近年来,在大语言模型(LLM)的反复刷屏过程中,作为其内核的 Transformer 始终是绝对的主角。然而,随着业务落地的诉求逐渐强烈,有些原本不被过多关注的特性,也开始成为焦点。例如:在 Transformer 诞生之初,被视为天然具备的长度外推能力,随着相关研究的深入,人们发现,传统的 Transformer 架构在训练长度之外无一例外表现出糟糕的推理性能。
在本文中,作者从一个全新的视角,剖析了造成这种糟糕表现的可能原因,并给出了相应的解决方案。文章主要聚焦于 Self-Attention (Vaswani et al., 2017) 与 RoPE (Su et al., 2021) 的碰撞,后者是近年较多开源模型所采用的位置编码方式,例如:LLaMA (Touvron et al., 2023a) 和 Qwen (Bai et al., 2023)。
论文已被ACL 2024接收,技术细节可以查看预印版本:https://arxiv.org/abs/2309.08646

引言:
在自注意力 (Vaswani et al., 2017) 诞生之初,长度外推被认为是一种理所当然的能力。然而,随着实际应用的不断验证,这在事实上是有难度的,进而产生了一系列相关的优化工作。
现有工作通常聚焦于2个方向:注意力模块和位置编码,并有一系列优秀的工作产生。如:Longformer (Beltagy et al., 2020)、StreamingLLM (Xiao et al., 2023)、LM-Infinite (Han et al., 2023)、Alibi (Press et al., 2021)、Position Interpolation (PI) (Chen et al., 2023)、NTK-aware Scaled RoPE (bloc97, 2023)、CLEX (Chen et al., 2024) 等。
本文从一个全新的视角,揭示了自注意力与位置编码之间的内在联系(尤其是如今广泛应用的RoPE)。自注意力之中,查询和键之间天然存在的夹角,将位置编码引入了意料之外的困境,尤其是对具有关键信息的邻近位置的估计,存在不符合预期的异常行为。文章以此为切入,提出了相应的解决方案。
主要贡献如下:
-
揭示了自注意力与位置编码之间的一种异常行为
-
提出了 Collinear Constrained Attention (CoCA) 以解决上述问题
-
实验表明 CoCA 在长上下文处理能力比常规自注意力具有显著优势
-
开源了一份 CoCA 高效实现,不会增加现有计算和空间复杂度
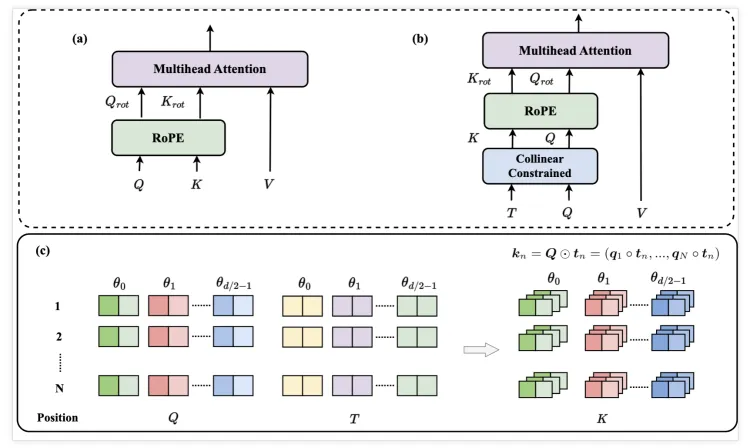
Fig. 1. CoCA model architecture.
01
背景
旋转位置编码
理论完备性和简洁的实现,使 RoPE 成为了多数开源模型的选择。RoPE 通过旋转矩阵来编码每一个 Token 的位置信息,并利用查询和键的旋转复合,来实现相对位置的表达。
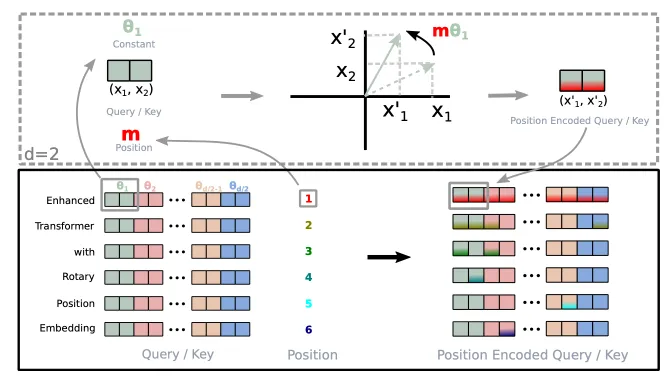
Fig. 2. rotary position embedding.(Su et al., 2021)
异常行为
在 Transformer 模型中,核心思想是计算 query 和 key 之间的关系。注意力机制使用这些关系来决定模型应该“关注”输入序列中的哪些部分。而 RoPE 利用旋转矩阵来编码位置信息的过程中,存在以下潜在的异常行为,如图 3 所示:

Fig. 3. Anomalous Behavior between RoPE and Attention Matrices.
情况(b)和(c):这是符合预期的行为,因为 query 和 key 之间注意力得分随着 m 和 n 的距离变大而逐渐减小,符合“近大远小”的先验假设。
情况(a)和(d):这是发生异常的行为,因为在最邻近的 Token 处,注意力得分预期之外的衰减,模型为了补偿这种衰减,必须在训练阶段给邻近 Token 补偿额外的增益,进而在长度外推过程中产生训练/推理的不一致。
02
CoCA实现
共线约束
基于上述观察,一个很自然的想法是让 Self-Attention 中的query和key初始夹角为0,这是论文中共线约束(Collinear Constrained Attention)的由来。
详细的推导和公式,这里不进行一一展开,读者可以阅读原文进行深入理解,这里只给出核心公式:
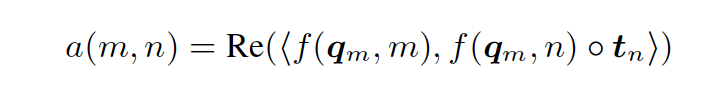
与原始的 Self-Attention 和 RoPE 相比,上述公式表达了CoCA 的核心:即在第 m 个 query 和第 n 个 key 之间建立联系,使它们的任意一个二维切片共线,从而保证 query 和 key 初始夹角为 0 。
松弛约束
然而,上述共线约束所导出的精确解仅仅在理论上可行,实际操作过程中,由于空间复杂度的问题,并不能够实现。为此,文章中给出了一种“对偶”实现,并证明了两者的等价性。
核心公式如下:
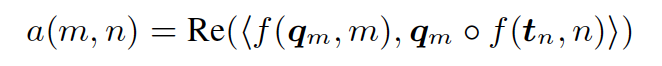
文章中证明了“对偶”实现施加以下额外约束后,等价于理论精确解:
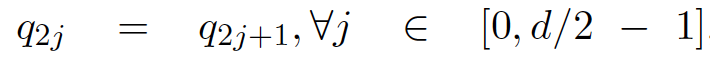
最后,文章移除该额外约束,并得到CoCA的最终实现,这是松弛约束(Slack Constraint)的由来。
03
实验结果
长文本能力
文章分别评估了重新训练和基于LLaMA微调2种方式,在PG-19 数据集 (Rae et al., 2019)和 (Mohtashami & Jaggi, 2023) 提出的密钥检索综合评估任务,均表明CoCA相比常规的Self-Attention在长文本能力上具有显著优势。
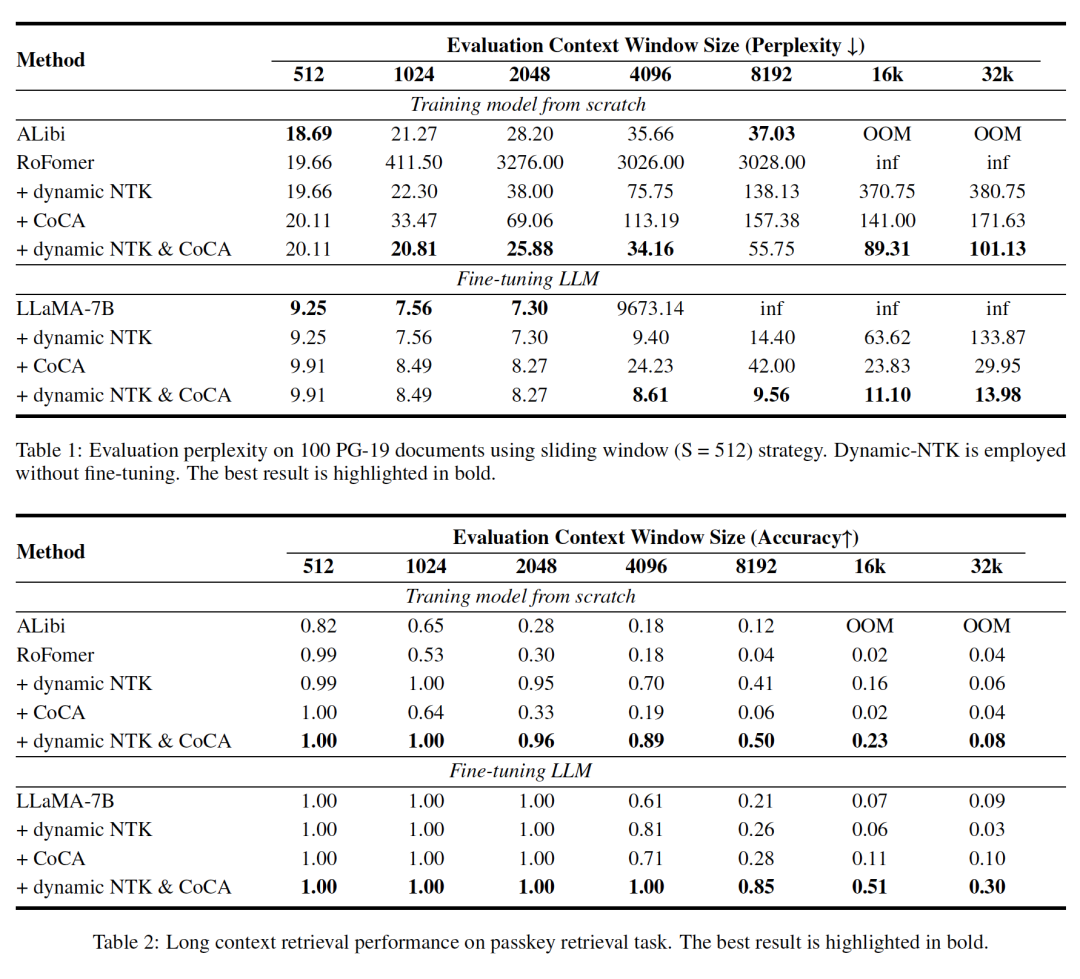
Fig. 4. Experiment Results.
消融实验
文章对比了松弛约束和非松弛版本的模型,得到了一些出人意料的结果:即尽管模型结构一致,但松弛约束具有更大的上下文窗口,且不影响模型表达能力。
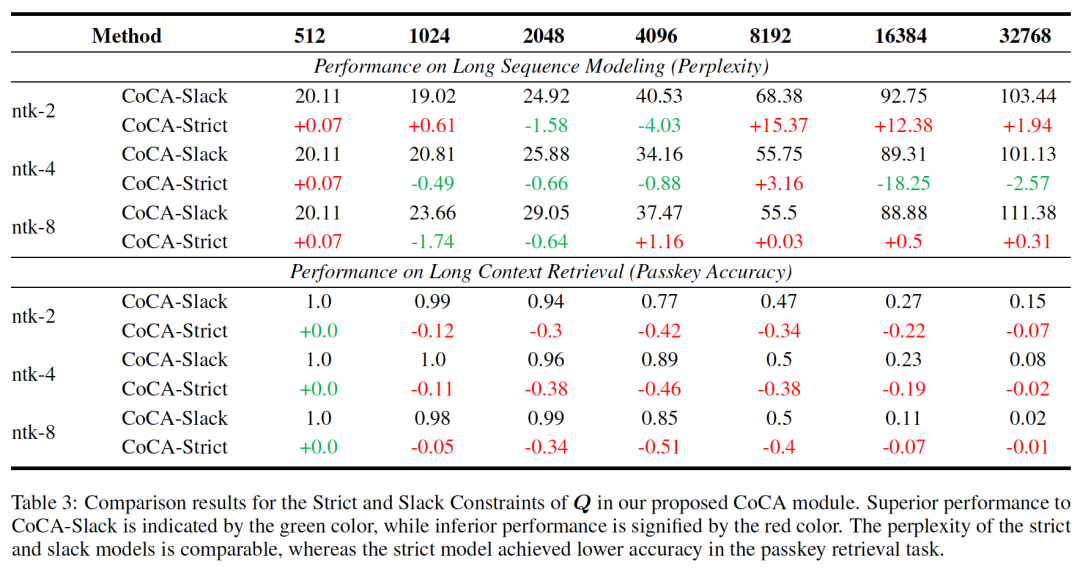
Fig. 5. Ablation study.
04
总结
文章提出了一种新的自注意力架构,以解决 RoPE 和原始 Self-Attention 之间的异常行为。这是首次对自注意力机制中查询和键的相对位置的深入研究,并由此发现了此前被忽视的位置编码异常。文章进一步导出了 CoCA 的松弛实现,并在大量实验上表明了该方法在长文本扩展上的优越性。同时,CoCA 与其他优化方法的兼容性,也为其未来的实用价值提供了基础。
CoCA 开源地址:https://github.com/codefuse-ai/Collinear-Constrained-Attention
参考文献
CoCA 预印版本:https://arxiv.org/abs/2309.08646
致谢
感谢来自 Moonshot AI Ltd 的苏剑林和Sangfor Technology 的黄忠强,在论文修改过程中提出的宝贵建议。
本文属于 CodeFuse 模型创新成果,想了解更多CodeFuse 详情和互动交流,欢迎加入 CodeFuse 技术交流群。
获取最新信息,你还可以扫描二维码直接加入群聊

阅读原文