java集合类(容器)
Java中的集合类主要由Collection和Map这两个接口派生而出,其中Collection接口又派生出三个子接口,分别是Set、List、Queue。所有的Java集合类,都是Set、List、Queue、Map这四个接口的实现类,这四个接口将集合分成了四大类:
- Set代表无序的,元素不可重复的集合;
- List代表有序的,元素可以重复的集合;
- Queue代表先进先出(FIFO)的队列;
- Map代表具有映射关系(key-value)的集合,其所有的key是一个Set集合,即key无序且不能重复。
Conllection
我们先看看Conllection体系继承树

蓝色框:接口 红色框:实现类 红色框+阴影:常用实现类
List集合(接口)(有序且重复)
public interface List<E> extends Collection<E> {
...
}
ArrayList(数组):动态数组,支持随机访问.
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
...
}
LinkedList(链表):基于双向链表实现,只能顺序访问,但是可以快速地在链表中间插入和删除元素.
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{
...
}
Vector(安全数组):和ArrayList类似,但是它是线程安全的.
public class Vector<E>
extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
...
}
Set集合(接口)(无序且不可重复)
HashSet:哈希表,基于HashMap,可以放入null,但是只能放一个null.
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
...
public HashSet() {
map = new HashMap<>();
}
...
}
LinkedHashSet:基于链表和哈希表,保证了顺序以及唯一性.
public class LinkedHashSet<E>
extends HashSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
...
}
TreeSet:红黑树,元素不能为null,基于TreeMap
public class TreeSet<E> extends AbstractSet<E>
implements NavigableSet<E>, Cloneable, java.io.Serializable
{
...
public TreeSet() {
this(new TreeMap<E,Object>());
}
...
}
Queue队列(接口)(FIFO先进先出)
ArrayDeque:ArrayDeque类是 双端队列的线性实现类,继承接口Deque(双端队列),接口Deque继承Queue
public class ArrayDeque<E> extends AbstractCollection<E>
implements Deque<E>, Cloneable, Serializable
{
...
}
迭代器(Iterator)
迭代器是属于设计模式之一,迭代器模式提供了一种方法来顺序访问一个聚合对象中的各个元素,而不保留该对象的内部表示.
Iterator对象称为迭代器,主要用于遍历Collection集合中的元素。
集合的顶层接口Collection继承Iterable接口。
public interface Collection<E> extends Iterable<E>{
...
}
使用方法:

Map
代表具有映射关系的集合(key-value)key由set存储,所以无序且不能改变,value由单向链表存储.
public interface Map<K,V>{
...
}
以下是Map的继承树

HashMap(链表+红黑树): 1.7基于数组+链表实现,1.8基于数组+链表+红黑树。
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable
{
...
}
LinkedHashMap:哈希表+双向链表维护顺序,继承自 HashMap
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V>
{
...
}
TreeMap:红黑树,TreeMap是NavigableMap接口的直接实现类,其底层数据结构是红黑树结构,不过因为NavigableMap接口也间接继承了Map接口,因此Map拥有的特点TreeMap也同样拥有。并且TreeMap基本没有自身特点,我们可以直接认为Map的特点就是TreeMap的特点。
public class TreeMap<K,V>
extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, java.io.Serializable
{
...
}
public interface NavigableMap<K,V> extends SortedMap<K,V> {
...
}
public interface SortedMap<K,V> extends Map<K,V> {
}
安全容器
-
Vector,HashTable,等(java5 之前自带的集合类,虽然安全,但是性能较差)
-
Concurrent(java5之后的安全类,以Concurrent开头的集合类,支持并发访问)
-
CopyOnWrite(以CopyOnWrite开头的集合类,采用复制副本修改的方法实现并发读写)
Stream流
以流的方式操作集合,java8之后提出.
Stream将要处理的元素集合看作一种流,在流的过程中,借助Stream API对流中的元素进行操作,比如:筛选、排序、聚合等。
聚集方法
对流中的元素进行处理
方法分类:Stream可以由数组或集合创建,对流的操作分为两种:
- 中间操作,每次返回一个新的流,可以有多个流.
- 终端操作,每个流只能进行一次终端操作,终端操作结束后流无法再次使用.终端操作会产生一个新的集合或值.
方法特征
- 有状态的方法(给流增加一些属性,比如不能重复等)
- 短路方法(尽早结束对流的操作,不比检查所有元素)
特性:
- stream不存储数据,而是按照特定的规则对数据进行计算,一般会输出结果.
- stream不会改变数据源,通常情况下会产生一个新的集合或一个值.
- stream具有延迟执行特性,只有代用终端操作时,中间操作才会执行.
使用方式
- 使用Stream的builder()方法创建对应Builder
- 重复调用add()向流添加多个元素
- 调用Builder的builder()方法获取对应Steam
- 调用Stream的聚集方法
Stream的创建
- 通过
java.util.Collection.stream()方法用集合创建流.
//创建数组
List<String> list = Arrays.asList("a","b","c");
//创建顺序流
Stream<String> stream = list.stream();
stream.forEach(System.out::println);
System.out.println("\n");
//创建并行流
Stream<String> parallelStream = list.parallelStream();
parallelStream.forEach(System.out::println);
结果:
a
b
c
b
c
a
- 使用
java.util.Arrays.stream(T[] array)方法用数组创建流
//创建数组
int[] array = {1,2,3,4,5};
//创建流
IntStream intStream = Arrays.stream(array);
intStream.forEach(System.out::println);
结果:
1
2
3
4
5
-
使用
Stream的静态方法:of()、iterate()、generate()-
of()方法是对集合添加元素的优化,因为List和Set接口用add()方法一个个元素添加特别的麻烦,map接口添加元素用put(K,V)也是一个个添加特别麻烦。of()方法可以一次性添加多个元素,是一个静态的方法,只能用在接口List,Map和Set,不能用在他们的实现类.
-
迭代器创建
-
Stream.generate,
generate方法返回一个无限连续的无序流,其中每个元素由提供的供应商(Supplier)生成。generate方法用于生成常量流和随机元素流。
-
static Stream generate(Supplier<? extends T> s)
参数:传递生成流元素的供应商(
Supplier)。
返回:它返回一个新的无限顺序无序的流(Stream)。
//of()方法创建
Stream<Integer> stream1 = Stream.of(1, 2, 3, 4, 5);
stream1.forEach(System.out::println);
System.out.println("\n");
//迭代器创建
Stream<Integer> stream2 = Stream.iterate(0,(x)->x+3).limit(4);
stream2.forEach(System.out::println);
System.out.println("\n");
//Stream.generate
Stream<Double> stream3 = Stream.generate(Math::random).limit(3);
stream3.forEach(System.out::println);
结果:
1
2
3
4
5
0
3
6
9
0.38712696410649783
0.5341484475982541
0.7667782667234894
注意:
stream和parallelStream的简单区分:stream是顺序流,由主线程按顺序对流执行操作,而parallelStream是并行流,内部以多线程并行执行的方式对流进行操作,但前提是流中的数据处理没有顺序要求。例如筛选集合中的奇数,两者的处理不同之处:

如果流中的数据量足够大,并行流可以加快处速度。
除了直接创建并行流,还可以通过parallel()把顺序流转换成并行流:
//创建数组
List<String> list = Arrays.asList("a", "b", "c");
//创建顺序流
Stream<String> stream = list.stream();
//将顺序流转换为并行流
stream.parallel();
stream.forEach(System.out::println);
结果:
b
c
a
Stream的使用
我们需要先了解一个类:Optional.
Optional 类是一个可以为null的容器对象。如果值存在则isPresent()方法会返回true,调用get()方法会返回该对象。
Optional 是个容器:它可以保存类型T的值,或者仅仅保存null。Optional提供很多有用的方法,这样我们就不用显式进行空值检测。
Optional 类的引入很好的解决空指针异常。
public final class Optional<T> extends Object{
}
首先定义一个员工类
public class Person {
private String name; // 姓名
private int salary; // 薪资
private int age; // 年龄
private String sex; //性别
private String area; // 地区
// 构造方法
public Person(String name, int salary, int age,String sex,String area) {
this.name = name;
this.salary = salary;
this.age = age;
this.sex = sex;
this.area = area;
}
//添加get和set方法
...
}
为集合添加一些初始元素.
List<Person> personList = new ArrayList<Person>();
personList.add(new Person("Tom", 8900, 23, "male", "New York"));
personList.add(new Person("Jack", 7000, 25, "male", "Washington"));
=personList.add(new Person("Lily", 7800, 21, "female", "Washington"));
=personList.add(new Person("Anni", 8200, 24, "female", "New York"));
=personList.add(new Person("Owen", 9500, 25, "male", "New York"));
=personList.add(new Person("Alisa", 7900, 26, "female", "New York"));
遍历/匹配(foreach/find/match)
Stream支持类似集合的遍历和匹配元素,只是stream中的元素是以Optional类型存在的.
Stream的遍历和匹配也比较简单.

//定义一个List
List<Integer> list = Arrays.asList(7, 6, 9, 3, 8, 2, 1);
//遍历输出符合条件的元素
list.stream().filter(x->x>6).forEach(System.out::println);
//匹配第一个
Optional<Integer> findFirst = list.stream().filter(x -> x > 6).findFirst();
//匹配任意(适用于并行流)
Optional<Integer> findAny = list.parallelStream().filter(x->x>6).findAny();
//是否包含符合特定条件的元素
boolean anyMatch = list.stream().anyMatch(x->x>6);
System.out.println("匹配第一个值:" + findFirst.get());
System.out.println("匹配任意一个值:" + findAny.get());
System.out.println("是否存在大于6的值:" + anyMatch);
7
9
8
匹配第一个值:7
匹配任意一个值:8
是否存在大于6的值:true
筛选(filter)
筛选,是按照一定的规则校验流中的元素,将符合条件的元素提取到新的流中的操作。

案例一:筛选出Integer集合中大于7的元素,并打印出来
List<Integer> list = Arrays.asList(6, 7, 3, 8, 1, 2, 9);
Stream<Integer> stream = list.stream();
stream.filter(x->x>7).forEach(System.out::println);
8
9
案例二: 筛选员工中工资高于8000的人,并形成新的集合。 形成新集合依赖collect(收集),后文有详细介绍。
//筛选筛选员工中工资高于8000的人,并形成新的集合。
//map()方法通常与流(Stream)一起使用,用于将流中的每个元素映射到另一个元素。
List<String> fiterList = personList.stream() .filter(x>x.getSalary()>8000).map(Person::getName)
.collect(Collectors.toList());
System.out.print("薪资高于8000美元的员工:" + fiterList);
薪资高于8000美元的员工:[Tom, Anni, Owen]
聚合(max/min/count)
max、min、count这些字眼你一定不陌生,没错,在mysql中我们常用它们进行数据统计。Java stream中也引入了这些概念和用法,极大地方便了我们对集合、数组的数据统计工作。

案例一:获取String集合中最长的元素。
List<String> list = Arrays.asList("adnm", "admmt", "pot", "xbangd", "weoujgsd");
Optional<String> max = list.stream().max(Comparator.comparing(String::length));
System.out.println("最长的字符串:" + max.get());
最长的字符串:weoujgsd
案例二:获取Integer集合中的最大值。
List<Integer> list = Arrays.asList(7, 6, 9, 4, 11, 6);
//max通过自定义方法可以实现不同的功能
//自然排序
Optional<Integer> max = list.stream().max(Integer::compareTo);
//自定义排序(从大到小排序)(o1-o2就是升序,o2-o1就是降序)
//因为在comparator里面,-1代表小于,0代表等于,1代表大于
Optional<Integer> max2 = list.stream().max(((o1, o2) -> o2-o1));
System.out.println("自然排序的最大值:" + max.get());
System.out.println("自定义排序的最大值:" + max2.get());
自然排序的最大值:11
自定义排序的最大值:4
案例三:获取员工薪资最高的人。
//获取员工薪资最高的人
Optional<Person> max = personList.stream().max(Comparator.comparing(Person::getSalary));
System.out.println("员工薪资最大值:" + max.get().getSalary());
员工薪资最大值:9500
案例四:计算Integer集合中大于6的元素的个数。
//计算Integer集合中大于6的元素的个数
List<Integer> list = Arrays.asList(7, 6, 4, 8, 2, 11, 9);
long count = list.stream().filter(x->x>6).count();
System.out.println("list中大于6的元素个数:" + count);
list中大于6的元素个数:4
映射(map/flatMap)
映射,可以将一个流的元素按照一定的映射规则映射到另一个流中。分为map和flatMap:
map:接收一个函数作为参数,该函数会被应用到每个元素上,并将其映射成一个新的元素。flatMap:接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流。


案例一:英文字符串数组的元素全部改为大写。整数数组每个元素+3。
//英文字符串数组的元素全部改为大写。整数数组每个元素+3
String[] strArr = { "abcd", "bcdd", "defde", "fTr" };
List<String> stringList = Arrays.stream(strArr)
.map(String::toUpperCase).collect(Collectors.toList());
List<Integer> integerList = Arrays.asList(1, 3, 5, 7, 9, 11);
List<Integer> intListNew = integerList.stream().map(x->x+3)
.collect(Collectors.toList());
System.out.println("每个元素大写:" + stringList);
System.out.println("每个元素+3:" + intListNew);
每个元素大写:[ABCD, BCDD, DEFDE, FTR]
每个元素+3:[4, 6, 8, 10, 12, 14]
案例二:将员工的薪资全部增加1000。
//不改变原来员工集合的方式(新建一个对象进行修改)
List<Person> personListNew = personList.stream().map(person -> {
Person personNew = new Person(person.getName(), 0, 0, null, null);
personNew.setSalary(person.getSalary() + 10000);
return personNew;
}).collect(Collectors.toList());
System.out.println("一次改动前:" + personList.get(0).getName() + "-->" + personList.get(0).getSalary());
System.out.println("一次改动后:" + personListNew.get(0).getName() + "-->" + personListNew.get(0).getSalary());
// 改变原来员工集合的方式(在原来对象的基础上进行修改)
List<Person> personListNew2 = personList.stream().map(person -> {
person.setSalary(person.getSalary() + 10000);
return person;
}).collect(Collectors.toList());
System.out.println("二次改动前:" + personList.get(0).getName() + "-->" + personListNew.get(0).getSalary());
System.out.println("二次改动后:" + personListNew2.get(0).getName() + "-->" + personListNew.get(0).getSalary());
一次改动前:Tom-->8900
一次改动后:Tom-->18900
二次改动前:Tom-->18900
二次改动后:Tom-->18900
案例三:将两个字符数组合并成一个新的字符数组。
//将两个字符数组合并成一个新的字符数组
List<String> list = Arrays.asList("m,k,l,a", "1,3,5,7");
List<String> listNew = list.stream().flatMap(s->{
//将每个元素转换成一个stream
String[] split = s.split(",");
Stream<String> stringStream = Arrays.stream(split);
return stringStream;
}).collect(Collectors.toList());
System.out.println("处理前的集合:" + list);
System.out.println("处理后的集合:" + listNew);
处理前的集合:[m,k,l,a, 1,3,5,7]
处理后的集合:[m, k, l, a, 1, 3, 5, 7]
此外,map系列还有mapToInt、mapToLong、mapToDouble三个函数,它们以一个映射函数为入参,将流中每一个元素处理后生成一个新流。以mapToInt为例,看两个示例:
public static void main(String[] args) {
// 输出字符串集合中每个字符串的长度
List<String> stringList = Arrays.asList("mu", "CSDN", "hello",
"world", "quickly");
stringList.stream().mapToInt(String::length).forEach(System.out::println);
// 将int集合的每个元素增加1000
List<Integer> integerList = Arrays.asList(4, 5, 2, 1, 6, 3);
integerList.stream().mapToInt(x -> x + 1000).forEach(System.out::println);
}
mapToInt三个函数生成的新流,可以进行很多后续操作,比如求最大最小值、求和、求平均值:
public static void main(String[] args) {
List<Double> doubleList = Arrays.asList(1.0, 2.0, 3.0, 4.0, 2.0);
double average = doubleList.stream().mapToDouble(Number::doubleValue).average().getAsDouble();
double sum = doubleList.stream().mapToDouble(Number::doubleValue).sum();
double max = doubleList.stream().mapToDouble(Number::doubleValue).max().getAsDouble();
System.out.println("平均值:" + average + ",总和:" + sum + ",最大值:" + max);
}
归约(reduce)
归约,也称缩减,顾名思义,是把一个流缩减成一个值,能实现对集合求和、求乘积和求最值操作。
reduce函数其用作从一个流中生成一个值,其生成的值不是随意的,而是根据指定的计算模型。
比如终止操作中提到 count、min 和 max 方法,因为常用而被纳入标准库中。事实上这些方法都是一种 reduce 操作。

reduce操作三要素:
Optional reduce(BinaryOperator accumulator);
T reduce(T identity, BinaryOperator accumulator);
U reduce(U identity,
BiFunction<U, ? super T, U> accumulator,
BinaryOperator combiner);
可以看到,在 Stream API 中,提供了三个 reduct 操作方法,根据参数不同进行区分。
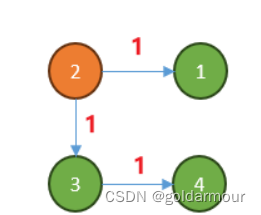
identity,accumulator,combiner
接下来,我来介绍一下这三个参数分别有什么作用.
- identiy
identiy(初始值)是 reduce 操作的初始值,也就是当元素集合为空时的默认结果。对应下方代码示例,也就是说 reduce 操作的初始值是 0和1。
- accumulator
accumulator(累加器)是一个函数,它接受两个参数,reduce 操作的部分元素和元素集合中的下一个元素。它返回一个新的部分元素。在这个例子中,累加器是一个 lambda 表达式,它将集合中两个整数相加并返回一个整数:(x,y)->x+y。
- combiner
combiner(组合器)是一个函数,它用于在 reduce 操作被并行化或者当累加器的参数类型和实现类型不匹配时,将 reduce 操作的部分结果进行组合。在上面代码示例中,我们不需要使用组合器,因为上面我们的 reduce 操作不需要并行,而且累加器的参数类型和实现类型都是 Integer。
combiner(组合器),说白了就是在并行流中会用到.
如图所示:

案例一:求Integer集合的元素之和、乘积和最大值。
//求Integer集合的元素之和、乘积和最大值。
List<Integer> list = Arrays.asList(1, 3, 2, 8, 11, 4);
//求和方式1
Optional<Integer> sum = list.stream().reduce((x,y)->x+y);
//求和方式2
Optional<Integer> sum2 = list.stream().reduce(Integer::sum);
//求和方式3
Integer sum3 = list.stream().reduce(0,Integer::sum);
//求乘积
Optional<Integer> product = list.stream().reduce((x,y)->x*y);
//求最大值方式1
Optional<Integer> max1 = list.stream().reduce((x, y) -> x > y ? x : y);
//求最大值方式2
Integer max2 = list.stream().reduce(1,Integer::max);
System.out.println("list求和:" + sum.get() + "," + sum2.get() + "," + sum3);
System.out.println("list求积:" + product.get());
System.out.println("list求最大值:" + max1.get() + "," + max2);
list求和:29,29,29
list求积:2112
list求最大值:11,11
案例二:求所有员工的工资之和和最高工资。
//求工资之和方式1
Optional<Integer> sumSalary1 = personList.stream().map(Person::getSalary).reduce(Integer::sum);
//求工资之和方式2
Integer sumSalary2 = personList.stream().reduce(0, (sum, p) ->
sum += p.getSalary(), (sum1, sum2) -> sum1 + sum2);
// 求工资之和方式3
Integer sumSalary3 = personList.stream().reduce(0, (sum, p) -> sum += p.getSalary(), Integer::sum);
// 求最高工资方式1
Integer maxSalary1 = personList.stream().reduce(0, (max, p) -> max > p.getSalary() ? max : p.getSalary(),
Integer::max);
// 求最高工资方式2
Integer maxSalary2 = personList.stream().reduce(0, (max, p) -> max > p.getSalary() ? max : p.getSalary(),
(max1, max2) -> max1 > max2 ? max1 : max2);
// 求最高工资方式3
Integer maxSalary3 = personList.stream().map(Person::getSalary).reduce(Integer::max).get();
System.out.println("工资之和:" + sumSalary1.get() + "," + sumSalary2 + "," + sumSalary3);
System.out.println("最高工资:" + maxSalary1 + "," + maxSalary2 + "," + maxSalary3);
工资之和:49300,49300,49300
最高工资:9500,9500,9500
收集(collect)
collect,收集,可以说是内容最繁多、功能最丰富的部分了。从字面上去理解,就是把一个流收集起来,最终可以是收集成一个值也可以收集成一个新的集合。
collect主要依赖java.util.stream.Collectors类内置的静态方法。
- 归集(toList/toSet/toMap)
因为流不存储数据,那么在流中的数据完成处理后,需要将流中的数据重新归集到新的集合里。toList、toSet和toMap比较常用,另外还有toCollection、toConcurrentMap等复杂一些的用法。
下面用一个案例演示toList、toSet和toMap:
List<Integer> list = Arrays.asList(1, 6, 3, 4, 6, 7, 9, 6, 20);
List<Integer> listNew= list.stream().filter(x->x%2==0).collect(Collectors.toList());
Set<Integer> set = list.stream().filter(x->x%2==0).collect(Collectors.toSet());
System.out.println("toList:" + listNew);
System.out.println("toSet:" + set);
toList:[6, 4, 6, 6, 20]
toSet:[4, 20, 6]
Map<?,Person> map = personList.stream().filter(p -> p.getSalary() > 8000).collect(Collectors.toMap(Person::getName,p->p));
System.out.println("toMap:" + map);
toMap:{Tom=Person@15aeb7ab, Owen=Person@7b23ec81, Anni=Person@6acbcfc0}
- 统计(count/averaging)
Collectors提供了一系列用于数据统计的静态方法:
- 计数:count
- 平均值:averagingInt、averagingLong、averagingDouble
- 最值:maxBy、minBy
- 求和:summingInt、summingLong、summingDouble
- 统计以上所有:summarizingInt、summarizingLong、summarizingDouble
案例:统计员工人数、平均工资、工资总额、最高工资。
// 求总数
Long count = personList.stream().collect(Collectors.counting());
// 求平均工资
Double average = personList.stream().collect(Collectors.averagingDouble(Person::getSalary));
// 求最高工资
Optional<Integer> max = personList.stream().map(Person::getSalary).collect(Collectors.maxBy(Integer::compare));
// 求工资之和
Integer sum = personList.stream().collect(Collectors.summingInt(Person::getSalary));
// 一次性统计所有信息
DoubleSummaryStatistics collect = personList.stream().collect(Collectors.summarizingDouble(Person::getSalary));
System.out.println("员工总数:" + count);
System.out.println("员工平均工资:" + average);
System.out.println("员工工资总和:" + sum);
System.out.println("员工工资所有统计:" + collect);
员工总数:6
员工平均工资:8216.666666666666
员工工资总和:49300
员工工资所有统计:DoubleSummaryStatistics{count=6, sum=49300.000000, min=7000.000000, average=8216.666667, max=9500.000000}
- 分组(partitioningBy/groupingBy)
- 分区:将
stream按条件分为两个Map,比如员工按薪资是否高于8000分为两部分。 - 分组:将集合分为多个Map,比如员工按性别分组。有单级分组和多级分组。
案例:将员工按薪资是否高于8000分为两部分;将员工按性别和地区分组
//将员工按薪资是否高于8000分组
Map<Boolean,List<Person>> part = personList.stream().collect(Collectors.partitioningBy(x->x.getSalary()>8000));
//将员工按照性别分组
Map<String,List<Person>> group = personList.stream().collect(Collectors.groupingBy(Person::getSex));
// 将员工先按性别分组,再按地区分组
Map<String, Map<String, List<Person>>> group2 = personList.stream().collect(Collectors.groupingBy(Person::getSex, Collectors.groupingBy(Person::getArea)));
System.out.println("员工按薪资是否大于8000分组情况:" + part);
System.out.println("员工按性别分组情况:" + group);
System.out.println("员工按性别、地区:" + group2);
员工按薪资是否大于8000分组情况:{false=[Person@7291c18f, Person@34a245ab, Person@7cc355be], true=[Person@6e8cf4c6, Person@12edcd21, Person@34c45dca]}
员工按性别分组情况:{female=[Person@34a245ab, Person@12edcd21, Person@7cc355be], male=[Person@6e8cf4c6, Person@7291c18f, Person@34c45dca]}
员工按性别、地区:{female={New York=[Person@12edcd21, Person@7cc355be], Washington=[Person@34a245ab]}, male={New York=[Person@6e8cf4c6, Person@34c45dca], Washington=[Person@7291c18f]}}
- 接合(joining)
joining可以将stream中的元素用特定的连接符(没有的话,则直接连接)连接成一个字符串。
String name = personList.stream().map(person -> person.getName()).collect(Collectors.joining(","));
System.out.println("所有员工的姓名:" + name);
所有员工的姓名:Tom,Jack,Lily,Anni,Owen,Alisa
- 归约(reducing)
Collectors类提供的reducing方法,相比于stream本身的reduce方法,增加了对自定义归约的支持。
// 每个员工减去起征点后的薪资之和
Integer sum = personList.stream().collect(Collectors.reducing(0, Person::getSalary, (i, j) -> (i + j - 5000)));
System.out.println("员工扣税薪资总和:" + sum);
员工扣税薪资总和:19300
排序(sorted)
sorted,中间操作。有两种排序:
- sorted():自然排序,流中元素需实现Comparable接口
- sorted(Comparator com):Comparator排序器自定义排序
案例:将员工按工资由高到低(工资一样则按年龄由大到小)排序
// 按工资升序排序(自然排序)
List<String> newList = personList.stream().sorted(Comparator.comparing(Person::getSalary)).map(Person::getName)
.collect(Collectors.toList());
// 按工资倒序排序
List<String> newList2 = personList.stream().sorted(Comparator.comparing(Person::getSalary).reversed())
.map(Person::getName).collect(Collectors.toList());
// 先按工资再按年龄升序排序
List<String> newList3 = personList.stream()
.sorted(Comparator.comparing(Person::getSalary).thenComparing(Person::getAge)).map(Person::getName)
.collect(Collectors.toList());
// 先按工资再按年龄自定义排序(降序)
List<String> newList4 = personList.stream().sorted((p1, p2) -> {
if (p1.getSalary() == p2.getSalary()) {
return p2.getAge() - p1.getAge();
} else {
return p2.getSalary() - p1.getSalary();
}
}).map(Person::getName).collect(Collectors.toList());
System.out.println("按工资升序排序:" + newList);
System.out.println("按工资降序排序:" + newList2);
System.out.println("先按工资再按年龄升序排序:" + newList3);
System.out.println("先按工资再按年龄自定义降序排序:" + newList4);
按工资升序排序:[Jack, Lily, Alisa, Anni, Tom, Owen]
按工资降序排序:[Owen, Tom, Anni, Alisa, Lily, Jack]
先按工资再按年龄升序排序:[Jack, Lily, Alisa, Anni, Tom, Owen]
先按工资再按年龄自定义降序排序:[Owen, Tom, Anni, Alisa, Lily, Jack]
提取/组合
流也可以进行合并、去重、限制、跳过等操作。
String[] arr1 = { "a", "b", "c", "d" };
String[] arr2 = { "d", "e", "f", "g" };
Stream<String> stream1 = Stream.of(arr1);
Stream<String> stream2 = Stream.of(arr2);
// concat:合并两个流 distinct:去重
List<String> newList = Stream.concat(stream1, stream2).distinct().collect(Collectors.toList());
// limit:限制从流中获得前n个数据
List<Integer> collect = Stream.iterate(1, x -> x + 2).limit(10).collect(Collectors.toList());
// skip:跳过前n个数据
List<Integer> collect2 = Stream.iterate(1, x -> x + 2).skip(1).limit(5).collect(Collectors.toList());
System.out.println("流合并:" + newList);
System.out.println("limit:" + collect);
System.out.println("skip:" + collect2);
流合并:[a, b, c, d, e, f, g]
limit:[1, 3, 5, 7, 9, 11, 13, 15, 17, 19]
skip:[3, 5, 7, 9, 11]
哈希(hash)
了解哈希
定义
散列表(Hash table,也叫哈希表),是根据键(Key)而直接访问在内存存储位置的数据结构。也就是说,它通过计算一个关于键值的函数,将所需查询的数据映射到表中一个位置来访问记录,这加快了查找速度。这个映射函数称做散列函数,存放记录的数组称做散列表。
哈希表其实是一种数据结构。
特点
如果我们要根据名字找到其中的任何一个元素,就需要遍历整个数组。最坏情况下时间复杂度是O(n) ,但是借助 Hash 可以将时间复杂度降为O(1)。
原理
Hash表采用一个映射函数 f :key —> address 将关键字映射到该记录在表中的存储位置,从而在想要查找该记录时,可以直接根据关键字和映射关系计算出该记录在表中的存储位置,通常情况下,这种映射关系称作为Hash函数,而通过Hash函数和关键字计算出来的存储位置(注意这里的存储位置只是表中的存储位置,并不是实际的物理地址)称作为Hash地址。
优点
哈希表的效率非常高,查找、插入、删除操作只需要接近常量的时间即0(1)的时间级。如果需要在一秒种内查找上千条记录通常使用哈希表,哈希表的速度明显比树快,树的操作通常需要O(N)的时间级。哈希表不仅速度快,编程实现也相对容易。如果不需要遍历数据,不二的选择。
缺点
它是基于数组的,数组创建后难于扩展。有些情况下,哈希表被基本填满时,性能下降得非常严重,所以开发者必须要清楚表中将要存储的数据量。或者也可以定期地把数据转移到更大的哈希表中,不过这个过程耗时相对比较大。
应用
-
唯一标识或数据检验
能够对输入数据或文件进行校验,判断是否相同或是否被修改。如图片识别,可针对图像二进制流进行摘要后MD5,得到的哈希值作为图片唯一标识;
-
安全加密
对于敏感数据比如密码字段进行MD5或SHA加密传输。哈希算法还可以检验信息的拥有者是否真实。如,用保存密码的哈希值代替保存密码,基本可以杜绝泄密风险。
-
数字签名
由于非对称算法的运算速度较慢,所以在数字签名协议中,单向散列函数扮演了一个重要的角色。对Hash值,又称“数字摘要”进行数字签名,在统计上可以认为与对文件本身进行数字签名是等效的。
-
散列函数
是构造散列表的关键。它直接决定了散列冲突的概率和散列表的性质。不过相对哈希算法的其他方面应用,散列函数对散列冲突要求较低,出现冲突时可以通过开放寻址法或链表法解决冲突。对散列值是否能够反向解密要求也不高。反而更加关注的是散列的均匀性,即是否散列值均匀落入槽中以及散列函数执行的快慢也会影响散列表性能。所以散列函数一般比较简单,追求均匀和高效。
-
负载均衡
常用的负载均衡算法有很多,比如轮询、随机、加权轮询。如何实现一个会话粘滞的负载均衡算法呢?可以通过哈希算法,对客户端IP地址或会话SessionID计算哈希值,将取得的哈希值与服务器列表大小进行取模运算,最终得到应该被路由到的服务器编号。这样就可以把同一IP的客户端请求发到同一个后端服务器上。
-
分布式存储
一致性哈希算法解决缓存等分布式系统的扩容、缩容导致大量数据搬移难题。
Hash函数
定义
所谓的 hash 函数就是将字符串转换为数字的算法。
种类
-
直接定址法
取关键字或者关键字的某个线性函数为 Hash 地址,即address(key) = a * key + b; 如知道学生的学号从2000开始,最大为4000,则可以将address(key)=key-2000(其中a = 1)作为Hash地址。
-
平方取中法
对关键字进行平方计算,取结果的中间几位作为 Hash 地址。如有以下关键字序列 {421,423,436} ,平方之后的结果为 {177241,178929,190096} ,那么可以取中间的两位数 {72,89,00} 作为 Hash 地址。
-
折叠法
将关键字拆分成几部分,然后将这几部分组合在一起,以特定的方式进行转化形成Hash地址。如图书的 ISBN 号为 8903-241-23,可以将 address(key)=89+03+24+12+3 作为 Hash 地址。
-
除留取余法
如果知道 Hash 表的最大长度为 m,可以取不大于m的最大质数 p,然后对关键字进行取余运算,address(key)=key % p。这里 p 的选取非常关键,p 选择的好的话,能够最大程度地减少冲突,p 一般取不大于m的最大质数。
在设计Hash函数的时候。一定要保证相同字符串产生的 Hash 值相同,同时要尽量的减小Hash冲突的发生,这样才算是好的 hash 函数。
Hash算法
定义
Hash 算法能将将任意长度的二进制明文映射为较短的二进制串的算法,并且不同的明文很难映射为相同的 Hash 值。
散列算法(Hash Algorithm),又称哈希算法,杂凑算法,是一种从任意文件中创造小的数字「指纹」的方法。与指纹一样,散列算法就是一种以较短的信息来保证文件唯一性的标志,这种标志与文件的每一个字节都相关,而且难以找到逆向规律。
常见Hash算法有MD5和SHA系列,目前MD5和SHA1已经被破解,一般推荐至少使用SHA2-256算法。
MD5
定义
MD5属于Hash算法中的一种,它输入任意长度的信息,在处理过程中以512位输入数据块为单位,输出为128位的信息(数字指纹)。
适用场景
-
防篡改,保障文件传输可靠性
如SVN中对文件的控制;文件下载过程中,网站提供MD5值供下载后判断文件是否被篡改;BT中对文件块进行校验的功能。
-
增强密码保存的安全性
例如网站将用户密码的MD5值保存,而不是存储明文用户密码,当然,还会加SALT,进一步增强安全性。
-
数字签名
在部分网上赌场中,使用MD5算法来保证过程的公平性,并使用随机串进行防碰撞,增加解码难度。
过程
- 消息填充,补长到512的倍数。最后64位为消息长度(填充前的长度)的低64位,一定要补长(64+1~512),内容为100…0(如若消息长448,则填充512+64)。
- 分割,把结果分割为512位的块:Y0,Y1,…(每一个有16个32比特长字)。
- 计算,初始化MD buffer,128位常量(4个32bit字),进入循环迭代,共L次。每次一个输入128位,另一个输入512位,结果输出128位,用于下一轮输入。
- 输出,最后一步的输出即为散列结果128位。
SHA-1
安全哈希算法(Secure Hash Algorithm)主要适用于数字签名标准(Digital Signature Standard DSS)里面定义的数字签名算法(Digital Signature Algorithm DSA)。对于长度小于2^64b的消息,SHA-1将输入流按照每块512b(64B)进行分块,并产生20B或160b的信息摘要。
SHA-2
SHA-2是六个不同算法的合称,包括:SHA-224、SHA-256、SHA-384、SHA-512、SHA-512/224、SHA-512/256。除了生成摘要的长度、循环运行的次数等一些微小差异外,这些算法的基本结构是一致的。对于任意长度的消息,SHA256都会产生一个256bit长的消息摘要。