本次实验的视频链接如下:https://www.bilibili.com/video/BV1iA4y1f7o1/
本次实验在MindStudio上进行,请先按照
教程
配置环境,安装MindStudio。
MindStudio的是一套基于华为自研昇腾AI处理器开发的AI全栈开发工具平台,该IDE上功能很多,涵盖面广,可以进行包括网络模型训练、移植、应用开发、推理运行及自定义算子开发等多种任务。MindStudio除了具有工程管理、编译、调试、运行等一般普通功能外,还能进行性能分析,算子比对,可以有效提高工作人员的开发效率。除此之外,MIndStudio具有远端环境,运行任务在远端实现,对于近端的个人设备的要求不高,用户交互体验很好,可以让我们随时随地进行使用。
1、pytorch编译/安装介绍
- 1) 从gitee获取Pytorch源码。
git clone https://gitee.com/ascend/pytorch.git

如果clone命令失败,可以使用以下命令重新安装git。
apt update; apt install git
此外,也可以在Ascend仓库中查看Pytorch源码,链接为:https://gitee.com/ascend/pytorch
- 2) 根据需要切换分支并获取PyTorch源代码。
| AscendPytorch版本 | CANN版本 | 支持PyTorch版本 |
|---|---|---|
| 2.0.2 | CANN 5.0.2 | 1.5.0 |
| 2.0.3 | CANN 5.0.3 | 1.5.0/1.8.1(1.8.1仅支持resnet50模型) |
| 2.0.4 | CANN 5.0.4 | 1.5.0/1.8.1(1.8.1仅支持resnet50模型) |
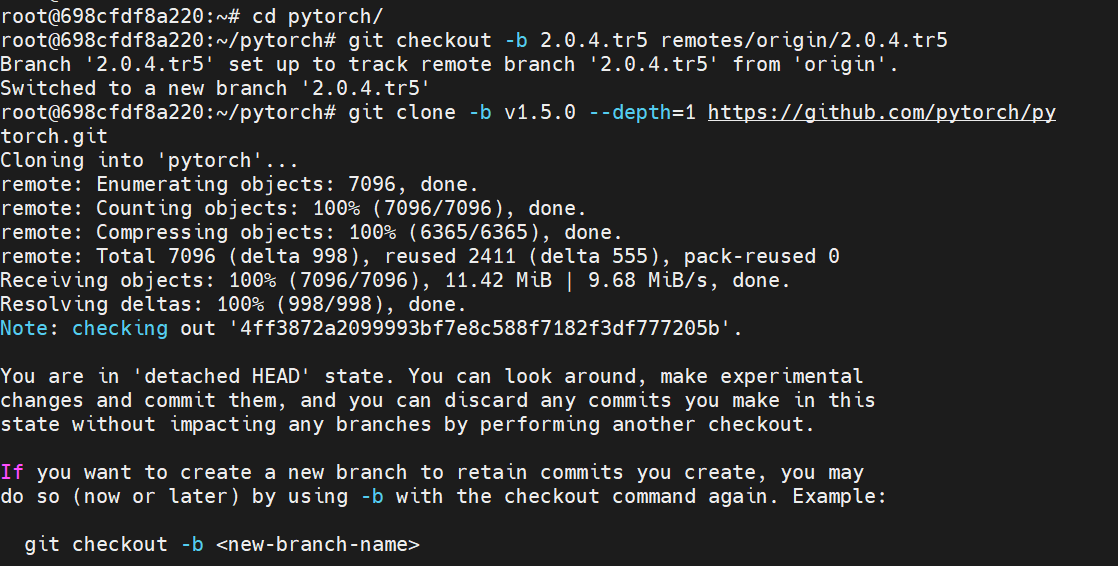
从上表来看,我们的CANN版本是5.0.4,安装的Pytorch版本为1.5.0。因此切换到2.0.4的分支,具体有哪些分支可在
gitee
源码查看。
分别执行以下命令:
cd pytorch
git checkout -b 2.0.4.tr5 remotes/origin/2.0.4.tr5
git clone -b v1.5.0 --depth=1 https://github.com/pytorch/pytorch.git
- 3)获取Pytorch被动依赖代码
分别运行以下命令
cd pytorch
git submodule sync
git submodule update --init --recursive
获取代码时,因为代码是位于GitHub上,受网络影响,获取时间可能较长,并且在获取过程中可能报错,如:

出现这种情况时,我们需要删除该报错路径的文件,重新运行后面两条代码,直到执行git submodule update --init --recursive不再报错为止。如下图没有任何报错信息:

PS:重新运行时需要将报错信息的文件夹删除再重新运行,删除时要看清楚完整的文件夹路径,比如说报错的路径“/third_party/benchmark/”有完整路径可能是在“pytorch/third_party/onnx/third_party/benchmark/”,不要与“pytorch/third_party/benchmark/”搞混。
PS:如果一直有某个包克隆失败,我们可以手动添加。如third_party/QNNPACK/克隆失败,我们先在GitHub上搜索QNNPACK,然后再手动下载zip文件,再上传至服务器相关目录并解压。或者使用gitee将其导入,再从gitee中克隆。
- 4)编译生成适配昇腾AI处理器的PyTorch安装包
(1) 回退一级目录,进入pytorch/scrips文件夹下,执行转换脚本,生成适配昇腾AI处理器的全量代码。运行截图如下:
cd ../scripts
bash gen.sh

(2) 进入pytorch/pytorch目录下,安装依赖库
cd ../pytorch
pip3 install -r requirements.txt
(3) 运行build.sh,编译生成pytorch的二进制安装包
bash build.sh --python=3.7
编译成功如下图,并可以在路径./pytorch/pytorch/dist/下找到对应的whl文件。如果失败,请重新检查第3)步-获取Pytorch被动依赖代码的操作。

- 5)安装Pytorch
进入生成的whl包的目录dist下,使用pip命令进行安装
cd dist
pip3 install --upgrade torch-1.5.0+ascend.post3-cp37-cp37m-linux_aarch64.whl

PS:因为之前服务器环境存在pytorch,所以截图中先卸载后安装。
- 6)配置环境变量
安装完软件包后,需要配置环境变量才能正常使用昇腾PyTorch
进入pytorch/pytorch目录下,运行env.sh
cd ../
source env.sh
这样,我们的pytorch就安装完毕了。
2、 模型简介
本次实验我们的目标是在MindStudio上使用ResNet进行图像分类任务。ResNet曾在ILSVRC2015比赛中取得冠军,在图像分类上具有很大的潜力。 ResNet的主要思想是在网络中增加了直连通道,使得原始输入信息能够直接传输到后面的层中,ResNet的残差块的结构如下图所示。

ResNet会重复将残差块串联,形成多层网络。一般常见的ResNet根据层数的大小有ResNet-18,ResNet-34,ResNet-50,ResNet-101等等。后面的数字代表网络的层数。在本次实验中,我们选用的数据集是tiny-imagenet。该数据集是斯坦福大学提供的图像分类数据集,其中包含200个类别,每个类别包含500张训练图像,50张验证图像及50张测试图像。可以在此
链接
下载。因为数据集不是很大,这里我们选用的模型是较小的ResNet-18。
3、训练工程创建,工程功能以及相关菜单介绍
3.1 训练过程创建
- 打开MindStudio,点击New Project,进入新建工程界面。
- 选择Ascend Training。填入项目名。首次新建训练工程时,需要配置CANN的版本。点击install。

- 首先,点击 + 配置远程连接,然后根据选项填入自己服务器的ip地址、端口号、用户名和密码等。


- 配置Remote CANN location。该参数需要填入ascend-toolkit在服务器上的路径地址。在这里,我们toolkit的路径如下:/usr/local/Ascend/ascend-toolkit/5.0.4/。点击finishing进行配置。初次配置时时间稍长,请耐心等待。

- 点击Next,选择Pytorch Project。

- 点击Finish,完成工程创建,进入工程主界面。

- 配置Module SDK,便于编码。
右键点击项目名,选择Open Module Settings。

因为我们的模型任务都是基于Python编程的,本机环境也是Python3.7.5,因此我们选择Python 3.7

3.2 工程功能及相关菜单介绍
MindStudio是基于华为自研昇腾AI处理器开发的AI全栈开发工具平台,具有非常丰富的功能。在该IDE上可以进行包括网络模型训练、移植、应用开发、推理运行及自定义算子开发等多种任务。接下来我们简单介绍MindStudio中我们会用到的功能。
新建Pytorch工程后,我们可以进行普通Pytorch框架下的所有开发任务,如模型构建,模型训练等。还有很多便捷的功能。

如上图所示,MindStudio的菜单栏除了包含IDEA,Pycharm等IDE的File,Edit,View,Navigate,Code,Refactor,Run,Tools,VCS,Windows,Help等常规菜单按钮外。还多出了Ascend的特色菜单按钮。

在该菜单栏下,有很多便捷的功能。其相关选项,对应于上图中用红框表示的图标,可以快速点击使用。具体功能见下表所示。
| 名称 | 功能 |
|---|---|
| AutoML | AI初学者可以通过AutoML工具结合数据集,生成满足需求的模型 |
| Framework Trans | 包含三种工具,X2MindSpore,Pytorch GPU2Ascend,TensorFlow GPU2Ascedn。其功能分别为:将PyTorch脚本文件、ONNX模型文件TensorFlow模型文件转换到MindSpore脚本;将基于GPU训练的Pytorch训练脚本转换到支持NPU训练的脚本;将基于GPU训练的TensorFlow训练脚本转换到支持NPU训练的脚本 |
| Model Converter | 将训练好的模型转换为离线模型 |
| Model Visualizer | 将转换的模型进行可视化 |
| Dump | 精度比对功能 |
| System Profiler | 性能采集和分析功能 |
4、模型迁移
因为MindStudio是在NPU上进行网络训练的,因此对于基于GPU训练的代码需要进行稍微的修改。
- 首先,将已经在GPU上正常训练的Pytorch训练代码拷贝至新建好的工程目录下。本次实验的代码文件及其实现功能可见下表。
| 文件名 | 功能 |
|---|---|
| config.py | 配置训练的相关参数,如学习率,数据集路径,模型存储路径等等 |
| dataset.py | 数据集读入文件 |
| main.py | 网络定义以及网络训练的主函数入口 |
| train.py | 网络训练 |
| test.py | 结果测试文件 |
| util.py | 通用函数文件 |
| pt2onnx.py | 将pt文件转为onnx模型 |
- 代码大致讲解
1)网络构建
ResNet在torchvision中自带有网络架构和预训练的网络参数。在这里我们使用其网络架构代码,并且修改其最后的全连接层(因为分类的物品只有200个类别),并使用预训练的参数来初始化网络,再根据数据集微调。
import torchvision
model = torchvision.models.resnet18(pretrained=True)
## torchvision默认的ResNet输出维度为1000,本次使用的数据集总共只有200个类别,对模型的最后一层进行修改
fc_inputs = model.fc.in_features
model.fc = nn.Sequential(nn.Linear(fc_inputs, 200))
PS:如果想要查看ResNet-18的网络构建源码,可以在Pytorch的官方文档中查看:
torchvision.models.resnet — Torchvision 0.12 documentation (pytorch.org)
2)数据读入和预处理
我们下载
tiny-imagenet
后,解压文件后的目录架构如下:
tiny-imagenet-200
├── train
│ ├── class1
│ │ ├── images
│ │ │ ├── img1.JPEG
│ │ │ ├── img2.JPEG
│ │ │ └── ...
│ │ └── class1_boxes.txt
│ ├── class2
│ │ ├── images
│ │ │ ├── img3.JPEG
│ │ │ ├── img4.JPEG
│ │ │ └── ...
│ │ └── class2_boxes.txt
│ └── ...
├── val
│ ├── images
│ │ ├── img5.JPEG
│ │ ├── img6.JPEG
│ │ └── ...
│ └── val_annotations.txt
├── test
│ └── images
│ ├── img7.JPEG
│ ├── img8.JPEG
│ └── ...
├── wnids.txt
└── words.txt
因为测试集的数据不带有标签,因此我们只使用训练集和验证集的数据。我们需要对数据进行预处理,用于之后的模型训练。新建类TinyImageNet来继承torch.utils.data.Dataset。并在这个类中定义以下函数:
create_class_idx_dict_train的作用是遍历训练集的文件目录,获取训练集中的数据总量,赋值到self.len_dataset。同时,统计类别总个数,将各个类别排序,按照从0开始逐渐增大的规律进行类别的重新命名,作为训练数据的标签。
def _create_class_idx_dict_train(self):
if sys.version_info >= (3, 5):
classes = [d.name for d in os.scandir(self.train_dir) if d.is_dir()]
else:
classes = [d for d in os.listdir(self.train_dir) if os.path.isdir(os.path.join(train_dir, d))]
classes = sorted(classes)
num_images = 0
for root, dirs, files in os.walk(self.train_dir):
for f in files:
if f.endswith(".JPEG"):
num_images = num_images + 1
self.len_dataset = num_images;
self.tgt_idx_to_class = {i: classes[i] for i in range(len(classes))}
self.class_to_tgt_idx = {classes[i]: i for i in range(len(classes))}
create_class_idx_dict_val函数与create_class_idx_dict_train函数的功能相同,但是因为数据的目录结构不同,代码也有稍许不同。
def _create_class_idx_dict_val(self):
val_image_dir = os.path.join(self.val_dir, "images")
if sys.version_info >= (3, 5):
images = [d.name for d in os.scandir(val_image_dir) if d.is_file()]
else:
images = [d for d in os.listdir(val_image_dir) if os.path.isfile(os.path.join(train_dir, d))]
val_annotations_file = os.path.join(self.val_dir, "val_annotations.txt")
self.val_img_to_class = {}
set_of_classes = set()
with open(val_annotations_file, 'r') as fo:
entry = fo.readlines()
for data in entry:
words = data.split("\t")
self.val_img_to_class[words[0]] = words[1]
set_of_classes.add(words[1])
self.len_dataset = len(list(self.val_img_to_class.keys()))
classes = sorted(list(set_of_classes))
# self.idx_to_class = {i:self.val_img_to_class[images[i]] for i in range(len(images))}
self.class_to_tgt_idx = {classes[i]: i for i in range(len(classes))}
self.tgt_idx_to_class = {i: classes[i] for i in range(len(classes))}
make_dataset函数将图片和对应的标签作为集合添加到一个列表images中,便于读写。
def _make_dataset(self, Train=True):
self.images = []
if Train:
img_root_dir = self.train_dir
list_of_dirs = [target for target in self.class_to_tgt_idx.keys()]
else:
img_root_dir = self.val_dir
list_of_dirs = ["images"]
for tgt in list_of_dirs:
dirs = os.path.join(img_root_dir, tgt)
if not os.path.isdir(dirs):
continue
for root, _, files in sorted(os.walk(dirs)):
for fname in sorted(files):
if (fname.endswith(".JPEG")):
path = os.path.join(root, fname)
if Train:
item = (path, self.class_to_tgt_idx[tgt])
else:
item = (path, self.class_to_tgt_idx[self.val_img_to_class[fname]])
self.images.append(item)
getitem函数是重写Dataset函数必须重写的函数,其功能是按照idx返回对应的图片和标签。
def __getitem__(self, idx):
img_path, tgt = self.images[idx]
with open(img_path, 'rb') as f:
sample = Image.open(img_path)
sample = sample.convert('RGB')
if self.transform is not None:
sample = self.transform(sample)
return sample, tgt
根据参数train的值,TinyImageNet可以分别生成训练集和验证集的数据库。并定义transform,将图片先转为Tensor,再根据平均值和标准差进行归一化。之后分别定义训练集和验证集的DataLoader,将数据按批次读入,方便模型训练。这样我们已经完成了数据读入的所有部分。
dataset_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=cfg.dataset_mean, std=cfg.dataset_std),])
## 训练数据dataloader
def get_train_data(train = True):
dataset_train = TinyImageNet(cfg.data_dir, train=train,transform=dataset_transform)
data_loader = DataLoader(dataset_train, batch_size=cfg.batch_size, shuffle=train)
return data_loader
## 验证数据dataloader
def get_val_data(train = False):
dataset_train = TinyImageNet(cfg.data_dir, train=train,transform=dataset_transform)
data_loader = DataLoader(dataset_train, batch_size=cfg.batch_size, shuffle=train)
return data_loader
3)网络训练,主要的训练代码如下所示。首先调用torch.optim 定义Adam优化器optimizer,再将网络的所有参数置于optimizer中。随后按照epoch数进行循环,在每一个批次都进行前向传递,loss值计算,后向传递和参数更新,具体代码如下所示。
##定义Adam优化器,并将网络的参数都放入优化器中
parameter_list = list(Net.parameters())
optimizer = optim.Adam(parameter_list, lr=cfg.lr, weight_decay=cfg.weight_decay)
##定义loss函数为交叉熵损失函数
criterion = nn.CrossEntropyLoss()
for epoch in range(cfg.end_epoch):
for step, (image, targets) in enumerate(train_data):
image = image.float()
image = image.npu()
targets = targets.long()
targets = targets.npu()
optimizer.zero_grad()
output = Net(image)
loss = criterion(output, targets)
##计算loss值并更新参数
loss.backward()
optimizer.step()
4)网络测试。按批次读取验证集中的所有数据,分布统计cnt,corrct,corrct_5的值(cnt,corrct,corrct_5分布记录验证数据总数目,正确分类的数目,top-5正确的数目)。最终打印准确率和top-5。
corrct,cnt,corrct_5 = 0,0,0
for step, (image, targets) in enumerate(test_data):
image = image.float()
image = image.npu()
targets = targets.npu()
output = Net(image).cpu()
targets = targets.cpu()
for i in range(len(output)):
index = torch.argmax(output[i])
if index==targets[i]:
corrct+=1
_,t5 = torch.topk(output[i],5)
for id in t5:
if id == targets[i]:
corrct_5+=1
cnt+=1
print("The Accuracy is :{} ".format(corrct/cnt))
print("The top5 is :{}".format(corrct_5/cnt))
- 使用
PyTorch GPU2Ascend
工具进行自动迁移。
有多种方法可以打开Pytorch GPU2Ascend。
1)选择菜单栏Ascend/Framework Trans/Pytorch GPU2Ascend。见3.2菜单栏介绍。
2)右键点击项目名,选择Pytorch GPU2Ascend。

3)点击菜单栏按钮。如图中红框所示

- 进如Pytorch GPU2Ascend界面,进行参数配置

如图,选择输出的文件目录(需要与输入路径位于同一驱动器下:如同在C盘),然后点击Transplant进行转换。
其他参数的功能如下表:
| 参数 | 参数说明 |
|---|---|
| Input Path | 要进行转换的原始脚本文件所在文件夹路径或文件路径。单击文件夹图标选择目录。必选。 |
| Output Path | 脚本转换结果文件输出路径。单击文件夹图标选择目录。必选。 |
| Custom Rule | 是否打开自定义转换规则。可选。 |
| Rule File | **“Custom Rule”**开启后此参数才会体现。单击文件夹图标选择用户自定义通用转换规则的json文件路径。该json文件主要包括函数参数修改、函数名称修改和模块名称修改三部分。必选。 |
| Distributed Rule | 将GPU单卡脚本转换为NPU多卡脚本,此参数仅支持使用torch.utils.data.DataLoader方式加载数据的场景。可选。 |
| Main File | "Distributed Rule"开启后此参数才会体现。单击文件夹选择训练脚本的入口python文件。必选。 |
| Target Model | "Distributed Rule"开启后此参数才会体现。目标模型变量名,默认为’model’,可选。 |
| Replace Unsupported APIs | 用功能相似的API替换某些不支持的API,但有可能导致准确性和性能下降。可选。 |
- 转换完成后,除了包含迁移后的代码文件,还会生成相关日志文件msFmkTranspltlog.txt,进行迁移的函数列表文件change_list.csv和当前不支持的操作统计文件unsupported_op.csv。如果存在不支持的函数,我们就需要进行一些人工调整。在本次实验中,我们不需要再进行人工修改。
5、执行训练/评估
5.1 模型训练
- 配置运行文件,点击左上角三角形左侧的箭头,选择Edit Configurations。配置界面如下图:

各个参数的功能见下表:
| 参数 | 参数说明 |
|---|---|
| Name | 工程名称,用户自行配置。名称必须以字母开头,数字或字母结尾,只能包含字母、数字、中划线和下划线,且长度不能超过64个字符。 |
| Executable | 训练工程中的执行入口文件。 |
| Run Mode | 运行环境选择。选择“Remote Run”或“Local Run”,默认为“Remote Run”。 |
| SSH Connection | 远程训练服务器地址,在“File > Settings… > Tools > SSH Configurations”中配置。 |
| Command Arguments | 训练工程执行参数。 |
| Environment Variables | 训练工程环境变量。 |
在模型训练时,是在远端服务器环境完成的,我们的运行文件为main.py。因为我们的参数已经在config.py中配置好了,因此Command Argument不需要填写。点击OK完成配置。
- 数据集准备
本次实验我们使用的数据集是tiny Imagenet,可以点击官方下载
链接
下载。
因为MindStudio的训练任务是在远端服务器上运行的,因此在开始模型训练时,需要首先对本地的文件与远端环境进行同步。为了加快运行时的前期文件同步工作,我们可以将较大的数据集预先上传至服务器中。这里,我们将数据集上传至/root/data/tiny-imagenet-200/路径下。
- 网络训练参数配置。本次训练的所有参数配置都在config.py文件中。学习率,epoch,batchsize可见下图。

- 点击菜单栏的三角形开始训练网络。输出日志会在底部任务台打印出。训练的loss值等信息保存在./loss文件夹下。训练完成后,如果保存的模型参数在工程目录下,会将保存的模型参数文件同步到本地。
5.2 结果评估
如5.1操作,将运行文件更改为test.py。点击run开始运行评估。
本次实验进行的是200个不同物品的分类实验,评判标准使用准确率和top-5的方法。top-5即每次选择前五个概率最高的分类预测,如果这五个中有分类正确的,就判断为分类正确。
运行的实验结果如下图:

实验的最终结果如下表所示
| ACC(%) | Top-5(%) |
|---|---|
| 50.73 | 74.63 |
6、导出onnx
在第五步模型训练中,我们获得了参数文件,其路径为./model/ResNet18_5e_5/ResNetEpoch15.pt
我们需要将该模型转换为onnx模型,主要使用的方法是torch.onnx.export,首先加载模型参数,定义输入形状(输入的形状应与训练时的形状相同,但是batchsize可以不同),然后再进行onnx模型转换。其具体的转换方法如下代码所示:
##保存的参数文件路径
path = "./model/ResNet18_5e_5/ResNetEpoch15.pt"
model = build_model(path=path)
model.eval()
print(model)
input_names = ["image_input"]
output_names = ["outputs"]
dummy_input = torch.randn(1, 3, 64, 64)
torch.onnx.export(model, dummy_input, "resnet18.onnx", input_names=input_names, output_names=output_names, opset_version=11)
这里,我们重新配置运行文件为pt2onnx.py,点击运行。运行完毕后,在工程目录下生成resnet18.onnx文件。
得到onnx模型后,我们可以继续将该模型转换为om模型,这样就可以在Ascend310上进行推理任务了。
这里我们可以利用MindStudio的模型转换工具进行转换。点击菜单栏上方的模型转换按钮。

进入模型转换界面,选择之前导出的onnx格式文件。可以选择输出目录。这里我们只需要选择要转换的onnx模型,填入模型名字,其余参数默认即可。

上述参数对应的功能见下表
| 参数 | 功能 |
|---|---|
| CANN Machine(仅Windows系统支持此参数) | 自动填充。远程连接ADK所在环境的SSH地址,表现格式为 username@localhost:端口号 。 |
| Model File | 模型文件。必填。该模型文件需要取消其他用户写的权限。有两种选择方式:单击右侧的文件夹图标,在后台服务器路径选择需要转化的模型文件并上传。 在参数后面的输入框中自行输入模型文件在后台服务器的路径,包括模型文件名称后缀 |
| Model Name | 模型文件名称,必填。选择模型文件后,该参数会自动填充,用户可以根据需要自行修改名称,要求如下:只支持a-z、A-Z、0-9、下划线以及短划线的组合,最多支持64个字符。如果模型转换的输出路径已经存在相同名称模型文件,单击“Next”后会提示覆盖原有文件或重命名当前Model Name的信息,用户根据实际情况选择 |
| Target SoC Version | 模型转换时指定芯片型号。请根据板端环境具体芯片形态进行选择。 |
| Input Format | 输入数据格式。 当原始框架是MindSpore、ONNX时,取值为NCHW。 |
| Input Nodes | 模型输入节点信息。若原始框架类型为Caffe、ONNX,支持的数据类型为FP32、FP16、UINT8 |
| Shape | 模型输入的shape信息 |
| Type | 指定输入节点的数据类型 |
| Output Nodes | 指定输出节点信息。单击“Select”在弹出的网络拓扑结构中,选中某层节点,右击选择“Select”,该层变成蓝色,单击“OK”后,在“Output Nodes”参数下面会看到标记层的算子,右击选择“Deselect”取消选中。 |
| Load Configuration | 导入上次模型转换的配置文件。 |
同时点击右侧的眼睛,还可以对模型进行可视化。

一直点击Next,最后点击finish,完成模型转换。
7、FAQ
1) 在进行pytorch编译执行bash build.sh --python=3.7报错怎么办?
请检查上一步的git submodule update --init --recursive命令是否出现报错。每次出现报错时应把报错的文件夹删除后重新运行git submodule sync 和git submodule update --init --recursive命令。建议运行完成后检查下每一个./pytorch/pytorch/third_party/目录下的每一个文件夹是否有空文件夹。
删除文件时要看清楚完整的文件夹路径,比如说报错的路径“/third_party/benchmark/”,其完整路径可能是在“pytorch/third_party/onnx/third_party/benchmark/”,不要与“pytorch/third_party/benchmark/”搞混。
2)pip3 install -r requirements.txt时报错torchvision版本未找到。
默认的requirements.txt里的torchvision版本为0.6.0,这是对应x86-64架构的,aarch64架构请改为torchvision==0.2.2.post3。
3)pip安装torch后在import torch时报错ImportError: llibtorch_cpu.so: cannot open shared object file: No such file or directory。
使用命令find / -name libtorch_cpu.so找到libtorch_cpu.so的位置,再建立软连接。如ln -s /usr/local/python3.7.5/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so /usr/lib
8、从昇腾论坛获得更多支持
如果上述步骤中大家在实践中仍然遇到其他问题,比如使用自带的脚本迁移工具PyTorch GPU2Ascend最终生成的报告unsupported_op.csv中有需要人工修改的代码,或者遇到其他上述步骤中未能出现的错误,欢迎大家到昇腾论坛中提出自己的问题,在这里有很多技术大拿可以解决你的问题。或者也可以访问昇腾博客,搜索他人的独到见解。
访问昇腾论坛的方法是进行
昇腾官网
。选择开发者选项,点击进入昇腾论坛或者昇腾博客。

torch时报错ImportError: llibtorch_cpu.so: cannot open shared object file: No such file or directory。
使用命令find / -name libtorch_cpu.so找到libtorch_cpu.so的位置,再建立软连接。如ln -s /usr/local/python3.7.5/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so /usr/lib
8、从昇腾论坛获得更多支持
如果上述步骤中大家在实践中仍然遇到其他问题,比如使用自带的脚本迁移工具PyTorch GPU2Ascend最终生成的报告unsupported_op.csv中有需要人工修改的代码,或者遇到其他上述步骤中未能出现的错误,欢迎大家到昇腾论坛中提出自己的问题,在这里有很多技术大拿可以解决你的问题。或者也可以访问昇腾博客,搜索他人的独到见解。
访问昇腾论坛的方法是进行
昇腾官网
。选择开发者选项,点击进入昇腾论坛或者昇腾博客。
[外链图片转存中…(img-pONxm2eo-1652579573585)]