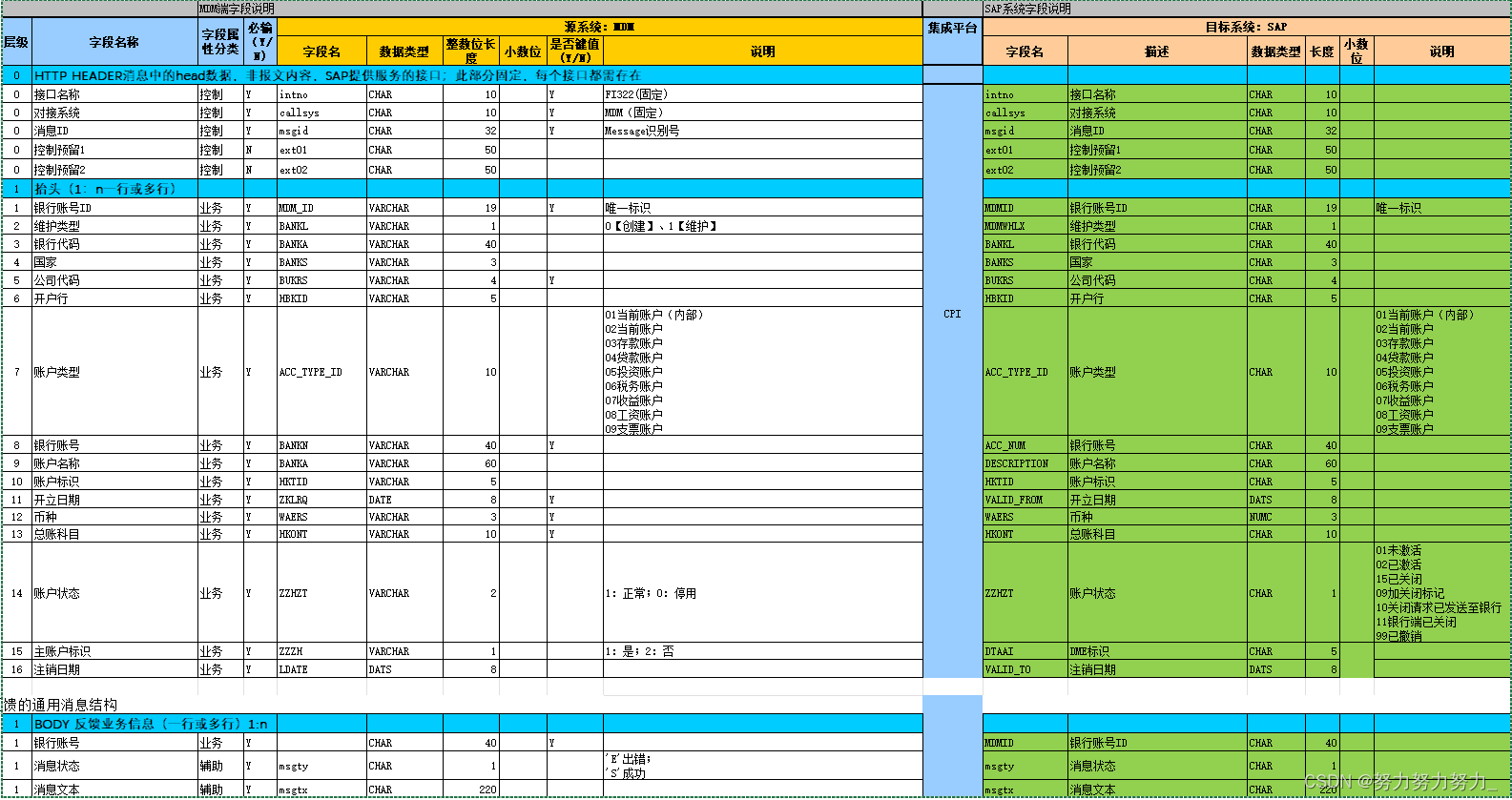
内容提示:
mdb数据转出为gdb,应保留原mdb的库体结构。库体结构中,应该正确处理数据集、要素类和表之间的结构。
数据集:保持数据集结构;
要素类:要素类位于mdb根目录或数据集下;
表:表位于mdb根目录。
要实现mdb转gdb后,数据库库体结构保持一致,不是一件容易的事,本文完整记录了解析mdb库体结构的过程。
图很多,内容可能有一些难度,感兴趣的朋友,可以动手做一做。
![]()
-
mdb(个人地理数据库)转shape file其实并不简单
1、 pyodbc 解析mdb库体结构
将mdb转为gdb,第一步就是先解析mdb库体结构,得到mdb下数据集、要素类、表之间的组织结构,以及创建数据集、要素类和表所需要的信息,如空间参考、名称、字段属性信息等。
获取的mdb地理数据库,可能存在多个数据集,数据集下可能存在要素类,也可能为空,并且有些要素类和表位于mdb根目录。
mdb地理数据示意如下:
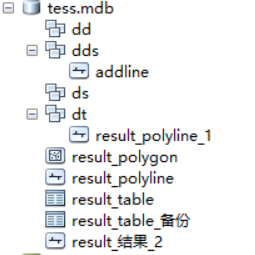
1.1 使用odb解析mdb库体结构
01 使用odbc读取mdb
# 定义连接字符串和MDB文件路径driver = '{Microsoft Access Driver (*.mdb, *.accdb)}'mdb_file = r"D:\data\tess.mdb"conn_str = f'Driver={driver};DBQ={mdb_file}'# 执行连接conn = pyodbc.connect(conn_str)
(1)很可能会报错:
ERROR 1: Unable to initialize ODBC connection to DSN
(2)需要安装:
![]()
直接双击安装,可能会报如下错误:
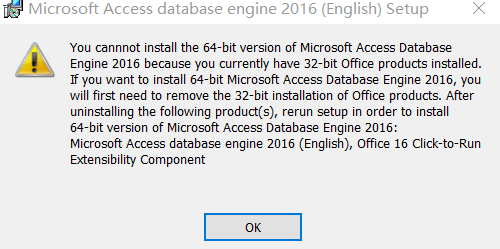
在命令行窗口,找到AccessDatabaseEngine_X64.exe所在目录,执行如下命令即可:
AccessDatabaseEngine_X64.exe /quiet
(3)列出mdb中的所有表:
import pyodbc# 定义MDB文件路径和ODBC驱动mdb_file = r"D:\data\tess.mdb"driver = '{Microsoft Access Driver (*.mdb, *.accdb)}'# 连接到数据库conn = pyodbc.connect(f'Driver={driver};DBQ={mdb_file}')cursor = conn.cursor()# 获取所有表名tables = cursor.tables(tableType='TABLE')# 输出所有表名for table in tables:print(table.table_name)# 关闭连接cursor.close()conn.close()
输出中,对比mdb示意中的数据,能快速发现一堆不认识的表名,如下图绿色边框所示,可能和存放了mdb中一些特别的信息。
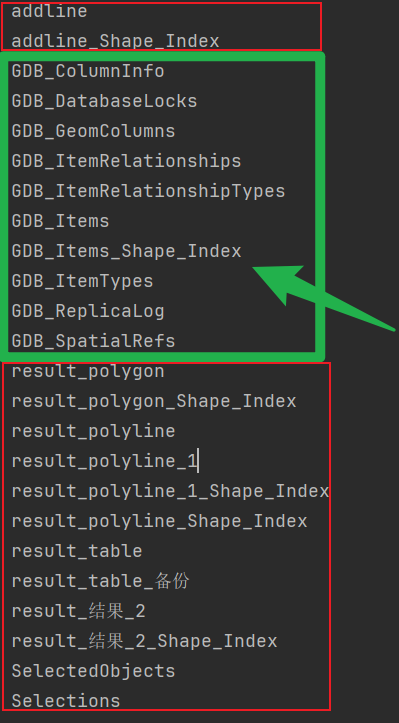
(4)获取数据库中的系统表格信息
实际上,这些以“MDB”开头的表,事mdb的系统表。存放着地理信息数据相关的信息。我们需要打开这些表,进一步分析。
获取系统表信息的代码如下:
import pandas as pdimport pyodbcmdb_file = r"D:\data\tess.mdb"driver = '{Microsoft Access Driver (*.mdb, *.accdb)}'conn = pyodbc.connect(f'Driver={driver};DBQ={mdb_file}')cursor = conn.cursor()# 获取数据库中的系统表格信息system_tables = ["GDB_ColumnInfo","GDB_DatabaseLocks","GDB_GeomColumns","GDB_ItemRelationships","GDB_ItemRelationshipTypes","GDB_Items","GDB_Items_Shape_Index","GDB_ItemTypes","GDB_ReplicaLog","GDB_SpatialRefs"]for table1 in system_tables:# 获取每个表的列信息cursor.execute(f"SELECT * FROM [{table1}]")table1_columns = [column[0] for column in cursor.description]# 获取查询结果rows = cursor.fetchall()if len(rows) == 0:continuetable1_val = []for row in rows:# 将每个表的字段值分别存放在不同的列表中table1_val.append([val for idx, val in enumerate(row) if idx < len(table1_columns)])table2_df = pd.DataFrame(table1_val, columns=table1_columns)print(f"表{table1}数据:")print(table2_df)
每个表格对应的字段信息如下:
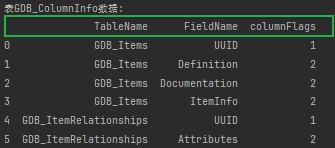
GDB_ColumnInfo(GDB列信息):这张表存储了地理数据库中每个表的列信息,包括表名、字段名以及列的标志位。
GDB_GeomColumns(GDB几何列):这张表包含了地理数据库中几何列的信息,包括表名、字段名、几何类型、空间范围以及其他几何相关的属性。

GDB_ItemRelationships(GDB项关系):这张表记录了地理数据库中各项之间的关系,包括源项、目标项、关系类型以及一些属性。

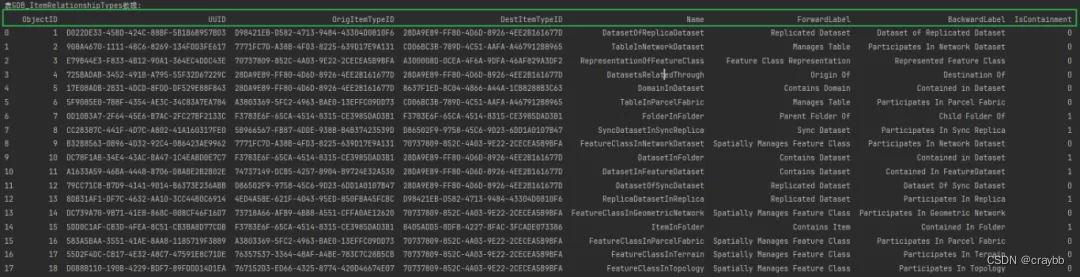
GDB_ItemRelationshipTypes(GDB项关系类型):这张表存储了地理数据库中项之间关系的类型信息,包括关系类型的UUID、原始项类型ID、目标项类型ID以及前向和后向标签等。
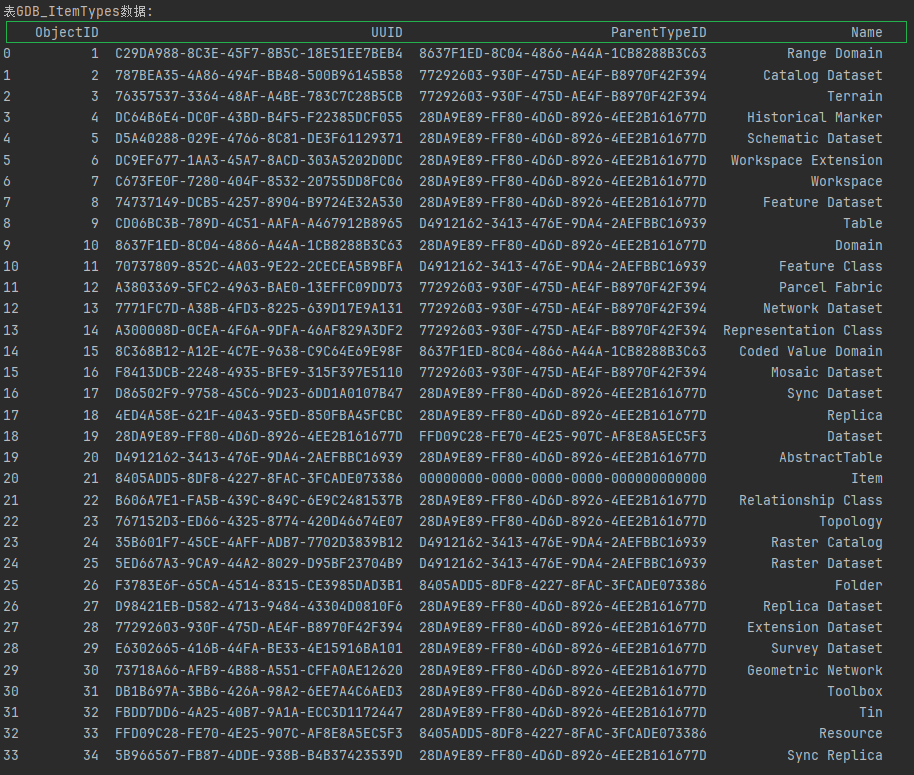
GDB_Items(GDB项):这张表包含了地理数据库中所有项的基本信息,包括项的UUID、类型、名称、物理名称、路径、数据集子类型等。

终于,出现了我们熟悉的内容:
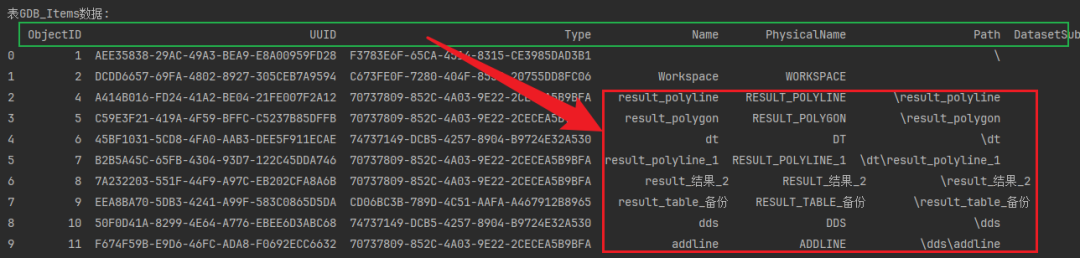
GDB_Items_Shape_Index 的表存储了地理数据库中各项几何形状的索引信息
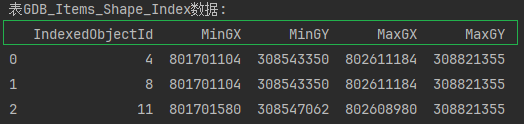
GDB_ItemTypes(GDB项类型):这张表定义了地理数据库中项的类型,包括项类型的UUID、父类型ID和名称等。
GDB_SpatialRefs表提供了地理数据库中使用的各种空间参考的详细信息,包括了坐标系的定义、偏移量、单位和容差等信息。

(5)系统表之间的关联分析
从步骤(4)中对各个表格信息的查看,似乎都看不懂这些信息是什么意思。只有表GDB_Items中出现了mdb中的图层名。
因此,找出表之间的关联,尤其是与表GDB_Items的关联,似乎就能找到答案。
system_tables = [
"GDB_ColumnInfo",
"GDB_DatabaseLocks",
"GDB_GeomColumns",
"GDB_ItemRelationships",
"GDB_ItemRelationshipTypes",
"GDB_Items",
"GDB_Items_Shape_Index",
"GDB_ItemTypes",
"GDB_ReplicaLog",
"GDB_SpatialRefs"
]
系统表之间关联分析的代码实现如下:
import pyodbcimport pandas as pddef get_conn(mdb_file):# 定义连接字符串和MDB文件路径driver = '{Microsoft Access Driver (*.mdb, *.accdb)}'conn_str = f'Driver={driver};DBQ={mdb_file}'conn = pyodbc.connect(conn_str)return conndef check_relations(conn):# 执行连接cursor = conn.cursor()# 定义要合并的系统表system_tables = ["GDB_ColumnInfo","GDB_DatabaseLocks","GDB_GeomColumns","GDB_ItemRelationships","GDB_ItemRelationshipTypes","GDB_Items","GDB_Items_Shape_Index","GDB_ItemTypes","GDB_ReplicaLog","GDB_SpatialRefs"]# 获取每个表的列信息table_columns = {}for table_name in system_tables:cursor.execute(f"SELECT * FROM [{table_name}]")columns = [column[0] for column in cursor.description]table_columns[table_name] = columns# 预先设置每个单元格的长度cell_length = 30 # 调整为 26 来保持一致性# 打印表之间的关系print("Table Relations:")split_line = "+" + "-" * ((len(system_tables) + 1) * cell_length) + "+"print(split_line)# 打印表头row = " " * cell_length + "|"for table_name in system_tables:row += f" {table_name.center(cell_length)}|"print(row)# 打印分割线print(split_line)# 打印表之间的关系table_relations = []for idx, table_name1 in enumerate(system_tables):row = f"| {table_name1.center(cell_length)} |"for table_name2 in system_tables:if table_name1 != table_name2: # 排除同一个表之间的关系common_columns = set(table_columns[table_name1]) & set(table_columns[table_name2])if common_columns:table_relations.append([table_name1, table_name2])row += f"{' √ '.center(cell_length)}|"else:row += f"{' - '.center(cell_length)}|"else:row += f"{' - '.center(cell_length)}|"print(row)# 打印分割线print(split_line)# # 关闭连接cursor.close()# 使用集合去除重复关系unique_relations = {tuple(sorted(relation)) for relation in table_relations}# 将集合转换回列表形式table_relations = [list(relation) for relation in unique_relations]return table_relationsif __name__ == '__main__':mdb_file = r"D:\data\tess.mdb"# 执行连接conn = get_conn(mdb_file)table_relations = check_relations(conn)
表格有点长,可能需要放大才能看清楚。
在对表之间的关联分析时,我们采取判断两个表是否存在相同的字段名,再将同名字段作为“键”进行连接分析。
表之间,使用二维矩阵对其进行查看,表格值为“√”的,代表两个表格至少存在一个同名字段。表之间的关系如下:

将存在同名字段的表关系提取如下:
1:['GDB_ItemRelationships', 'GDB_Items']
2:['GDB_ItemRelationshipTypes', 'GDB_ItemRelationships']
3:['GDB_ItemRelationshipTypes', 'GDB_ItemTypes']
4:['GDB_ColumnInfo', 'GDB_GeomColumns']
5:['GDB_GeomColumns', 'GDB_SpatialRefs']
6:['GDB_ItemTypes', 'GDB_Items']
7:['GDB_ItemRelationships', 'GDB_ItemTypes']
8:['GDB_ItemRelationshipTypes', 'GDB_Items']
(6)关联表分析
步骤(5)中说明,需要重点关注表GDB_Items。因此从存在同名字段的关联表之间找出与GDB_Items相关的记录。
此外,作为创建数据集、要素类时必须的参数“空间参考”,应该从表GDB_SpatialRefs中获取。
若需要了解表结构关系,需要重点关注:
1: ['GDB_ItemRelationships','GDB_Items']
2: ['GDB_ItemRelationshipTypes', 'GDB_Items']
3: ['GDB_ItemTypes', 'GDB_Items']
若需要了解表属性,则需要重点关注:
4: ['GDB_GeomColumns', 'GDB_SpatialRefs']
基于同名字段分析两个表之间联系的代码如下:
def join_tables(conn, table1, table2):cursor = conn.cursor()# 获取每个表的列信息cursor.execute(f"SELECT * FROM [{table1}]")table1_columns = [column[0] for column in cursor.description]cursor.execute(f"SELECT * FROM [{table2}]")table2_columns = [column[0] for column in cursor.description]# 获取公共列common_columns = set(table1_columns) & set(table2_columns)# 如果没有公共列,直接返回if not common_columns:print("没有公共列,无法执行连接查询。")return# 对每个公共列创建单独的查询for col in common_columns:# 构建查询语句query = f"""SELECT {table1}.*, {table2}.*FROM [{table1}] INNER JOIN [{table2}]ON {table1}.[{col}] = {table2}.[{col}]"""# 执行查询cursor.execute(query)# 获取查询结果rows = cursor.fetchall()if len(rows) == 0:continue# 打印查询结果print(f"查询结果(基于公共列 '{col}'):")table1_val = []table2_val = []for row in rows:# 将每个表的字段值分别存放在不同的列表中table1_val.append([val for idx, val in enumerate(row) if idx < len(table1_columns)])table2_val.append([val for idx, val in enumerate(row) if idx >= len(table1_columns)])# 将列表转换为DataFrametable1_df = pd.DataFrame(table1_val, columns=table1_columns)table2_df = pd.DataFrame(table2_val, columns=table2_columns)# 打印DataFrameprint(f"表{table1}数据:")print(table1_df)print(f"表{table2}数据:")print(table2_df)# 关闭连接cursor.close()table_relations = [['GDB_ItemTypes', 'GDB_Items'],['GDB_ItemRelationshipTypes', 'GDB_Items'],['GDB_ItemRelationships', 'GDB_Items'],['GDB_GeomColumns', 'GDB_SpatialRefs']]for i, j in enumerate(table_relations):print(f"{i + 1}: {j}")join_tables(conn, j[0], j[1])
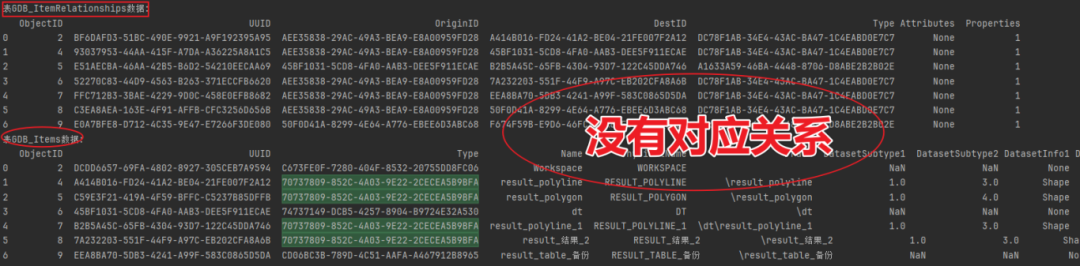
(1)['GDB_ItemRelationships','GDB_Items']
通过分析,在表GDB_ItemRelationships与表GDB_Items的属性值之间,未找到明显的对应关系。
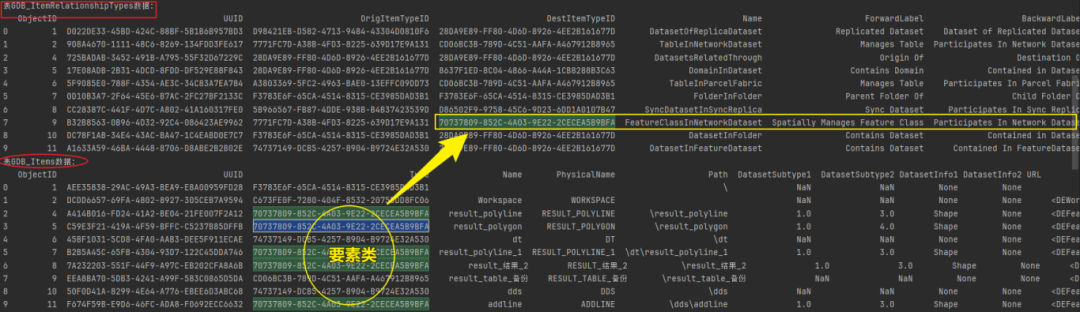
(2)['GDB_ItemRelationships','GDB_Items']
通过表GDB_ItemRelationships和表GDB_Items的属性值关联分析,明显发现,要素类、数据集和表之间存在着关联属性值。
# 查询要素类,可通过构建如下查询语句实现。
feature_class_query = """
SELECT A.NAME
FROM GDB_ITEMS A, GDB_ItemRelationshipTypes B
WHERE A.Type = B.DestItemTypeID AND B.NAME = 'FeatureClassInNetworkDataset'
"""
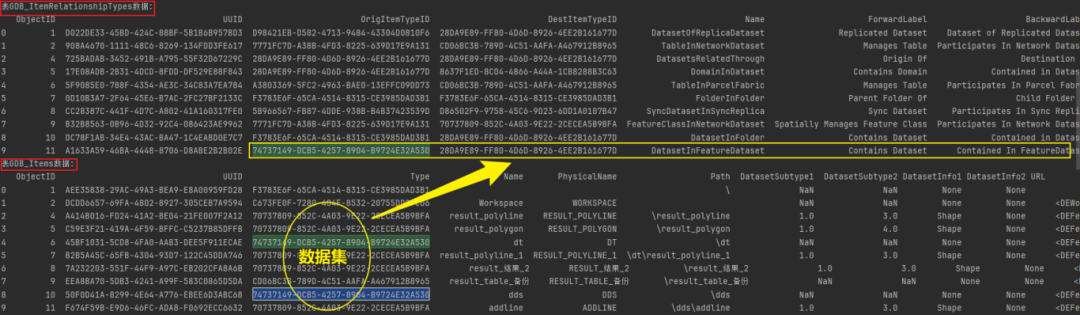
# 查询数据集,可通过构建如下查询语句实现。
feature_class_query = """
SELECT A.NAME
FROM GDB_ITEMS A, GDB_ItemRelationshipTypes B
WHERE A.Type = B.OrigItemTypeID AND B.NAME = 'DatasetInFeatureDataset'
"""
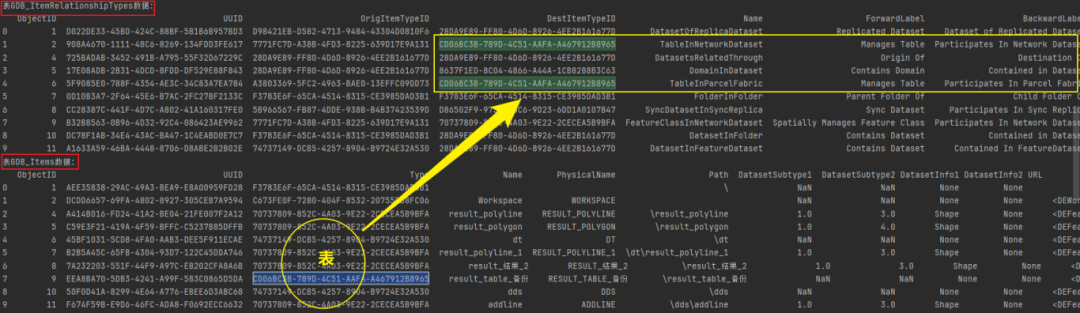
# 查询表,可通过构建如下查询语句实现。
feature_class_query = """
SELECT DISTINCT A.NAME
FROM GDB_ITEMS A, GDB_ItemRelationshipTypes B
WHERE A.Type = B.DestItemTypeID AND (B.NAME = 'TableInNetworkDataset' OR B.NAME = 'TableInParcelFabric')
"""
(3)['GDB_ItemTypes', 'GDB_Items']
表GDB_ItemTypes和表GDB_Items的属性值关联分析,也明显发现,要素类、数据集和表之间存在着关联属性值。
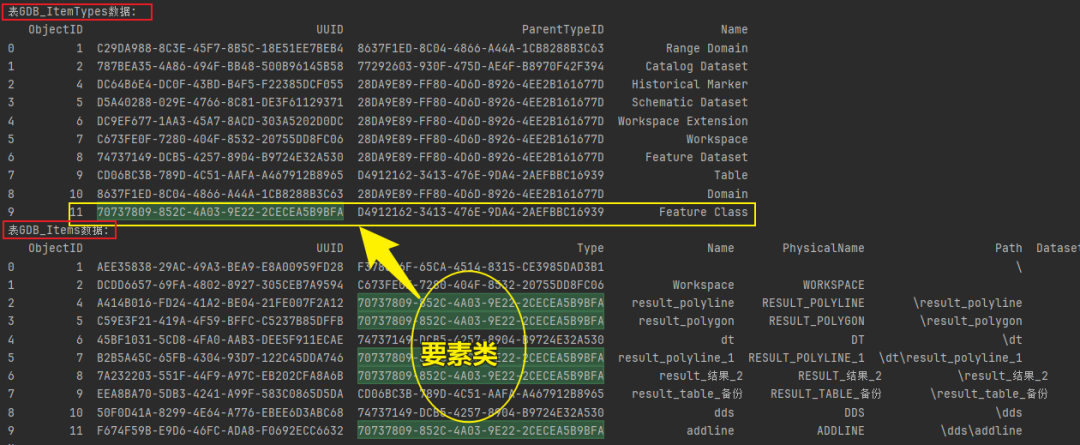
# 查询要素类,可通过构建如下查询语句实现。
feature_class_query = """
SELECT A.NAME
FROM GDB_ITEMS A, GDB_ItemTypes B
WHERE A.Type = B.UUID AND B.NAME = 'Feature Class'
"""
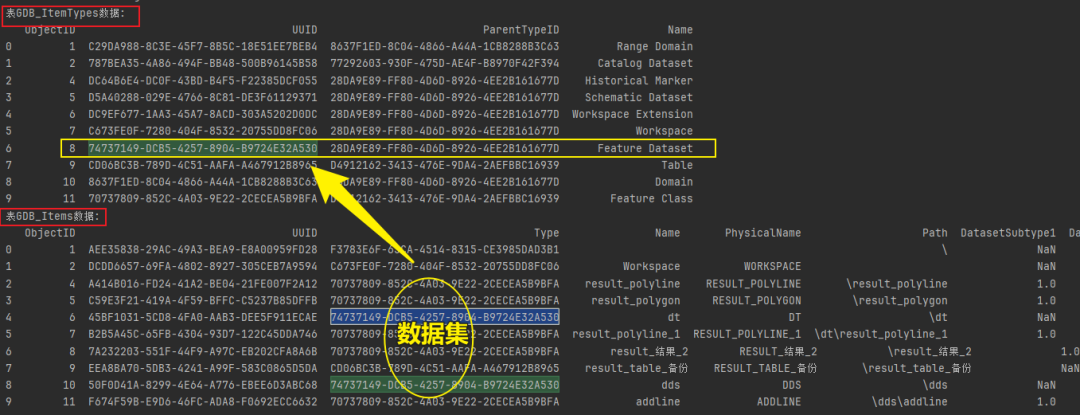
# 查询数据集,可通过构建如下查询语句实现。
dataset_query = """
SELECT A.NAME
FROM GDB_ITEMS A, GDB_ItemTypes B
WHERE A.Type = B.UUID AND B.NAME = 'Feature Dataset'
"""
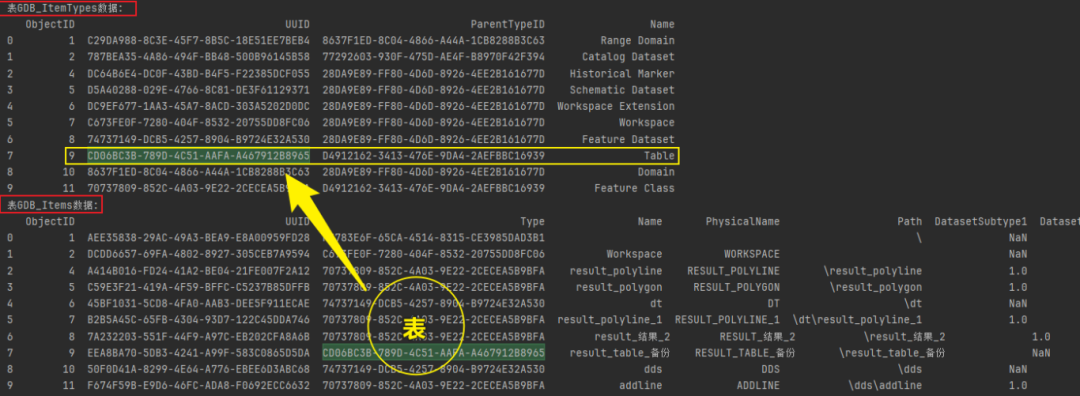
# 查询表,可通过构建如下查询语句实现。
table_query = """
SELECT A.NAME
FROM GDB_ITEMS A, GDB_ItemTypes B
WHERE A.Type = B.UUID AND B.NAME = 'Table'
"""
(4)['GDB_GeomColumns', 'GDB_SpatialRefs']
通过表GDB_GeomColumns与表GDB_SpatialRefs之间的属性值联系,能实现空间参考,要素类型的获取。
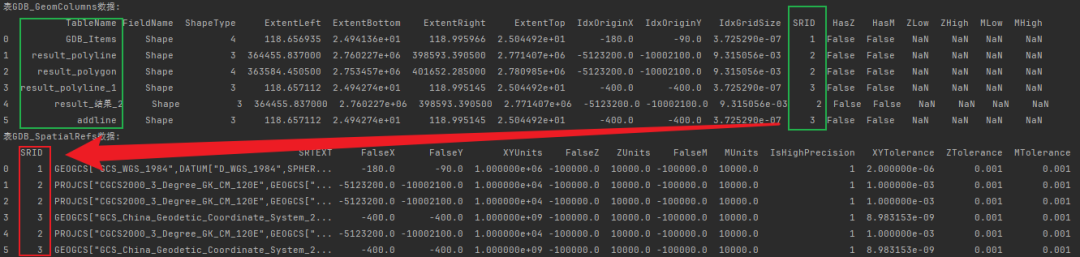
# 查询空间参考信息、要素类型等,可通过构建如下查询语句实现。
table_query = """
SELECT B.SRTEXT,A.ShapeType
FROM GDB_GeomColumns A, GDB_SpatialRefs B
WHERE A.SRID = B.SRID
"""
综上:可使用表
['GDB_ItemRelationshipTypes', 'GDB_Items']
['GDB_ItemTypes', 'GDB_Items']之间的关系实现mdb地理数据库数据组织结构的解析。
使用['GDB_ItemRelationshipTypes', 'GDB_Items']之间的表结构关系,能确定mdb地理数据库下的数据结构和更加细粒度的类型描述。
使用['GDB_GeomColumns', 'GDB_SpatialRefs']获取要素的空间参考信息,要素类型等信息。
1.2 解析mdb中的库体结构
(1)获取mdb中的数据集、要素类和表信息
通过如下代码,可以将mdb中的数据集、要素类以及表都找出:
import pyodbcdef parse_mdb(mdb_file):# 连接到 MDB 文件driver = '{Microsoft Access Driver (*.mdb, *.accdb)}'conn = pyodbc.connect(f'Driver={driver};DBQ={mdb_file}')cursor = conn.cursor()# 查询数据集dataset_query = """SELECT A.NAMEFROM GDB_ITEMS A, GDB_ItemRelationshipTypes BWHERE A.Type = B.OrigItemTypeID AND B.NAME = 'DatasetInFeatureDataset'"""# 或者# dataset_query = """# SELECT A.NAME# FROM GDB_ITEMS A, GDB_ItemTypes B# WHERE A.Type = B.UUID AND B.NAME = 'Feature Dataset'# """cursor.execute(dataset_query)datasets = [row.NAME for row in cursor.fetchall()]# 查询要素类feature_class_query = """SELECT A.NAMEFROM GDB_ITEMS A, GDB_ItemRelationshipTypes BWHERE A.Type = B.DestItemTypeID AND B.NAME = 'FeatureClassInNetworkDataset'"""# 或者# feature_class_query = """# SELECT A.NAME# FROM GDB_ITEMS A, GDB_ItemTypes B# WHERE A.Type = B.UUID AND B.NAME = 'Feature Class'# """cursor.execute(feature_class_query)feature_classes = [row.NAME for row in cursor.fetchall()]# 查询表格table_query = """SELECT DISTINCT A.NAMEFROM GDB_ITEMS A, GDB_ItemRelationshipTypes BWHERE A.Type = B.DestItemTypeID AND (B.NAME = 'TableInNetworkDataset' OR B.NAME = 'TableInParcelFabric')"""# 或者# table_query = """# SELECT A.NAME# FROM GDB_ITEMS A, GDB_ItemTypes B# WHERE A.Type = B.UUID AND B.NAME = 'Table'# """cursor.execute(table_query)tables = [row.NAME for row in cursor.fetchall()]# 关闭数据库连接cursor.close()conn.close()return datasets, feature_classes, tablesif __name__ == '__main__':# 使用示例mdb_file_path = r"D:\data\tess.mdb"datasets, feature_classes, tables = parse_mdb(mdb_file_path)print("DataSets:", datasets)print("Feature Classes:", feature_classes)print("Tables:", tables)
代码执行结果如下:

对比mdb的结构:
明显看出,所有的数据集、要素类和表名都已经获取到。
(2)获取mdb库体结构
通过对上一步获取的数据集、要素类和表进一步梳理,按mdb库体结构进行组织,代码如下:
def format_tables(datasets, feature_classes, tables):from collections import defaultdictdts = defaultdict(list)fcs = [fc[0] for fc in feature_classes]for dt in datasets:dts.setdefault(dt[0], [])dts[dt[0]].append([])for fc in feature_classes:if str(fc[1]).startswith(str(dt[1])):dts[dt[0]].append(fc[0])try:fcs.remove(fc[0])except ValueError:passtbs = [tb[0] for tb in tables]return {"Feature Dataset": dts}, {"Feature Class": fcs}, {"Table": tbs}def parse_mdb(mdb_file):# 连接到 MDB 文件driver = '{Microsoft Access Driver (*.mdb, *.accdb)}'conn = pyodbc.connect(f'Driver={driver};DBQ={mdb_file}')cursor = conn.cursor()# 查询数据集dataset_query = """SELECT A.NAME, A.PathFROM GDB_ITEMS A, GDB_ItemRelationshipTypes BWHERE A.Type = B.OrigItemTypeID AND B.NAME = 'DatasetInFeatureDataset'"""# 或者# dataset_query = """# SELECT A.NAME, A.Path# FROM GDB_ITEMS A, GDB_ItemTypes B# WHERE A.Type = B.UUID AND B.NAME = 'Feature Dataset'# """cursor.execute(dataset_query)datasets = [row for row in cursor.fetchall()]# 查询要素类feature_class_query = """SELECT A.NAME, A.PathFROM GDB_ITEMS A, GDB_ItemRelationshipTypes BWHERE A.Type = B.DestItemTypeID AND B.NAME = 'FeatureClassInNetworkDataset'"""# 或者# feature_class_query = """# SELECT A.NAME, A.Path# FROM GDB_ITEMS A, GDB_ItemTypes B# WHERE A.Type = B.UUID AND B.NAME = 'Feature Class'# """cursor.execute(feature_class_query)feature_classes = [row for row in cursor.fetchall()]# 查询表格table_query = """SELECT DISTINCT A.NAME, A.PathFROM GDB_ITEMS A, GDB_ItemRelationshipTypes BWHERE A.Type = B.DestItemTypeID AND (B.NAME = 'TableInNetworkDataset' OR B.NAME = 'TableInParcelFabric')"""# 或者# table_query = """# SELECT A.NAME, A.Path# FROM GDB_ITEMS A, GDB_ItemTypes B# WHERE A.Type = B.UUID AND B.NAME = 'Table'# """cursor.execute(table_query)tables = [row for row in cursor.fetchall()]# 关闭数据库连接cursor.close()conn.close()datasets, feature_classes, tables = format_tables(datasets, feature_classes, tables)# print(datasets, feature_classes, tables)mdb_name = os.path.basename(mdb_file)def print_tree(data, depth=0):for key, value in data.items():print('{}{}'.format(' ' * depth * 4, key))if isinstance(value, dict):print_tree(value, depth + 1)else:for item in value:if item:print('{}{} {}'.format(' ' * (depth + 1) * 4, '-' * 4, item))# Print datasetsprint(f'------{mdb_name}------')for dt in datasets.values():print_tree(dt, depth=1)# Print feature classesfor fc_name, fc in feature_classes.items():print_tree({fc_name: fc}, depth=0)# Print tablesfor tb_name, tb in tables.items():print_tree({tb_name: tb}, depth=0)
按层级结构,通过简单的打印,可能看出mdb的库体结构。代码执行结果如下:
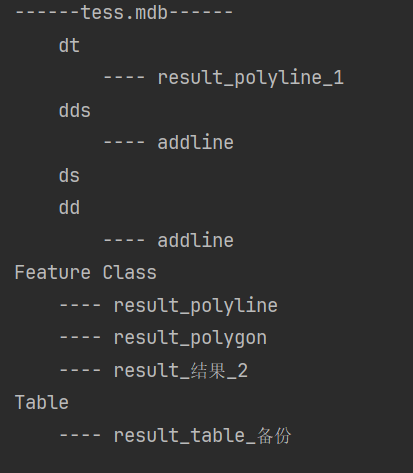
现在,只是通过表关系:
['GDB_ItemRelationshipTypes','GDB_Items']
['GDB_ItemTypes', 'GDB_Items']
从GDB_Items中获取数据集、要素类和表的名称,要进一步获取数据集、要素类和表的其他属性,比如空间参考、要素类型、字段属性等,则需要对GDB_Items、GDB_GeomColumns以及GDB_SpatialRefs进一步剖析。
表GDB_Items、GDB_GeomColumns以及GDB_SpatialRefs之间的字段信息通过如下代码进行输出分析:
mdb_file = r"D:\data\tess.mdb"driver = '{Microsoft Access Driver (*.mdb, *.accdb)}'conn = pyodbc.connect(f'Driver={driver};DBQ={mdb_file}')system_tables = ["GDB_Items","GDB_GeomColumns","GDB_SpatialRefs"]data_structures = {}# 逐个系统表格提取数据结构信息for table_name in system_tables:cursor = conn.cursor()cursor.execute(f"SELECT * FROM [{table_name}]")columns = [column[0] for column in cursor.description]data_structures[table_name] = columns# 输出数据结构信息for table_name, columns in data_structures.items():print(f"Table Name: {table_name}")print("Columns:")for column in columns:print(f" - {column}")print()
代码输出截图对比如下:
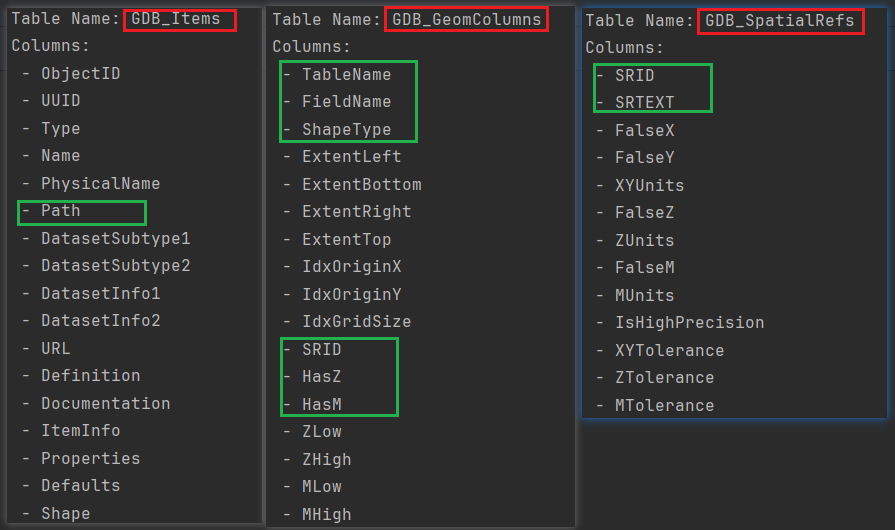
(3)获取创建数据集、要素类和表所需的参数信息
代码如下:
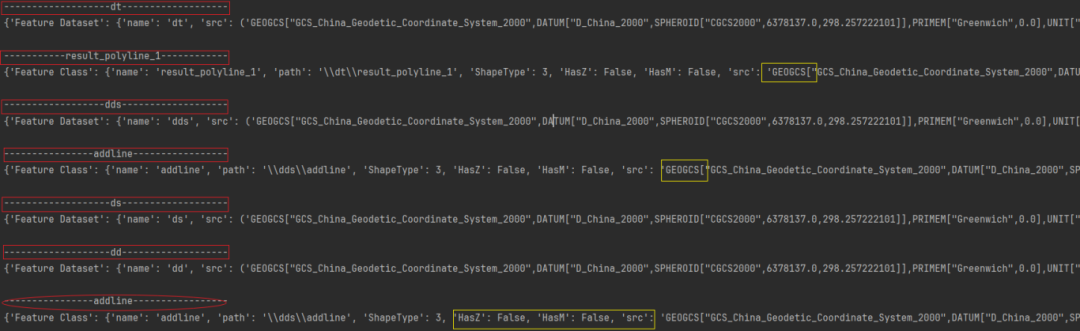
def get_info(conn, table_name):cursor = conn.cursor()table_query = f"""SELECT DISTINCT A.Type, A.Path, B.NameFROM GDB_ITEMS A, GDB_ItemTypes BWHERE A.Name = '{table_name}' AND B.UUID = A.Type"""table_info = {}create_info = {'name': table_name}cursor.execute(table_query)info = [i for i in cursor][0]if info[2] == 'Feature Dataset':# 获取坐标系信息sr_query = f"""SELECT A.DefinitionFROM GDB_ITEMS A"""cursor_sr = conn.cursor()cursor_sr.execute(sr_query)for row in cursor_sr.fetchall():if "DEFeatureDataset" in str(row):sr = get_sr_from_Definition(row[0])create_info['src'] = srbreaktable_info['Feature Dataset'] = create_infoelif info[2] == 'Feature Class':fc_query = f"""SELECT DISTINCT A.ShapeType, A.HasZ, A.HasM, B.SRTEXTFROM GDB_GeomColumns A, GDB_SpatialRefs BWHERE A.TableName = '{table_name}' AND B.SRID = A.SRID"""cursor_fc = conn.cursor()cursor_fc.execute(fc_query)fc = [row for row in cursor_fc][0]# 获取要素类字段信息f_infos = get_fields_infos(conn, table_name)create_info['path'] = info[1]create_info['ShapeType'] = fc[0]create_info['HasZ'] = fc[1]create_info['HasM'] = fc[2]create_info['src'] = fc[3]create_info['f_info'] = f_infostable_info['Feature Class'] = create_infoelif info[2] == 'Table':# 获取表字段信息t_infos = get_fields_infos(conn, table_name)create_info['f_info'] = t_infostable_info['Table'] = create_infoelse:print(info[2])return {}return table_infodef get_mdb_struct_info(conn, table_names):for tables in table_names.values():if isinstance(tables, dict):for dt_name, tables in tables.items():for table in tables:if table:infos = get_info(conn, table)print()print(str(table).center(40, '-'))else:infos = get_info(conn, dt_name)print()print(str(dt_name).center(40, '-'))print(infos)elif isinstance(tables, list):for table in tables:infos = get_info(conn, table)print()print(str(table).center(40, '-'))print(infos)if __name__ == '__main__':# 使用示例mdb_file_path = r"D:\data\tess.mdb"conn = get_conn(mdb_file_path)get_mdb_struct_info(conn, datasets)
得到了每个要素集(包括空要素集)的名称、空间参考信息;
得到了每个要素类的名称、所属要素集、要素类型、空间参考以及字段属性信息;
得到了每个表的名称、表字段属性信息。
代码执行结果如下:
2、 Geoscene Pro4.0
根据mdb库体结构创建gdb数据库
(1)创建与mdb同名的gdb;
(2)创建数据集,并在数据集下创建该数据集下的要素类;
(3)在gdb根目录创建要素类;
(4)创建表。
这部分将在下一篇中进行讲解,本文篇幅已经太长了。







![[C++][设计模式][迭代器模式]详细讲解](https://img-blog.csdnimg.cn/direct/b8d187dd0a9f4cad91859d70f7198893.png)