摘要:
介绍了昇思MindSpore AI框架采用贪心搜索、集束搜索计算高概率词生成文本的方法、步骤,并为解决重复等问题所作的多种尝试。
这一节完全看不懂,猜测是如何用一定范围的词造句。
一、概念
自回归语言模型

文本序列概率分布
分解为每个词基于其上文的条件概率的乘积
![]()
W_0:初始上下文单词序列
T: 时间步
当生成EOS标签时,停止生成。
MindNLP/huggingface Transformers提供的文本生成方法
Greedy search
在每个时间步t输出概率最高的词:
Wt=argmax_w P(w|w(l::t-l))
贪心搜索输出序列("The","nice","woman") 的条件概率为:0.5 * 0.4 = 0.2
缺点:容易错过后面的高概率词
如:dog=0.5, has=0.9 
二、环境配置
%%capture captured_output
# 实验环境已经预装了mindspore==2.2.14,如需更换mindspore版本,可更改下面mindspore的版本号
!pip uninstall mindspore -y
!pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindspore==2.2.14
!pip uninstall mindvision -y
!pip uninstall mindinsight -y输出:
Found existing installation: mindvision 0.1.0
Uninstalling mindvision-0.1.0:
Successfully uninstalled mindvision-0.1.0
WARNING: Skipping mindinsight as it is not installed.# 该案例在 mindnlp 0.3.1 版本完成适配,如果发现案例跑不通,可以指定mindnlp版本,执行`!pip install mindnlp==0.3.1`
!pip install mindnlp输出:
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Requirement already satisfied: mindnlp in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (0.3.1)
Requirement already satisfied: mindspore in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from mindnlp) (2.2.14)
Requirement already satisfied: tqdm in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from mindnlp) (4.66.4)
Requirement already satisfied: requests in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from mindnlp) (2.32.3)
Requirement already satisfied: datasets in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from mindnlp) (2.20.0)
Requirement already satisfied: evaluate in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from mindnlp) (0.4.2)
Requirement already satisfied: tokenizers in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from mindnlp) (0.19.1)
Requirement already satisfied: safetensors in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from mindnlp) (0.4.3)
Requirement already satisfied: sentencepiece in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from mindnlp) (0.2.0)
Requirement already satisfied: regex in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from mindnlp) (2024.5.15)
Requirement already satisfied: addict in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from mindnlp) (2.4.0)
Requirement already satisfied: ml-dtypes in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from mindnlp) (0.4.0)
Requirement already satisfied: pyctcdecode in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from mindnlp) (0.5.0)
Requirement already satisfied: jieba in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from mindnlp) (0.42.1)
Requirement already satisfied: pytest==7.2.0 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from mindnlp) (7.2.0)
Requirement already satisfied: attrs>=19.2.0 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from pytest==7.2.0->mindnlp) (23.2.0)
Requirement already satisfied: iniconfig in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from pytest==7.2.0->mindnlp) (2.0.0)
Requirement already satisfied: packaging in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from pytest==7.2.0->mindnlp) (23.2)
Requirement already satisfied: pluggy<2.0,>=0.12 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from pytest==7.2.0->mindnlp) (1.5.0)
Requirement already satisfied: exceptiongroup>=1.0.0rc8 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from pytest==7.2.0->mindnlp) (1.2.0)
Requirement already satisfied: tomli>=1.0.0 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from pytest==7.2.0->mindnlp) (2.0.1)
Requirement already satisfied: filelock in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from datasets->mindnlp) (3.15.3)
Requirement already satisfied: numpy>=1.17 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from datasets->mindnlp) (1.26.4)
Requirement already satisfied: pyarrow>=15.0.0 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from datasets->mindnlp) (16.1.0)
Requirement already satisfied: pyarrow-hotfix in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from datasets->mindnlp) (0.6)
Requirement already satisfied: dill<0.3.9,>=0.3.0 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from datasets->mindnlp) (0.3.8)
Requirement already satisfied: pandas in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from datasets->mindnlp) (2.2.2)
Requirement already satisfied: xxhash in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from datasets->mindnlp) (3.4.1)
Requirement already satisfied: multiprocess in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from datasets->mindnlp) (0.70.16)
Requirement already satisfied: fsspec<=2024.5.0,>=2023.1.0 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from fsspec[http]<=2024.5.0,>=2023.1.0->datasets->mindnlp) (2024.5.0)
Requirement already satisfied: aiohttp in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from datasets->mindnlp) (3.9.5)
Requirement already satisfied: huggingface-hub>=0.21.2 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from datasets->mindnlp) (0.23.4)
Requirement already satisfied: pyyaml>=5.1 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from datasets->mindnlp) (6.0.1)
Requirement already satisfied: charset-normalizer<4,>=2 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from requests->mindnlp) (3.3.2)
Requirement already satisfied: idna<4,>=2.5 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from requests->mindnlp) (3.7)
Requirement already satisfied: urllib3<3,>=1.21.1 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from requests->mindnlp) (2.2.2)
Requirement already satisfied: certifi>=2017.4.17 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from requests->mindnlp) (2024.6.2)
Requirement already satisfied: protobuf>=3.13.0 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from mindspore->mindnlp) (5.27.1)
Requirement already satisfied: asttokens>=2.0.4 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from mindspore->mindnlp) (2.0.5)
Requirement already satisfied: pillow>=6.2.0 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from mindspore->mindnlp) (10.3.0)
Requirement already satisfied: scipy>=1.5.4 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from mindspore->mindnlp) (1.13.1)
Requirement already satisfied: psutil>=5.6.1 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from mindspore->mindnlp) (5.9.0)
Requirement already satisfied: astunparse>=1.6.3 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from mindspore->mindnlp) (1.6.3)
Requirement already satisfied: pygtrie<3.0,>=2.1 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from pyctcdecode->mindnlp) (2.5.0)
Requirement already satisfied: hypothesis<7,>=6.14 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from pyctcdecode->mindnlp) (6.104.2)
Requirement already satisfied: six in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from asttokens>=2.0.4->mindspore->mindnlp) (1.16.0)
Requirement already satisfied: wheel<1.0,>=0.23.0 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from astunparse>=1.6.3->mindspore->mindnlp) (0.43.0)
Requirement already satisfied: aiosignal>=1.1.2 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from aiohttp->datasets->mindnlp) (1.3.1)
Requirement already satisfied: frozenlist>=1.1.1 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from aiohttp->datasets->mindnlp) (1.4.1)
Requirement already satisfied: multidict<7.0,>=4.5 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from aiohttp->datasets->mindnlp) (6.0.5)
Requirement already satisfied: yarl<2.0,>=1.0 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from aiohttp->datasets->mindnlp) (1.9.4)
Requirement already satisfied: async-timeout<5.0,>=4.0 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from aiohttp->datasets->mindnlp) (4.0.3)
Requirement already satisfied: typing-extensions>=3.7.4.3 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from huggingface-hub>=0.21.2->datasets->mindnlp) (4.11.0)
Requirement already satisfied: sortedcontainers<3.0.0,>=2.1.0 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from hypothesis<7,>=6.14->pyctcdecode->mindnlp) (2.4.0)
Requirement already satisfied: python-dateutil>=2.8.2 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from pandas->datasets->mindnlp) (2.9.0.post0)
Requirement already satisfied: pytz>=2020.1 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from pandas->datasets->mindnlp) (2024.1)
Requirement already satisfied: tzdata>=2022.7 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from pandas->datasets->mindnlp) (2024.1)
[notice] A new release of pip is available: 24.1 -> 24.1.1
[notice] To update, run: python -m pip install --upgrade pip三、贪心搜索Greedy search
#greedy_search
from mindnlp.transformers import GPT2Tokenizer, GPT2LMHeadModel
tokenizer = GPT2Tokenizer.from_pretrained("iiBcai/gpt2", mirror='modelscope')
# add the EOS token as PAD token to avoid warnings
model = GPT2LMHeadModel.from_pretrained("iiBcai/gpt2", pad_token_id=tokenizer.eos_token_id, mirror='modelscope')
# encode context the generation is conditioned on
input_ids = tokenizer.encode('I enjoy walking with my cute dog', return_tensors='ms')
# generate text until the output length (which includes the context length) reaches 50
greedy_output = model.generate(input_ids, max_length=50)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(greedy_output[0], skip_special_tokens=True))输出:
Building prefix dict from the default dictionary ...
Dumping model to file cache /tmp/jieba.cache
Loading model cost 1.006 seconds.
Prefix dict has been built successfully.
100%---------------------------------------- 26.0/26.0 [00:00<00:00, 1.63kB/s]
100%---------------------------------------- 0.99M/0.99M [00:00<00:00, 18.9MB/s]
100%---------------------------------------- 446k/446k [00:00<00:00, 7.49MB/s]
100%---------------------------------------- 1.29M/1.29M [00:00<00:00, 18.0MB/s]
100%---------------------------------------- 665/665 [00:00<00:00, 49.7kB/s]
100%---------------------------------------- 523M/523M [00:42<00:00, 17.2MB/s]Output:
-------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with my dog. I'm not sure if I'll ever be able to walk with my dog.
I'm not sure if I'll四、集束搜索Beam search
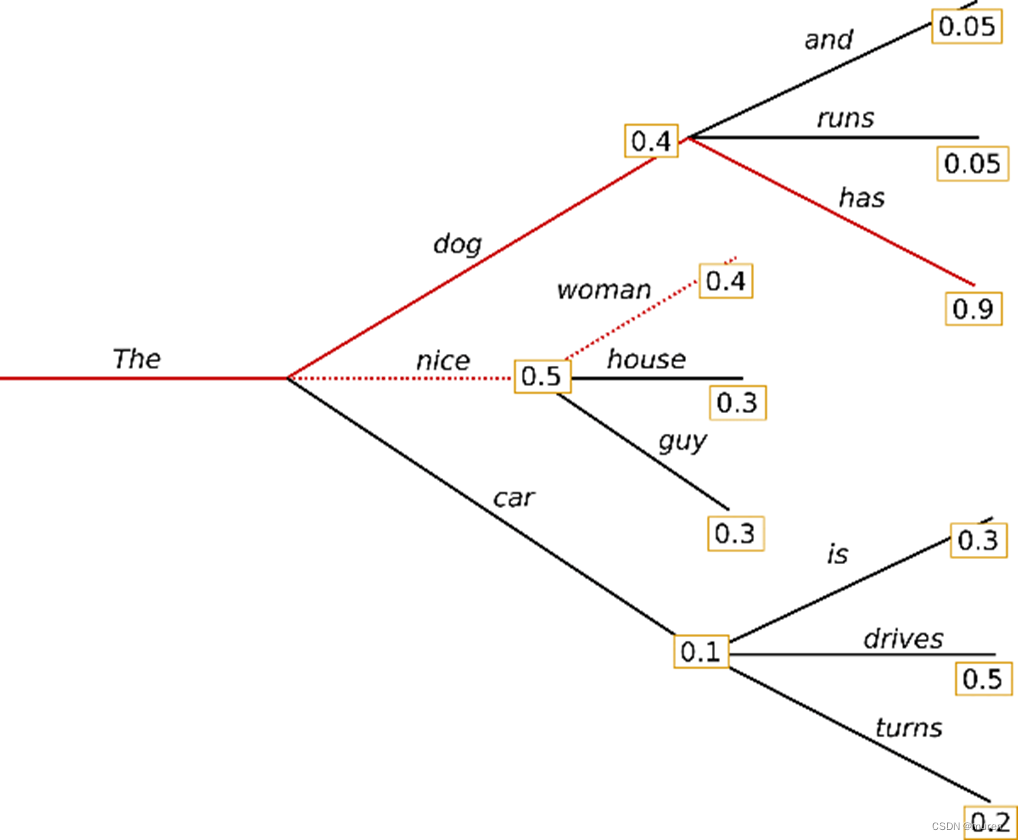
每个时间步保留最可能的 num_beams 个词,选择概率最高的序列。
如图以 num_beams=2 为例:
("The","dog" ,"has" ) : 0.4 * 0.9 = 0.36
("The","nice","woman") : 0.5 * 0.4 = 0.20
优点:一定程度保留最优路径
缺点:
1. 无法解决重复问题;
2. 开放域生成效果差
from mindnlp.transformers import GPT2Tokenizer, GPT2LMHeadModel
tokenizer = GPT2Tokenizer.from_pretrained("iiBcai/gpt2", mirror='modelscope')
# add the EOS token as PAD token to avoid warnings
model = GPT2LMHeadModel.from_pretrained("iiBcai/gpt2", pad_token_id=tokenizer.eos_token_id, mirror='modelscope')
# encode context the generation is conditioned on
input_ids = tokenizer.encode('I enjoy walking with my cute dog', return_tensors='ms')
# activate beam search and early_stopping
beam_output = model.generate(
input_ids,
max_length=50,
num_beams=5,
early_stopping=True
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(beam_output[0], skip_special_tokens=True))
print(100 * '-')
# set no_repeat_ngram_size to 2
beam_output = model.generate(
input_ids,
max_length=50,
num_beams=5,
no_repeat_ngram_size=2,
early_stopping=True
)
print("Beam search with ngram, Output:\n" + 100 * '-')
print(tokenizer.decode(beam_output[0], skip_special_tokens=True))
print(100 * '-')
# set return_num_sequences > 1
beam_outputs = model.generate(
input_ids,
max_length=50,
num_beams=5,
no_repeat_ngram_size=2,
num_return_sequences=5,
early_stopping=True
)
# now we have 3 output sequences
print("return_num_sequences, Output:\n" + 100 * '-')
for i, beam_output in enumerate(beam_outputs):
print("{}: {}".format(i, tokenizer.decode(beam_output, skip_special_tokens=True)))
print(100 * '-')输出:
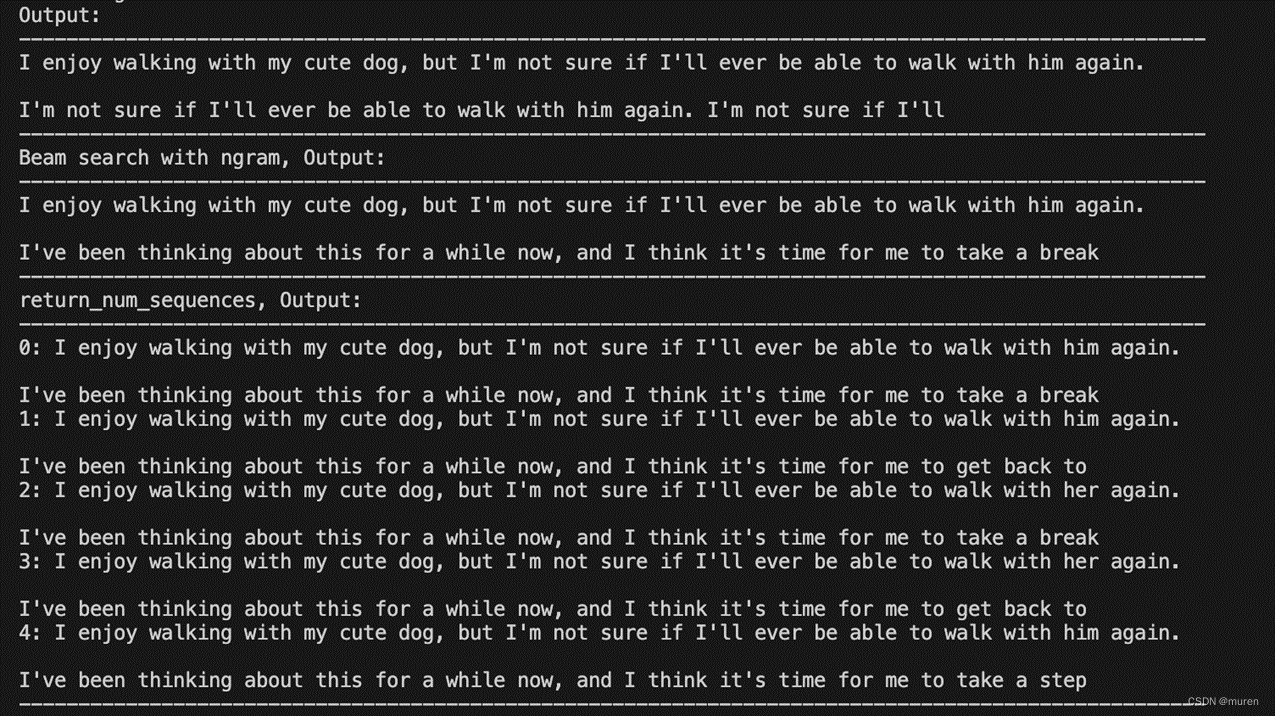
-------------------------------------------------------------------------------------------------I enjoy walking with my cute dog, but I don't think I'll ever be able to walk with her again."
"I don't think I'll ever be able to walk with her again."
"I don't think I
-------------------------------------------------------------------------------------------------
Beam search with ngram, Output:
-------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog, but I don't think I'll ever be able to walk with her again."
"I'm not sure what to say to that," she said. "I mean, it's not like I'm
-------------------------------------------------------------------------------------------------
return_num_sequences, Output:
-------------------------------------------------------------------------------------------------
0: I enjoy walking with my cute dog, but I don't think I'll ever be able to walk with her again."
"I'm not sure what to say to that," she said. "I mean, it's not like I'm
1: I enjoy walking with my cute dog, but I don't think I'll ever be able to walk with her again."
"I'm not sure what to say to that," she said. "I mean, it's not like she's
2: I enjoy walking with my cute dog, but I don't think I'll ever be able to walk with her again."
"I'm not sure what to say to that," she said. "I mean, it's not like we're
3: I enjoy walking with my cute dog, but I don't think I'll ever be able to walk with her again."
"I'm not sure what to say to that," she said. "I mean, it's not like I've
4: I enjoy walking with my cute dog, but I don't think I'll ever be able to walk with her again."
"I'm not sure what to say to that," she said. "I mean, it's not like I can
-------------------------------------------------------------------------------------------------五、集束搜索的问题
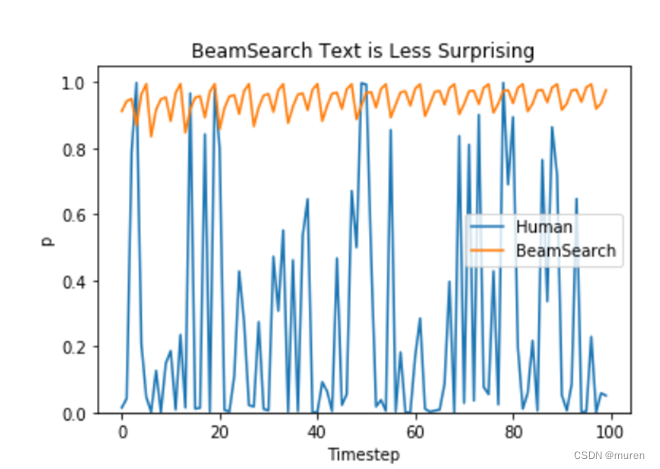
重复问题


n-gram 惩罚:
候选词再现概率设置为 0
设置no_repeat_ngram_size=2 ,任意 2-gram 不会出现两次
Notice: 实际文本生成需要重复出现
Sample
根据当前条件概率分布随机选择输出词
![]()
("car") ~P(w∣"The")("drives") ~P(w∣"The","car")
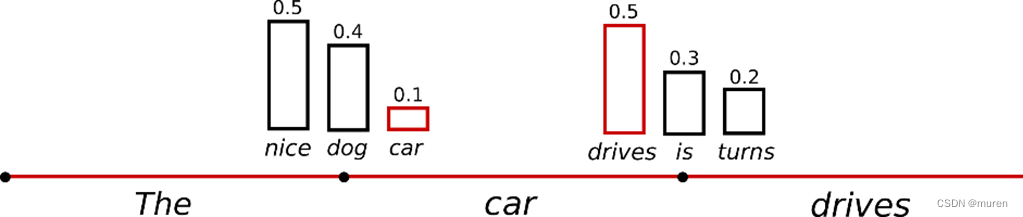
优点:文本生成多样性高
缺点:生成文本不连续
import mindspore
from mindnlp.transformers import GPT2Tokenizer, GPT2LMHeadModel
tokenizer = GPT2Tokenizer.from_pretrained("iiBcai/gpt2", mirror='modelscope')
# add the EOS token as PAD token to avoid warnings
model = GPT2LMHeadModel.from_pretrained("iiBcai/gpt2", pad_token_id=tokenizer.eos_token_id, mirror='modelscope')
# encode context the generation is conditioned on
input_ids = tokenizer.encode('I enjoy walking with my cute dog', return_tensors='ms')
mindspore.set_seed(0)
# activate sampling and deactivate top_k by setting top_k sampling to 0
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=0
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))输出:
-------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog Neddy as much as I'd like. Keep up the good work Neddy!"
I realized what Neddy meant when he first launched the website. "Thank you so much for joining."
ITemperature
降低softmax 的temperature使 P(w∣w1:t−1)分布更陡峭
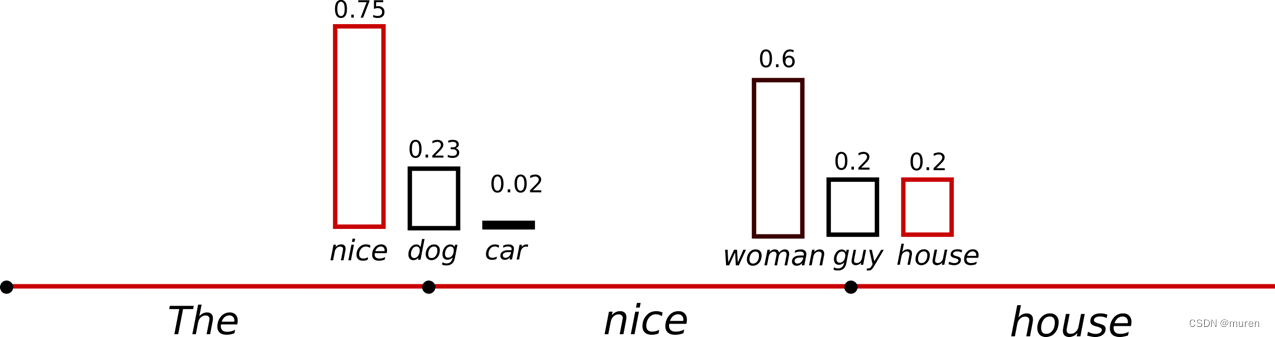
增加高概率单词的似然
降低低概率单词的似然
import mindspore
from mindnlp.transformers import GPT2Tokenizer, GPT2LMHeadModel
tokenizer = GPT2Tokenizer.from_pretrained("iiBcai/gpt2", mirror='modelscope')
# add the EOS token as PAD token to avoid warnings
model = GPT2LMHeadModel.from_pretrained("iiBcai/gpt2", pad_token_id=tokenizer.eos_token_id, mirror='modelscope')
# encode context the generation is conditioned on
input_ids = tokenizer.encode('I enjoy walking with my cute dog', return_tensors='ms')
mindspore.set_seed(1234)
# activate sampling and deactivate top_k by setting top_k sampling to 0
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=0,
temperature=0.7
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))输出:
-------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog and have never had a problem with her until now.
A large dog named Chucky managed to get a few long stretches of grass on her back and ran around with it for about 5 minutes, ran aroundTopK sample
选出概率最大的 K 个词,重新归一化,最后在归一化后的 K 个词中采样
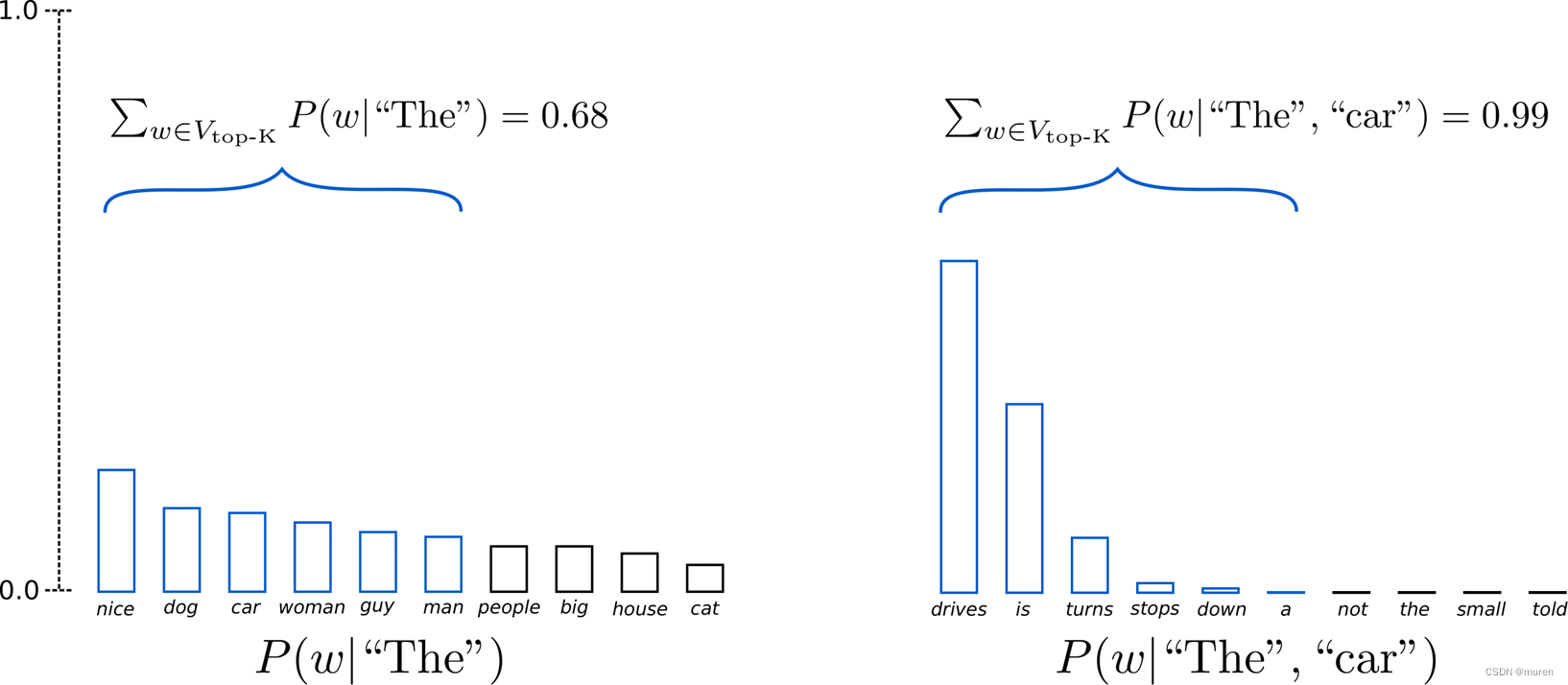
将采样池限制为固定大小 K :
- 在分布比较尖锐的时候产生胡言乱语
- 在分布比较平坦的时候限制模型的创造力
import mindspore
from mindnlp.transformers import GPT2Tokenizer, GPT2LMHeadModel
tokenizer = GPT2Tokenizer.from_pretrained("iiBcai/gpt2", mirror='modelscope')
# add the EOS token as PAD token to avoid warnings
model = GPT2LMHeadModel.from_pretrained("iiBcai/gpt2", pad_token_id=tokenizer.eos_token_id, mirror='modelscope')
# encode context the generation is conditioned on
input_ids = tokenizer.encode('I enjoy walking with my cute dog', return_tensors='ms')
mindspore.set_seed(0)
# activate sampling and deactivate top_k by setting top_k sampling to 0
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=50
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))输出:
-------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog.
She's always up for some action, so I have seen her do some stuff with it.
Then there's the two of us.
The two of us I'm talking about wereTop-P sample
在累积概率超过概率 p 的最小单词集中进行采样,重新归一化
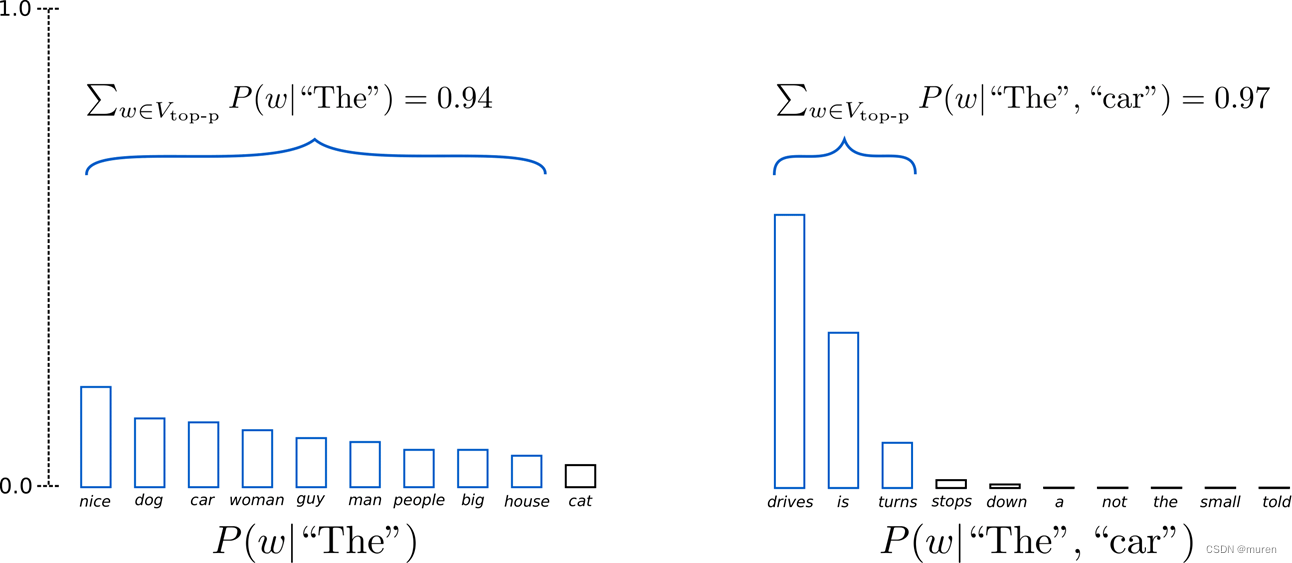
采样池可以根据下一个词的概率分布动态增加和减少
import mindspore
from mindnlp.transformers import GPT2Tokenizer, GPT2LMHeadModel
tokenizer = GPT2Tokenizer.from_pretrained("iiBcai/gpt2", mirror='modelscope')
# add the EOS token as PAD token to avoid warnings
model = GPT2LMHeadModel.from_pretrained("iiBcai/gpt2", pad_token_id=tokenizer.eos_token_id, mirror='modelscope')
# encode context the generation is conditioned on
input_ids = tokenizer.encode('I enjoy walking with my cute dog', return_tensors='ms')
mindspore.set_seed(0)
# deactivate top_k sampling and sample only from 92% most likely words
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_p=0.92,
top_k=0
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))输出:
-------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog Neddy as much as I'd like. Keep up the good work Neddy!"
I realized what Neddy meant when he first launched the website. "Thank you so much for joining."
Itop_k_top_p
import mindspore
from mindnlp.transformers import GPT2Tokenizer, GPT2LMHeadModel
tokenizer = GPT2Tokenizer.from_pretrained("iiBcai/gpt2", mirror='modelscope')
# add the EOS token as PAD token to avoid warnings
model = GPT2LMHeadModel.from_pretrained("iiBcai/gpt2", pad_token_id=tokenizer.eos_token_id, mirror='modelscope')
# encode context the generation is conditioned on
input_ids = tokenizer.encode('I enjoy walking with my cute dog', return_tensors='ms')
mindspore.set_seed(0)
# set top_k = 50 and set top_p = 0.95 and num_return_sequences = 3
sample_outputs = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=5,
top_p=0.95,
num_return_sequences=3
)
print("Output:\n" + 100 * '-')
for i, sample_output in enumerate(sample_outputs):
print("{}: {}".format(i, tokenizer.decode(sample_output, skip_special_tokens=True)))输出:
-------------------------------------------------------------------------------------------------
0: I enjoy walking with my cute dog.
"My dog loves the smell of the dog. I'm so happy that she's happy with me.
"I love to walk with my dog. I'm so happy that she's happy
1: I enjoy walking with my cute dog. I'm a big fan of my cat and her dog, but I don't have the same enthusiasm for her. It's hard not to like her because it is my dog.
My husband, who
2: I enjoy walking with my cute dog, but I'm also not sure I would want my dog to walk alone with me."
She also told The Daily Beast that the dog is very protective.
"I think she's very protective of