写在前面:
transformer模型已经是老生常谈的一个东西,以transformer为基础出现了很多变体和文章,Informer、autoformer、itransformer等等都是顶刊顶会。一提到transformer自然就是注意力机制,变体更是数不胜数,一提到注意力自然就是“放大优点,忽视缺点”、“模仿人的思考,只关注有用的信息”之类的解释,但我认为这样的解释就是没有解释。只是在实验过程中,通过这种操作使得实验结果变得很好,为了方便称呼这种操作,联想到了“注意力”这个词,于是才有了“注意力机制”这个说法。
transformer到底是在干什么,了解它的设计思想,存在哪些缺陷,才是对水文章有帮助的地方。
讲解细节和代码的博客已经有很多了,我们重点整理一下模型设计思路,为什么时至今日还能出这么多成果,就算肉被吃完了,我们是否还能喝到一口汤。
目录
- 1. Transformer
- 2. Informer
- 3. Autoformer
- 4. FEDformer
- 4. Scaleformer
- 5. iTransformer
- 总结
1. Transformer
第一个问题:为什么对模型命名为transformer(变形金刚)
带着问题和答案来阅读,能更好理解其设计思想。
汽车人在变形的过程中,会先把身体分解成一系列基本的元素,然后重构成人形,整个过程简单来说就是“分解->重组”。Transformer本质还是“编码->解码”模型,那显然“编码”就是对应“分解”,“解码”就是对应“重组”。
以这种视角切入,就能很快明白模型想干什么。
现在就可以正式切入我们的论文了,发表在31st Conference on Neural Information Processing Systems (NIPS 2017),Long Beach,CA,USA. 也是老顶会了。

第二个问题:为什么论文名字要突出“Attention”
最前面我写到,实验中的某个操作效果很好,为了方便称呼,所以取名Attention。
transformer本质是在做编解码,但是论文的重点却在Attention,那就只有一种可能了:编解码中都用了某一种操作(技术),能够使得效果变好。
也就是说Attention是分解和重组的关键步骤,是整篇论文最创新的地方。(分解重组、编解码大部分人都能想到,如果是你,你会怎么创新)
第三个问题:为什么叫"Attention"
这个问题等读完整篇文章就很显然了。但我想说,既然实验中的这个操作能联想到“注意力”,那同样也能从“注意力”推出这个操作在干什么。
人在进行某个活动时,通过会把注意力放在这个活动上,会忽略掉其他东西。在代码中,处理的东西是一个张量,也就是一堆数值,怎么把注意力放在某个重要地方?很显然,乘以一个系数就行,重要的部分乘以放大因子,不重要的乘以缩小因子。
关键是哪些地方放大,哪些地方缩小,放大和缩小的程度是多少?
那么模型设计的思路基本就呼之欲出了。作者在实验过程中,设计了一种操作,能够在编码器和解码器中设计了一种操作,能够使得矩阵中自适应的放大和缩小某些地方的数值;区别在于编码器更侧重分解,解码器更注重重组。
这个时候来看整个模型,很快就能get到作者的意图
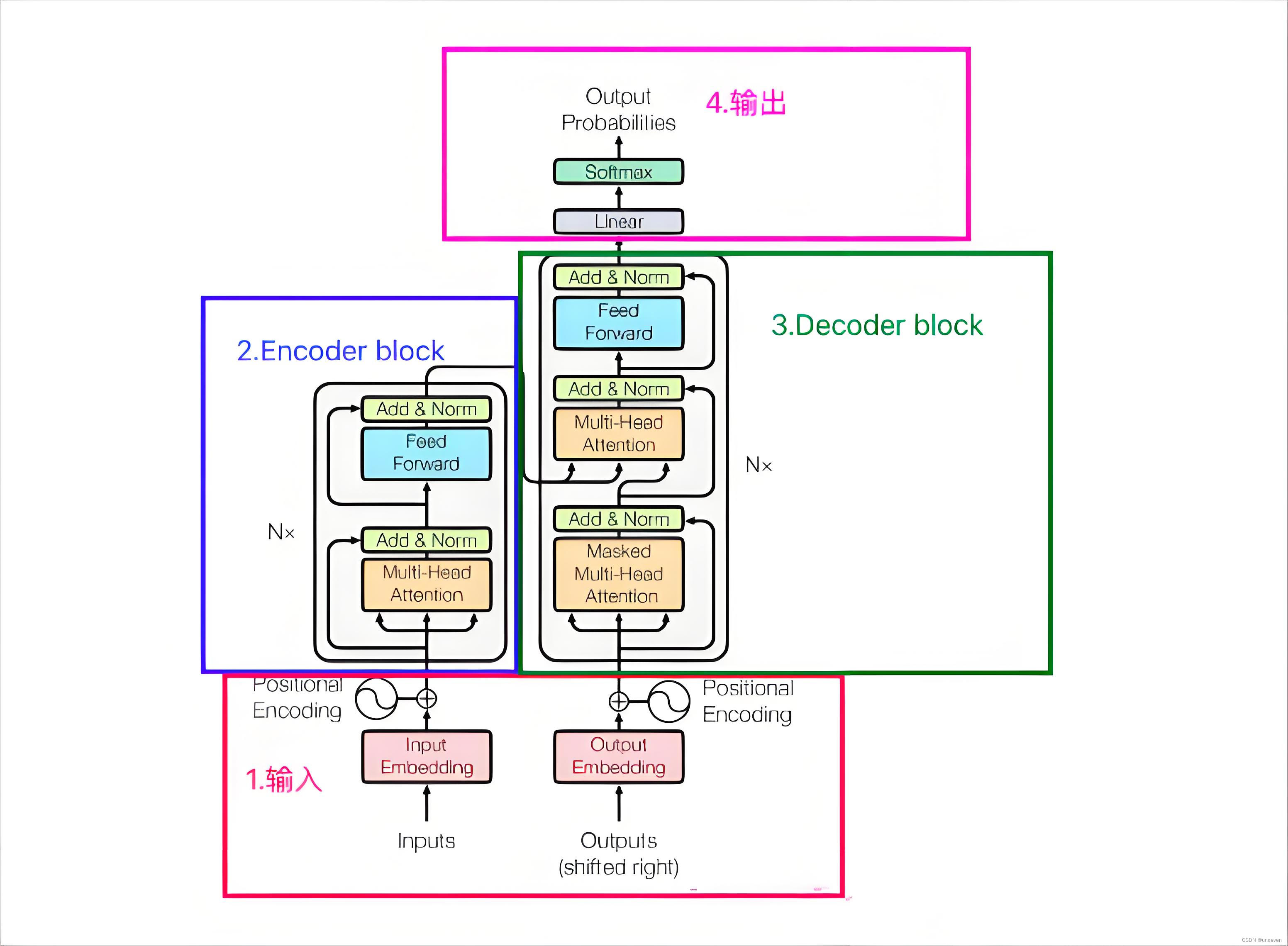
讲解模型的博客有很多,但是为了理顺整个流程,我们还是继续把各个模块过一遍
1 输入
在前人的研究基础上,我们已经知道,在处理文本的过程中,每个单词的长度并不一致,输入格式的不一致将使模型运行不了,将单词映射到一个统一的维度就是一个很好的方法。
怎么映射也是一门学问,也出了很多成果,说的最多的就是“词向量”,把单词变成一个词向量,并且在这个映射的空间中,就算长的不像但是语义上很像的单词在这个空间中距离很近,这就很有意义。
Embedding就是在做这样的一件事,但position Encoding又在干什么呢?
在Transformer出来之前,LSTM一直是序列数据处理的老大(man~),最大的优势和劣势就在于LSTM是顺序处理的模型,一个一个记忆单元顺序处理使LSTM对位置极其敏感,“从北京到上海”和“从上海到北京”两句话的意思天差地别,LSTM就能明白这种区别,transformer很难。解决这个问题就用到了position Encoding,把序列中元素的位置进行编码作为协变量加入进去,就能弥补位置信息的缺失。
(“有机会的话,也可以聊聊xLSTM如何改进的”)
output这个地方也是同样的操作。output也是有说法的,一开始可能会疑惑,为了这个图里的输出和输入为什么都有output?因为transformer会把所有的输出都送到解码器,才会输出下一个单词,不断重复这个操作。但这会带来一些问题,一句话越变越长,这句话还得完整送到解码器,导致最后越来越慢,这就是所谓的transformer推理慢的原因。大部分的变体都是基于这点做的改进。
还有个问题,最开头这个词没有输出啊,output不就是空吗,以及什么时候结尾啊,因此在模型初始的时候输入< start >标记符标志开始,当模型输出< end >表示结束了。
2 编码器
注意力这个东西讲的博客很多,就不再赘述,下面这个图就是注意力的过程
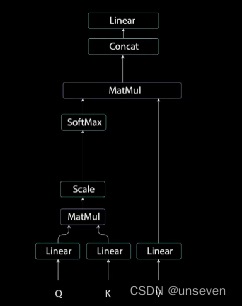
从transformer的原图可以看出来,编码器的Q,K,V都是同一个东西,序列编码之后送到了三个不同的Linear(线性层)因此对Q,K,V产生了变化,但是这样做的数学原理是什么?
其结果就是放大了部分数值和缩小了部分数值,整个过程一看就懂,不过注意力、计算相似度这类的说法听起来很难。
通过Q,K,V三个分支把输入分解了。
多头注意力和自注意力的区别在于,自注意力把真个输入都一次性算完了。事情交给一个人做,要是他出错了就完蛋了,不如把输入分成多个head,每个head交给不同的人做,然后把结果汇总,就算一个人出错了也不至于全部完蛋。
之后就是前馈网络、残差连接、归一化,这个操作基本都要用到,没什么好说的,作用就在于对信息进一步的过滤。
3 解码器
解码器的重点在重组。
首先对之前的输入先做了一个多头注意力(Q,K,V是同一个),但在第二个多头注意力的Q,K是编码器的结果,V是上一个多头注意力的结果,通过这种方式对输入信息和之前的输出信息进行了整合、重组。
值得注意的是,编解码器都一个“N x ” ,意思是叠加N层,这也提示了注意力不会改变原始输入的大小。叠加N层也体现了深度学习和浅层学习的区别,transformer是典型的深度学习技术。
4 输出
输出是一个Linear和softmax,Linear就是一个全连接层,把解码信息变为单词库的大小,有多少个单词那么维度就该设为多大,通过softmax转为每个单词的概率,把概率最大的单词作为输出。
总结
如果会全连接神经网络,那么学会transformer并不难,因为核心的操作还是Linear,但是读懂transformer还是很难,我当初也是死抠模型细节,搞不懂它在干什么。从模型设计的角度来理解transformer,就会发现transformer干的事情很明确很简单——把输入和输出通过注意力机制在编解码中实现分解和重组,这样的模型就叫transformer。在其他地方改动,但只要遵循了这样的设计规则,就是transformer的变体。
2. Informer

Informer :超越高效Transformer的长时间序列预测
发表在The Thirty-Fifth AAAI Conference on Artificial Intelligence (AAAI-21),也是老顶会了。
transformer很吊,这我们都知道,但是也存在致命的问题,推理的时候会越来越慢,内存开销越来越大,有没有什么方法解决?
Informer就提出了一系列创新点
- 提出了ProbSparse self-attention机制,时间复杂度为O(L∙logL),降低了常规 Self-Attention 计算复杂度和空间复杂度。
- 提出了self-attention蒸馏机制来缩短每一层的输入序列长度降低了 J 个堆叠层的内存使用量。
- 提出了生成式的decoder机制,在预测序列(也包括inference阶段)时一步得到结果,而不是step-by-step,直接将预测时间复杂度由O(N)降到了O(1)。
模型结构图,我们一点一点理解为什么要这样设计
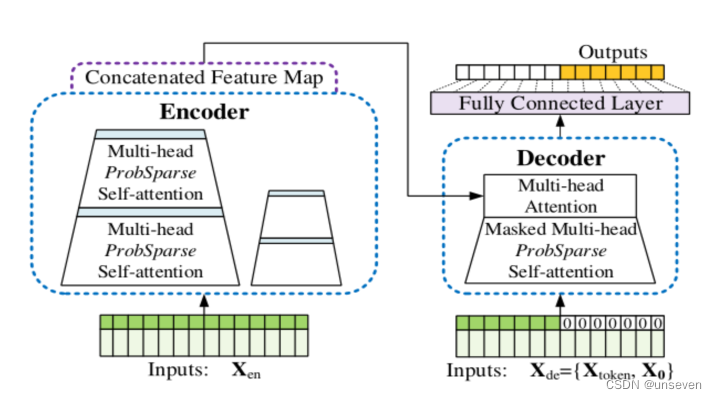
我们已经知道遵循什么样的设计原则可以称为transformer变体,Informer的结构图基本就是把transformer抄了一篇,是典型的transformer结构。
先来看输出
transformer:我推理慢都是因为需要一个一个输出结果,因为我需要上一个结果作为下一个数据输出的依据 (•ิ_•ิ)
Informer:那我就是想搞快点,不想管这么多怎么办 (︶︹︺) ,那我就把所有结果当成0先填进去,你先给我预测出来,准不准先不说,你就说快不快吧 (╯ ̄Д ̄)╯╘═╛
transformer:填0没有依据啊,这不是瞎搞吗?( ´◔ ‸◔`)
Informer:要依据是吧!我tm先把前几个时刻抄一遍,后面再填0行吧 (*  ̄︿ ̄)
transformer:… … …行,行吧( ・ˍ・)
这种一步生成结果的方式把复杂度由O(N)降到了O(1),
虽然有点抽象,但是后续所有变体基本都是这么做的,
准不准先不说,你就说快不快吧。
Informer:需要预测多少个时刻的数值,我就填多少个0 (。→‿←。)
transformer:但有个问题啊,输出是定长的,但是我不知道一句话最后有多长啊?ヽ(.◕ฺˇд ˇ◕ฺ;)ノ
Informer:谁跟你说我要预测本文啊,我做时序预测不行吗 (;¬_¬)
transformer:… … … (┙>∧<)┙へ┻┻
是的,后续的变体都是时序预测任务,
而不是自然语言处理,巧妙地避开了这个问题,
换应用场景也是典型的科研小妙招
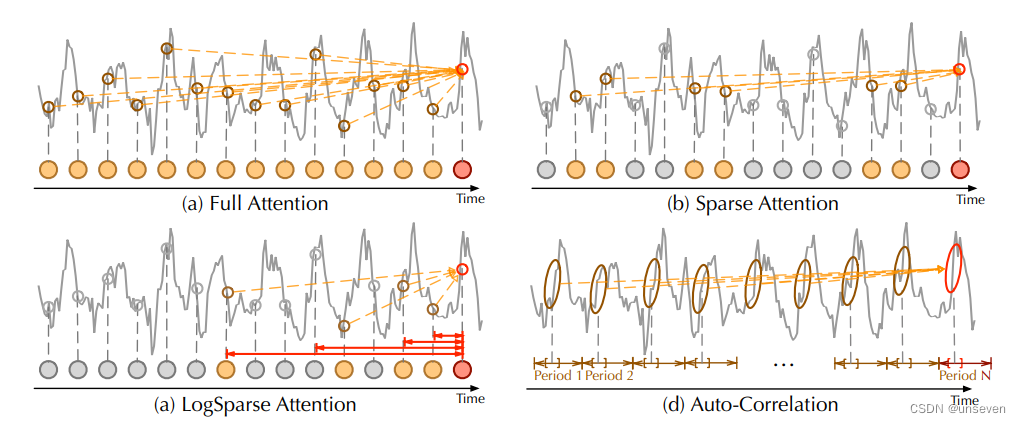
ProbAttention
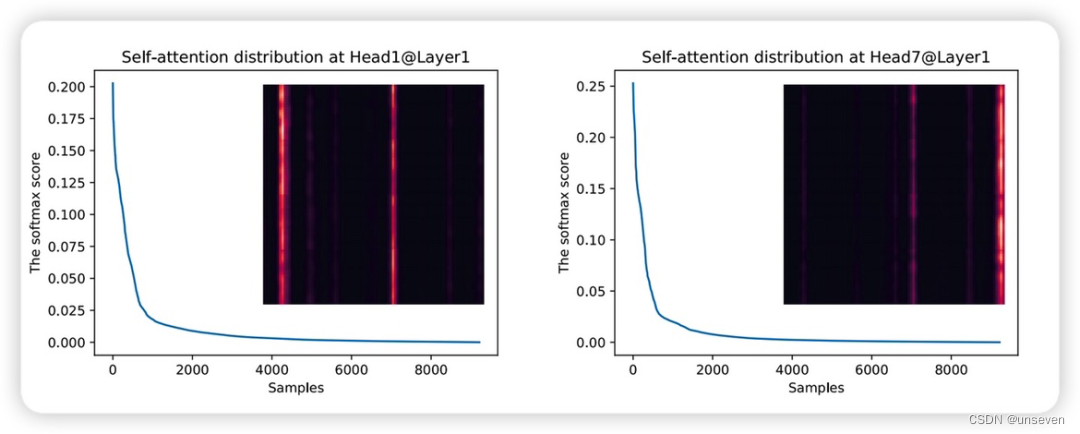
作者发现在原始的Transformer中的自注意力机制中,注意力分数呈现长尾分布,也就是只有少部分的点是和别的点直接有强相关性的,所以在Transformer中如果可以在计算Attention过程中删除那些没有用的query,就可以降低计算量
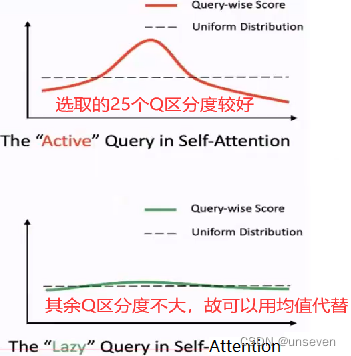
- 简化K:
对每个Q不再与所有K计算,而是随机选取25个K,这样减少计算量 - 简化Q:
每个Q与各自随机选取的25个K计算结果有25个值,选取最大值作为Q结果
对所有Q,选取最大的前25个Q ,因为这25个Q具有较好的区分度
25个Q之外的其余Q使用96个特征V的均值作为Q结果,因为这些Q区分度不大,可以看做均匀分布
self-attention Distilling 蒸馏
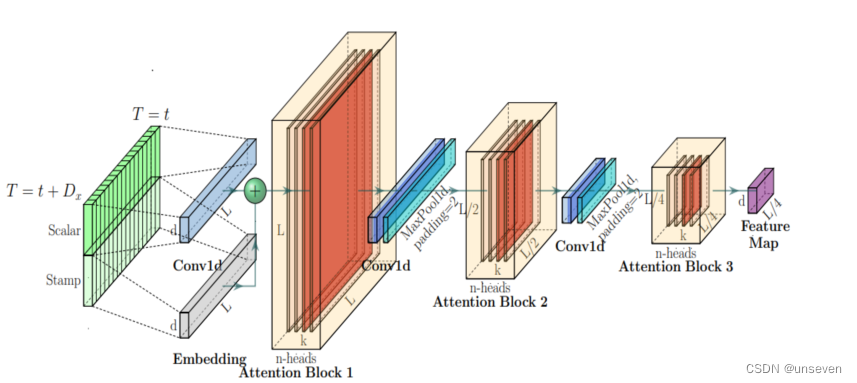
在每个attention block后加入Cov1d + Maxpooling操作来减少特征维度;Informer在encoder模块用到Self-attention Distilling抽取最重要的Attention信息并减少算法所需的内存和时间。
前面我们提到encoder有N层,每加一层开销就加大一步,这样不断去蒸馏的话,相比原先的模型,每加一层,参数反而进一步减少。
总结
一步式生成的做法减去了对上一个数据的依赖,理论上精度是更糟糕,但是在时序预测任务中,也防止了上一个时刻预测错误导致的误差累加。
Q,K直接通过类似抽样的方式只计算有用的部分,极大的简化了计算
蒸馏则直接通过下采样的方式,把信息减少一大半。
在我看来,这些改进都很容易想到,而且显然是牺牲精度换取时间,但最早吃到transformer蛋糕发了顶会。
3. Autoformer
Autoformer:用于长时序预测的分解Transformer模型,
发表在35th Conference on Neural Information Processing Systems (NeurIPS 2021),也是老顶会了。

Autoformer才是在时序预测上下了功夫的,在天气预报上一战成名,Informer像是缝合的。
Autoformer结构如下图所示。
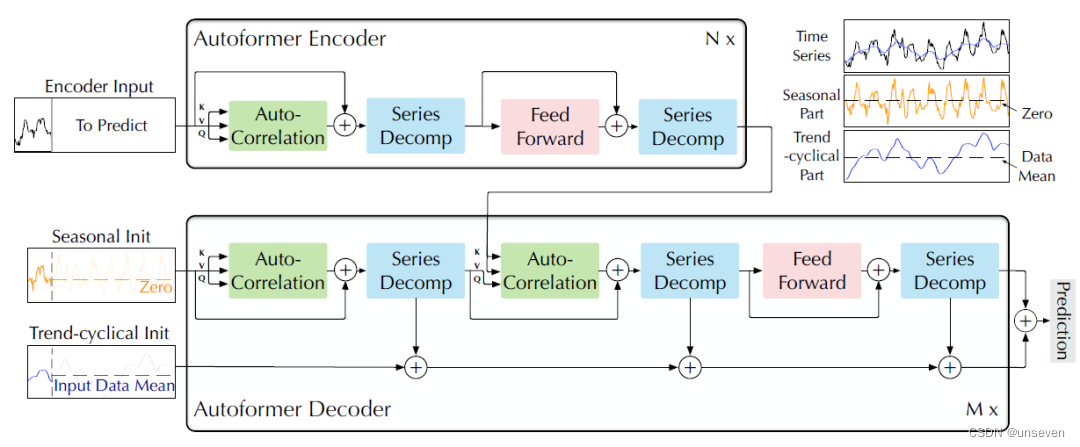
很明显Autoformer是典型的transformer结构,但它把时序预测任务和transformer做了结合(缝合)。
最突出的特征是:把以往时序任务成果的序列分解概念引入了transformer、和Informer一样的一步式生成结果、新的注意力机制。
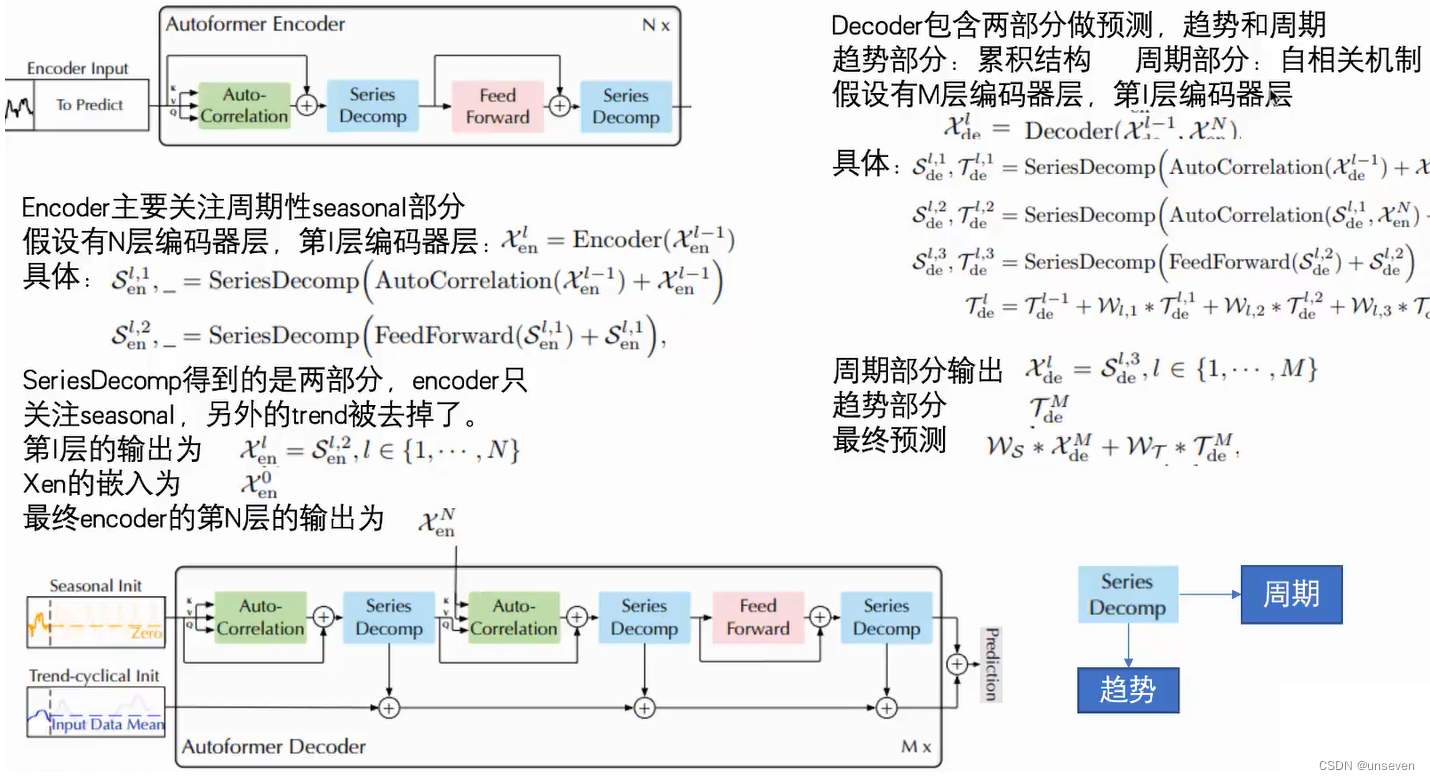
Decomposition Architecture(分解结构)
作者使用了平均池化以滑动窗口的方式提取了时间序列的整体趋势特征(记作趋势项),其中为保证提取特征前后维度大小不变而使用了首尾填充操作(padding)。接着将原先序列同趋势项做差得到两者差值(记作季节项)。至此原始时间序列便被分解为两个特征序列。
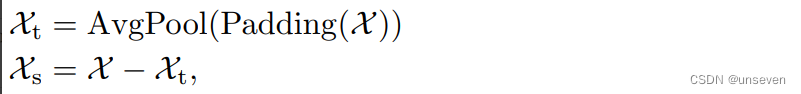
Auto-Correlation Mechanism(自相关机制)
通过计算序列的自相关来发现基于周期的依赖关系,并通过时延聚合来聚合相似的子序列。基于周期的依赖关系,作者发现周期之间相同的相位位置的子序列具有相关性。
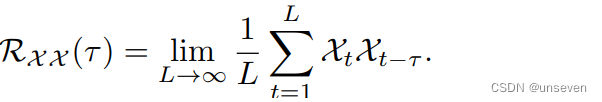
根据随机过程理论,两个序列的相关性可以通过上述公式获得。τ为原始序列平移长度,该公式旨在对多次序列平移前后的相关性进行计算并求其均值。

这个Roll操作可以讲一讲,中间分成的两段其实就是前后对调了一下,换回来就是原序列L,把掉到后面的序列再和前面相同大小的序列做自相关。
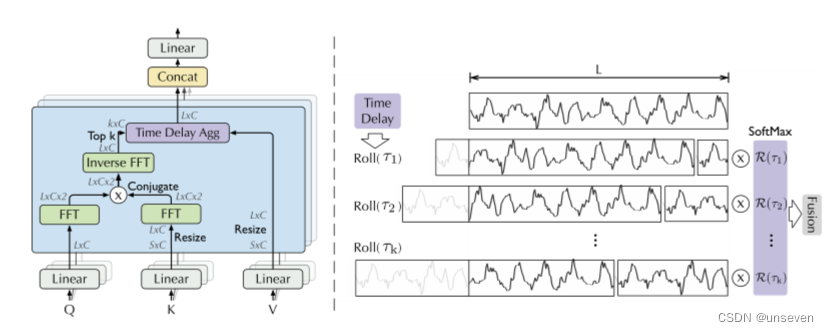
好处就是不再局限于参考之前哪几个时刻的点,而是参考一段时间的序列。
总结
Autoformer算是把transformer把时序任务做了适配,采用了一步式生成(和Informer同一年发表),提出了参考一段序列的注意力机制。
总的来说,并不是很难,这些创新也不是很难想到。适配太过简单,滑动平均池化就算作了趋势序列,原序列一减就得到了季节序列,怎么看都扯淡,因此后面基于这点有新的变体出现,但或许是作者故意留了口汤给后面的研究者。
4. FEDformer
FEDformer:用于长期序列预测的频率增强分解Transformer, Proceedings of the 39th International Conference on Machine Learning,Baltimore,Maryland,USA,PMLR 162,2022.Copy-right 2022 by the author(s).

FEDformer结构图如下,Autoformer留的这口汤显然就被FEDformer喝到了,不能说有点像,只能说一模一样
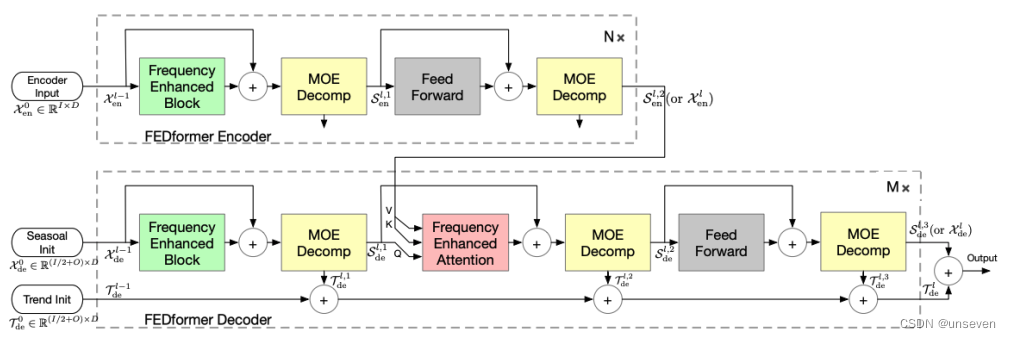
FEDformer 的主体架构采用编码-解码器架构。周期-趋势分解模块(MOE Decomp)将序列分解为周期项S和趋势项T。而且这种分解不只进行一次,而是采用反复分解的模式。
在编码器中,输入经过两个 MOE Decomp 层,每层会将信号分解为 seasonal 和 trend 两个分量。其中,trend 分量被舍弃,seasonal分量交给接下来的层进行学习,并最终传给解码器。
在解码器中,编码器的输入同样经过三个 MOE Decomp 层并分解为 seasonal 和 trend 分量。其中,seasonal 分量传递给接下来的层进行学习,其中通过 频域Attention(Frequency Enhanced Attention)层对编码器和解码器的 seasonal 项进行频域关联性学习,trend 分量则进行累加最终加回给 seasonal 项以还原原始序列。
FEB
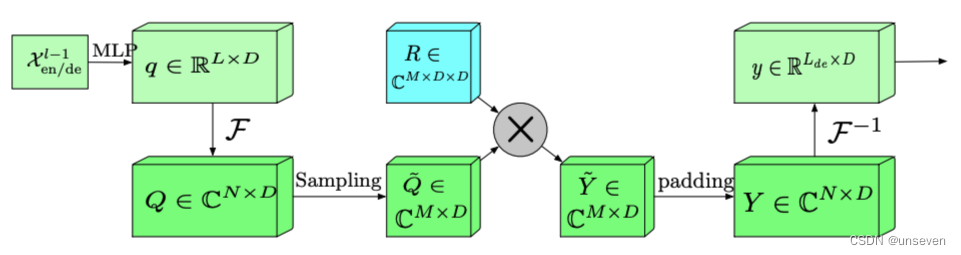
FEDformer 中两个最主要的结构单元的设计灵感正是来源于此。Frequency Enchanced Block(FEB)和 Frequency Enhanced Attention(FEA)具有相同的流程:频域投影 -> 采样 -> 学习 -> 频域补全 -> 投影回时域:
首先将原始时域上的输入序列投影到频域。
再在频域上进行随机采样。这样做的好处在于极大地降低了输入向量的长度进而降低了计算复杂度,然而这种采样对输入的信息一定是有损的。但实验证明,这种损失对最终的精度影响不大。因为一般信号在频域上相对时域更加「稀疏」。且在高频部分的大量信息是所谓「噪音」,这些「噪音」在时间序列预测问题上往往是可以舍弃的,因为「噪音」往往代表随机产生的部分因而无法预测。相比之下,在图像领域,高频部分的“噪音”可能代表的是图片细节反而不能忽略。
在学习阶段,FEB 采用一个全联接层 R 作为可学习的参数。
频域补全过程与第2步频域采样相对,为了使得信号能够还原回原始的长度,需要对第2步采样未被采到的频率点补零。
投影回时域,因为第4步的补全操作,投影回频域的信号和之前的输入信号维度完全一致。
FEA
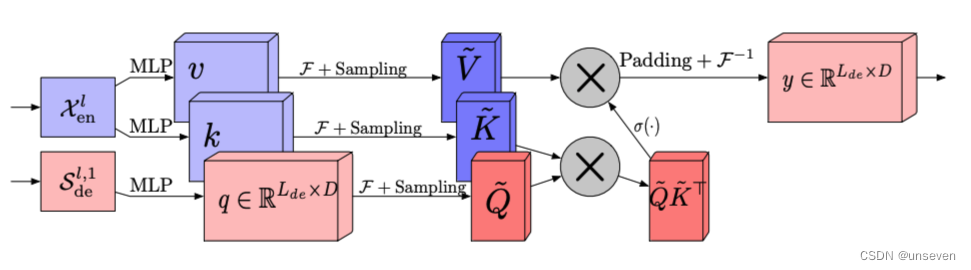
传统Transformer中采用的Attention机制是平方复杂度,而 Frequency Enhanced Attention(FEA)中采用的Attention是线性复杂度,这极大提高了计算效率。
因为 FEA 在频域上进行了采样操作,也就是说:「无论多长的信号输入,模型只需要在频域保留极少的点,就可以恢复大部分的信息」。采样后得到的小矩阵,是对原矩阵的低秩近似。
总结
FEDformer显然是认为Autoformer的序列分解太过简单,因此引入了傅里叶变换或者小波变换。但是频域信息冗余的问题也一并引入,采用了随机采样减少复杂度。
FEDformer钻了Autoformer空子,傅里叶变换本身就是序列分解用烂了手段,但是Autoformer没用,单凭这一点肯定发不出文章,但是傅里叶变换本身就有缺陷,因此还能根据这一点改进注意力机制,这种认为信息冗余需要抽样的做法显然是致敬了Informer。给我感觉是本来Autoformer能做,但我自己给自己制造点麻烦,然后自己解决,形成闭环。
4. Scaleformer
Scaleformer:用于时序预测的多尺度细化迭代Transformer,Published as a conference paper at ICLR 2023,也是老顶会了。

Scaleformer也是标准的transformer结构,结构如下
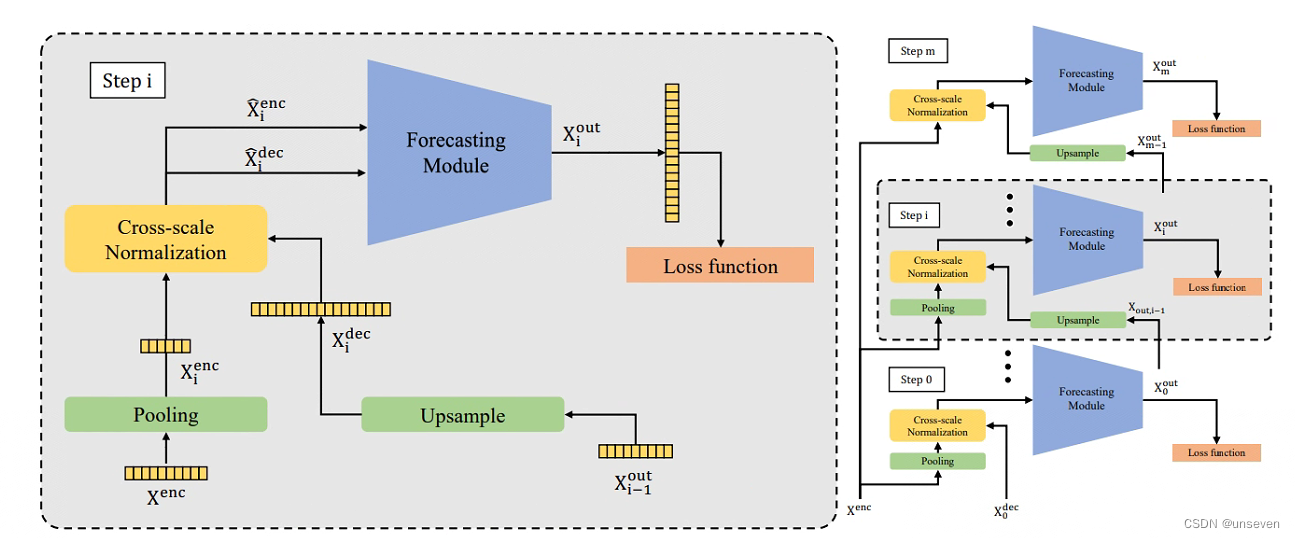
结构图给人最明显的特点就是,不再单独对编码器和解码器堆叠N层,而是对整个编解码对进行堆叠
这种堆叠方式其实很容易想到,想发顶刊还是差点东西,因此引入多尺度的概念,每一层的输入还得加点东西,层与层的pooling和Upsample大小不一致,提出的信息在尺度上自然就不同,将其称为多尺度信息
多尺度框架与跨尺度标准化如下:

当然我们不知道当初作者是如何想到这样的模型,但如果是我的话,我会先从堆叠方式入手,自然而然的想到多尺度作为不同的输入。Scaleformer在其他方面与transformer并无区别。
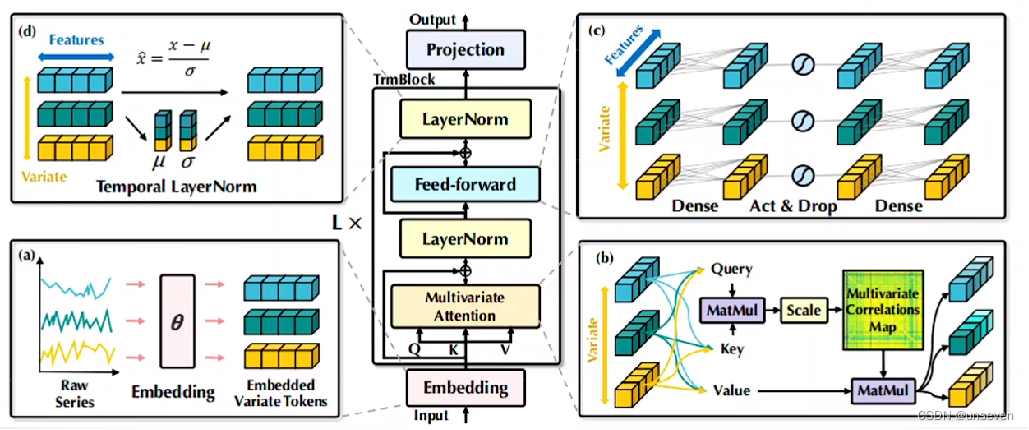
5. iTransformer
ITransformer:使用Transformer模型进行长期预测,发表在Published as a conference paper at ICLR 2023,也是老顶刊了

iTransformer更是典型的不能再典型的Transformer模型了,因为山模型上和Transformer没有一点区别。
Transformer的变体出了太多了,东抄一点,西抄一点,于是清华大学出手了,直接就是用的原原本本的Transformer,把这些变体全超过了。直接就是认为你们都不会玩Transformer,Transformer的效果比不过类似DLinear这样线性模型,是因为你们没用对
我们数据集的每条样本都是,在某个时刻的样本,由单个或多个特征组成,样本按行编码为token

实际上应该把每个特征的所有数据进行编码,样本按列编码为token

时刻也作为特征,按列编码进去
iTransformer应该这么玩:
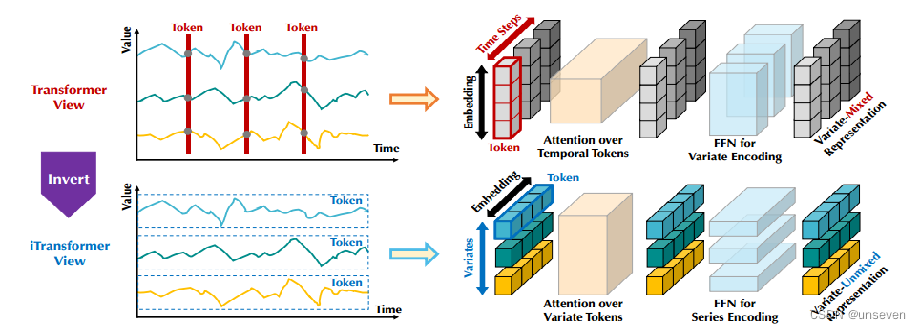
其余部分就是一个标准的Transformer
总结
这样的改进怎么说呢,也是万万没想到,我也不会玩Transformer。实验结果也证明这样的编码方式用在其他变体上都能使效果提升。
之后新的时序预测模型,S/D-mamba,SOFTS这些都是统一按照iTransformer的格式编码,模型改进进入下一个阶段。
总结
Transformer算是开启了一篇新的领域,在实验上没有过多介绍,从模型设计和创新点上来看Transformer,很快就能理解Transformer和这些变体想干什么。
Transformer从分解和重组出发,设计了一种机制并加将其加入了编解码器,得到了很好的效果。
Informer为了解决Transformer推理慢的问题,对Q、K进行了抽样,引入了蒸馏机制、一步式生成Decoder,应用在时序任务。
Autoformer为了解决Informer精度问题,引入了时序分解、序列到序列的注意力。
FEDformer完善了Autoformer序列分解机制,引入了傅里叶变换,并对频域信息进行抽样。
Scaleformer引入了多尺度信息,采用了新的模块堆叠方法。
iTransformer采用转置的编码方式,超越了先前的变体。