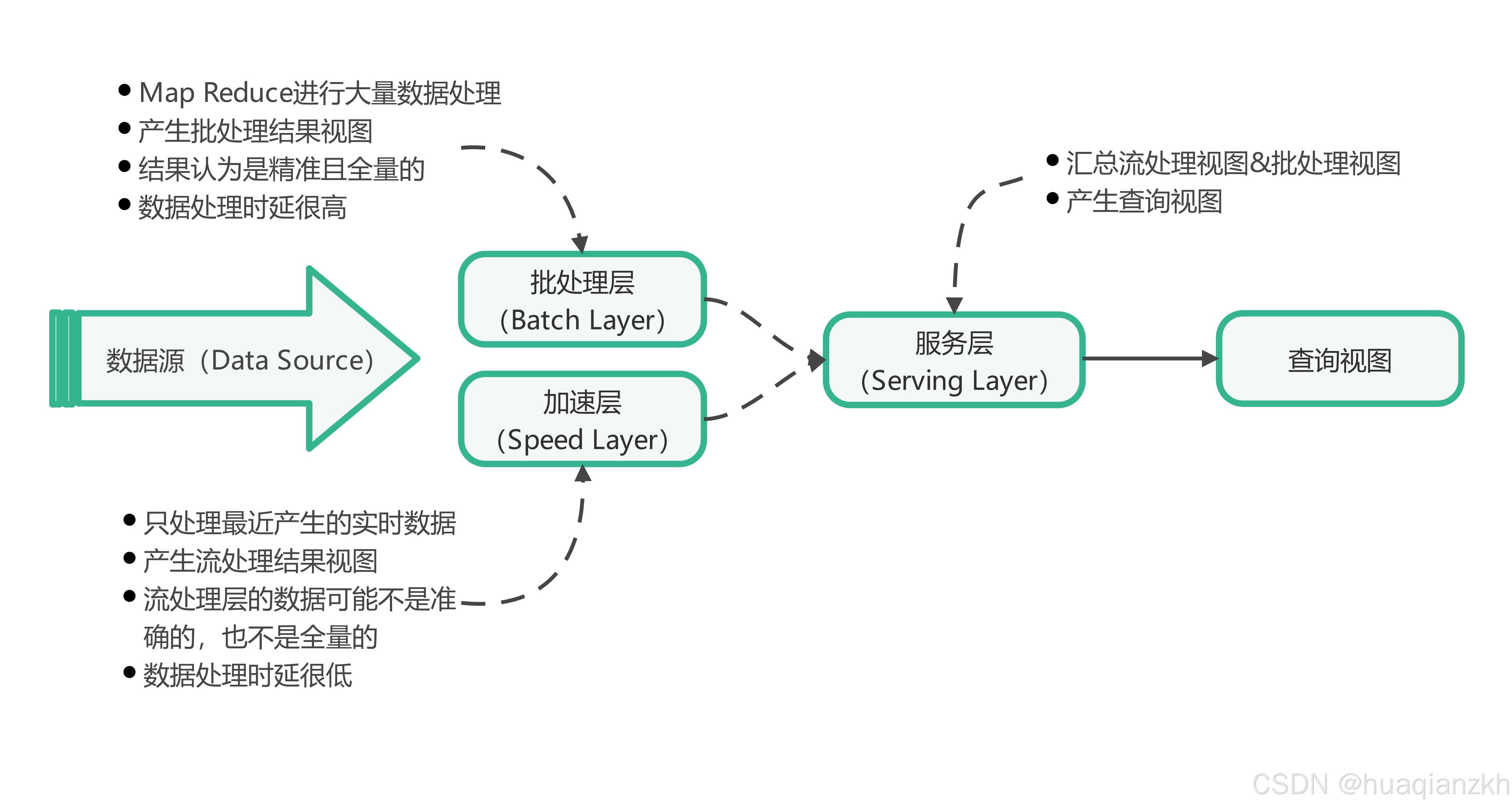
ShardingSphere实战
文章目录
- ShardingSphere实战
- 分库分表实战
- 建表
- 建表sql
- 利用存储过程建表
- Sharding-jdbc分库分表配置
- 基于业务的Sharding-key考虑
- 订单id
- 用户id
- 分片策略
- 订单id的设计与实现
- **设计思想**:
- 设计思路:
- 具体分片策略实现
- 测试数据插入
- 商户
- 商品
- 用户
- 订单和订单详情
- 如何批量新增数据
- Mybatis的批量插入
- 线程池开启多线程执行插入
- 关于查询
- 根据用户Id查询
- 根据订单id查询
- 分页查询模拟
- 有分片键的情况
- 无分片键的情况
- 全局查询法
- 禁止跳跃查询
- 商户端查询
- 索引法(冗余)
- ES异构
系统每日数据增量庞大,如何解决庞大数据带来的数据库性能瓶颈?
假设现在系统初始设计日增量十万,而数据是每半年做一次归档。则半年内,数据能达到180 * 10W = 1800W。
当系统运行到一定时间后,日增量达到一百万,则半年内数据达到180 * 100W =18000W,也就是1.8个亿。
这么庞大的数据量,单表无法承受那么大压力。这个时候就要考虑分库分表了。假设保持单表数据最多100W的情况下,这需要180张表容纳下这半年的数据。
分库分表实战
建表
为了模拟广播表和绑定表,选用Mysql数据库,这里共设计了5张表,分别为
-
用户表: user,这里设置成广播表,实际用户数量庞大,需要分表
-
商户表:business 这里设置成广播表
-
商品表: product 这里设置成广播表
-
订单表:orders 主要数据表,需要分表,需要根据用户Id和订单Id进行分片策略分表
-
订单详情表: order_items 主要数据表,需要分表,和订单表orders是绑定表关系,根据用户Id和订单Id进行分片策略分表。
演示共准备了三个数据库,orders和order_items均分成0…31,分别共3*32=96张表。
建表sql
各表类型字段如下:
-- 商品表,模拟广播表
create table product(
product_id bigint primary key,
product_name varchar(255)
);
-- 用户表,暂时不分表,模拟广播表
create table user(
user_id BIGINT PRIMARY KEY,
user_name varchar(55) not null
);
-- 商户表,分表
create table business(
business_id bigint primary key,
business_name varchar(255) not null
);
-- 订单表,分库分表,和订单详情表是绑定表
CREATE TABLE orders (
order_id BIGINT PRIMARY KEY,
user_id BIGINT,
business_id BIGINT,
order_date DATE
);
-- 订单详情表,分库分表
CREATE TABLE order_items (
item_id BIGINT PRIMARY KEY,
order_id BIGINT,
product_id BIGINT
);
利用存储过程建表
分别在三个数据库中执行以下sql语句
drop database IF EXISTS shardingdb ;
create database shardingdb;
use shardingdb;
-- 商品表,模拟广播表
create table product(
product_id bigint primary key,
product_name varchar(255)
);
-- 用户表,暂时不分表,模拟广播表
create table user(
user_id BIGINT PRIMARY KEY,
user_name varchar(55) not null
);
-- 商户表,暂时不分表,模拟广播表
create table business(
business_id bigint primary key,
business_name varchar(255) not null
);
-- 如果存储过程已存在,先删除
DROP PROCEDURE IF EXISTS `createTables`;
CREATE PROCEDURE `createTables`()
BEGIN
DECLARE `@i` int(11);
DECLARE `@createSql` VARCHAR(2560);
DECLARE `@createIndexSql1` VARCHAR(2560);
DECLARE `@createIndexSql2` VARCHAR(2560);
DECLARE `@createIndexSql3` VARCHAR(2560);
set `@i`=0;
WHILE `@i`<=31 DO
SET @createSql = CONCAT('CREATE TABLE IF NOT EXISTS orders_',`@i`,'(
`order_id` BIGINT NOT NULL COMMENT \'订单id\',
`user_id` BIGINT COMMENT \'用户名\',
`business_id` BIGINT COMMENT \'商户id\',
`order_date` date,
PRIMARY KEY (`order_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin');
prepare stmt from @createSql;
execute stmt;
SET `@i`= `@i`+1;
END WHILE;
END;
-- 如果存储过程已存在,先删除
DROP PROCEDURE IF EXISTS `createTables2`;
CREATE PROCEDURE `createTables2`()
BEGIN
DECLARE `@i` int(11);
DECLARE `@createSql` VARCHAR(2560);
DECLARE `@createIndexSql1` VARCHAR(2560);
DECLARE `@createIndexSql2` VARCHAR(2560);
DECLARE `@createIndexSql3` VARCHAR(2560);
set `@i`=0;
WHILE `@i`<=31 DO
SET @createSql = CONCAT('CREATE TABLE IF NOT EXISTS order_items_',`@i`,'(
`item_id` BIGINT NOT NULL COMMENT \'订单详情id\',
`order_id` BIGINT COMMENT \'订单id\',
`user_id` BIGINT COMMENT \'用户id\',
`product_id` BIGINT COMMENT \'商户id\',
PRIMARY KEY (`item_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin');
prepare stmt from @createSql;
execute stmt;
SET `@i`= `@i`+1;
END WHILE;
END;
-- 查询存储过程
SHOW CREATE PROCEDURE `createTables`;
-- 调用存储过程创建表
CALL createTables();
-- 查询存储过程
SHOW CREATE PROCEDURE `createTables2`;
-- 调用存储过程创建表
CALL createTables2();
注意:由于我是用navicat直接执行,所以没有分隔符语句,如果需要在mysql命令行执行,则需要定义分隔符,如何定义分隔符,利用DELIMITER $$,替代mysql默认的分号作为分隔符。这在创建存储过程的时候,防止存储过程语句中的;结尾被mysql直接判定语句结束,并执行。。
最终表创建结果如下:

Sharding-jdbc分库分表配置
- 创建springboot应用,并引入以下依赖
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.23</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.3.2</version>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.1.1</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>
- 分别创建entity实体和对应的mapper,具体代码就不列出来了。

- 分库分表配置
- 配置m1,m2,m3三个数据源
- 配置广播表user,business,product
- 配置分片表orders,order_items,并配置绑定关系
spring:
shardingsphere:
datasource:
names: m1,m2,m3
m1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://47.109.94.124:3306/shardingdb?serverTimezone=UTC&useSSL=false&allowPublicKeyRetrieval=true
username: root
password: 123456
m2:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://47.109.188.99:3306/shardingdb?serverTimezone=UTC&useSSL=false&allowPublicKeyRetrieval=true
username: root
password: 123456
m3:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.56.102:3306/shardingdb?serverTimezone=UTC&useSSL=false&allowPublicKeyRetrieval=true
username: root
password: 123456
sharding:
tables:
user:
actual-data-nodes: m1.user,m2.user,m3.user
product:
actual-data-nodes: m1.product,m2.product,m3.product
business:
actual-data-nodes: m1.business,m2.business,m3.business
orders:
actual-data-nodes: m$->{1..3}.orders_$->{0..31}
database-strategy:
complex:
sharding-columns: order_id,user_id
algorithm-class-name: cn.axj.sharding.ShardingAlgorithmConfig.OrdersDatabaseComplexAlgorithm
table-strategy:
complex:
sharding-columns: order_id,user_id
algorithm-class-name: cn.axj.sharding.ShardingAlgorithmConfig.OrdersTableComplexAlgorithm
order_items:
actual-data-nodes: m$->{1..3}.order_items_$->{0..31}
key-generator:
column: item_id
type: SNOWFLAKE
props:
worker:
id: 1
database-strategy:
complex:
sharding-columns: order_id,user_id
algorithm-class-name: cn.axj.sharding.ShardingAlgorithmConfig.OrdersDatabaseComplexAlgorithm
table-strategy:
complex:
sharding-columns: order_id,user_id
algorithm-class-name: cn.axj.sharding.ShardingAlgorithmConfig.OrdersTableComplexAlgorithm
broadcast-tables:
- user
- product
- business
binding-tables:
- orders,order_items
props:
sql:
#开启sp sql日志
show: true
分片策略下面讲
基于业务的Sharding-key考虑
订单id
若根据订单id查询订单,则可以直接将订单id作为分片键,这样通过订单id查询订单的时候,会快速定位到当前订单id归档的表中去。
有一种场景,用户需要查询自己所有的订单,这个时候没有订单id,怎么快速查询到单个用户的订单?如果只用订单id作为分片键,则这种情况势必要进行全库全表扫描。
用户id
用户端,用户在查询自己订单的时候,需要的就是性能,不可能从忙忙分表中查询用户的订单。
如果直接将用户id作为分片键,则单个用户所有的订单,会落到某一个库某一张表中去。这样解决了用户端查询自己订单。
当用户想根据订单id去查询的时候呢?如果只根据用户id去分片,则通过订单id查询的时候,势必要全表去扫描。
分片策略
通过将用户id集成到订单id中,可以解决通过用户id查询和订单id查询的问题。
具体实现
- 具体的分片逻辑是使用用户id进行分片。
- 当使用用户id查询的时候,可以快速定位到数据表
- 当使用订单id的时候,解析出用户id,也可以快速定位到数据表。
- 采用ShardingSphere的复合模式,使用用户id和订单id作为分片键
订单id的设计与实现
设计思想:
设计一个64位的唯一ID,包含时间戳、用户ID和序列号,同时确保生成的ID不为负数。
设计思路:
-
时间戳部分(22位): 使用毫秒级时间戳,并确保时间戳足够长以覆盖你预期的时间范围。
-
用户ID部分(32位): 用户ID需要占据较大的位数,以保证足够的唯一性。32位的用户id可以容纳40多亿的用户,已经足够使用,具体根据系统的预期,可以将时间戳和用户id对应的位数进行调整。
-
序列号部分(12位): 序列号用于解决同一毫秒内生成多个ID时的唯一性问题。12位的序列号表示,能生成4096个不同的订单id,这里生成规则不能和用户id绑定,应该是所有的用户共享。
-
确保ID非负数: 使用无符号数或者适当的移位操作确保生成的ID不为负数。
-
解析用户id:需要通过订单id,解析出用户的id
订单id生成规则如下:
package cn.axj.sharding.util;
/**
* @author aoxiaojun
* @date 2024/7/5 10:43
**/
public class OrderGenerator {
// 起始时间戳,可以根据需要设置
private static final long EPOCH = 1625097600000L; // 2021-07-01 00:00:00 UTC
// 每部分占据的位数
private static final int TIMESTAMP_BITS = 22;
private static final int USER_ID_BITS = 32;
private static final int SEQUENCE_BITS = 12;
// 最大值
private static final long MAX_USER_ID = (1L << USER_ID_BITS) - 1;
private static final long MAX_SEQUENCE = (1L << SEQUENCE_BITS) - 1;
// 位偏移量
private static final int USER_ID_SHIFT = SEQUENCE_BITS;
private static final int TIMESTAMP_SHIFT = USER_ID_BITS + SEQUENCE_BITS;
// 上次生成ID的时间戳
private static long lastTimestamp = -1L;
// 当前序列号
private static long sequence = 0L;
// 生成唯一ID
public static synchronized long generateUniqueId(long userId) {
long currentTimestamp = System.currentTimeMillis();
if (currentTimestamp < lastTimestamp) {
throw new RuntimeException("Clock moved backwards. Refusing to generate ID.");
}
if (lastTimestamp == currentTimestamp) {
sequence = (sequence + 1) & MAX_SEQUENCE;
if (sequence == 0) {
// 序列号溢出,等待下一个毫秒
currentTimestamp = waitNextMillis(lastTimestamp);
}
} else {
sequence = 0L; // 重置序列号
}
lastTimestamp = currentTimestamp;
long timestamp = currentTimestamp - EPOCH;
// 移位操作组合生成ID
long uniqueId = (timestamp << TIMESTAMP_SHIFT) | (userId << USER_ID_SHIFT) | sequence;
return uniqueId & Long.MAX_VALUE; // 确保ID非负数
}
// 解析用户ID
public static long getUserIdFromUniqueId(long uniqueId) {
return (uniqueId >> USER_ID_SHIFT) & MAX_USER_ID;
}
// 等待直到下一个毫秒
private static long waitNextMillis(long lastTimestamp) {
long currentTimestamp = System.currentTimeMillis();
while (currentTimestamp <= lastTimestamp) {
currentTimestamp = System.currentTimeMillis();
}
return currentTimestamp;
}
public static void main(String[] args) {
long userId = 1234567890L;
long uniqueId = generateUniqueId(userId);
System.out.println("Generated Unique ID: " + uniqueId);
long parsedUserId = getUserIdFromUniqueId(uniqueId);
System.out.println("Parsed User ID: " + parsedUserId);
}
}
用户id的生成规则如下:
public class DistributedUserIDGenerator {
private static final long EPOCH = 1625097600000L; // 2021-07-01 00:00:00 UTC
private static final int RANDOM_BITS = 32 - 13; // Use 13 bits for timestamp (enough until 2136)
private static final SecureRandom random = new SecureRandom();
public static long generateUserId() {
// Current timestamp in milliseconds
long currentTimestamp = System.currentTimeMillis();
// Convert timestamp to seconds since epoch
long secondsSinceEpoch = (currentTimestamp - EPOCH) / 1000;
// Generate random bits
int randomBits = random.nextInt(1 << RANDOM_BITS);
// Combine timestamp and random bits
long userId = (secondsSinceEpoch << RANDOM_BITS) | randomBits;
return userId & Long.MAX_VALUE; // Ensure non-negative user ID
}
public static void main(String[] args) {
long userId = generateUserId();
System.out.println("Generated Distributed User ID: " + userId);
}
}
具体分片策略实现
- Orders和order_items的分库策略实现逻辑,根据用户id或者通过订单id解析出用户id,通过对用户id取数据源数量的模+1,可以分片到不同的数据源中。
public class OrdersDatabaseComplexAlgorithm implements ComplexKeysShardingAlgorithm<Long> {
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, ComplexKeysShardingValue<Long> complexKeysShardingValue) {
Long orderId = null;
Collection<Long> orderId1 = complexKeysShardingValue.getColumnNameAndShardingValuesMap().get("order_id");
if(!CollectionUtils.isEmpty(orderId1)){
orderId = orderId1.iterator().next();
}
Long userId = null;
Collection<Long> userIdColl = complexKeysShardingValue.getColumnNameAndShardingValuesMap().get("user_id");
if(!CollectionUtils.isEmpty(userIdColl)){
userId = userIdColl.iterator().next();
}
//如果要根据用户去查找所有的订单,怎么办?
//select * from orders where user_id = ?
//orderId和用户id
if(Objects.nonNull(userId)) {
String dataSourceName = "m" + ((userId) % availableTargetNames.size() + 1);
for (String targetName : availableTargetNames) {
if (targetName.endsWith(dataSourceName)) {
return Collections.singleton(targetName); // 返回匹配的数据库名
}
}
}
if(orderId != null){
//截取orderId中的userId信息
//截取orderId中的userId信息
userId = OrderGenerator.getUserIdFromUniqueId(orderId);
String dataSourceName = "m" + ((userId) % availableTargetNames.size() + 1);
for (String targetName : availableTargetNames) {
if (targetName.endsWith(dataSourceName)) {
return Collections.singleton(targetName); // 返回匹配的数据库名
}
}
}
Map<String, Range<Long>> columnNameAndRangeValuesMap = complexKeysShardingValue.getColumnNameAndRangeValuesMap();
Range<Long> range = columnNameAndRangeValuesMap.get("order_id");
if(Objects.nonNull(range)){
return availableTargetNames;
}
throw new IllegalArgumentException("No precise sharding available for " + complexKeysShardingValue);
}
}
- Orders和order_items的分库策略实现逻辑,根据用户id或者通过订单id解析出用户id,通过对用户id取所有的分表数量的模,可以分片到不同的数据表中。
public class OrdersTableComplexAlgorithm implements ComplexKeysShardingAlgorithm<Long> {
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, ComplexKeysShardingValue<Long> complexKeysShardingValue) {
Long orderId = null;
Collection<Long> orderId1 = complexKeysShardingValue.getColumnNameAndShardingValuesMap().get("order_id");
if(!CollectionUtils.isEmpty(orderId1)){
orderId = orderId1.iterator().next();
}
Long userId = null;
Collection<Long> userIdColl = complexKeysShardingValue.getColumnNameAndShardingValuesMap().get("user_id");
if(!CollectionUtils.isEmpty(userIdColl)){
userId = userIdColl.iterator().next();
}
if(userId != null){
String tableName = complexKeysShardingValue.getLogicTableName() + "_" + ((userId) % availableTargetNames.size());
if(availableTargetNames.contains(tableName)){
return Collections.singleton(tableName);
}
}
if(orderId != null){
//截取orderId中的userId信息
userId = OrderGenerator.getUserIdFromUniqueId(orderId);
String tableName = complexKeysShardingValue.getLogicTableName() + "_" + ((userId) % availableTargetNames.size());
if(availableTargetNames.contains(tableName)){
return Collections.singleton(tableName);
}
}
Map<String, Range<Long>> columnNameAndRangeValuesMap = complexKeysShardingValue.getColumnNameAndRangeValuesMap();
Range<Long> range = columnNameAndRangeValuesMap.get("order_id");
if(Objects.nonNull(range)){
return availableTargetNames;
}
throw new IllegalArgumentException("No precise sharding available for " + complexKeysShardingValue);
}
}
至此,分库分表相关逻辑已经完成。
测试数据插入
商户
模拟200个商户,并直接插入
@SpringBootTest
@RunWith(SpringRunner.class)
public class BusienssTest {
@Resource
private BusinessMapper businessMapper;
@Test
public void addBusiness(){
for (int i = 0; i < 200; i++) {
Business business = new Business();
business.setBusinessId(i+2L);
business.setBusinessName("商户" + i + 2);
businessMapper.insert(business);
}
}
}
由于广播表的缘故,所有的库中都会插入
商品
模拟20个商品,并插入
@SpringBootTest
@RunWith(SpringRunner.class)
public class ProductTest {
@Resource
private ProductMapper productMapper;
@Test
public void addProduct(){
for (int i = 0; i < 20; i++) {
Product product = new Product();
product.setProductId(i + 2L);
product.setProductName("测试商品" + i+2);
productMapper.insert(product);
}
}
}
由于广播表的缘故,所有的库中都会插入
用户
模拟插入10000个用户
@SpringBootTest
@RunWith(SpringRunner.class)
public class UserTest {
@Resource
private UserMapper userMapper;
@Test
public void addUser(){
for (int i = 0; i <10000; i++) {
User user = new User();
user.setUserId(DistributedUserIDGenerator.generateUserId());
user.setUsername("用户" + 5000 + i);
userMapper.insert(user);
}
}
@Test
public void queryUser(){
QueryWrapper<User> userQueryWrapper = new QueryWrapper<>();
List<User> users = userMapper.selectList(userQueryWrapper);
System.out.println(users.size());
}
}
由于广播表的缘故,所有的库中都会插入
订单和订单详情
利用mapper.insert形式插入1000条数据
@Test
public void forInsertOrders(){
QueryWrapper<User> userQueryWrapper = new QueryWrapper<>();
List<User> users = userMapper.selectList(userQueryWrapper);
QueryWrapper<Product> productQueryWrapper = new QueryWrapper<>();
List<Product> products = productMapper.selectList(productQueryWrapper);
QueryWrapper<Business> businessQueryWrapper = new QueryWrapper<>();
List<Business> businesses = businessMapper.selectList(businessQueryWrapper);
long l = System.currentTimeMillis();
int total = 1000;
for (int i = 0; i < total; i++) {
Orders orders = new Orders();
int iusers = ThreadLocalRandom.current().nextInt(users.size());
orders.setUserId(users.get(iusers).getUserId());
orders.setOrderId(OrderGenerator.generateUniqueId(users.get(iusers).getUserId()));
int lbusiness = ThreadLocalRandom.current().nextInt(0, businesses.size());
orders.setBusinessId(businesses.get(lbusiness).getBusinessId());
orders.setOrderDate(new Date());
Long orderId = orders.getOrderId();
OrderItems orderItems = new OrderItems();
orderItems.setOrderId(orderId);
orderItems.setUserId(users.get(iusers).getUserId());
int lproduct = ThreadLocalRandom.current().nextInt(0, products.size());
orderItems.setProductId(products.get(lproduct).getProductId());
ordersMapper.insert(orders);
orderItemsMapper.insert(orderItems);
}
System.out.println("利用Mybatis insert插入"+total+"数据,耗时:" + (System.currentTimeMillis() - l));
}
利用Mybatis insert插入1000数据,耗时:80649
可以看到通过mapper.insert的方式直接插入,仅仅1000条就需要80秒之多。这在大批量插入数据的时候,简直是要折磨死人。
这是因为mapper.insert每次执行都需要反反复复去获取数据库连接,并关闭数据库连接,这是非常耗时的。
如何批量新增数据
Mybatis的批量插入
利用Mybatis的sqlSessionFactory开启执行批处理命令,打包所有的命令,并获取一次数据库连接,一次执行,最后commit的方式,可以有效的降低数据库连接获取和关闭消耗的时间
@Test
public void batchInsertBySqlSession(){
QueryWrapper<User> userQueryWrapper = new QueryWrapper<>();
List<User> users = userMapper.selectList(userQueryWrapper);
QueryWrapper<Product> productQueryWrapper = new QueryWrapper<>();
List<Product> products = productMapper.selectList(productQueryWrapper);
QueryWrapper<Business> businessQueryWrapper = new QueryWrapper<>();
List<Business> businesses = businessMapper.selectList(businessQueryWrapper);
long l = System.currentTimeMillis();
int total = 1000;
List<Orders> ordersList = new ArrayList<>();
List<OrderItems> orderItemsList = new ArrayList<>();
for (int i = 0; i < total; i++) {
Orders orders = new Orders();
int iusers = ThreadLocalRandom.current().nextInt(users.size());
orders.setUserId(users.get(iusers).getUserId());
orders.setOrderId(OrderGenerator.generateUniqueId(users.get(iusers).getUserId()));
int lbusiness = ThreadLocalRandom.current().nextInt(0, businesses.size());
orders.setBusinessId(businesses.get(lbusiness).getBusinessId());
orders.setOrderDate(new Date());
Long orderId = orders.getOrderId();
OrderItems orderItems = new OrderItems();
orderItems.setOrderId(orderId);
orderItems.setUserId(users.get(iusers).getUserId());
int lproduct = ThreadLocalRandom.current().nextInt(0, products.size());
orderItems.setProductId(products.get(lproduct).getProductId());
ordersList.add(orders);
orderItemsList.add(orderItems);
}
try (SqlSession sqlSession = sqlSessionFactory.openSession(ExecutorType.BATCH)) {
OrdersMapper ordersMapper1 = sqlSession.getMapper(OrdersMapper.class);
OrderItemsMapper orderItemsMapper1 = sqlSession.getMapper(OrderItemsMapper.class);
for (Orders orders : ordersList) {
ordersMapper1.insert(orders);
}
for (OrderItems orderItems : orderItemsList) {
orderItemsMapper1.insert(orderItems);
}
sqlSession.commit();
}
System.out.println("利用Mybatis 批处理插入"+total+"数据,耗时:" + (System.currentTimeMillis() - l));
}
利用Mybatis 批处理插入1000数据,耗时:11085
利用批处理,插入1000条数据,耗时11秒。比之前的80秒有很大的提升
线程池开启多线程执行插入
利用线程池,当订单数量达到一个特定的值,开启新线程执行插入数据。这样可以将特定的订单,分成多个任务同步执行插入
- 构建线程池
@Component
public class ThreadPool {
private ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(10,48,60, TimeUnit.SECONDS, new LinkedBlockingQueue<>(1000));
public void execute(Runnable command){
threadPoolExecutor.execute(command);
}
public void shutdown(){
threadPoolExecutor.shutdown();
}
/**
* 等待所有的任务执行关闭
*/
public void awaitTermination(){
try {
threadPoolExecutor.awaitTermination(Long.MAX_VALUE, TimeUnit.NANOSECONDS);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
- 构建插入批量插入任务
private static class BatchInsertTask implements Runnable {
private final List<Orders> ordersList;
private final List<OrderItems> orderItemsList;
public BatchInsertTask(List<Orders> ordersList, List<OrderItems> orderItemsList) {
this.ordersList = ordersList;
this.orderItemsList = orderItemsList;
}
@Override
public void run() {
// 在这里执行批量插入操作
// ...
try (SqlSession sqlSession = sqlSessionFactory.openSession(ExecutorType.BATCH)) {
OrdersMapper ordersMapper1 = sqlSession.getMapper(OrdersMapper.class);
OrderItemsMapper orderItemsMapper1 = sqlSession.getMapper(OrderItemsMapper.class);
for (Orders orders : ordersList) {
ordersMapper1.insert(orders);
}
for (OrderItems orderItems : orderItemsList) {
orderItemsMapper1.insert(orderItems);
}
sqlSession.commit();
}
}
}
- 执行插入
public class CopyUtils {
// 深拷贝列表方法:通过序列化和反序列化实现
public static <T extends Serializable> List<T> deepCopyList(List<T> originalList) throws IOException, ClassNotFoundException {
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bos);
oos.writeObject(originalList);
oos.flush();
oos.close();
ByteArrayInputStream bis = new ByteArrayInputStream(bos.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bis);
@SuppressWarnings("unchecked")
List<T> copiedList = (List<T>) ois.readObject();
ois.close();
return copiedList;
}
}
@Test
public void batchInsertOrders() throws IOException, ClassNotFoundException {
QueryWrapper<User> userQueryWrapper = new QueryWrapper<>();
List<User> users = userMapper.selectList(userQueryWrapper);
QueryWrapper<Product> productQueryWrapper = new QueryWrapper<>();
List<Product> products = productMapper.selectList(productQueryWrapper);
QueryWrapper<Business> businessQueryWrapper = new QueryWrapper<>();
List<Business> businesses = businessMapper.selectList(businessQueryWrapper);
List<Orders> ordersList = new ArrayList<>();
List<OrderItems> orderItemsList = new ArrayList<>();
int total = 1000;
long start = System.currentTimeMillis();
for (int i = 1; i <= total; i++) {
Orders orders = new Orders();
int iusers = ThreadLocalRandom.current().nextInt(users.size());
orders.setUserId(users.get(iusers).getUserId());
orders.setOrderId(OrderGenerator.generateUniqueId(users.get(iusers).getUserId()));
int lbusiness = ThreadLocalRandom.current().nextInt(0, businesses.size());
orders.setBusinessId(businesses.get(lbusiness).getBusinessId());
orders.setOrderDate(new Date());
ordersList.add(orders);
Long orderId = orders.getOrderId();
OrderItems orderItems = new OrderItems();
orderItems.setOrderId(orderId);
orderItems.setUserId(users.get(iusers).getUserId());
int l = ThreadLocalRandom.current().nextInt(0, products.size());
orderItems.setProductId(products.get(l).getProductId());
orderItemsList.add(orderItems);
if(i % 100 == 0){
//这里需要用到对象的深拷贝
List<Orders> ordersNewList = CopyUtils.deepCopyList(ordersList);
List<OrderItems> orderItemsNewList = CopyUtils.deepCopyList(orderItemsList);
threadPool.execute(new BatchInsertTask(ordersNewList, orderItemsNewList));
ordersList = new ArrayList<>();
orderItemsList = new ArrayList<>();
}
}
//等待线程池执行完毕
threadPool.shutdown();
threadPool.awaitTermination();
System.out.println("利用线程池结合Mybatis 批处理插入"+total+"数据,耗时:" + (System.currentTimeMillis() - start));
}
利用线程池结合Mybatis 批处理插入1000数据,耗时:4399
可以看到插入耗时,4秒多,比之前又提升了不少。
里面有个深拷贝代码如下
测试插入10000条,分十次执行需要耗时(24秒多)
利用线程池结合Mybatis 批处理插入10000数据,耗时:24984
关于查询
准备好700万的订单数据,平均每张表在7万多点。
根据用户Id查询
@Test
public void queryByUser(){
long start = System.currentTimeMillis();
QueryWrapper<Orders> ordersQueryWrapper = new QueryWrapper<>();
ordersQueryWrapper.eq("user_id", 49839282348229L);
List<Orders> orders = ordersMapper.selectList(ordersQueryWrapper);
System.out.println("花费时间 : \t" + (System.currentTimeMillis() - start));
for (Orders order : orders) {
System.out.println(order);
}
}
2024-07-06 02:07:27.131 INFO 14108 --- [ main] ShardingSphere-SQL : Logic SQL: SELECT order_id,user_id,business_id,order_date FROM orders
WHERE (user_id = ?)
2024-07-06 02:07:27.131 INFO 14108 --- [ main] ShardingSphere-SQL : Actual SQL: m2 ::: SELECT order_id,user_id,business_id,order_date FROM orders_5
WHERE (user_id = ?) ::: [49839282348229]
花费时间 : 728
根据ShardingSphere日志,可以看到通过用户Id去查询的时候,会精准定位到m2,orders_5表中查询,查询耗时728毫秒
根据订单id查询
@Test
public void queryByOrderId(){
long l = System.currentTimeMillis();
QueryWrapper<Orders> ordersQueryWrapper = new QueryWrapper<>();
ordersQueryWrapper.eq("order_id", 2700119196034437376L);
List<Orders> orders = ordersMapper.selectList(ordersQueryWrapper);
System.out.println("花费时间 : \t" + (System.currentTimeMillis() - l));
for (Orders order : orders) {
System.out.println(order);
}
}
2024-07-06 02:09:31.991 INFO 5560 --- [ main] ShardingSphere-SQL : Logic SQL: SELECT order_id,user_id,business_id,order_date FROM orders
WHERE (order_id = ?)
2024-07-06 02:09:31.992 INFO 5560 --- [ main] ShardingSphere-SQL : Actual SQL: m3 ::: SELECT order_id,user_id,business_id,order_date FROM orders_9
WHERE (order_id = ?) ::: [2700119196034437376]
花费时间 : 661
根据ShardingSphere日志,可以看到通过订单Id去查询的时候,会精准定位到m3,orders_9表中查询,并且查询花费661毫秒
分页查询模拟
模拟对order_id排序后,进行分页查询
有分片键的情况
public interface OrdersMapper extends BaseMapper<Orders> {
@Select("select * from orders where user_id = #{userId} order by order_id limit #{limit} offset #{offset}")
List<Orders> queryByUserIdAndPage(@Param("limit") int limit, @Param("offset") int offset, @Param("userId") Long userId);
@Select("select * from orders order by order_id limit #{limit} offset #{offset}")
List<Orders> query(@Param("limit") int limit, @Param("offset") int offset);
}
在通过用户id进行分页查询的时候
@Test
public void queryByUserIdAndPage(){
long start = System.currentTimeMillis();
List<Orders> orders = ordersMapper.queryByUserIdAndPage(10, 0, 49839282348229L);
for (Orders order : orders) {
System.out.println(order);
}
}
2024-07-06 02:15:37.537 INFO 14288 --- [ main] ShardingSphere-SQL : Actual SQL: m2 ::: select * from orders_5 where user_id = ? order by order_id limit ? offset ? ::: [49839282348229, 10, 0]
2024-07-06 02:13:45.792 INFO 12584 --- [ main] ShardingSphere-SQL : Actual SQL: m2 ::: select * from orders_5 where user_id = ? order by order_id limit ? offset ? ::: [49839282348229, 10, 10]
可以看到,在有分片键的情况下,分页是正常的单表分页查询
无分片键的情况
全局查询法
就是将所有数据按照一定的规则进行查询,最后聚合,筛选出需要的数据。
@Test
public void query(){
long l = System.currentTimeMillis();
List<Orders> orders = ordersMapper.query(10, 0);
System.out.println("花费时间 : \t" + (System.currentTimeMillis() - l));
for (Orders order : orders) {
System.out.println(order);
}
}
- 在查询10条,偏移量为0的时候,
2024-07-06 02:17:47.746 INFO 32340 --- [ main] ShardingSphere-SQL : Actual SQL: m1 ::: select * from orders_0 order by order_id limit ? offset ? ::: [10, 0]
2024-07-06 02:17:47.746 INFO 32340 --- [ main] ShardingSphere-SQL : Actual SQL: m1 ::: select * from orders_1 order by order_id limit ? offset ? ::: [10, 0]
2024-07-06 02:17:47.746 INFO 32340 --- [ main] ShardingSphere-SQL : Actual SQL: m1 ::: select * from orders_2 order by order_id limit ? offset ? ::: [10, 0]
.....
2024-07-06 02:17:47.747 INFO 32340 --- [ main] ShardingSphere-SQL : Actual SQL: m1 ::: select * from orders_31 order by order_id limit ? offset ? ::: [10, 0]
2024-07-06 02:17:47.747 INFO 32340 --- [ main] ShardingSphere-SQL : Actual SQL: m2 ::: select * from orders_0 order by order_id limit ? offset ? ::: [10, 0]
from orders_2 order by order_id limit ? offset ? ::: [10, 0]
2024-07-06 02:17:47.747 INFO 32340 --- [ main] ShardingSphere-SQL : Actual SQL: m2 ::: select * from orders_29 order by order_id limit ? offset ? ::: [10, 0]
...
...
2024-07-06 02:17:47.749 INFO 32340 --- [ main] ShardingSphere-SQL : Actual SQL: m3 ::: select * from orders_30 order by order_id limit ? offset ? ::: [10, 0]
2024-07-06 02:17:47.749 INFO 32340 --- [ main] ShardingSphere-SQL : Actual SQL: m3 ::: select * from orders_31 order by order_id limit ? offset ? ::: [10, 0]
花费时间 : 888
对每一张orders表进行偏移量为0,limit为10的查询,最后通过对每一张表取出的数据进行排序,选出最小的十条数据进行返回
花费时间 888毫秒,看起来还好
- 在查询10条,偏移量为10的时候,情况如下
对每一张orders表进行偏移量为0,limit为20的查询,最后通过对每一张表取出的数据进行排序,选出偏移量为10,limit为10的十条数据进行返回
这是为什么呢?为什么会取每张表的前20条数据进行汇总呢?
这是由于分表的缘故,由于是偏移量10,取10条,这十条数据不能保证不在同一张表中,而为啥从偏移量0开始取呢?那是因为这十条数据中的某一条都有可能在0-10这个区间中。
花费时间 814毫秒,看起来还好。
当分页达到很大值的时候,也就是偏移量很大的情况下,这种方式会取出所有的偏移量之前的数据,再进行排序。这样时间耗费就会上来了
- 偏移量在50000的情况下
2024-07-06 02:27:24.316 INFO 17864 --- [ main] ShardingSphere-SQL : Actual SQL: m3 ::: select * from orders_31 order by order_id limit ? offset ? ::: [50010, 0]
花费时间 : 12899
可以看到,时间花费达到了惊人的12秒多。
全局查询法弊端:
- 页码增加后,查询效率会非常低
- 页码增加后,查询出来的数据量庞大,需要对数据进行二次排序。对内存和cpu要求也非常高。
禁止跳跃查询
为了解决全局查询法当页码很大,需要查询出庞大的数据,进行排序的痛点。
禁止跳跃查询就是在排序规则确定后,用上一页某个排序字段的最大或者最小值,作为下一页的查询条件。这样查询的数据会固定在一个limit的值。
如查询
@Select("select * from orders where order_id > #{orderMin} order by order_id limit #{limit} offset #{offset}")
List<Orders> queryProhibit(@Param("limit") int limit, @Param("offset") int offset,@Param("orderMin") Long orderMin);
首先从第一页开始查询
@Test
public void queryProhibitPage(){
long l = System.currentTimeMillis();
List<Orders> orders = ordersMapper.queryProhibit(10, 0,0L);
System.out.println("花费时间 : \t" + (System.currentTimeMillis() - l));
for (Orders order : orders) {
System.out.println(order);
}
}
结果
Orders(orderId=1289014780911571066, userId=30533477, businessId=63, orderDate=Fri Jul 05 00:00:00 CST 2024)
Orders(orderId=1289014788336590870, userId=32346226, businessId=159, orderDate=Fri Jul 05 00:00:00 CST 2024)
Orders(orderId=1289015043814797343, userId=94718835, businessId=184, orderDate=Fri Jul 05 00:00:00 CST 2024)
Orders(orderId=1289015212125704194, userId=135810365, businessId=146, orderDate=Fri Jul 05 00:00:00 CST 2024)
Orders(orderId=1289015307747590238, userId=159155552, businessId=110, orderDate=Fri Jul 05 00:00:00 CST 2024)
Orders(orderId=1289015356776222844, userId=171125433, businessId=104, orderDate=Fri Jul 05 00:00:00 CST 2024)
Orders(orderId=1289015389011095558, userId=178995275, businessId=75, orderDate=Fri Jul 05 00:00:00 CST 2024)
Orders(orderId=1289015446032207967, userId=192916445, businessId=85, orderDate=Fri Jul 05 00:00:00 CST 2024)
Orders(orderId=1289015457140670521, userId=195628472, businessId=167, orderDate=Fri Jul 05 00:00:00 CST 2024)
Orders(orderId=1289015523201130581, userId=211756514, businessId=195, orderDate=Fri Jul 05 00:00:00 CST 2024)
查询第二页的时候,将第一页order_id结果的最大值,作为条件放在第二页查询中,此处为1289015523201130581,
@Test
public void queryProhibitPage(){
long l = System.currentTimeMillis();
List<Orders> orders = ordersMapper.queryProhibit(10, 0,1289015523201130581L);
System.out.println("花费时间 : \t" + (System.currentTimeMillis() - l));
for (Orders order : orders) {
System.out.println(order);
}
}
花费时间 : 955
Orders(orderId=1289015650867736645, userId=242925119, businessId=36, orderDate=Fri Jul 05 00:00:00 CST 2024)
Orders(orderId=1289015705371156506, userId=256231618, businessId=190, orderDate=Fri Jul 05 00:00:00 CST 2024)
Orders(orderId=1289015767379583072, userId=271370394, businessId=109, orderDate=Fri Jul 05 00:00:00 CST 2024)
Orders(orderId=1289015796777467972, userId=278547612, businessId=74, orderDate=Fri Jul 05 00:00:00 CST 2024)
Orders(orderId=1289015893385383950, userId=302133529, businessId=156, orderDate=Fri Jul 05 00:00:00 CST 2024)
Orders(orderId=1289016129480106035, userId=359773842, businessId=162, orderDate=Fri Jul 05 00:00:00 CST 2024)
Orders(orderId=1289016200532709421, userId=377120669, businessId=67, orderDate=Fri Jul 05 00:00:00 CST 2024)
Orders(orderId=1289016244286947432, userId=387802856, businessId=123, orderDate=Fri Jul 05 00:00:00 CST 2024)
Orders(orderId=1289016295920742499, userId=400408763, businessId=125, orderDate=Fri Jul 05 00:00:00 CST 2024)
Orders(orderId=1289016348148285461, userId=413159628, businessId=50, orderDate=Fri Jul 05 00:00:00 CST 2024)
通过实际执行sql分析
2024-07-06 15:05:23.003 INFO 32504 --- [ main] ShardingSphere-SQL : Actual SQL: m1 ::: select * from orders_28 where order_id > ? order by order_id limit ? offset ? ::: [1289015523201130581, 10, 0]
2024-07-06 15:05:23.004 INFO 32504 --- [ main] ShardingSphere-SQL : Actual SQL: m1 ::: select * from orders_29 where order_id > ? order by order_id limit ? offset ? ::: [1289015523201130581, 10, 0]
可以看到,每个数据节点查询出的数据永远都是十条,最后再聚合排序。
禁止跳跃查询法弊端:
- 不能跳页查询,只能一页一页的查询,比如说从第一页直接跳到第五页,因为无法获取到第四页的最大值,所以无法直接从第一页获取第五页的数据。
商户端查询
在商户端想要查询自己所有的订单这种业务情况下,如何根据实现?
由于没有商户id不是分片键的情况,查询商户自己的订单会走全库全表查询。数据量一旦过大,则查询效率会显著下降~
索引法(冗余)
- 就是在各自的库中创建基于商户id和订单id的表,用商户id去分表
- 查询的时候通过商户id可以快速定位到数据节点中。
- 获取订单id,通过订单id再从订单表中去查询所有的订单。
ES异构
-
在订单创建的时候,异构一份订单数据到elasticsearch中
-
elasticsearch对于这种数据量的查询简直效率很高。
-
商户端的查询可以直接从es中获取











![[BJDCTF 2nd]简单注入](https://i-blog.csdnimg.cn/direct/2c33c4a171e845c2b6a5cd61e23f108b.png)