GPT-3、GPT-4 等 LLM 及其开源版本经常难以检索最新信息,有时会产生幻觉或不正确的信息。
检索增强生成 (RAG)是一种将 LLM 的强大功能与外部知识检索相结合的技术。RAG 使我们能够将 LLM 响应建立在事实、最新的信息之上,从而显著提高 AI 生成内容的准确性和可靠性。
在这篇博文中,我们将探索如何从头开始为 RAG 构建 LLM 代理,深入研究架构、实现细节和高级技术。我们将涵盖从 RAG 基础知识到创建能够进行复杂推理和执行任务的复杂代理的所有内容。
在深入构建 LLM 代理之前,让我们先了解什么是 RAG 以及它为什么重要。
RAG(检索增强生成)是一种将信息检索与文本生成相结合的混合方法。在 RAG 系统中:
- 查询用于从知识库中检索相关文档。
- 然后将这些文档与原始查询一起输入到语言模型中。
- 该模型根据查询和检索到的信息生成响应。
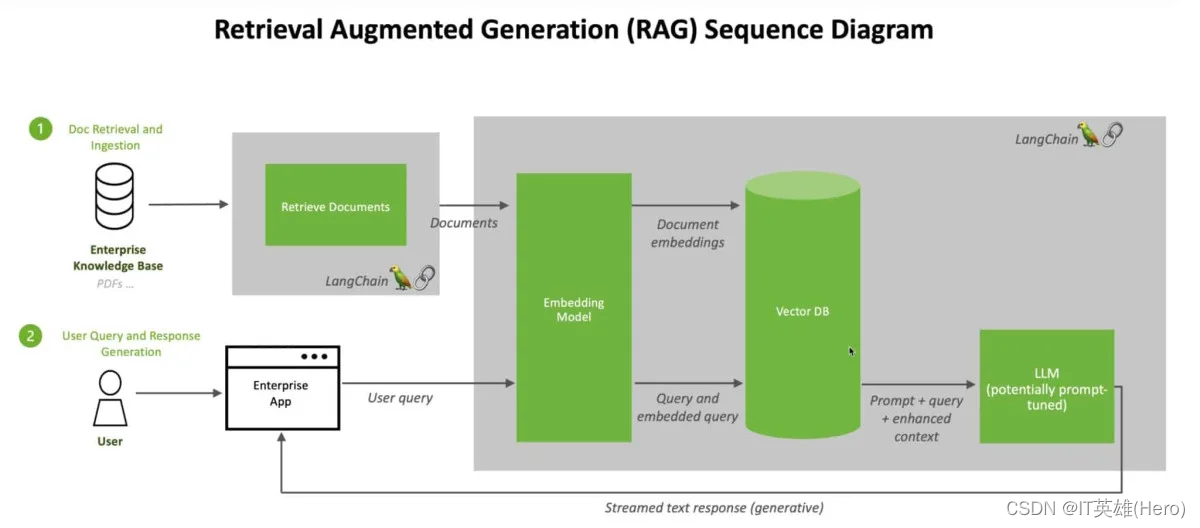
这种方法有几个优点: - 提高准确性:通过根据检索到的信息做出反应,RAG 可以减少幻觉并提高事实准确性。
- 最新信息:知识库可以定期更新,使系统能够访问最新信息。
- 用户评论透明:该系统可以提供信息来源,增加信任并允许核实事实。
了解 LLM 代理

当您面对一个没有简单答案的问题时,您通常需要遵循几个步骤,仔细思考,并记住您已经尝试过的方法。语言模型应用程序中的 LLM 代理正是为此类情况而设计的。它们结合了全面的数据分析、战略规划、数据检索以及从过去行动中学习的能力来解决复杂问题。
什么是 LLM 代理?
LLM 代理是先进的人工智能系统,专为创建需要顺序推理的复杂文本而设计。他们可以提前思考,记住过去的对话,并使用不同的工具根据情况和所需风格调整他们的反应。
考虑法律领域的一个问题,例如:“在加利福尼亚州,特定类型的合同违约可能产生什么法律后果?”具有检索增强生成 (RAG) 系统的基本法学硕士可以从法律数据库中获取必要的信息。
更详细的场景是:“鉴于新的数据隐私法,公司面临的常见法律挑战是什么,法院如何处理这些问题?”这个问题比仅仅查找事实更深入。它涉及了解新规则、它们对不同公司的影响以及法院的回应。法学硕士代理会将此任务分解为子任务,例如检索最新法律、分析历史案例、总结法律文件以及根据模式预测趋势。
LLM 代理的组件
LLM代理一般由四个部分组成:
- Agent/Brain:处理和理解语言的核心语言模型。
- 规划:推理、分解任务和制定具体计划的能力。
- 内存:保存过去交互的记录并从中学习。
- 工具使用: 集成各种资源来执行任务。
代理/大脑
LLM 代理的核心是语言模型,该模型基于经过大量训练的数据来处理和理解语言。首先,您需要给它一个特定的提示,指导代理如何响应、使用哪些工具以及要实现的目标。您可以使用适合特定任务或交互的角色来定制代理,从而提高其性能。
内存
记忆组件通过保存过去操作的记录来帮助 LLM 代理处理复杂任务。记忆主要有两种类型:
- 短期记忆: 就像一个记事本,记录正在进行的讨论。
- 长期记忆:像日记一样的功能,存储过去互动的信息以学习模式并做出更好的决策。
通过融合这些类型的记忆,代理可以提供更加定制化的响应并记住用户的长期偏好,从而创建更加紧密和相关的交互。
规划
规划使 LLM 代理能够推理、将任务分解为可管理的部分,并随着任务的发展调整计划。规划涉及两个主要阶段:
- 计划制定:将任务分解为更小的子任务。
- 计划反思:审查和评估计划的有效性,结合反馈意见完善策略。
思路链(CoT)和思路树(ToT)等方法有助于这一分解过程,让代理探索解决问题的不同路径。
设置环境
要构建我们的 RAG 代理,我们需要设置开发环境。我们将使用 Python 和几个关键库:
- 浪链:用于协调我们的 LLM 和检索组件
- 浓度:作为文档嵌入的向量存储
- OpenAI 的 GPT 模型:作为我们的基础 LLM(如果愿意,你可以用开源模型替代它)
- FastAPI:用于创建一个简单的 API 来与我们的代理进行交互
让我们开始设置我们的环境:
# Create a new virtual environment
python -m venv rag_agent_env
source rag_agent_env/bin/activate # On Windows, use `rag_agent_env\Scripts\activate`
# Install required packages
pip install langchain chromadb openai fastapi uvicorn
Now, let's create a new Python file called rag_agent.py and import the necessary libraries:
[code language="PYTHON"]
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.text_splitter import CharacterTextSplitter
from langchain.llms import OpenAI
from langchain.chains import RetrievalQA
from langchain.document_loaders import TextLoader
import os
# Set your OpenAI API key
os.environ["OPENAI_API_KEY"] = "your-api-key-here"
构建简单的RAG系统
现在我们已经设置好了环境,让我们构建一个基本的 RAG 系统。我们将首先从一组文档中创建一个知识库,然后使用它来回答查询。
步骤 1:准备文件
首先,我们需要加载并准备文档。在本例中,我们假设有一个名为 knowledge_base.txt 的文本文件,其中包含一些有关 AI 和机器学习的信息。
# Load the document
# Load the document
loader = TextLoader("knowledge_base.txt")
documents = loader.load()
# Split the documents into chunks
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
# Create embeddings
embeddings = OpenAIEmbeddings()
# Create a vector store
vectorstore = Chroma.from_documents(texts, embeddings)
步骤 2:创建基于检索的 QA 链
现在我们有了向量存储,我们可以创建一个基于检索的 QA 链:
# Create a retrieval-based QA chain
qa = RetrievalQA.from_chain_type(llm=OpenAI(), chain_type="stuff", retriever=vectorstore.as_retriever())
步骤 3:查询系统
我们现在可以查询我们的 RAG 系统:
query = "What are the main applications of machine learning?"
result = qa.run(query)
print(result)
步骤4:创建LLM代理
虽然我们简单的RAG系统很有用,但它非常有限。让我们通过创建一个LLM代理来增强它,该代理可以执行更复杂的任务并对它检索到的信息进行推理。
LLM代理是一种人工智能系统,它可以使用工具并决定采取哪些行动。我们将创建一个代理,它不仅可以回答问题,还可以执行网络搜索和基本计算。
首先,让我们为代理定义一些工具:
from langchain.agents import Tool
from langchain.tools import DuckDuckGoSearchRun
from langchain.tools import BaseTool
from langchain.agents import initialize_agent
from langchain.agents import AgentType
# Define a calculator tool
class CalculatorTool(BaseTool):
name = "Calculator"
description = "Useful for when you need to answer questions about math"
def _run(self, query: str)
try:
return str(eval(query))
except:
return "I couldn't calculate that. Please make sure your input is a valid mathematical expression."
# Create tool instances
search = DuckDuckGoSearchRun()
calculator = CalculatorTool()
# Define the tools
tools = [Tool(name="Search",func=search.run,description="Useful for when you need to answer questions about current events"),
Tool(name="RAG-QA",func=qa.run,description="Useful for when you need to answer questions about AI and machine learning"),
Tool(name="Calculator",func=calculator._run,description="Useful for when you need to perform mathematical calculations")
]
# Initialize the agent
agent = initialize_agent(tools, OpenAI(temperature=0), agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True
)
现在我们有了一个代理,它可以使用我们的RAG系统,执行web搜索和计算。让我们来测试一下:
result = agent.run("What's the difference between supervised and unsupervised learning? Also, what's 15% of 80?")
print(result)
这个代理展示了LLM代理的一个关键优势:它们可以组合多个工具和推理步骤来回答复杂的查询。
用先进的RAG技术增强Agent
虽然我们目前的RAG系统运行良好,但我们可以使用一些先进的技术来提高其性能:
a)基于密集通道检索(DPR)的语义搜索
与使用简单的基于嵌入的检索不同,我们可以实现DPR以实现更准确的语义搜索:
from transformers import DPRQuestionEncoder, DPRContextEncoder
question_encoder = DPRQuestionEncoder.from_pretrained("facebook/dpr-question_encoder-single-nq-base")
context_encoder = DPRContextEncoder.from_pretrained("facebook/dpr-ctx_encoder-single-nq-base")
# Function to encode passages
def encode_passages(passages):
return context_encoder(passages, max_length=512, return_tensors="pt").pooler_output
# Function to encode query
def encode_query(query):
return question_encoder(query, max_length=512, return_tensors="pt").pooler_output
b)查询扩展
我们可以使用查询扩展来提高检索性能:
from transformers import T5ForConditionalGeneration, T5Tokenizer
model = T5ForConditionalGeneration.from_pretrained("t5-small")
tokenizer = T5Tokenizer.from_pretrained("t5-small")
def expand_query(query):
input_text = f"expand query: {query}"
input_ids = tokenizer.encode(input_text, return_tensors="pt")
outputs = model.generate(input_ids, max_length=50, num_return_sequences=3)
expanded_queries = [tokenizer.decode(output, skip_special_tokens=True) for output in outputs]
return expanded_queries
c)迭代细化
我们可以实现一个迭代的细化过程,其中代理可以提出后续问题来澄清或扩展其初始检索:
def iterative_retrieval(initial_query, max_iterations=3):
query = initial_query
for _ in range(max_iterations):
result = qa.run(query)
clarification = agent.run(f"Based on this result: '{result}', what follow-up question should I ask to get more specific information?")
if clarification.lower().strip() == "none":
break
query = clarification
return result
# Use this in your agent's process
实现多智能体系统
为了处理更复杂的任务,我们可以实现一个多智能体系统,其中不同的智能体专注于不同的领域。这里有一个简单的例子:
class SpecialistAgent:
def __init__(self, name, tools):
self.name = name
self.agent = initialize_agent(tools, OpenAI(temperature=0), agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
def run(self, query):
return self.agent.run(query)
# Create specialist agents
research_agent = SpecialistAgent("Research", [Tool(name="RAG-QA", func=qa.run, description="For AI and ML questions")])
math_agent = SpecialistAgent("Math", [Tool(name="Calculator", func=calculator._run, description="For calculations")])
general_agent = SpecialistAgent("General", [Tool(name="Search", func=search.run, description="For general queries")])
class Coordinator:
def __init__(self, agents):
self.agents = agents
def run(self, query):
# Determine which agent to use
if "calculate" in query.lower() or any(op in query for op in ['+', '-', '*', '/']):
return self.agents['Math'].run(query)
elif any(term in query.lower() for term in ['ai', 'machine learning', 'deep learning']):
return self.agents['Research'].run(query)
else:
return self.agents['General'].run(query)
coordinator = Coordinator({'Research': research_agent, 'Math': math_agent, 'General': general_agent})
# Test the multi-agent system
result = coordinator.run("What's the difference between CNN and RNN? Also, calculate 25% of 120.")
print(result)
这种多代理系统允许专门化,可以更有效地处理更广泛的查询。
评估和优化RAG代理
为了确保我们的RAG代理运行良好,我们需要实施评估指标和优化技术:
a)相关性评价
我们可以使用BLEU、ROUGE或BERTScore等指标来评估检索文档的相关性:
from bert_score import score
def evaluate_relevance(query, retrieved_doc, generated_answer):
P, R, F1 = score([generated_answer], [retrieved_doc], lang="en")
return F1.mean().item()
b)答案质量评价
我们可以使用人工评估或自动化指标来评估答案的质量:
from nltk.translate.bleu_score import sentence_bleu
def evaluate_answer_quality(reference_answer, generated_answer):
return sentence_bleu([reference_answer.split()], generated_answer.split())
# Use this to evaluate your agent's responses
未来方向与挑战
当我们展望RAG代理的未来时,出现了几个令人兴奋的方向和挑战:
- 多模态RAG:扩展RAG以合并图像、音频和视频数据。
2.联邦RAG:跨分布式、保护隐私的知识库实现RAG。 - 持续学习:为RAG代理开发方法,以随时更新其知识库和模型。
- 伦理考虑:解决RAG系统中的偏见、公平性和透明度问题。
- 可扩展性:为大规模、实时应用优化RAG。
结论
从头开始为RAG构建LLM代理是一个复杂但有益的过程。我们已经介绍了RAG的基础知识,实现了一个简单的系统,创建了一个LLM代理,用高级技术增强了它,探索了多代理系统,并讨论了评估和优化策略。
在此,我满怀期待地邀请您,即刻启程,一同踏入这片充满机遇与启迪的网络空间,让知识的力量照亮我们的前行之路。您的每一次访问,都是对我们工作的最大肯定与激励;您的每一份收获,都是我们不懈努力的最佳回馈。期待在网站上与您相遇,共赴知识探索之约!---------深度学习。