本文学习参考:datawhalechina/llm-universe: 本项目是一个面向小白开发者的大模型应用开发教程,在线阅读地址:https://datawhalechina.github.io/llm-universe/
一些可使用的大模型地址:
Claude 使用地址
PaLM 官方地址
Gemini 使用地址
文心一言使用地址
星火大模型使用地址
开源大模型:
1:Llama
LLaMA 开源地址:
LLaMA 系列模型是 Meta 开源的一组参数规模 从 7B 到 70B 的基础语言模型。LLaMA 于2023 年 2 月发布,2023 年 7 月发布了 LLaMA2 模型,并于 2024 年 4 月 18 日发布了 LLaMA3 模型。
2:Qwen
通义千问开源地址:
通义千问由阿里巴巴基于“通义”大模型研发,于 2023 年 4 月正式发布。2023 年 9 月,阿里云开源了 Qwen(通义千问)系列工作。2024 年 2 月 5 日,开源了 Qwen1.5(Qwen2 的测试版)。并于 2024 年 6 月 6 日正式开源了 Qwen2。 Qwen2 是一个 decoder-Only 的模型,采用 SwiGLU 激活、RoPE、GQA的架构。中文能力相对来说非常不错的开源模型。
目前,已经开源了 5 种模型大小:0.5B、1.5B、7B、72B 的 Dense 模型和 57B (A14B)的 MoE 模型;所有模型均支持长度为 32768 token 的上下文。并将 Qwen2-7B-Instruct 和 Qwen2-72B-Instruct 的上下文长度扩展至 128K token。
3:ChatGLM
ChatGLM 开源地址:
GLM 系列模型是清华大学和智谱 AI 等合作研发的语言大模型。2023 年 3 月 发布了 ChatGLM。6 月发布了 ChatGLM 2。10 月推出了 ChatGLM3。2024 年 1 月 16 日 发布了 GLM4,并于 2024 年 6 月 6 日正式开源。
GLM-4-9B-Chat 支持多轮对话的同时,还具备网页浏览、代码执行、自定义工具调用(Function Call)和长文本推理(支持最大 128K 上下文)等功能。
开源了对话模型 GLM-4-9B-Chat、基础模型 GLM-4-9B、长文本对话模型 GLM-4-9B-Chat-1M(支持 1M 上下文长度)、多模态模型GLM-4V-9B 等全面对标 OpenAI
4:Baichuan
百川开源地址:
Baichuan 是由百川智能开发的开源可商用的语言大模型。其基于Transformer 解码器架构(decoder-only)。
2023 年 6 月 15 日发布了 Baichuan-7B 和 Baichuan-13B。百川同时开源了预训练和对齐模型,预训练模型是面向开发者的“基座”,而对齐模型则面向广大需要对话功能的普通用户。
Baichuan2 于 2023年 9 月 6 日推出。发布了 7B、13B 的 Base 和 Chat 版本,并提供了 Chat 版本的 4bits 量化。
2024 年 1 月 29 日 发布了 Baichuan 3。但是目前还没有开源。
RAG:检索增强生成(Retrieval-Augmented Generation)
RAG 是一个完整的系统,其工作流程可以简单地分为数据处理、检索、增强和生成四个阶段:

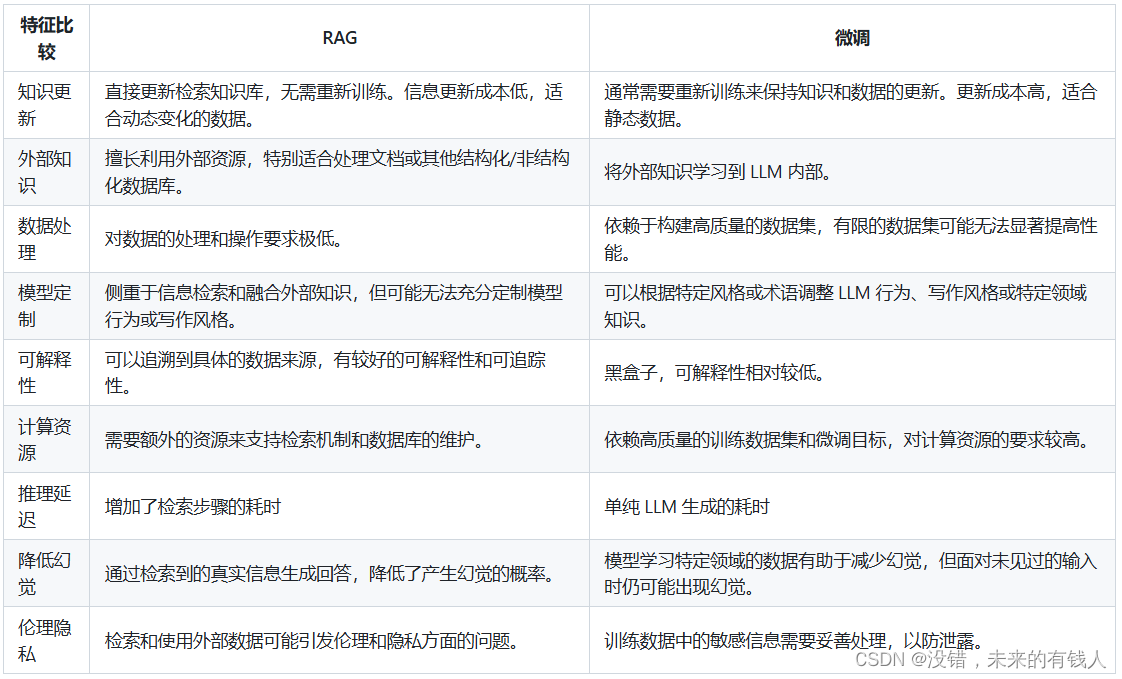
1:微调和RAG的对比:
提到rag肯定会提到langchian:
2:LangChain 主要由以下 6 个核心组件组成:
- 模型输入/输出(Model I/O):与语言模型交互的接口
- 数据连接(Data connection):与特定应用程序的数据进行交互的接口
- 链(Chains):将组件组合实现端到端应用。比如后续我们会将搭建
检索问答链来完成检索问答。 - 记忆(Memory):用于链的多次运行之间持久化应用程序状态;
- 代理(Agents):扩展模型的推理能力。用于复杂的应用的调用序列;
- 回调(Callbacks):扩展模型的推理能力。用于复杂的应用的调用序列;
langchain的结构:Langchain-rag小demo-CSDN博客
3:langchain的生态:

大模型开发:

实践:
1:首先建立一个虚拟环境然后拷贝项目
- 新建虚拟环境
conda create -n llm-universe python=3.10 - 激活虚拟环境
conda activate llm-universe - 在希望存储项目的路径下克隆当前仓库
git clone git@github.com:datawhalechina/llm-universe.git(下载的时候可能出现需要匹配秘钥:解决git@github.com: Permission denied (publickey). fatal: Could not read from remote repository. Pleas-CSDN博客,如果还是不行就用这个:git clone https://github.com/datawhalechina/llm-universe.git)
2:配置环境
在llm-universe下进行环境配置
pip install -r requirements.txt如果下载得很慢的话:
这里列出了常用的国内镜像源,镜像源不太稳定时,大家可以按需切换: 清华:Simple Index 阿里云:Simple Index 中国科技大学:Simple Index 华中科技大学:http://pypi.hustunique.com/simple/ 上海交通大学:https://mirror.sjtu.edu.cn/pypi/web/simple/ 豆瓣:http://pypi.douban.com/simple
Prompt:
具体来说,在使用 ChatGPT API 时,你可以设置两种 Prompt:一种是 System Prompt,该种 Prompt 内容会在整个会话过程中持久地影响模型的回复,且相比于普通 Prompt 具有更高的重要性;另一种是 User Prompt,这更偏向于我们平时提到的 Prompt,即需要模型做出回复的输入。
我们一般设置 System Prompt 来对模型进行一些初始化设定,例如,我们可以在 System Prompt 中给模型设定我们希望它具备的人设如一个个人知识库助手等。System Prompt 一般在一个会话中仅有一个。在通过 System Prompt 设定好模型的人设或是初始设置后,我们可以通过 User Prompt 给出模型需要遵循的指令。例如,当我们需要一个幽默风趣的个人知识库助手,并向这个助手提问我今天有什么事时,可以构造如下的 Prompt:
{
"system prompt": "你是一个幽默风趣的个人知识库助手,可以根据给定的知识库内容回答用户的提问,注意,你的回答风格应是幽默风趣的",
"user prompt": "我今天有什么事务?"
}通过如上 Prompt 的构造,我们可以让模型以幽默风趣的风格回答用户提出的问题。
使用 LLM API:
llm-universe/docs/C2/2. 使用 LLM API.md at main · datawhalechina/llm-universe (github.com)

例子:
文心一言----千帆 SDK
通过文心千帆平台调用文心一言 API,要去百度智能云获取AK和SK
1:创建.env文件
2:将密钥加载到环境变量中
import os
from dotenv import load_dotenv, find_dotenv
# 寻找并定位 .env 文件的路径
dotenv_path = find_dotenv()
if dotenv_path:
print(f"Found .env file at {dotenv_path}")
else:
print("No .env file found")
# 读取该 .env 文件,并将其中的环境变量加载到当前的运行环境中
load_dotenv(dotenv_path)
# 检查环境变量是否已经被加载
qianfan_ak = os.getenv('QIANFAN_AK')
qianfan_sk = os.getenv('QIANFAN_SK')
if qianfan_ak and qianfan_sk:
print(f"QIANFAN_AK: {qianfan_ak}")
print(f"QIANFAN_SK: {qianfan_sk}")
print("Environment variables loaded successfully.")
else:
print("Environment variables not found in the environment.")3:使用sdk封装一下,然后进行使用
import qianfan
def gen_wenxin_messages(prompt):
'''
构造文心模型请求参数 messages
请求参数:
prompt: 对应的用户提示词
'''
messages = [{"role": "user", "content": prompt}]
return messages
def get_completion(prompt, model="ERNIE-Bot", temperature=0.01):
'''
获取文心模型调用结果
请求参数:
prompt: 对应的提示词
model: 调用的模型,默认为 ERNIE-Bot,也可以按需选择 ERNIE-Bot-4 等其他模型
temperature: 模型输出的温度系数,控制输出的随机程度,取值范围是 0~1.0,且不能设置为 0。温度系数越低,输出内容越一致。
'''
chat_comp = qianfan.ChatCompletion()
message = gen_wenxin_messages(prompt)
resp = chat_comp.do(messages=message,
model=model,
temperature = temperature,
system="你是一名个人助理-小鲸鱼")
return resp["result"]
result = get_completion("你好,介绍一下你自己", model="Yi-34B-Chat")
print(result)备注:想要使用其他大模型的api可以参考:llm-universe/docs/C2/2. 使用 LLM API.md at main · datawhalechina/llm-universe (github.com)