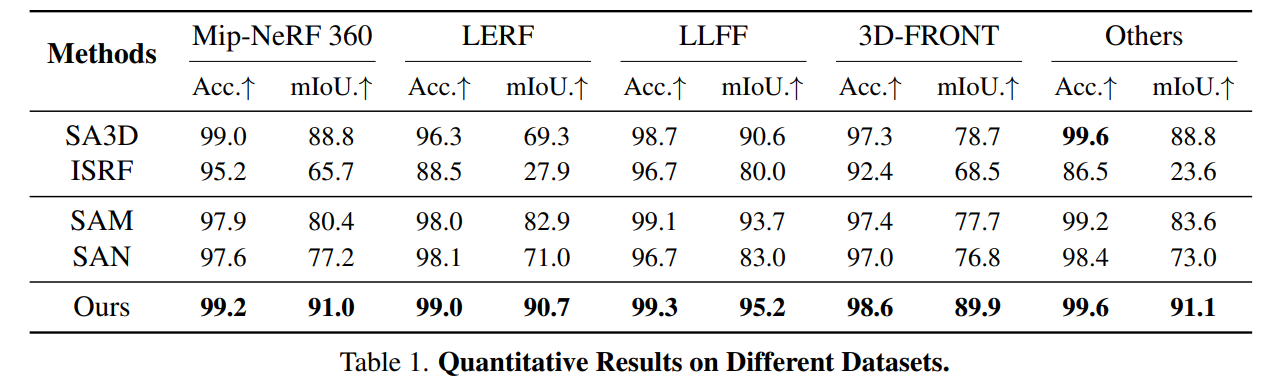
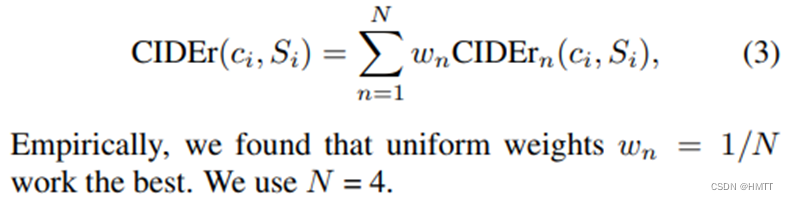CIDEr(Consensus-based Image Description Evaluation)
论文原文 CIDEr: Consensus-based Image Description Evaluation
CIDEr(Consensus-based Image Description Evaluation)是一种用于自动评估图像描述(image captioning)任务性能的指标。它主要通过计算生成的描述与一组参考描述之间的相似性来评估图像描述的质量。CIDEr的独特之处在于它考虑了人类对图像描述的共识,尝试捕捉描述的自然性和信息量。
计算过程
定义
计算关于图片 I i I_i Ii 生成的描述 c i c_i ci 与一组给定图片描述 S i = { s i 1 , … , s i m } S_i = \{s_{i1}, \dots, s_{im} \} Si={si1,…,sim} 的一致性。
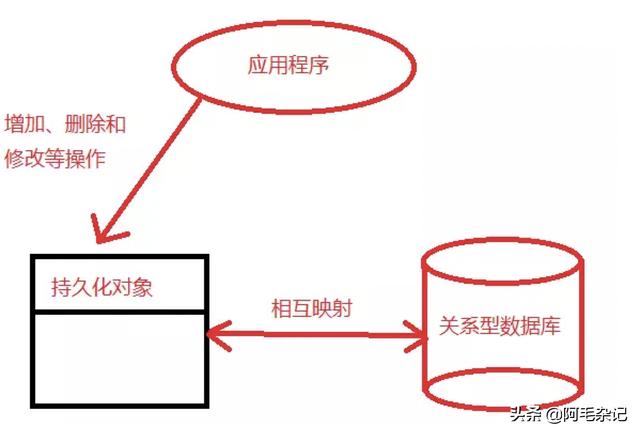
计算一个词组(wk)的权重
一个n-gram词组 w k w_k wk 出现在参考句子(生成描述)中的次数记为 h k ( s i j ) h_k(s_{ij}) hk(sij) ( h k ( c i ) h_k(c_i) hk(ci) )。
首先,为每个n-gram词组 w k w_k wk 计算TF-IDF权重( g k ( s i j ) g_k(s_{ij}) gk(sij) ):
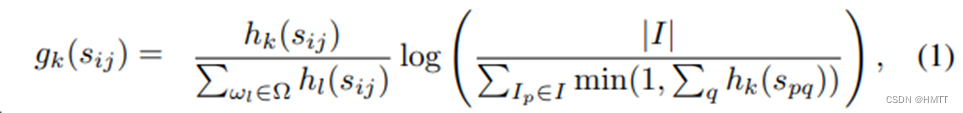
其中 Ω Ω Ω 表示包含所有n-gram词组的词典, I I I 是数据集中所有图片的集合。
前面的算式计算的是每个 w k w_k wk 的TF,第二个算式计算的是 w k w_k wk 的稀有程度(IDF)。
简单来说,
前面的算式 = w k 在当前句子 ( s i j ) 的出现次数 每个 w 在当前句子的出现次数之和 前面的算式 = \frac{w_k在当前句子(s_{ij})的出现次数}{每个w在当前句子的出现次数之和} 前面的算式=每个w在当前句子的出现次数之和wk在当前句子(sij)的出现次数,
后面的算式 = log 数据集图片数量 给定描述中出现过 w k 的图片数量 后面的算式 = \log \frac{数据集图片数量}{给定描述中出现过w_k的图片数量} 后面的算式=log给定描述中出现过wk的图片数量数据集图片数量
前面是词组在当前句子中的重要程度,后面是词组在整个数据集中的出现概率的倒数。整体作用跟tf-idf类似。
TF-IDF(term frequency–inverse document frequency)
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。
百度百科:TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与数据挖掘的常用加权技术。TF是词频(Term Frequency),IDF是逆文本频率指数(Inverse Document Frequency)。
顾名思义,Tf-idf由tf和idf两部分组成,tf是指一个词在当前document里面出现的频率,idf是指这个词在全体语料库中出现频率的倒数。根据这个定义,说明一个词对于一个document的重要程度与这个词出现在当前document的频率成正比,与出现在全体语料库中的频率成反比。通俗理解,一个词在一篇文章中出现次数越多,这个词对这篇文章越重要;在全体语料中出现频率越多,说明,这个词只是一个常用词而已,两者乘积就是Tf-idf。注意:这里document不一定是文章,可能是句子之类的,或者是其他的。
公式为:
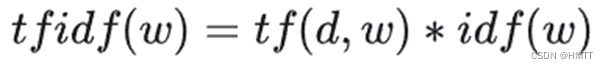
其中 t f ( d , w ) tf(d,w) tf(d,w) 是文档d中w的词频, i d f ( w ) = log N N ( w ) + 1 idf(w) = \log\frac{N}{N(w) + 1} idf(w)=logN(w)+1N ,+1是为了避免单词未出现导致分母为0。
- N表示预料中的文本总数
- N(w)表示w出现在多少个文档中。
当某个词在当前文档中出现频率比较高,而且在整体语料库中的出现的概率较小,这样的词会获得较大权重,因此TF-IDF倾向于过滤掉常见的词语,而保留对某一篇文档来说出现频率高的词。
这里需要补充一点,tf是一个词在当前文档中的词频,也就是这个词出现的次数,这里就引出了另外的一个问题,就是如果某篇文档的总词数远大于其他文档,那么不管重要与否它的词通常拥有更高的词频,因此通常对tf进行归一化,也就是用当前文档某个词的词频除以当前文档总词数。
计算n-gram的CIDEr
对于n-gram的某个特定情况,如n=1,2,…,会有一个特定的值 C I D E r n CIDEr_n CIDErn ,计算公式如下:
其中 g n ( c i ) \textbf{g}^\textbf{n}(c_i) gn(ci) 是一个向量,由所有当前设置n下的词组计算的 g k ( c i ) g_k(c_i) gk(ci) 构成, ∣ ∣ g ∣ ∣ ||\textbf{g}|| ∣∣g∣∣ 是向量的长度,用来归一化。 s i j s_{ij} sij 计算方式一样; j j j 为当前图片所拥有的给定描述长度。
简单来说, C I D E R n ( c i , S i ) = 1 / m ∑ j 所有 n − g r a m 词组对于 c i 的 g 构成的向量 ⋅ 所有 n − g r a m 对于 s i j 的 g 构成的向量 归一化 CIDER_n(c_i, S_i) = 1 / m \sum_j\frac{所有n-gram词组对于c_i的g构成的向量 \cdot 所有n-gram对于s_{ij}的g构成的向量}{归一化} CIDERn(ci,Si)=1/m∑j归一化所有n−gram词组对于ci的g构成的向量⋅所有n−gram对于sij的g构成的向量
这里的”所有n-gram词组”应该是 { w i ∣ w i ∈ c i or w i ∈ S i } \{w_i | w_i \in c_i \text{ or } w_i \in S_i \} {wi∣wi∈ci or wi∈Si} ,即候选句子和给定句子集合中的所有n-gram词组。
整体CIDEr
就是循环计算n=1,2,3,…的
C
I
D
E
r
n
CIDEr_n
CIDErn ,然后求均值: