欢迎来到我的博客,很高兴能够在这里和您见面!欢迎订阅相关专栏:
⭐️ 全网最全IT互联网公司面试宝典:收集整理全网各大IT互联网公司技术、项目、HR面试真题.
⭐️ AIGC时代的创新与未来:详细讲解AIGC的概念、核心技术、应用领域等内容。
⭐️ 全流程数据技术实战指南:全面讲解从数据采集到数据可视化的整个过程,掌握构建现代化数据平台和数据仓库的核心技术和方法。
文章目录
- 常见的初级面试题
- 1. 什么是ETL?它的主要步骤有哪些?
- 2. 请解释SQL中的JOIN操作及其常见类型。
- 3. 什么是数据清洗?为什么重要?
- 4. 如何优化SQL查询性能?
- 5. 请解释什么是数据建模?
- 6. 什么是分区(Partitioning)?在数据库中如何使用?
- 7. 请解释什么是索引(Index)?如何影响数据库性能?
- 8. 什么是数据仓库?
- 9. 如何在Python中读取和处理CSV文件?
- 10. 请解释什么是NoSQL数据库,并举例说明。
- 常见的中级面试题
- 1. 什么是数据管道?它的主要组件有哪些?
- 2. 请解释什么是数据湖?它与数据仓库有何不同?
- 3. 如何在Spark中处理大数据?
- 4. 请解释什么是Hadoop及其核心组件。
- 5. 什么是数据分片(Sharding)?如何实现?
- 6. 如何在Python中使用Pandas进行数据清洗?
- 7. 请解释什么是Kafka及其应用场景。
- 8. 如何在数据库中实现事务?事务的ACID特性是什么?
- 9. 请解释什么是数据变换(Data Transformation)?
- 10. 如何设计一个高效的数据管道?
- 常见的高级面试题
- 1. 请解释什么是数据流处理(Stream Processing)及其框架。
- 2. 如何使用Docker容器化数据处理应用?
- 3. 请解释什么是Kubernetes及其在数据工程中的应用。
- 4. 如何在分布式系统中处理数据一致性问题?
- 5. 请解释什么是Lambda架构及其优缺点。
- 6. 如何在大数据环境中实现数据加密和隐私保护?
- 7. 如何处理数据管道中的数据丢失和错误?
- 8. 请解释什么是容错设计及其在数据工程中的重要性。
- 9. 如何在数据管道中实现自动化测试?
- 10. 请解释什么是数据治理(Data Governance)及其关键要素。
- 常考知识点总结
- 1. ETL工具及流程
- 2. 编程语言
- 3. 数据库管理
- 4. 数据建模
- 5. 大数据平台
- 6. 数据管道设计
- 7. 分布式系统
- 8. 容器化技术
- 9. 数据安全与隐私保护
- 10. 数据治理
常见的初级面试题
1. 什么是ETL?它的主要步骤有哪些?
ETL代表提取(Extract)、转换(Transform)和加载(Load)。提取是从不同数据源获取数据,转换是将数据清洗、格式化和处理成分析所需的格式,加载是将转换后的数据存储到目标数据库或数据仓库中。
2. 请解释SQL中的JOIN操作及其常见类型。
JOIN操作用于组合来自两个或多个表的数据。常见类型包括INNER JOIN(只返回匹配的记录)、LEFT JOIN(返回左表所有记录及匹配的右表记录)、RIGHT JOIN(返回右表所有记录及匹配的左表记录)和FULL JOIN(返回两表的所有记录)。
3. 什么是数据清洗?为什么重要?
数据清洗是发现并修正或删除数据集中的错误和不一致的数据。它的重要性在于确保数据质量,使后续分析和决策更准确和可靠。
4. 如何优化SQL查询性能?
可以通过创建索引、优化查询语句(如避免SELECT *)、使用EXPLAIN分析查询计划、避免复杂的子查询和优化JOIN操作来提升SQL查询性能。
5. 请解释什么是数据建模?
数据建模是创建数据模型以定义和分析数据需求的过程。数据模型为数据存储、组织和操作提供结构。常见的数据模型有概念模型、逻辑模型和物理模型。
6. 什么是分区(Partitioning)?在数据库中如何使用?
分区是将大表或索引拆分成更小、更易管理的部分。数据库中的分区可以通过范围(Range)、列表(List)或散列(Hash)等方法实现,能提高查询性能和管理效率。
7. 请解释什么是索引(Index)?如何影响数据库性能?
索引是一种数据结构,用于快速查找数据库表中的记录。正确使用索引能显著提高查询速度,但也会增加插入、更新和删除操作的开销,因为需要维护索引。
8. 什么是数据仓库?
数据仓库是一个面向主题的、集成的、不可变的、随时间变化的数据集合,用于支持管理决策。它汇总了来自不同来源的数据,便于分析和报表生成。
9. 如何在Python中读取和处理CSV文件?
可以使用pandas库的read_csv函数读取CSV文件,并使用DataFrame的方法对数据进行处理。例如:import pandas as pd; df = pd.read_csv('file.csv')。
10. 请解释什么是NoSQL数据库,并举例说明。
NoSQL数据库是一类非关系型数据库,适用于处理大规模分布式数据存储。它们灵活的模式设计和高性能读写特性,使其适合处理海量数据。常见的NoSQL数据库包括MongoDB、Cassandra和Redis。
常见的中级面试题
1. 什么是数据管道?它的主要组件有哪些?
数据管道是数据流动的系统,用于数据提取、处理和存储。主要组件包括数据源、ETL流程、数据存储(如数据仓库)、数据处理工具(如Spark)和数据消费层(如BI工具)。
2. 请解释什么是数据湖?它与数据仓库有何不同?
数据湖是一个存储海量原始数据的系统,可以处理结构化、半结构化和非结构化数据。与数据仓库不同,数据湖在数据存储前不需要预先定义模式,适合大数据分析和机器学习应用。
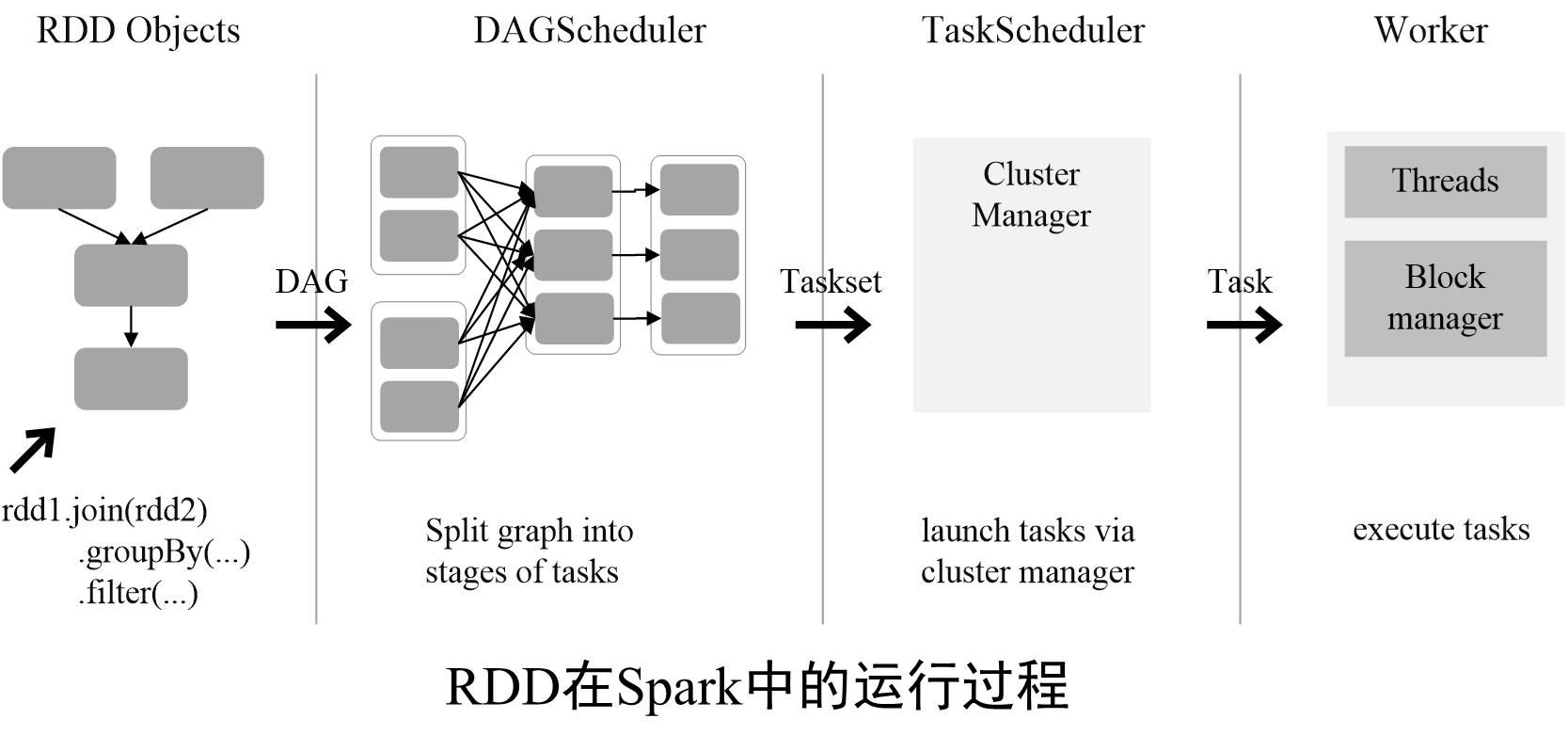
3. 如何在Spark中处理大数据?
可以使用Spark的核心组件RDD进行弹性分布式数据集的操作,使用Spark SQL进行结构化数据的查询,使用Spark Streaming处理实时数据流,以及使用MLlib进行机器学习。
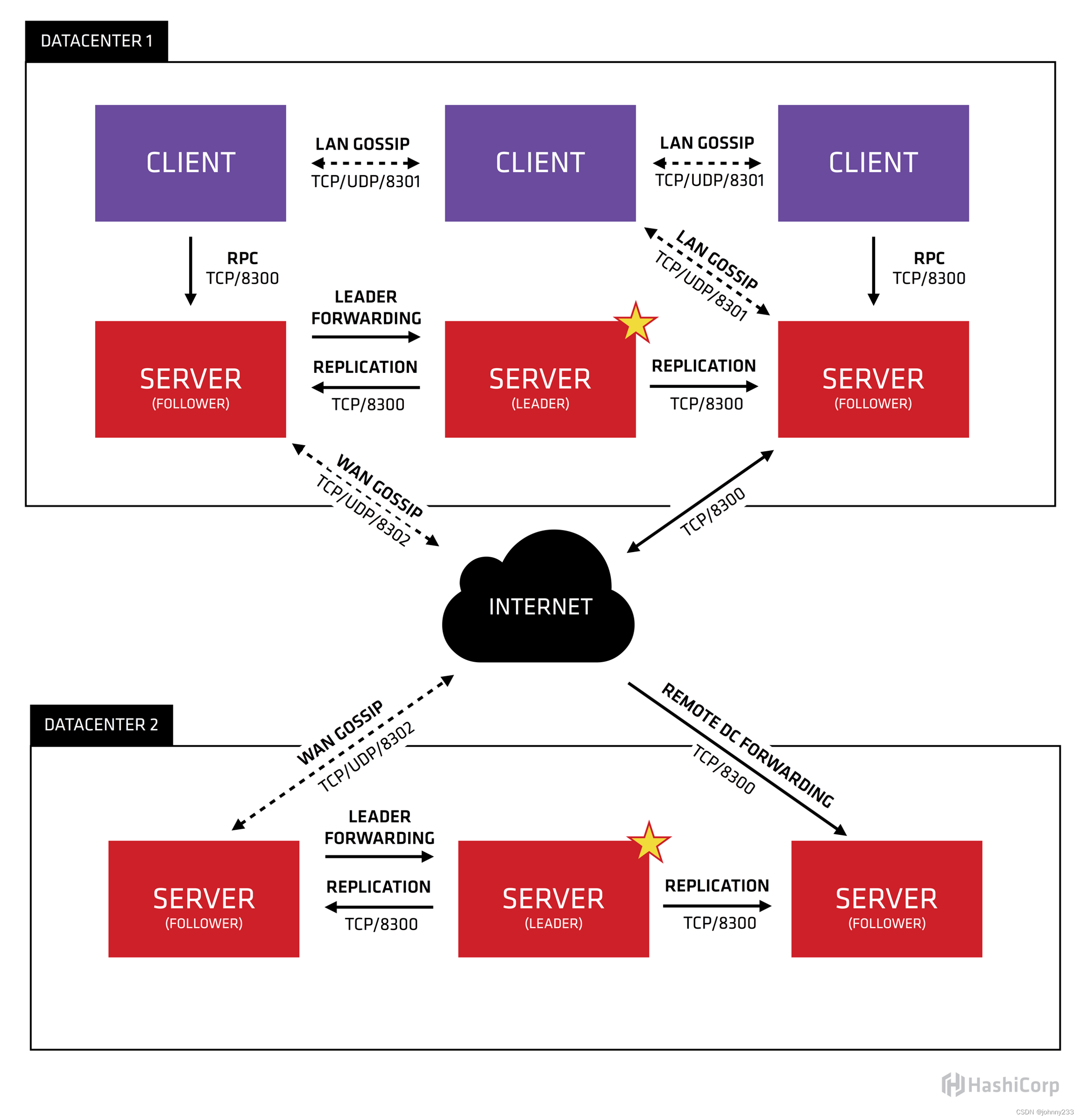
4. 请解释什么是Hadoop及其核心组件。
Hadoop是一个开源的大数据处理框架。其核心组件包括HDFS(Hadoop分布式文件系统)用于分布式存储,MapReduce用于分布式计算,YARN用于资源管理和调度。
5. 什么是数据分片(Sharding)?如何实现?
数据分片是将数据库拆分为更小的部分(称为分片)以提高性能和扩展性。可以通过按范围、散列或地理位置进行分片,常用于NoSQL数据库中,如MongoDB的分片机制。
6. 如何在Python中使用Pandas进行数据清洗?
Pandas提供了丰富的函数用于数据清洗,如dropna移除缺失值,fillna填充缺失值,apply应用自定义函数进行数据转换,astype转换数据类型。
7. 请解释什么是Kafka及其应用场景。
Kafka是一个分布式流处理平台,适用于实时数据流的发布、订阅和存储。应用场景包括日志收集、实时监控、数据流管道和事件驱动的微服务架构。
8. 如何在数据库中实现事务?事务的ACID特性是什么?
事务是确保一组数据库操作原子性执行的机制。ACID特性包括原子性(Atomicity),一致性(Consistency),隔离性(Isolation)和持久性(Durability),确保数据可靠和一致。
9. 请解释什么是数据变换(Data Transformation)?
数据变换是将原始数据转换成适合分析和处理的格式的过程。变换步骤包括数据清理、格式转换、聚合和衍生变量创建。
10. 如何设计一个高效的数据管道?
设计高效数据管道需考虑数据源识别、数据提取频率、数据清洗和处理策略、数据存储选型(如选择适合的数据仓库或数据湖)、数据安全和隐私保护、监控和故障处理机制。
常见的高级面试题
1. 请解释什么是数据流处理(Stream Processing)及其框架。
数据流处理是在数据生成的瞬间对数据进行处理。常见框架包括Apache Kafka、Apache Flink和Apache Storm,适用于实时分析、监控和报警系统。
2. 如何使用Docker容器化数据处理应用?
可以编写Dockerfile定义应用环境和依赖,使用docker build构建镜像,docker run启动容器运行应用,并使用Docker Compose编排多个容器服务,实现数据处理应用的容器化部署。
3. 请解释什么是Kubernetes及其在数据工程中的应用。
Kubernetes是一个容器编排平台,用于自动化部署、扩展和管理容器化应用。在数据工程中,Kubernetes可用于部署和管理大数据处理集群,如Spark集群和Kafka集群。
4. 如何在分布式系统中处理数据一致性问题?
可以通过使用分布式事务、二阶段提交协议(2PC)、幂等操作、最终一致性模型和数据复制机制,来处理分布式系统中的数据一致性问题。
5. 请解释什么是Lambda架构及其优缺点。
Lambda架构结合批处理和流处理,确保数据处理的高容错性和低延迟。优点是实时和批量数据处理兼顾,但存在代码重复和维护复杂性的问题。
6. 如何在大数据环境中实现数据加密和隐私保护?
可以使用透明数据加密(TDE)、字段级加密、传输层安全协议(如TLS/SSL)和访问控制策略(如RBAC)来保护大数据环境中的数据安全和隐私。
7. 如何处理数据管道中的数据丢失和错误?
可以通过数据校验和监控、重试机制、数据版本控制和数据审计日志,来检测和处理数据管道中的数据丢失和错误,确保数据完整性。
8. 请解释什么是容错设计及其在数据工程中的重要性。
容错设计是确保系统在出现故障时仍能正常运行的设计方法。它在数据工程中至关重要,可以通过冗余设计、数据备份、自动故障切换和弹性扩展实现。
9. 如何在数据管道中实现自动化测试?
可以使用单元测试、集成测试和端到端测试,结合CI
/CD工具(如Jenkins、GitLab CI)实现数据管道的自动化测试,确保数据处理流程的正确性和稳定性。
10. 请解释什么是数据治理(Data Governance)及其关键要素。
数据治理是对数据的管理和控制,以确保数据的可用性、完整性、安全性和合规性。关键要素包括数据质量管理、数据安全与隐私保护、数据生命周期管理和数据使用政策。
常考知识点总结
1. ETL工具及流程
了解ETL工具的使用及数据提取、转换和加载的具体步骤。
2. 编程语言
熟悉Python、Scala等编程语言在数据处理中的应用。
3. 数据库管理
掌握SQL及NoSQL数据库的设计、优化和管理技巧。
4. 数据建模
理解概念、逻辑和物理数据模型的构建和应用。
5. 大数据平台
了解Hadoop、Spark等大数据处理平台及其核心组件。
6. 数据管道设计
掌握数据管道的设计、实现和优化方法。
7. 分布式系统
熟悉分布式系统的架构及数据一致性问题的解决方案。
8. 容器化技术
了解Docker和Kubernetes在数据工程中的应用。
9. 数据安全与隐私保护
掌握数据加密、访问控制和隐私保护的技术和策略。
10. 数据治理
了解数据治理的关键要素及其在企业中的重要性。
💗💗💗 如果觉得这篇文对您有帮助,请给个点赞、关注、收藏吧,谢谢!💗💗💗
👇扫👇 码👇+ V👇获取👇更多👇福利👇






![[JS]BOM操作](https://img-blog.csdnimg.cn/img_convert/75c88108fea0d40c83e480df4562c682.png)