这是我的第314篇原创文章。
一、引言
对于表格数据,一套完整的机器学习建模流程如下:

针对不同的数据集,有些步骤不适用,其中橘红色框为必要步骤,欢迎大家关注翻看我之前的一些相关文章。前面我介绍了机器学习模型的二分类任务和回归任务,接下来做一下机器学习的多分类系列,由于本系列案例数据质量较高,有些步骤跳过了,跳过的步骤将单独出文章总结!在Python中,可以使用Scikit-learn库来构建决策树分类模型进行多分类预测,本文以预测小麦品种为例,对这个过程做一个简要解读。
二、实现过程
2.1 准备数据
data = pd.read_csv(r'data.csv')
df = pd.DataFrame(data)
print(df.head())df:
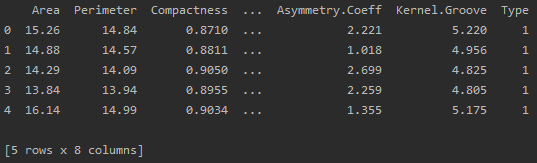
2.2 提取目标变量
target = 'Type'
features = df.columns.drop(target)
print(data["Type"].value_counts()) # 顺便查看一下样本是否平衡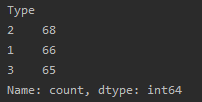
2.3 划分数据集
# df = shuffle(df)
X_train, X_test, y_train, y_test = train_test_split(df[features], df[target], test_size=0.2, random_state=0)2.4 归一化
# 此步可不做处理2.5 模型的构建
model = DecisionTreeClassifier(max_depth=5)2.6 模型的训练
model.fit(X_train, y_train)2.7 模型的推理
y_pred = model.predict(X_test)
y_scores = model.predict_proba(X_test)
print(y_pred)![]()
2.8 模型的评价
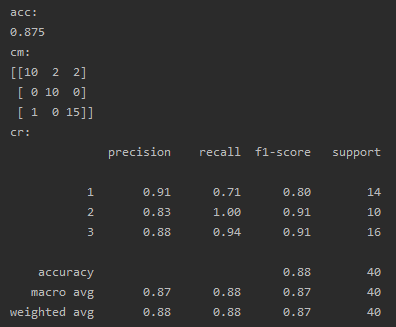
acc = accuracy_score(y_test, y_pred) # 准确率acc
print(f"acc: \n{acc}")
cm = confusion_matrix(y_test, y_pred) # 混淆矩阵
print(f"cm: \n{cm}")
cr = classification_report(y_test, y_pred) # 分类报告
print(f"cr: \n{cr}")结果:
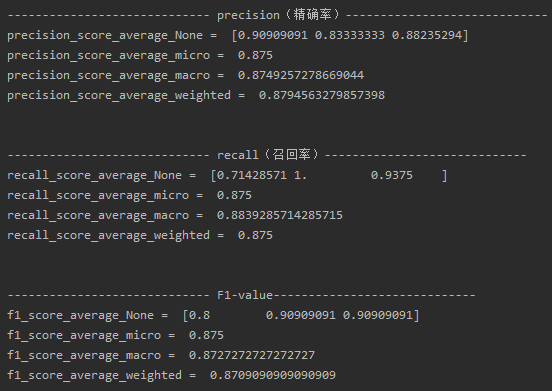
print("----------------------------- precision(精确率)-----------------------------")
precision_score_average_None = precision_score(y_test, y_pred, average=None)
precision_score_average_micro = precision_score(y_test, y_pred, average='micro')
precision_score_average_macro = precision_score(y_test, y_pred, average='macro')
precision_score_average_weighted = precision_score(y_test, y_pred, average='weighted')
print('precision_score_average_None = ', precision_score_average_None)
print('precision_score_average_micro = ', precision_score_average_micro)
print('precision_score_average_macro = ', precision_score_average_macro)
print('precision_score_average_weighted = ', precision_score_average_weighted)
print("\n\n----------------------------- recall(召回率)-----------------------------")
recall_score_average_None = recall_score(y_test, y_pred, average=None)
recall_score_average_micro = recall_score(y_test, y_pred, average='micro')
recall_score_average_macro = recall_score(y_test, y_pred, average='macro')
recall_score_average_weighted = recall_score(y_test, y_pred, average='weighted')
print('recall_score_average_None = ', recall_score_average_None)
print('recall_score_average_micro = ', recall_score_average_micro)
print('recall_score_average_macro = ', recall_score_average_macro)
print('recall_score_average_weighted = ', recall_score_average_weighted)
print("\n\n----------------------------- F1-value-----------------------------")
f1_score_average_None = f1_score(y_test, y_pred, average=None)
f1_score_average_micro = f1_score(y_test, y_pred, average='micro')
f1_score_average_macro = f1_score(y_test, y_pred, average='macro')
f1_score_average_weighted = f1_score(y_test, y_pred, average='weighted')
print('f1_score_average_None = ', f1_score_average_None)
print('f1_score_average_micro = ', f1_score_average_micro)
print('f1_score_average_macro = ', f1_score_average_macro)
print('f1_score_average_weighted = ', f1_score_average_weighted)结果:
作者简介:
读研期间发表6篇SCI数据挖掘相关论文,现在某研究院从事数据算法相关科研工作,结合自身科研实践经历不定期分享关于Python、机器学习、深度学习、人工智能系列基础知识与应用案例。致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。需要数据集和源码的小伙伴可以关注底部公众号添加作者微信。