以下内容为结合李沐老师的课程和教材补充的学习笔记,以及对课后练习的一些思考,自留回顾,也供同学之人交流参考。
本节课程地址:17 使用和购买 GPU【动手学深度学习v2】_哔哩哔哩_bilibili
本节教材地址:5.6. GPU — 动手学深度学习 2.0.0 documentation (d2l.ai)
本节开源代码:...>d2l-zh>pytorch>chapter_multilayer-perceptrons>use-gpu.ipynb
以下代码使用Kaggle每周免费提供的GPU运行。
使用方法:登录Kaggle,点击右上角头像,进入Setting,验证手机号完成后,即可使用GPU。
以下代码使用Kaggle每周免费提供的GPU运行。
使用方法:登录Kaggle,点击右上角头像,进入Setting,验证手机号完成后,即可使用GPU。
Setting中也可以查看GPU可用时长:
GPU
在 本章前言 中, 我们回顾了过去20年计算能力的快速增长。 简而言之,自2000年以来,GPU性能每十年增长1000倍。
本节,我们将讨论如何利用这种计算性能进行研究。 首先是如何使用单个GPU,然后是如何使用多个GPU和多个服务器(具有多个GPU)。
我们先看看如何使用单个NVIDIA GPU进行计算。 首先,确保至少安装了一个NVIDIA GPU。 然后,下载NVIDIA驱动和CUDA 并按照提示设置适当的路径。 当这些准备工作完成,就可以使用nvidia-smi命令来(查看显卡信息。)
!nvidia-smi输出结果:
Fri Apr 26 09:30:05 2024
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.129.03 Driver Version: 535.129.03 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 |
| N/A 45C P8 11W / 70W | 0MiB / 15360MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
| 1 Tesla T4 Off | 00000000:00:05.0 Off | 0 |
| N/A 46C P8 12W / 70W | 0MiB / 15360MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| No running processes found |
+---------------------------------------------------------------------------------------+
在PyTorch中,每个数组都有一个设备(device), 我们通常将其称为环境(context)。 默认情况下,所有变量和相关的计算都分配给CPU。 有时环境可能是GPU。 当我们跨多个服务器部署作业时,事情会变得更加棘手。 通过智能地将数组分配给环境, 我们可以最大限度地减少在设备之间传输数据的时间。 例如,当在带有GPU的服务器上训练神经网络时, 我们通常希望模型的参数在GPU上。
要运行此部分中的程序,至少需要两个GPU。 注意,对大多数桌面计算机来说,这可能是奢侈的,但在云中很容易获得。 例如可以使用AWS EC2的多GPU实例。 本书的其他章节大都不需要多个GPU, 而本节只是为了展示数据如何在不同的设备之间传递。
[计算设备]
我们可以指定用于存储和计算的设备,如CPU和GPU。 默认情况下,张量是在内存中创建的,然后使用CPU计算它。
在PyTorch中,CPU和GPU可以用torch.device('cpu') 和torch.device('cuda')表示。 应该注意的是,cpu设备意味着所有物理CPU和内存, 这意味着PyTorch的计算将尝试使用所有CPU核心。 然而,gpu设备只代表一个卡和相应的显存。 如果有多个GPU,我们使用torch.device(f'cuda:{i}') 来表示第 块GPU(
从0开始)。 另外,
cuda:0和cuda是等价的。
import torch
from torch import nn
torch.device('cpu'), torch.device('cuda'), torch.device('cuda:1')输出结果:
(device(type='cpu'), device(type='cuda'), device(type='cuda', index=1))
我们可以(查询可用gpu的数量。)
torch.cuda.device_count()输出结果:
2
现在我们定义了两个方便的函数, [这两个函数允许我们在不存在所需所有GPU的情况下运行代码。]
def try_gpu(i=0): #@save
"""如果存在,则返回gpu(i),否则返回cpu()"""
if torch.cuda.device_count() >= i + 1:
return torch.device(f'cuda:{i}')
return torch.device('cpu')
def try_all_gpus(): #@save
"""返回所有可用的GPU,如果没有GPU,则返回[cpu(),]"""
devices = [torch.device(f'cuda:{i}')
for i in range(torch.cuda.device_count())]
return devices if devices else [torch.device('cpu')]
try_gpu(), try_gpu(10), try_all_gpus()输出结果:
(device(type='cuda', index=0),
device(type='cpu'),
[device(type='cuda', index=0), device(type='cuda', index=1)])
张量与GPU
我们可以[查询张量所在的设备。] 默认情况下,张量是在CPU上创建的。
x = torch.tensor([1, 2, 3])
x.device输出结果:
device(type='cpu')
需要注意的是,无论何时我们要对多个项进行操作, 它们都必须在同一个设备上。 例如,如果我们对两个张量求和, 我们需要确保两个张量都位于同一个设备上, 否则框架将不知道在哪里存储结果,甚至不知道在哪里执行计算。
[存储在GPU上]
有几种方法可以在GPU上存储张量。 例如,我们可以在创建张量时指定存储设备。接 下来,我们在第一个gpu上创建张量变量X。 在GPU上创建的张量只消耗这个GPU的显存。 我们可以使用nvidia-smi命令查看显存使用情况。 一般来说,我们需要确保不创建超过GPU显存限制的数据。
X = torch.ones(2, 3, device=try_gpu())
X输出结果:
tensor([[1., 1., 1.],
[1., 1., 1.]], device='cuda:0')
假设我们至少有两个GPU,下面的代码将在(第二个GPU上创建一个随机张量。)
Y = torch.rand(2, 3, device=try_gpu(1))
Y输出结果:
tensor([[0.7598, 0.1343, 0.8962],
[0.1689, 0.5433, 0.4807]], device='cuda:1')
复制
如果我们[要计算X + Y,我们需要决定在哪里执行这个操作]。 例如,如 :numref:fig_copyto所示, 我们可以将X传输到第二个GPU并在那里执行操作。 不要简单地X加上Y,因为这会导致异常, 运行时引擎不知道该怎么做:它在同一设备上找不到数据会导致失败。 由于Y位于第二个GPU上,所以我们需要将X移到那里, 然后才能执行相加运算。
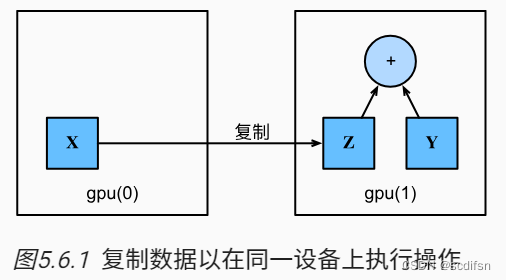
Z = X.cuda(1)
print(X)
print(Z)输出结果:
tensor([[1., 1., 1.],
[1., 1., 1.]], device='cuda:0')
tensor([[1., 1., 1.],
[1., 1., 1.]], device='cuda:1')
[现在数据在同一个GPU上(Z和Y都在),我们可以将它们相加。]
Y + Z输出结果:
tensor([[1.7598, 1.1343, 1.8962],
[1.1689, 1.5433, 1.4807]], device='cuda:1')
假设变量Z已经存在于第二个GPU上。 如果我们还是调用Z.cuda(1)会发生什么? 它将返回Z,而不会复制并分配新内存。
Z.cuda(1) is Z输出结果:
True
旁注
人们使用GPU来进行机器学习,因为单个GPU相对运行速度快。 但是在设备(CPU、GPU和其他机器)之间传输数据比计算慢得多。 这也使得并行化变得更加困难,因为我们必须等待数据被发送(或者接收), 然后才能继续进行更多的操作。 这就是为什么拷贝操作要格外小心。 根据经验,多个小操作比一个大操作糟糕得多。 此外,一次执行几个操作比代码中散布的许多单个操作要好得多。 如果一个设备必须等待另一个设备才能执行其他操作, 那么这样的操作可能会阻塞。 这有点像排队订购咖啡,而不像通过电话预先订购: 当客人到店的时候,咖啡已经准备好了。
最后,当我们打印张量或将张量转换为NumPy格式时, 如果数据不在内存中,框架会首先将其复制到内存中, 这会导致额外的传输开销。 更糟糕的是,它现在受制于全局解释器锁,使得一切都得等待Python完成。
[神经网络与GPU]
类似地,神经网络模型可以指定设备。 下面的代码将模型参数放在GPU上。
net = nn.Sequential(nn.Linear(3, 1))
net = net.to(device=try_gpu())在接下来的几章中, 我们将看到更多关于如何在GPU上运行模型的例子, 因为它们将变得更加计算密集。
当输入为GPU上的张量时,模型将在同一GPU上计算结果。
net(X)输出结果:
tensor([[0.0873],
[0.0873]], device='cuda:0', grad_fn=<AddmmBackward0>)
让我们(确认模型参数存储在同一个GPU上。)
net[0].weight.data.device输出结果:
device(type='cuda', index=0)
总之,只要所有的数据和参数都在同一个设备上, 我们就可以有效地学习模型。 在下面的章节中,我们将看到几个这样的例子。
小结
- 我们可以指定用于存储和计算的设备,例如CPU或GPU。默认情况下,数据在主内存中创建,然后使用CPU进行计算。
- 深度学习框架要求计算的所有输入数据都在同一设备上,无论是CPU还是GPU。
- 不经意地移动数据可能会显著降低性能。一个典型的错误如下:计算GPU上每个小批量的损失,并在命令行中将其报告给用户(或将其记录在NumPy
ndarray中)时,将触发全局解释器锁,从而使所有GPU阻塞。最好是为GPU内部的日志分配内存,并且只移动较大的日志。
练习
1. 尝试一个计算量更大的任务,比如大矩阵的乘法,看看CPU和GPU之间的速度差异。再试一个计算量很小的任务呢?
解:
对于计算量较大的任务,GPU的运行速度相比CPU有很大优势; 但对于计算量较小的任务,GPU则没有明显优势。
代码如下:
import time
# 对于计算量较大的任务
# CPU计算计时
start1 = time.time()
for i in range(100):
A = torch.randn(200, 200)
B = torch.randn(200, 200)
C = torch.matmul(A, B)
end1 = time.time()
print('CPU计算耗时:', round((end1 - start1)*1000, 2),'ms')
# GPU计算计时
start2 = time.time()
for i in range(100):
A = torch.randn(200, 200, device=try_gpu())
B = torch.randn(200, 200, device=try_gpu())
C = torch.matmul(A, B)
end2 = time.time()
print('GPU计算耗时:', round((end2 - start2)*1000, 2),'ms')
CPU计算耗时: 119.72 ms
GPU计算耗时: 14.13 ms
# 对于计算量较小的任务
# CPU计算计时
start1 = time.time()
for i in range(3):
A = torch.randn(5, 5)
B = torch.randn(5, 5)
C = torch.matmul(A, B)
end1 = time.time()
print('CPU计算耗时:', round((end1 - start1)*1000, 2),'ms')
# GPU计算计时
start2 = time.time()
for i in range(10):
A = torch.randn(50, 50, device=try_gpu())
B = torch.randn(50, 50, device=try_gpu())
C = torch.matmul(A, B)
end2 = time.time()
print('GPU计算耗时:', round((end2 - start2)*1000, 2),'ms')输出结果:
CPU计算耗时: 1.17 ms
GPU计算耗时: 1.28 ms
2. 我们应该如何在GPU上读写模型参数?
解:
与上节操作类似,只是在GPU上进行,增加一句 net.to(device=try_gpu()),代码如下:
# 将前面存储在GPU上的net参数存储
torch.save(net.state_dict(), 'net.params')
# 调用存储的参数
net2 = nn.Sequential(nn.Linear(3, 1))
net2.load_state_dict(torch.load('net.params'))
net2 = net2.to(device=try_gpu())
net2(X) == net(X)输出结果:
tensor([[True],
[True]], device='cuda:0')
3. 测量计算1000个 100×100 矩阵的矩阵乘法所需的时间,并记录输出矩阵的Frobenius范数,一次记录一个结果,而不是在GPU上保存日志并仅传输最终结果。
解:
一次记录一个结果花费的时间更多, 代码如下:
start1 = time.time()
X = torch.randn(100, 100, device=try_gpu())
for i in range(999):
X = torch.matmul(X, X)
# 每次矩阵乘法后记录一次范数
Frobenius_norm = torch.norm(X)
end1 = time.time()
print('每次矩阵乘法记录一次范数的GPU计算耗时:', round((end1 - start1)*1000, 2),'ms')
start2 = time.time()
X = torch.randn(100, 100, device=try_gpu())
for i in range(999):
X = torch.matmul(X, X)
# 只记录最终矩阵乘法结果的范数
Frobenius_norm = torch.norm(X)
end2 = time.time()
print('只记录最终结果范数的GPU计算耗时:', round((end2 - start2)*1000, 2),'ms')输出结果:
每次矩阵乘法记录一次范数的GPU计算耗时: 34.92 ms
只记录最终结果范数的GPU计算耗时: 13.01 ms
4. 测量同时在两个GPU上执行两个矩阵乘法与在一个GPU上按顺序执行两个矩阵乘法所需的时间。提示:应该看到近乎线性的缩放。
解:
两个GPU同时执行两个矩阵乘法,可减少接近一半的运行时间。 代码如下:
# 在两个GPU上同时执行两个矩阵乘法
A = torch.randn(200, 200, device=try_gpu())
B = torch.randn(200, 200, device=try_gpu())
C = A.cuda(1)
D = B.cuda(1)
start1 = time.time()
X = torch.matmul(A, B)
Y = torch.matmul(C, D)
end1 = time.time()
print('在两个GPU上同时执行两个矩阵乘法计算耗时:', round((end1 - start1)*1000, 2),'ms')
# 在一个GPU上按顺序执行两个矩阵乘法
start2 = time.time()
X = torch.matmul(A, B)
Y = torch.matmul(A, B)
end2 = time.time()
print('在一个GPU上顺序执行两个矩阵乘法计算耗时:', round((end2 - start2)*1000, 2),'ms')输出结果:
在两个GPU上同时执行两个矩阵乘法计算耗时: 0.27 ms
在一个GPU上顺序执行两个矩阵乘法计算耗时: 0.53 ms