目录
- 引言
- 1、MaxKB概述
- 1.1 定义与目标
- 1.2 特点与优势
- 2、MaxKB原理
- 3、MaxKB架构
- 4、基于MaxKB+Ollama+Qwen2搭建本地知识库
- 4.1 环境准备
- 4.2 部署MaxKB
- 4.3 部署Ollama
- 4.4 部署运行qwen2
- 4.5 知识库配置
- 4.5.1登录 MaxKB 系统
- 4.5.2上传文档
- 4.5.3设置分段规则
- 4.6 模型配置
- 4.7 创建应用
- 结语
- 参考引用
引言
我们生活在一个信息爆炸的时代,数据的增长速度前所未有,企业每天产生的数据量呈指数级增长。这些数据中蕴含着巨大的价值,但同时也带来了前所未有的挑战:如何从海量的数据中快速提取有价值的信息,转化为企业的竞争优势?传统的数据处理方法已经无法满足现代企业的需求,企业迫切需要一种更高效、更智能的解决方案。
在这样的背景下,MaxKB应运而生。MaxKB,即Max Knowledge Base,是一款基于LLM(Large Language Model)大语言模型的知识库问答系统。它利用最新的人工智能技术,特别是自然语言处理(NLP)和机器学习,为企业提供了一种全新的信息处理和利用方式。
1、MaxKB概述
1.1 定义与目标
MaxKB,全称Max Knowledge Base,是一个开源的AI知识库问答系统。它的目标是成为企业的"最强大脑",通过集成大型语言模型,提供快速、准确的问答服务。

1.2 特点与优势
- 开箱即用:支持直接上传文档、自动爬取在线文档,支持文本自动拆分、向量化、RAG(检索增强生成),智能问答交互体验好;
- 无缝嵌入:支持零编码快速嵌入到第三方业务系统;
- 多模型支持:支持对接主流的大模型,包括 Ollama 本地私有大模型(如 Meta Llama 3、qwen 等)、通义千问、OpenAI、Azure OpenAI、Kimi、智谱 AI、讯飞星火和百度千帆大模型等。
2、MaxKB原理
知识库构建
MaxKB通过构建知识库,将企业内部的文档、资料等信息进行结构化存储,便于后续的检索和分析。
问答机制
利用LLM大语言模型,MaxKB能够理解用户的查询意图,并从知识库中检索出最相关的答案。
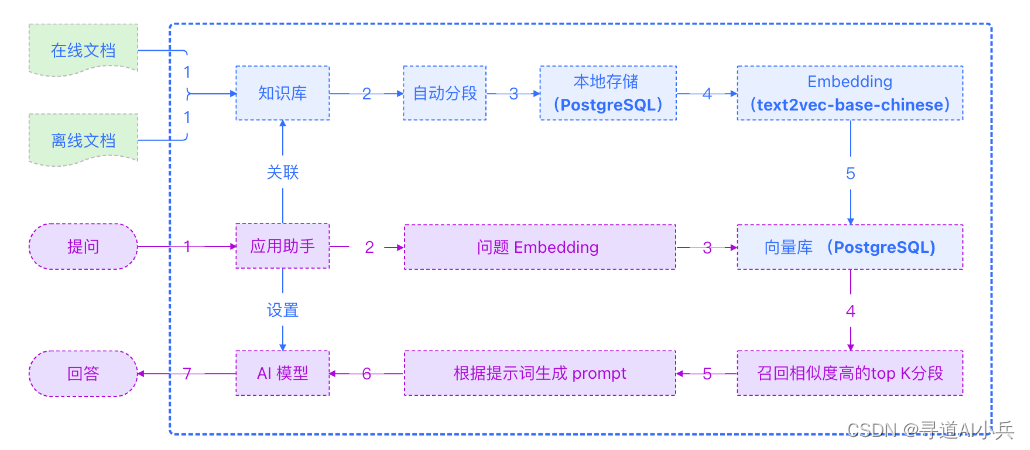
3、MaxKB架构
技术栈
- 前端:Vue.js
- 后端:Python / Django
- 工作流引擎:LangChain
- 向量数据库:PostgreSQL / pgvector
- 大模型支持:Azure OpenAI、OpenAI、百度千帆等
系统组件:MaxKB由多个组件构成,包括文档上传、自动爬虫、文本处理、问答引擎等,共同协作完成知识库的构建和问答服务。
文档处理:支持多种格式的文档上传,自动进行文本拆分和向量化处理。
智能问答:提供智能问答交互,根据用户查询,快速从知识库中检索答案。
业务系统集成:支持与第三方业务系统的集成,无需编码即可实现智能问答功能。
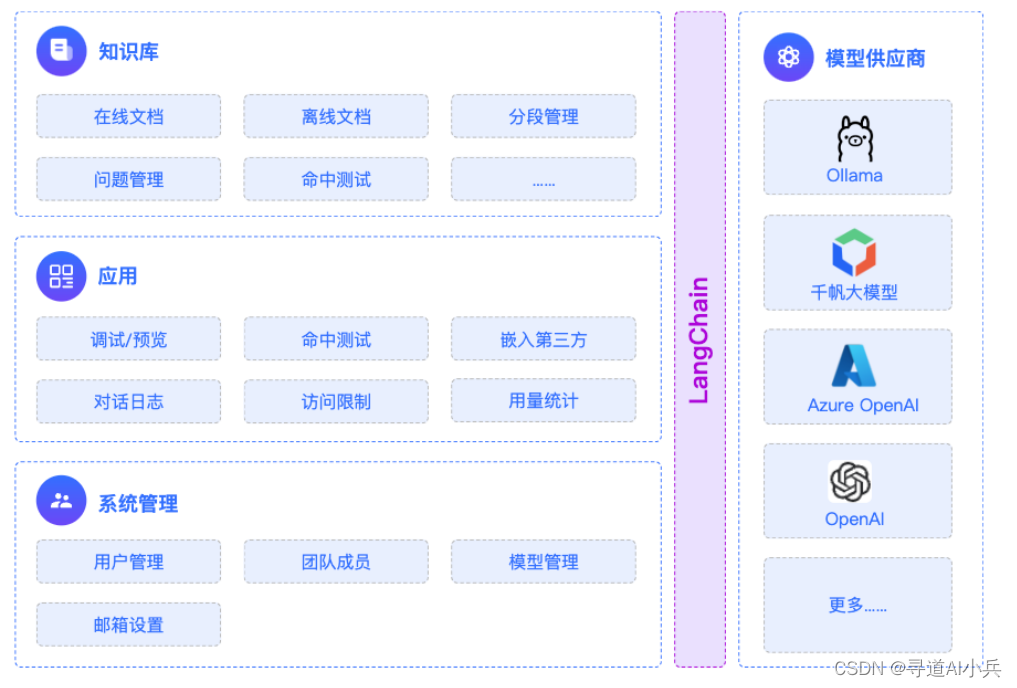
4、基于MaxKB+Ollama+Qwen2搭建本地知识库
4.1 环境准备
确保系统满足MaxKB的运行条件,包括操作系统、数据库、Python环境等。
- 操作系统:Ubuntu 22.04 / CentOS 7 64 位系统;
- CPU/内存: 推荐 2C/4GB 以上;
- 磁盘空间:100GB;
- 浏览器要求:请使用 Chrome、FireFox、Safari、Edge等现代浏览器;
可访问互联网。
4.2 部署MaxKB
通过Docker快速部署MaxKB,执行以下命令即可启动服务:
docker run -d --name=maxkb -p 8080:8080 -v ~/.maxkb:/var/lib/postgresql/data cr2.fit2cloud.com/1panel/maxkb
安装成功后,可通过浏览器访问 MaxKB:
http://目标服务器 IP 地址:目标端口
默认登录信息
用户名:admin 默认密码:MaxKB@123…
4.3 部署Ollama
Ollama支持多种安装方式,包括通过包管理器、Docker或从源代码编译。
对于Linux用户,可以使用如下命令进行安装:
curl -fsSL https://ollama.com/install.sh | sh
查看模型列表:
ollama list
查看版本:
查看 Ollama 版本
ollama -v
启动服务:
ollama serve
4.4 部署运行qwen2
Ollama支持很多模型,可以在https://ollama.com/library查看
使用以下命令部署运行模型:
ollama run qwen2
4.5 知识库配置
4.5.1登录 MaxKB 系统
使用浏览器打开服务地址:http://目标服务器IP地址:目标端口。
默认的登录信息:
用户名:admin 默认密码:MaxKB@123…
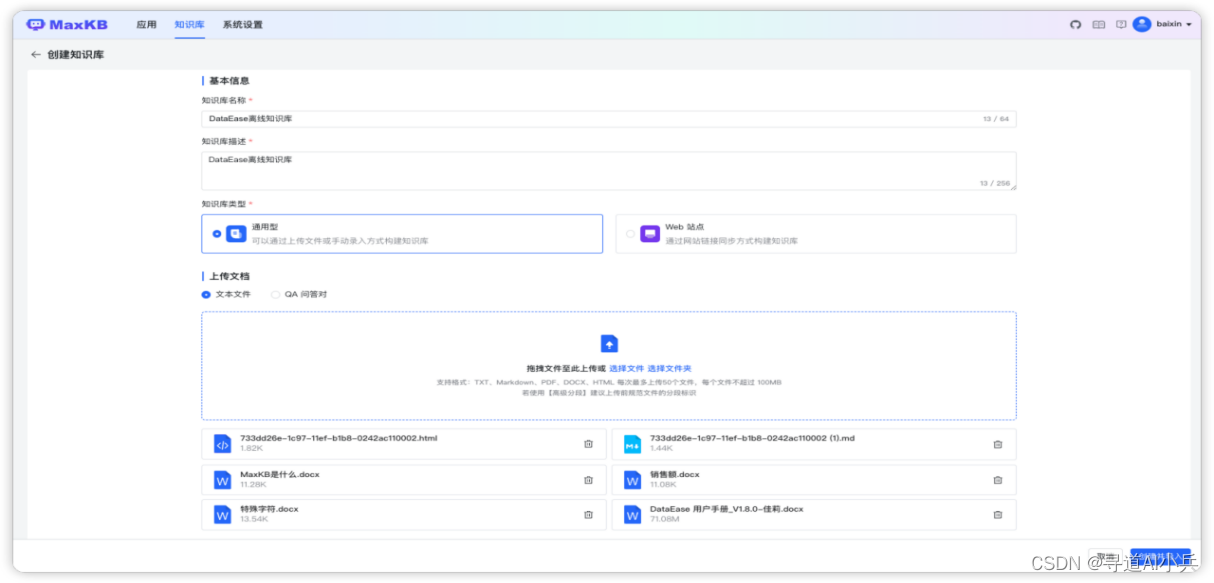
打开【知识库】页面,点击【创建知识库】,进入创建知识库页面。 输入知识库名称、知识库描述、选择通用型知识库类型。
然后将离线文档通过拖拽方式或选择文件上传方式进行上传。
4.5.2上传文档
上传文档要求:
1)支持文本文件格式为:Markdown、TXT、PDF、DOCX、HTML;
2)支持 QA 问答对格式为:Excel、CSV;
3)每次最多上传 50 个文件;
4)每个文件不超过 100 MB;
5)支持选择文件夹,上传文件夹下符合要求的文件。
4.5.3设置分段规则
智能分段
MarkDown 类型的文件分段规则为:根据标题逐级下钻式分段(最多支持 6 级标题),每段的字符数最大为 4096 个字符;
当最后一级的文本段落字符数超过设置的分段长度时,会查找分段长度以内的回车进行截取。
HTML、DOCX 类型的分段规则为:识别标题格式转换成 markdown 的标题样式,逐级下钻进行分段(最多支持 6 级标题)每段的字符数最大为 4096 个字符;
TXT和 PDF 类型的文件分段规则为:按照标题# 进行分段,若没有#标题的责按照字符数4096个字符进行分段,会查找分段长度以内的回车进行截取。
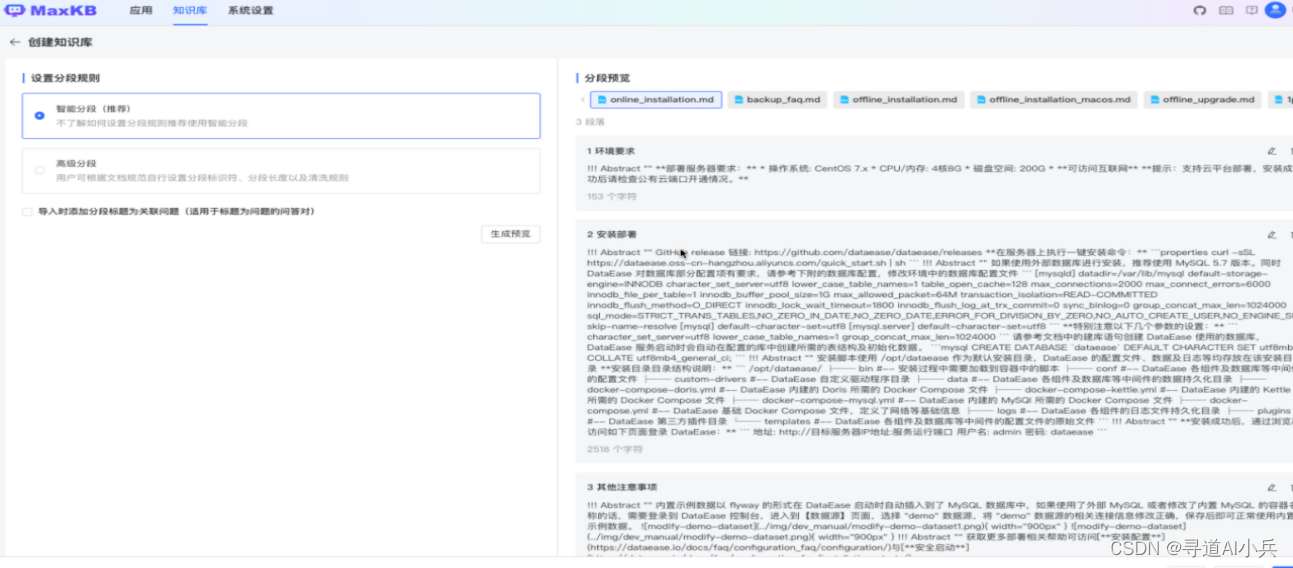
高级分段
用户可以根据文档规范自定义设置分段标识符、分段长度及自动清洗。
分段标识支持:#、##、###、####、#####、######、-、空行、回车、空格、分号、逗号、句号,若可选项没有还可以自定义输入分段标识符。
分段长度:支持最小 50个字符,最大 4096 个字符。
自动清洗:开启后系统会自动去掉重复多余的符号如空格、空行、制表符等。
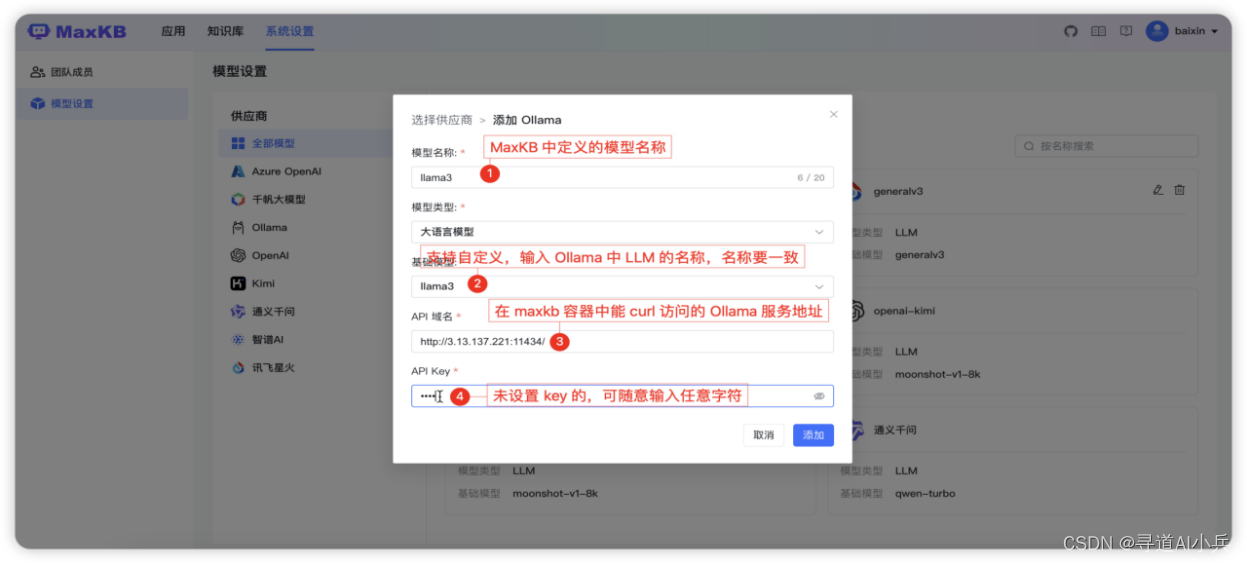
4.6 模型配置
添加 Ollama 模型
点击【添加模型】,选择供应商【 Ollama 】,直接进入下一步填写 Ollama 供应商的大模型表单。或者左侧供应商先选择【 Ollama 】,然后点击【添加模型】,则直接进入 Ollama 表单。
模型名称: MaxKB 中自定义的模型名称。
模型类型: 大语言模型。
基础模型: 为供应商的 LLM 模型,支持自定义输入,但需要与供应商的模型名称保持一致,系统会自动下载部署模型。
API 域名和 API Key: 为供应商的连接信息(Ollama 服务地址, 如:http://42.92.198.53:11434 )。若没有 API Key 可以输入任意字符。
点击【添加】后 校验通过则添加成功,便可以在应用的 AI 模型列表选择该模型。
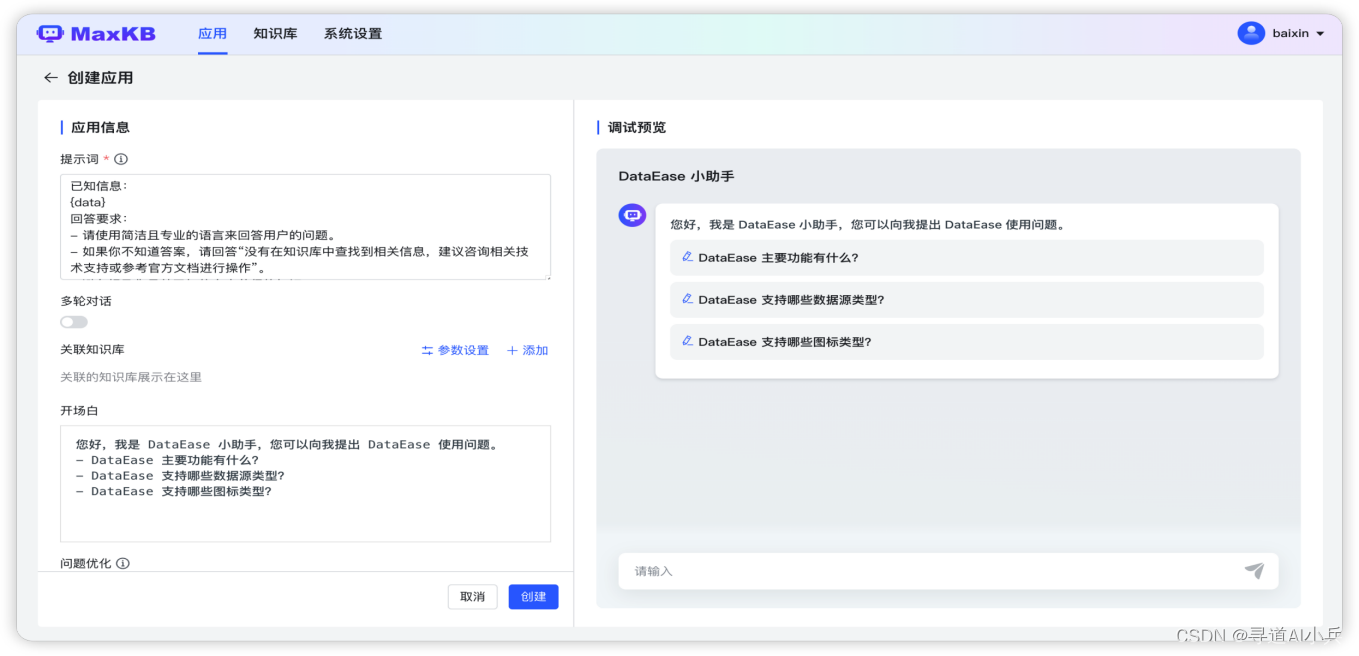
4.7 创建应用
点击【创建应用】,进入创建应用页面,左侧为应用信息,右侧为调试预览界面。
应用名称:用户提问时对话框的标题和名字。
应用描述:对应用场景及用途的描述。
AI模型: 在【系统设置】-【模型管理】中添加的大语言模型。
提示词:系统默认有智能知识库的提示词,用户可以自定义通过调整提示词内容,可以引导大模型聊天方向.
多轮对话: 开启时当用户提问携带用户在当前会话中最后3个问题;不开启则仅向大模型提交当前问题题。
关联知识库:用户提问后会在关联的知识库中检索分段。
开场白:用户打开对话时,系统弹出的问候语。支持 Markdown 格式;[-]后的内容为快捷问题,一行一个。
问题优化:对用户提出的问题先进行一次 LLM 优化处理,将优化后的问题在知识库中进行向量化检索;
开启后能提高检索知识库的准确度,但由于多一次询问大模型会增加回答问题的时长。
应用信息设置完成后,可以在右侧调试预览中进行提问预览,调试预览中提问内容不计入对话日志。
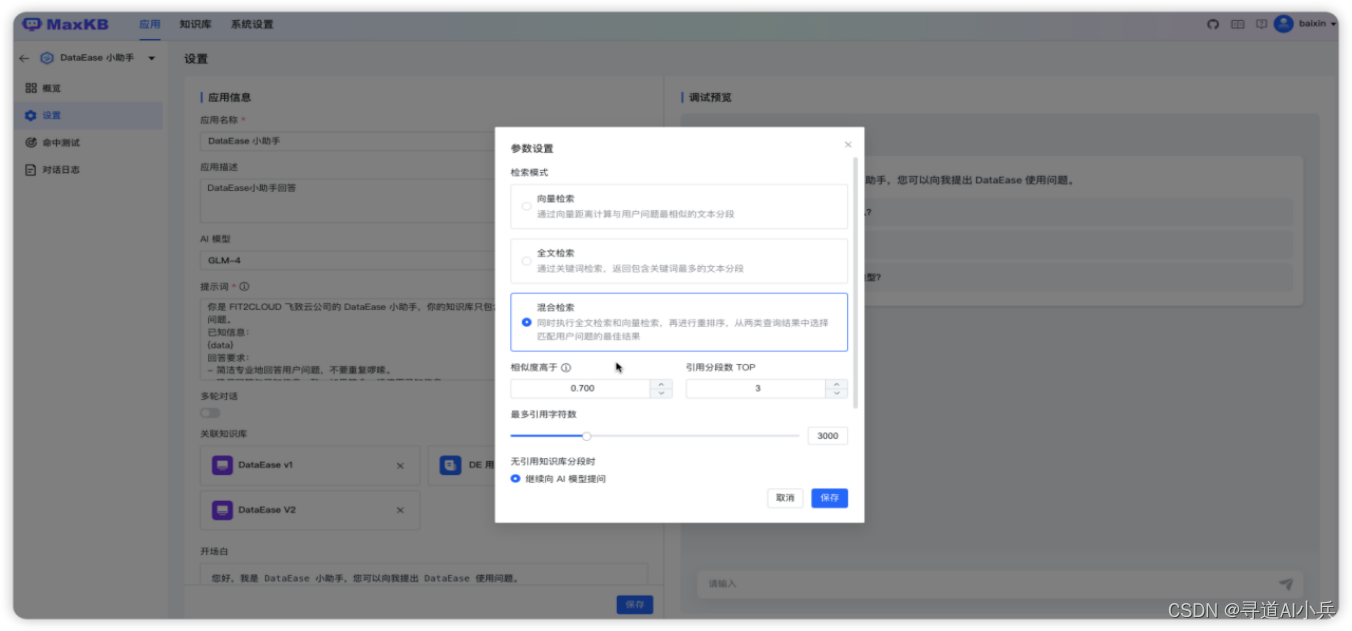
参数设置详细说明
1)检索模式:
向量检索:使用向量模型通过向量距离计算与用户问题最相似的文本分段;
全文检索:通过关键词检索,返回包含关键词最多的文本分段;
混合检索:同时执行全文检索和向量检索,再进行重排序,从两类查询结果中选择匹配用户问题的最佳结果。
2)相似度:相似度越高代表问题和分段的相关性越强。
3)引用分段数:提问时按相似度携带N个分段生成提示词询问 LLM 模型。
4)引用最大字符数:引用分段内容设置最大字符数,超过时则截断。
5)无引用知识库时,有 2 种处理方式可设置:
继续提问:可以自定义设置提示词,需要有{question}用户问题的占位符,才会把用户问题发送给模型。
指定回复内容:当没有命中知识库分段时可以指定回复内容。
结语
MaxKB,作为企业级知识库问答系统的佼佼者,不仅以其强大的功能和灵活的部署方式,为企业提供了一种高效、智能的信息处理方案,更在AI技术的持续进步中展现出无限的潜力。它通过深度整合自然语言处理和机器学习技术,使得企业能够轻松应对数据洪流,实现信息的快速检索、精准分析和智能决策。
展望未来,随着AI技术的进一步发展,MaxKB有望在知识管理和智能问答领域发挥更大的作用。它将继续推动企业知识资产的有效管理和利用,助力企业在激烈的市场竞争中保持领先。我们期待与更多企业携手,共同探索MaxKB的无限可能,开启智能信息处理的新篇章。
参考引用
- MaxKB GitHub项目地址

🎯🔖更多专栏系列文章:AI大模型提示工程完全指南、AI大模型探索之路(零基础入门)、AI大模型预训练微调进阶、AI大模型开源精选实践、AI大模型RAG应用探索实践🔥🔥🔥 其他专栏可以查看博客主页📑
😎 作者介绍:我是寻道AI小兵,资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索。
📖 技术交流:欢迎关注【小兵的AI视界】公众号或扫描下方👇二维码,加入技术交流群,开启编程探索之旅。
💘精心准备📚500本编程经典书籍、💎AI专业教程,以及高效AI工具。等你加入,与我们一同成长,共铸辉煌未来。
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我,让我们携手同行AI的探索之旅,一起开启智能时代的大门!