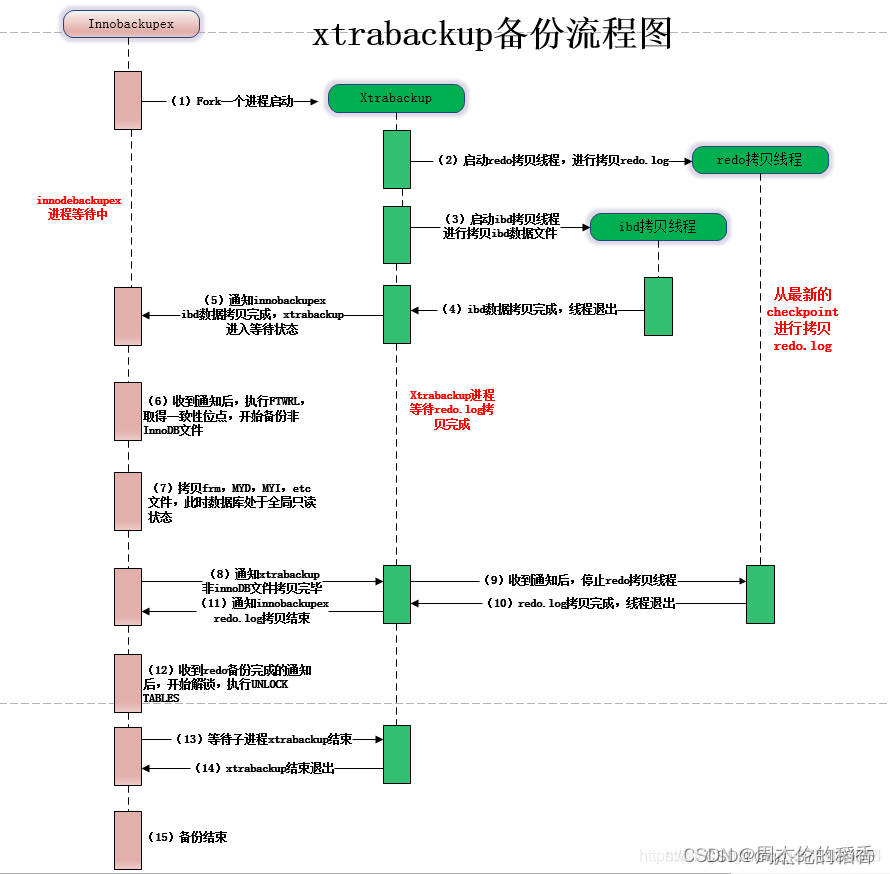
01、案例说明
这个案例是一个酒厂,通过对其产品中不同化学性质的指标数值,寻找哪些是可能出现问题的产品。这是一个标准的离异点(Outlier)使用情形。
如果能够将在不同属性的一定范围之内的数据,作为判断的标准,并能够将其自动分类,就可以确定不同的族群。而使用这些族群所界定的范围,能判断离异点是否存在。整体模型如下图所示:
02、数据资料
首先我们观察数据,数据的质量并没有问题,其中没有缺失,并且都在合理的范围之内,其分布也算平衡。唯一观察到的问题是对于其数据的大小数量级变化太大,所以不能够直接进行操作,必须经过转换将数据都常态化,才能将不同数据(Heterogeneous)之间的变化范围,做成可以分类的标准。
03、操作流程
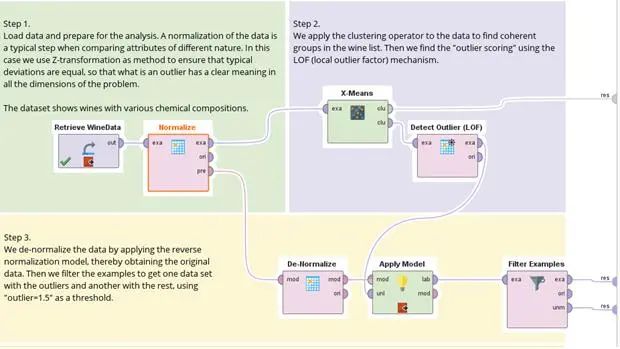
Step1读入数据
首先导入数据,而后将数据进行一个常态化(Normalize)的操作。特别注意在常态化操作的Pre(Preprocessing Model)端口输出,输出的是一个数据模型用来作为后续的使用,比如说使用同样的转换参数对于其他数据进行相同的转换,或是如我们在之后看到的,作为反常态的操作时所需要的参数。如下图所示:
Step2 数据整理/自动分群
如同之前所使用的X-Means算子,这边也用同样的操作将数据分类为4个族群,而不是系统一开始的2个族群(可以思考在什么情况之下,K的值会大于2),并且将族群的分类方式输出到系统。
同样也将这个分类导入到下一个离异点侦测的算子(Detect Outlier),特别注意的是这边的使用方法是区域性离异点侦测LOF (Local Outlier Factors)的算子。这个算子的原理是计算每一个数据到其相近的数据点,然后考虑每一个数据的密度,如果其数据点周围的平均密度很低,而其最靠近的数据点的密度却很高,则很有可能这就是一个离异点,而这个密度的差距是以离异点分数(Outlier Score)来表示(这个部分RM的帮助文档有很清楚的说明,建议可以参考)。这个算子输出数据会增加一个离异点分数的属性,如果这个分数大于1,通常就被视作为是离异点。
Step3: 模型使用
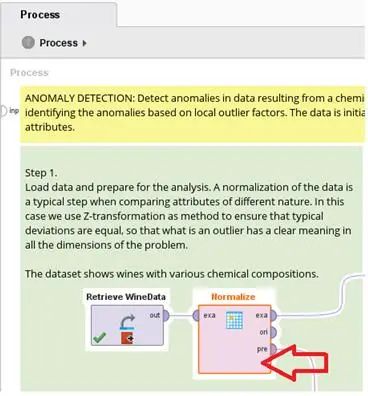
首先将已经被常态的化数据再通过反常态化(De-Normalize)的操作,恢复到原来的数值。再将这个数据输入到Apply Model算子中(因为之前的常态化操作是输出的原来数据模型),并且将已经发现的离异点数据通过位置数据合并进来,从而确定每一个相关数据的离异点分数,这个操作和我们之前的用法有所不同,值得特别的注意。
再通过筛检数据(Filter Example)的算子,将离异点分数超过1.5 设定值的数据过滤,最终输出合格/不合格的两组数据。也请注意其中的端口输出(exa/unm)的判断值。结果说明如下图所示:
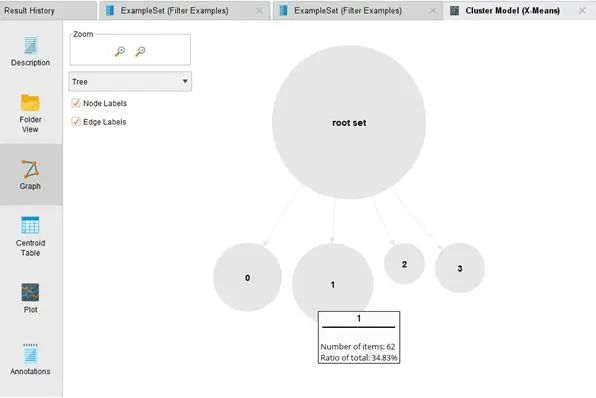
04、结果说明
这个案例部分特别说明了关于对离异点的侦测,使用这个方法可以更有效地对有多重相关属性的数据,进行整体的评估从而判断其是否有离异点的出现。相对于其他使用统计学的方式去找出离异点,这个方法在现实的社会中,更为常见及有效。
关于 Altair RapidMiner
Altair RapidMiner 数据分析与人工智能平台,是数据分析领域中最早实现将自动化数据科学、文本分析、自动特征工程和深度学习等多种功能同时集成的企业级一站式数据科学平台,帮助用户解决从数据清洗、准备、数据科学建模到模型管理和部署的全流程需求,同时支持数据和流数据的实时分析可视化,适用于从学术研究到企业级应用的广泛场景。
欲了解更多信息,欢迎关注公众号:Altair 澳汰尔