制可以有效地捕捉句子中单词之间的长期依赖关系和关系。自注意力模型的关键方面是自注意力机制,它允许序列中的每个单词同时关注所有其他单词,并根据它们对特定任务的重要性创建加权表示。换句话说,句子中的每个单词都会考虑所有其他单词来确定其作用和重要性。这种方法使模型能够考虑单词之间的长期关系以及整个句子的长度,而不依赖于特定的词序。总之,自注意力模型通过提供强大的工具来捕获文本数据中的复杂模式,极大地改变了 NLP。
Transformer机制
Transformer 模型使用注意力机制来理解文本结构并做出准确预测。过去,使用逐字翻译方法将句子从一种语言翻译成另一种语言的效果并不好。引入注意力机制是为了在每个时间步骤中从序列的所有元素中收集重要信息并识别它们之间的关系。但这并不意味着模型会一次读取所有句子。
在 Transformer 架构中,模型可以关注每个单词的句子中的所有其他单词,收集信息并据此做出不同的预测。GPT -3大规模使用 Transformer 架构,拥有超过 1750 亿个参数。如此大量的参数使模型能够自我训练并从大量数据中学习,无需人工监督即可识别更复杂的模式。因此,GPT-3自动利用对句子不同元素的注意力来生成复杂文本并执行语义分析。
所有这些模型都利用了空间注意力和层次注意力。在空间注意力中,模型只关注输入或输出的特定部分来生成输出。在层次注意力中,模型在输入或输出的不同层次上调整注意力,为文本的各个组成部分(如单词或句子)分配不同的机会和重要性。通过使用这两种类型的注意力,模型可以识别文本中的重要信息并生成最佳、最全面的输出。
使用预先训练的模型构建 LLM
BERT 和 GPT是两种非常成功的自然语言处理预训练模型。它们可用于各种任务,包括构建 LLM。这些模型可以在大型文本数据上进行训练,以创建具有特定功能的自定义 LLM,用于自然语言处理任务。
虽然我们通常可以访问原始模型(包括其架构和相应的权重),以便有效地将它们用于特定任务,但我们可以使用自己的数据对其进行微调。此过程可提高模型在特定任务上的性能,并且是一种经济高效的构建 LLM 的方法。
例如,如果我们想将GPT模型用作自然语言处理的预训练模型,我们可以通过运行以下代码来获得它。Hugging Face transformers库使我们能够使用相同的代码将大多数预训练模型用于 NLP 任务,例如DistilGPT-2、BERT、RoBERTa、DistilBERT和XLNet。
下面是取自 Hugging Face 网站的两个代码片段,展示了如何以不同方式使用DistilGPT-2模型进行文本生成。
# With pipeline, just specify the task and the model id from the Hub.
from transformers import pipeline
pipe = pipeline("text-generation", model="distilgpt2")
第一种方法涉及使用 transformers 库中的 ` pipeline`类。该类可以轻松使用预先训练的模型,而无需为各种任务(如文本分类、文本翻译、文本生成等)定义或构建它们。要使用此方法,只需将任务类型指定为“text-generation”,并将要使用的模型指定为“ distilgpt2 ”。另一方面,第二种方法在以下代码中描述。
# If you want more control, you will need to define the tokenizer and model.
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("distilgpt2")
model = AutoModelForCausalLM.from_pretrained("distilgpt2")
第二种方法涉及使用“ AutoTokenizer”类加载标记器,然后通过“ from_pretrained”方法加载与DistilGPT-2模型关联的标记器。要加载模型,我们使用“ AutoModelForCausalLM”类。对于需要对模型和标记器进行更多控制的用户,建议使用此方法。
一旦我们运行这些代码,预先训练好的模型就可用了。然后我们可以将文本输入到模型中,并使用以下代码分析其对文本特征的表示。
import torch
# Define your input text
input_text = “Love, her rain-filled eyes towards the blue sky.”
# Tokenize the input text
input_ids = tokenizer.encode(input_text, return_tensors=”pt”)
# Get the model’s output logits
with torch.no_grad():
outputs = model(input_ids)
logits = outputs.logits
# Print the shape of the output logits
print(“Output logits shape:”, logits.shape)
DistilGPT-2模型生成形状为 ` (batch_size,sequence_length,vocab_size) ` 的输出 logit。例如,[1, 12, 50257]表示生成的输出序列长度为 12,词汇量为 50257。
PyTorch和TensorFlow是两个用于构建预训练模型的流行库。虽然这两个库具有相同的架构,但它们在模型的定义和使用方式上有所不同。TensorFlow模型被定义为计算图,具有用于训练和使用模型的特定函数。通常,高级 API(如“ Keras”或“tf.keras ”)用于构建和训练模型。另一方面,PyTorch模型被定义为模块,您可以使用 Python 函数直接管理它们。此外,PyTorch是用于构建和训练模型的主要 API 。
精细调整
在本文中,我们探讨了与文本相关的不同类型的预训练模型,并研究了它们的架构。为了在我们自己的数据集上以及针对我们想要执行的特定任务使用这些模型,我们需要对它们进行微调。微调是训练深度模型(尤其是使用迁移学习的模型)的一个重要概念。
微调涉及调整已在大型数据集上训练的预训练模型,以适应我们用于任务的数据集。通常,我们会冻结模型的顶层,只有较低层的权重可以优化。此过程允许模型从较小的数据集中学习特定模式,同时受益于在较大的预训练数据集中学习到的一般模式。
预训练模型有多种架构和配置。首先,我们必须选择合适的预训练模型并执行上述所有步骤,包括使其参数适应新数据,同时保留训练期间学到的知识。这涉及选择合适的架构、定义特定于任务的目标函数、准备数据集、使用预训练权重初始化模型以及通过迭代优化微调参数。迁移学习、超参数调整和 PEFT(精度高效微调)等技术是此过程的核心。正则化方法和超参数调整可优化性能。
完成上述步骤后,我们会选择一个性能指标来评估微调后的模型,例如准确率、召回率或其他任何适合当前问题的指标。然后,我们会在准备好的数据集上微调模型,通常采用逐个时期或逐批的方法,计算目标函数(例如损失函数)的值并相应地更新模型参数。随后,我们会在评估数据上评估微调后的模型,并计算评估指标以评估最终的模型性能。
由于本文篇幅有限,我没有附上代码来解释微调。不过,很快,我会在另一篇文章中选择一个针对文本数据集的预训练模型,并使用代码逐步指导您完成微调过程。
结论
在本文的第一部分中,我们讨论了主要的预训练文本模型、它们的介绍以及它们的实用性。我们还看到,大型语言模型 (LLM) 现在已成为我们日常生活中不可或缺的一部分,并且正在不断改进。在不久的将来,这些模型将成为我们的个人助理,而搜索引擎的重要性将逐渐减弱。此外,我们了解到,微调这些模型对于优化其性能至关重要。