对自然语言处理领域相关文献进行梳理和总结,对学习的文献进行梳理和学习记录。希望和感兴趣的小伙伴们一起学习。欢迎大家在评论区进行学习交流!
论文:《ChineseBERT: Chinese Pretraining Enhanced by Glyph and Pinyin Information》
下面将根据以下五部分内容进行论述
1.解决了什么问题
2.提出了什么方法
3.此方法与之前的方法区别
4.运用了什么算法、数据来源
5.如何训练模型
1.解决了汉语中普遍存在的多音多义现象(同一汉字有不同的发音和不同的含义)的问题。
2.提出了一个将汉字的字形和拼音信息纳入大规模预训练过程的模型ChineseBERT。
3.ChineseBERT模型的优势
(1)最初的BERT(Bidirectional Encoder Representations from Transformers)模型通过自注意力机制(self-attention)从大规模文本数据中学习词的上下文表示。
优点:在英语及其他语言任务上表现出了优异的性能。
缺点:对于中文,直接应用BERT存在一些问题。汉字不同于拼音文字,其不仅包含语义信息,还包含丰富的形状和音韵信息。传统的BERT模型忽略了这些信息,仅仅基于词或子词的表面形式进行学习,这对于中文这种表意文字来说显然是不够的。
(2)一些早期的工作尝试通过加入字形或拼音信息来增强模型表示。GlyphBERT:引入汉字的字形信息(如笔画、结构),以帮助模型更好地理解汉字的形态。Pinyin-BERT:结合拼音信息,使模型在学习过程中能够考虑汉字的发音特征。
优点:这些方法在一定程度上提高了模型的表现。
缺点:但通常是分别引入字形或拼音信息,没有将两者结合起来。
(3)ChineseBERT提出了一种新的预训练方法,将汉字的字形和拼音信息同时引入模型中。这种方法的优势在于:字形信息:通过图像嵌入(image embeddings)将汉字的字形信息引入,捕捉汉字的结构和笔画细节。拼音信息:通过拼音嵌入(pinyin embeddings)将汉字的音韵信息整合进模型,提供额外的语音信息。使得模型在处理中文时能够更全面地理解汉字,从而在各种下游任务中表现出更优异的性能。
4.训练了一个大规模的预训练中文NLP模型ChineseBERT;数据来源:从Common Crawl收集了预训练数据。预处理后(如去除英文文本过多的数据,过滤html标注器),保留10%左右的高质量数据进行预训练,共包含4B个汉字。我们使用LTP工具箱来识别中文单词的边界以进行全词掩蔽。
5.训练模型:
ChineseBERT的模型架构在传统BERT的基础上增加了两个额外的嵌入层,一个用于字形信息,另一个用于拼音信息。这种多模态信息的融合使得模型在处理中文时能够更全面地理解汉字,从而在各种下游任务中表现出更优异的性能。
对于每个汉字,首先将其字符嵌入、字形嵌入和拼音嵌入层连接起来,然后通过全连通层映射到d维嵌入,形成融合嵌入。然后将融合嵌入与位置嵌入相结合,作为BERT模型的输入。由于我们不使用NSP预训练任务,我们省略了段嵌入。我们使用全词掩蔽(WWM) (Cui et al., 2019a)和Char掩蔽(CM)进行预训练。如下图所示。
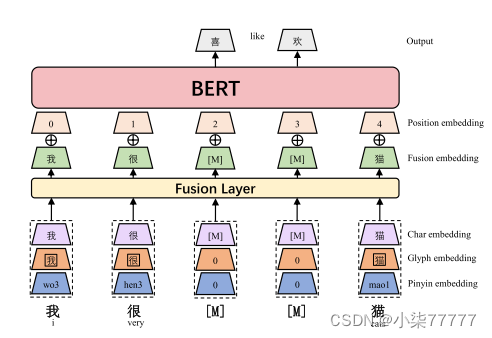
我们使用了两种掩蔽策略-全字掩蔽(WWM)和Char masking(CM)。Li等人(2019b)建议使用汉字作为基本输入单位可以缓解汉语语言的词汇外问题。因此,我们采用在给定上下文中屏蔽随机字符的方法,称为Char masking。另一方面,中文中的大量单词由多个字符组成,对于这种情况,CM策略可能太容易使模型无法预测。例如,对于输入上下文“[M] (i like going to the Forbidden [M])”,模型可以很容易地预测出被蒙面字符是“(City)”。因此,我们遵循Cui等人(2019a)使用WWM,这是一种掩盖选定单词内所有字符的策略,从而消除了CM策略易于预测的缺点。请注意,对于WWM和CM,基本输入单位都是汉字。WWM和CM的主要区别在于它们如何屏蔽字符以及模型如何预测被屏蔽字符。
模型的输入是可学习的绝对位置嵌入和融合嵌入的相加,其中融合嵌入是基于相应字符的字符嵌入、字形嵌入和拼音嵌入。字符嵌入的执行方式类似于BERT中使用的令牌嵌入,但在字符粒度上。下面我们分别描述了如何诱导字形嵌入、拼音嵌入和融合嵌入。
字形嵌入:我们按照Meng等人(2019)的方法,使用了三种类型的中文字体—仿宋、行楷和隶书,每种字体实例化为24张×24图像,浮点像素范围为0到255。与Meng等人(2019)使用cnn将图像转换为表示不同,我们使用FC层。我们首先将24×24×3向量转换为2352向量。将平面化的向量馈送到FC层(全连接层)以获得输出的字形向量。如下图所示。

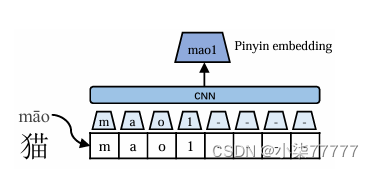
拼音嵌入:每个字符的拼音嵌入用于解耦属于同一字符形式的不同语义含义,如下图所示。我们使用开源的pypinyin package为其组成字符生成拼音序列。Pypinyin是一个将机器学习模型与基于字典的规则相结合的系统,用于推断给定上下文中字符的拼音。汉字的拼音是罗马尼亚字符的序列,四个变音符号中的一个表示声调。我们使用特殊的记号来表示声调,这些声调被附加到罗马尼亚字符序列的末尾。我们将宽度为2的CNN模型应用于拼音序列,然后进行最大合并以得出最终的拼音嵌入。这使得输出维度不受输入拼音序列的长度的影响。输入拼音序列的长度固定为8,当拼音序列的实际长度未达到8时,剩余的空位填充特殊字母“-”。
融合嵌入:一旦我们有了字符的字符嵌入、字形嵌入和拼音嵌入,我们就将它们连接起来形成一个3D向量。融合层通过完全连接的层将3D维向量映射到D维。将融合嵌入与位置嵌入相加,输出到BERT层。概述如下图所示。
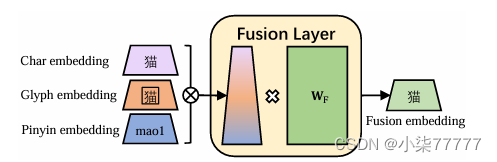
输出是每个输入汉字对应的上下文化表示。
通过上面叙述的内容进行模型训练。