推荐指数: #paper/⭐⭐⭐ #paper/💡
发表于:AAAI21
简称:FAGCL
问题提出背景:
GCN常常使用低频信息,但是在现实中,不仅低频信息重要,高频信息页重要

如上图,随着类间链接的增加,低频信号的增强开始变弱,高频信号的增强开始增加.
作者贡献:
- 不仅低频信号重要,高频信号也重要
- 我们提出了FAGCN,不需要知道网络类型就可以自适应传播低频高频信号
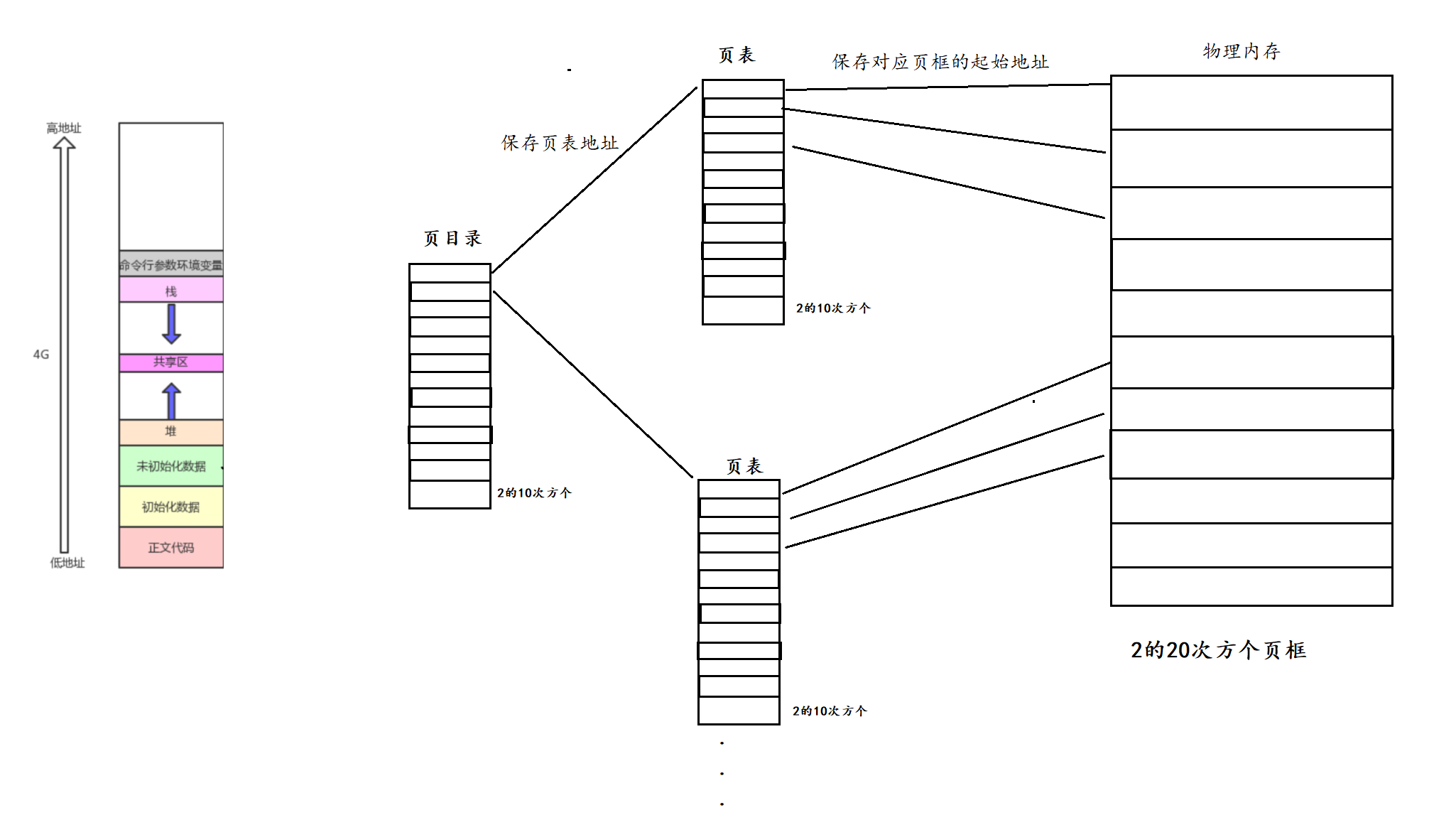
模型
先验知识:
L
=
I
n
−
D
−
1
/
2
A
D
−
1
/
2
,
L = I_n - D^{-1/2}AD^{-1/2},
L=In−D−1/2AD−1/2,
在这里,
λ
l
∈
[
0
,
2
]
\lambda_{l}\in[0,2]
λl∈[0,2],
L
=
U
Λ
U
T
L = U\Lambda U^{T}
L=UΛUT,
Λ
=
d
i
a
g
(
[
λ
1
,
λ
2
,
⋯
,
λ
n
]
)
\Lambda=diag([\lambda_1,\lambda_2,\cdots,\lambda_n])
Λ=diag([λ1,λ2,⋯,λn])
ChebNet的卷积核:
g
θ
=
∑
k
=
0
K
−
1
α
k
Λ
k
g_\theta=\sum_{k=0}^{K-1}\alpha_k\Lambda^k
gθ=∑k=0K−1αkΛk,
g
θ
=
I
−
Λ
g_{\theta}=I-\Lambda
gθ=I−Λ
高频滤波器和低频滤波器
如下,我们设计了高通滤波器
F
L
F_{L}
FL和低通滤波器
F
H
F_{H}
FH
F
L
=
ε
I
+
D
−
1
/
2
A
D
−
1
/
2
=
(
ε
+
1
)
I
−
L
,
F
H
=
ε
I
−
D
−
1
/
2
A
D
−
1
/
2
=
(
ε
−
1
)
I
+
L
\begin{align} \mathcal{F}_L=\varepsilon I+D^{-1/2}AD^{-1/2}=(\varepsilon+1)I-L,\\\mathcal{F}_H=\varepsilon I-D^{-1/2}AD^{-1/2}=(\varepsilon-1)I+L \end{align}
FL=εI+D−1/2AD−1/2=(ε+1)I−L,FH=εI−D−1/2AD−1/2=(ε−1)I+L
在这里,
ε
\varepsilon
ε是超参,范围为[0,1]
如果我们使用
F
L
和
F
h
F_{L}和F_{h}
FL和Fh替代卷积核f,我们可以得到如下:
F
L
∗
G
x
=
U
[
(
ε
+
1
)
I
−
Λ
]
U
⊤
x
=
F
L
⋅
x
,
F
H
∗
G
x
=
U
[
(
ε
−
1
)
I
+
Λ
]
U
⊤
x
=
F
H
⋅
x
.
\begin{align} \mathcal{F}_L*_Gx=U[(\varepsilon+1)I-\Lambda]U^\top x=\mathcal{F}_L\cdot x,\\\mathcal{F}_H*_Gx=U[(\varepsilon-1)I+\Lambda]U^\top x=\mathcal{F}_H\cdot x. \end{align}
FL∗Gx=U[(ε+1)I−Λ]U⊤x=FL⋅x,FH∗Gx=U[(ε−1)I+Λ]U⊤x=FH⋅x.

由于一阶滤波器: g θ ( λ i ) = ε + 1 − λ i g_\theta(\lambda_i)=\varepsilon+1-\lambda_i gθ(λi)=ε+1−λi(图2a)会存在负的幅度,我们为了摆脱这种情况,我们采用了图2b,图2d的二阶滤波器
低通高通分析
F
L
=
ε
I
+
D
−
1
/
2
A
D
−
1
/
2
\mathcal{F}_L=\varepsilon I+D^{-1/2}AD^{-1/2}
FL=εI+D−1/2AD−1/2
F
H
=
ε
I
−
D
−
1
/
2
A
D
−
1
/
2
\mathcal{F}_H=\varepsilon I-D^{-1/2}AD^{-1/2}
FH=εI−D−1/2AD−1/2如上,
F
L
⋅
x
F_{L}\cdot x
FL⋅x表示节点和邻居特征在光谱区域的和,高频信号
F
H
⋅
x
F_{H}\cdot x
FH⋅x代表节点和邻居特征之间的不同

为了整合高频和低频信号,一个很自然的想法是利用注意力机制去学习高频和低频信号
h
~
i
=
α
i
j
L
(
F
L
⋅
H
)
i
+
α
i
j
H
(
F
H
⋅
H
)
i
=
ε
h
i
+
∑
j
∈
N
i
α
i
j
L
−
α
i
j
H
d
i
d
j
h
j
,
\tilde{\mathrm{h}}_i=\alpha_{ij}^L(\mathcal{F}_L\cdot\mathbf{H})_i+\alpha_{ij}^H(\mathcal{F}_H\cdot\mathbf{H})_i=\varepsilon\mathbf{h}_i+\sum_{j\in\mathcal{N}_i}\frac{\alpha_{ij}^L-\alpha_{ij}^H}{\sqrt{d_id_j}}\mathbf{h}_j,
h~i=αijL(FL⋅H)i+αijH(FH⋅H)i=εhi+j∈Ni∑didjαijL−αijHhj,
为了简化,我们令:
α
i
j
L
+
α
i
j
H
=
1
\alpha_{ij}^{L}+\alpha_{ij}^{H}=1
αijL+αijH=1
α
i
j
G
=
α
i
j
L
−
α
i
j
H
\alpha_{ij}^{G}=\alpha_{ij}^{L}-\alpha_{ij}^{H}
αijG=αijL−αijH
remark
理解1:当
α
i
j
G
>
0
,
i
.
e
.
,
α
i
j
L
>
α
i
j
H
\alpha_{ij}^{G} > 0, i.e., \alpha_{ij}^{L} > \alpha_{ij}^{H}
αijG>0,i.e.,αijL>αijH,这表示低频信号是主要的信号.
理解2:
α
i
j
G
>
0
\alpha_{ij}^{G}>0
αijG>0表示节点和邻居特征,
h
i
+
h
j
\mathrm{h}_i+\mathrm{h}_j
hi+hj.
α
i
j
G
<
0
\alpha_{ij}^G<0
αijG<0表示节点之间的区别.
为了自适应的设置
α
i
j
G
\alpha_{ij}^G
αijG,我们考虑节点和它的邻居
α
i
j
G
=
tanh
(
g
⊤
[
h
i
∥
h
j
]
)
\alpha_{ij}^G=\tanh\left(\mathrm{g}^\top\left[\mathrm{h}_i\parallel\mathrm{h}_j\right]\right)
αijG=tanh(g⊤[hi∥hj])
g
∈
R
2
F
\mathbf{g}\in\mathbb{R}^{2F}
g∈R2F可以被视为一个共享的卷积核.tan函数限
α
i
j
G
\alpha_{ij}^G
αijG在[-1,1]内.初次之外,我们仅仅考虑节点和它的一阶邻居N的相关系数
计算
α
i
j
G
\alpha_{ij}^G
αijG之后,我们就可以聚合邻居的表征:
h
i
′
=
ε
h
i
+
∑
j
∈
N
i
α
i
j
G
d
i
d
j
h
j
,
\mathbf{h}_i^{^{\prime}}=\varepsilon\mathbf{h}_i+\sum_{j\in\mathcal{N}_i}\frac{\alpha_{ij}^G}{\sqrt{d_id_j}}\mathbf{h}_j,
hi′=εhi+j∈Ni∑didjαijGhj,
整个网络的结构
h
i
(
0
)
=
ϕ
(
W
1
h
i
)
∈
R
F
′
×
1
h
i
(
l
)
=
ε
h
i
(
0
)
+
∑
j
∈
N
i
α
i
j
G
d
i
d
j
h
j
(
l
−
1
)
∈
R
F
′
×
1
h
o
u
t
=
W
2
h
i
(
L
)
∈
R
K
×
1
,
\begin{aligned}&\mathbf{h}_i^{(0)}=\phi(\mathbf{W}_1\mathbf{h}_i)&&\in\mathbb{R}^{F^{\prime}\times1}\\&\mathbf{h}_i^{(l)}=\varepsilon\mathbf{h}_i^{(0)}+\sum_{j\in\mathcal{N}_i}\frac{\alpha_{ij}^G}{\sqrt{d_id_j}}\mathbf{h}_j^{(l-1)}&&\in\mathbb{R}^{F^{\prime}\times1}\\&\mathbf{h}_{out}=\mathbf{W}_2\mathbf{h}_i^{(L)}&&\in\mathbb{R}^{K\times1},\end{aligned}
hi(0)=ϕ(W1hi)hi(l)=εhi(0)+j∈Ni∑didjαijGhj(l−1)hout=W2hi(L)∈RF′×1∈RF′×1∈RK×1,
W
1
∈
R
F
×
F
′
,
W
2
∈
R
F
′
×
K
\mathbf{W}_1\in\mathbb{R}^{F\times F^{\prime}},\mathbf{W}_2\in\mathbb{R}^{F^{\prime}\times K}
W1∈RF×F′,W2∈RF′×K是权重矩阵.K代表类的个数
我们对FAGCN进行分析,当
α
i
j
=
1
\alpha_{ij}=1
αij=1,整个网络就是GCN网络.当我们使用正则化的
α
i
j
\alpha_{ij}
αij以及softmax函数,整个网络就是一个GAT网络.但是,GCN和GAT的
α
i
j
\alpha_{ij}
αij都大于0, 更倾向于聚合低频信号.FAGCN可以更好的去聚合低频和高频信号.
除此之外,我们还可以推断出,低通过滤可以让表征更相似,低通可以让表征更加区分
可视化边相似度

如上图,我们可以得到如下结论:Cora,Citeseer,Pubmed节点所有的边都是正的权重.然而,根据6b,6c可以展示:大量的类内边是负权重,这表明当类内边和类间边区分不清时,高频信号发挥更重要的作用.而对于actor数据集,他是个异类,类间和类内边没有明显区分.
总结
写的真好.这篇提出了一个自适应系数,自适应的学习高通滤波器权重和低通滤波器权重,更好的聚合各种信息.