目录
Metalearners for Discrete Treatments
T-Learner
简单回顾一下,在之前的部分中,你们的重点是干预效果的异质性,也就是确定各单位对治疗的不同反应。在此框架下,您希望估算
或连续情况下的 。换句话说,您想知道单位对干预的敏感程度。在无法干预所有人,需要对干预进行优先排序的情况下,这一点超级有用;例如,当您想给予折扣但预算有限时。或者当某些单位的干预效果为正,而其他单位的干预效果为负时。
在此之前,您已经了解了如何使用带有交互项的回归来获得条件平均干预效果 (CATE) 估计值。现在,是时候加入一些机器学习算法了。
Metalearners 是一种利用现成的预测性机器学习算法来近似干预效果的简便方法。它们可以用来估计 ATE,但一般来说,它们主要用于 CATE 估计,因为它们可以很好地处理高维数据。Metalearners 用于回收预测模型,以进行因果推断。所有预测模型,如线性回归、提升决策树、神经网络或高斯过程,都可以利用本章介绍的方法重新用于因果推理。因此,metalearner 的成功与否在很大程度上取决于它所使用的机器学习技术。很多时候,你只需尝试多种不同的方法,看看哪种最有效。
Metalearners for Discrete Treatments
假设你在一家在线零售商的营销团队工作。你的目标是找出哪些客户能够接受营销电子邮件。你知道这封电子邮件有可能让顾客花更多的钱,但你也知道有些顾客并不喜欢收到营销电子邮件。为了解决这个问题,您打算估算电子邮件对客户未来购买量的条件平均干预效果。这样,您的团队就可以利用这个估计值来决定向谁发送电子邮件。
与大多数商业应用一样,您拥有大量向客户发送营销电子邮件的历史数据。您可以利用这些丰富的数据来匹配您的 CATE 模型。此外,您还有一些来自随机发送营销电子邮件实验的数据点。您计划将这些宝贵的数据仅用于评估您的模型,因为您拥有的数据太少了:
import pandas as pd
import numpy as np
data_biased = pd.read_csv("./data/email_obs_data.csv")
data_rnd = pd.read_csv("./data/email_rnd_data.csv")
print(len(data_biased), len(data_rnd))
data_rnd.head()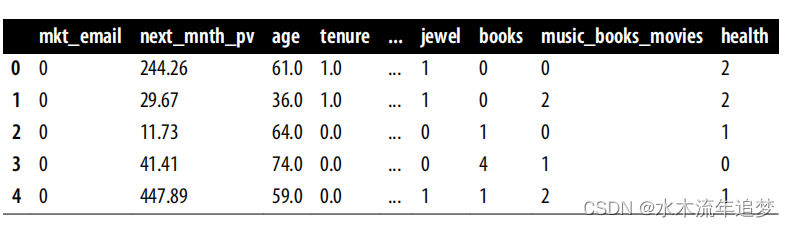
随机数据和观察数据都有完全相同的列。干预变量是 mkt_email,您关心的干预结果是收到电子邮件一个月后的购买量-next_mnth_pv。除了这些列之外,数据还包含一系列协变量,如客户的年龄、在您的网站上首次购买的时间(任期),以及他们在每个类别中的购买量数据。这些协变量将决定您计划拟合的干预异质性。
为了简化 CATE 模型的开发,您可以创建变量来存储处理、干预和协变量,以及训练集和测试集。
一旦掌握了所有这些,建造几乎所有的元学习器都将变得简单易行:
y = "next_mnth_pv"
T = "mkt_email"
X = list(data_rnd.drop(columns=[y, T]).columns)
train, test = data_biased, data_rnd一旦掌握了所有这些,建造几乎所有的元学习器都将变得简单易行:
T-Learner
如果您要进行分类干预,首先应该尝试的学习器是 T 学习器。它非常直观,我猜你已经想到了。 它为每个干预拟合一个结果模型 ,以估计潜在结果
。在二元情况下,您只需要估计两个模型(因此称为 T):学习器在T = 1上训练ML模型,在T = 0上训练ML模型;在预测时间,它使用这两种模型来估计治疗和控制之间的差异
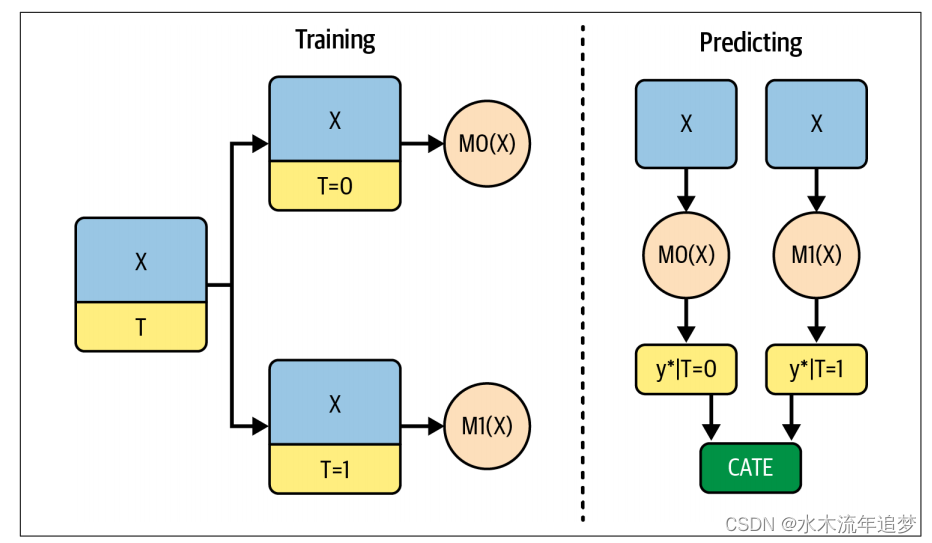 为了编写代码,我将使用提升回归树来建立结果模型。具体来说,我将使用 LGBMRegressor,这是一种非常流行的回归模型。我也会使用默认参数,但如果你愿意,也可以随意优化:
为了编写代码,我将使用提升回归树来建立结果模型。具体来说,我将使用 LGBMRegressor,这是一种非常流行的回归模型。我也会使用默认参数,但如果你愿意,也可以随意优化:
from lightgbm import LGBMRegressor
np.random.seed(123)
m0 = LGBMRegressor()
m1 = LGBMRegressor()
m0.fit(train.query(f"{T}==0")[X], train.query(f"{T}==0")[y])
m1.fit(train.query(f"{T}==1")[X], train.query(f"{T}==1")[y]);现在我有了这两个模型,对测试集进行 CATE 预测就非常容易了:
t_learner_cate_test = test.assign(
cate=m1.predict(test[X]) - m0.predict(test[X])
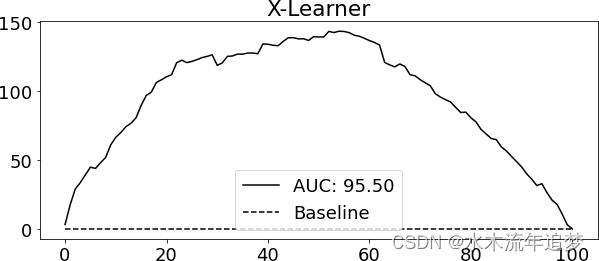
)为了评估这个模型,我使用了相对累积增益曲线和该曲线下的面积。
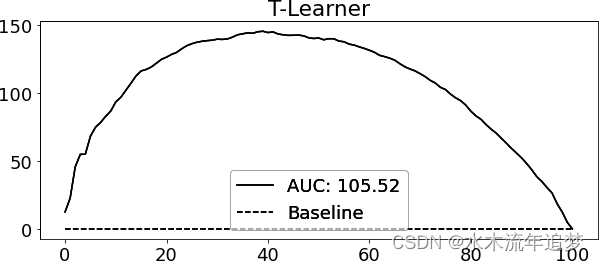
T-learner 在这个数据集中运行良好。从弯曲的累积增益曲线上可以看出,它可以很好地按 CATE 对客户进行排序。
一般来说,T-学习器往往是合理的首选,这主要是因为它简单易用。但它有一个潜在的问题,可能会根据具体情况表现出来:它容易产生正则化偏差。
考虑这样一种情况:未处理的数据很多,而处理的数据很少。这种情况在很多应用中都很常见,因为干预的成本很高。现在假设干预结果 Y 具有一定的非线性,但治疗效果是恒定的。 下图中的第一幅图描述了这种情况: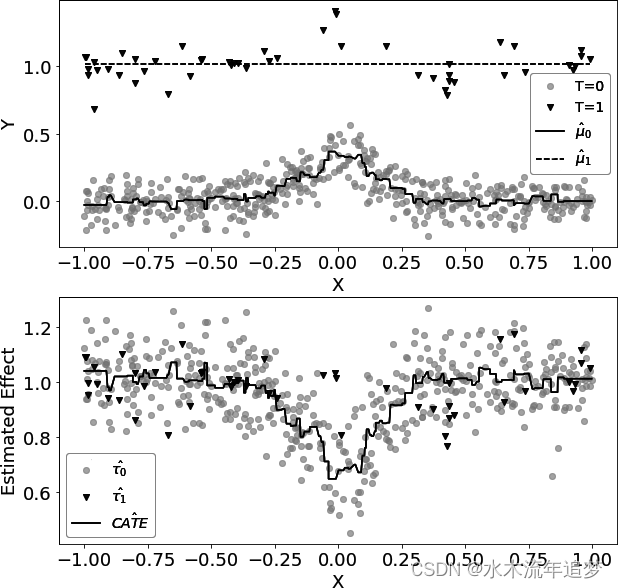 如果数据看起来像这样,与未处理的数据相比,处理过的观测数据非常少,那么 μ1 模型很有可能最终会变得简单,以避免过度拟合。相比之下,μ0 会更加复杂,但没关系,因为大量的数据可以防止过度拟合。重要的是,即使两个模型使用相同的超参数,也会出现这种情况。例如,为了生成前面的数据,我使用了 LGBM 回归模型,其 min_child_samples=25 且其他参数设置为默认值。 在处理较少的数据点时,很多 ML 算法都会自我规范化,min_child_samples 就是这种情况。它强制 LGBM 中的树在每个叶节点中至少有 25 个样本。
如果数据看起来像这样,与未处理的数据相比,处理过的观测数据非常少,那么 μ1 模型很有可能最终会变得简单,以避免过度拟合。相比之下,μ0 会更加复杂,但没关系,因为大量的数据可以防止过度拟合。重要的是,即使两个模型使用相同的超参数,也会出现这种情况。例如,为了生成前面的数据,我使用了 LGBM 回归模型,其 min_child_samples=25 且其他参数设置为默认值。 在处理较少的数据点时,很多 ML 算法都会自我规范化,min_child_samples 就是这种情况。它强制 LGBM 中的树在每个叶节点中至少有 25 个样本。
从机器学习的角度来看,自规范化非常有意义。如果数据很少,就应该使用更简单的模型。以至于上图中的两个模型都具有相当不错的预测性能,因为它们都针对各自的样本量进行了优化。但是,如果使用这些模型来计算 CATE ,
的非线性减去
的线性将导致非线性 CATE(虚线减去实线),这是错误的,因为在这种情况下,CATE 是恒定的,等于 1。您可以在上图的第二幅图中看到这种情况。
这里发生的情况是,未治疗者的模型可以捕捉到非线性,但治疗者的模型却捕捉不到,因为它是为了处理小样本量而正则化的。当然,你也可以减少对该模型的正则化处理,但这样会有过拟合的风险。在这里,您似乎陷入了进退两难的境地。如何解决这个问题呢?这就是 X-learner 的用武之地。