【显卡】服务器炼丹代码配置
- 写在最前面
- 一、查看哪几块显卡能用
- 二、使用指定gpu运行代码
- 1、指定使用GPU0运行脚本(默认是第一张显卡, 0代表第一张显卡的id,其他的以此类推)
- 2、指定使用多张显卡运行脚本
- 三、如何使用
- 1、单块显卡使用
- 2、多GPU训练
- 使用`DataParallel`
- 使用`DistributedDataParallel`
- 两种方法的对比
- 注意事项
- 选择合适的方法
- 参考资料
- 四、小结
- 关键点小结
- 配置多GPU并行和数据加载器
- 1. 设置`CUDA_VISIBLE_DEVICES`
- 2. 配置PyTorch设备和模型
- 3. 优化数据加载器
- 整合后的代码示例

写在最前面
深度学习(Deep Learning)已经成为众多领域中的重要技术,尤其在图像识别、自然语言处理、语音识别等方面表现出色。然而,深度学习模型的训练通常需要大量的计算资源,因此高性能计算(HPC)和GPU(图形处理单元)显卡变得至关重要。
在大型机构分配的服务器集群中,需要使用GPU的程序默认都会在第一张卡上进行,如果第一张卡倍别人占用或者显存不够的情况下,程序就会报错说没有显存容量,所以能够合理地利用GPU资源能帮助你更快更好地跑出实验效果。
本篇博客将介绍在服务器上进行深度学习炼丹(即训练模型)时如何配置代码,以及如何在Python中指定特定的GPU显卡来运行代码。
参考:https://cloud.tencent.com/developer/article/2352733
一、查看哪几块显卡能用
在进行深度学习任务之前,需要配置服务器环境。
登陆服务器,查看gpu是否可用,并确定CUDA版本
用ssh命令登录服务器(账号密码略),输入命令:nvidia-smi,查看gpu是否可用。
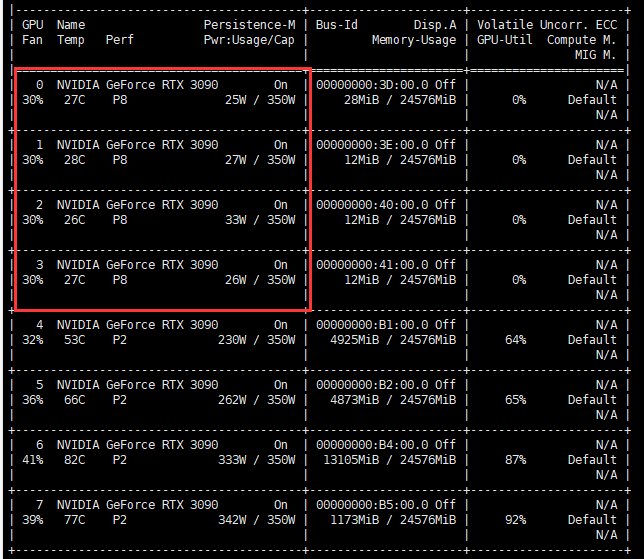
在我的这个案例中,可用显卡为:
- 可用显卡: GPU 0, GPU 1, GPU 2, GPU 3
- 部分使用中的显卡: GPU 4, GPU 5
- 高负载使用中的显卡: GPU 6, GPU 7
GPU 0 到 GPU 3 目前几乎未被使用,温度和内存利用率都很低,适合用于新任务。GPU 4 和 GPU 5 在中等负载下,但仍有一定余量。GPU 6 和 GPU 7 负载较高,建议避免使用或等负载减小后再使用。
二、使用指定gpu运行代码
1、指定使用GPU0运行脚本(默认是第一张显卡, 0代表第一张显卡的id,其他的以此类推)
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
2、指定使用多张显卡运行脚本
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0,2,3"
# 注意:这两行代码必须在文件的最开头,在加载各种包之前
三、如何使用
1、单块显卡使用
在python文件中,定义需要加速的模型之后,加上:
model = ......
model.train(True) or model.train(False) # 看你是要训练还是测试
model.to('cuda') # 或者model.cuda()
# 后面需要输入model的变量也是需要.to('cuda')或者.cuda()的,不然会报错既用了cpu又用gpu,不兼容
2、多GPU训练
假如:为了让你的PyTorch代码在多块显卡(0,1,2,3)上运行,你可以使用torch.nn.DataParallel或者torch.nn.parallel.DistributedDataParallel来进行多GPU训练。
使用DataParallel
DataParallel 是一个相对简单的方法,它可以在多块GPU上进行数据并行处理。下面是如何使用DataParallel的方法:
import torch
import torch.nn as nn
import torch.optim as optim
# 假设你有一个简单的模型
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc = nn.Linear(100, 10)
def forward(self, x):
return self.fc(x)
# 创建模型
model = SimpleModel()
# 将模型转换为DataParallel,并指定使用的显卡
model = nn.DataParallel(model, device_ids=[0, 1, 2, 3])
# 将模型移至GPU
model = model.cuda()
# 创建一个优化器
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 创建数据
inputs = torch.randn(64, 100).cuda()
labels = torch.randn(64, 10).cuda()
# 训练步骤
outputs = model(inputs)
loss = nn.MSELoss()(outputs, labels)
loss.backward()
optimizer.step()
使用DistributedDataParallel
DistributedDataParallel 是一种更高级的方法,通常在大规模分布式训练中使用,但在单机多卡上也可以提升性能。下面是如何使用DistributedDataParallel的方法:
-
启动代码:
在使用DistributedDataParallel时,你需要使用多进程方式启动程序。可以通过torch.multiprocessing或命令行启动。 -
代码修改:
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
import torch.nn as nn
import torch.optim as optim
from torch.nn.parallel import DistributedDataParallel as DDP
# 简单模型定义
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc = nn.Linear(100, 10)
def forward(self, x):
return self.fc(x)
def setup(rank, world_size):
# 初始化进程组
dist.init_process_group("nccl", rank=rank, world_size=world_size)
torch.cuda.set_device(rank)
def cleanup():
dist.destroy_process_group()
def train(rank, world_size):
setup(rank, world_size)
# 模型
model = SimpleModel().to(rank)
ddp_model = DDP(model, device_ids=[rank])
optimizer = optim.SGD(ddp_model.parameters(), lr=0.01)
inputs = torch.randn(64, 100).to(rank)
labels = torch.randn(64, 10).to(rank)
outputs = ddp_model(inputs)
loss = nn.MSELoss()(outputs, labels)
loss.backward()
optimizer.step()
cleanup()
if __name__ == "__main__":
world_size = 4
mp.spawn(train,
args=(world_size,),
nprocs=world_size,
join=True)
两种方法的对比
DataParallel:简单易用,适用于轻量级并行处理,但扩展性较差,在大规模分布式训练中性能不如DistributedDataParallel。DistributedDataParallel:适用于大规模训练,可以获得更好的性能,但代码复杂度略高,需要使用多进程启动。
注意事项
- 模型和数据要发送到指定的设备:确保模型和数据都发送到指定的GPU,否则可能会报错。
- 同步BN:在多GPU环境下,使用同步批标准化(Batch Normalization)可能需要特殊处理。
选择合适的方法
- 对于简单的多GPU训练任务,使用
DataParallel。 - 对于需要高性能、扩展性强的任务,使用
DistributedDataParallel。
参考资料
- PyTorch DataParallel Documentation
- PyTorch DistributedDataParallel Documentation
这两种方法可以帮助你在多块显卡上高效地运行你的深度学习代码,选择适合你的需求的方法,来实现模型的多GPU训练。
四、小结
关键点小结
- 设置
CUDA_VISIBLE_DEVICES: 指定多个GPU设备,使得代码只看到这些设备。 - 多GPU并行: 使用
torch.nn.DataParallel包装模型,利用多个GPU。 - 数据加载优化: 设置
num_workers参数优化数据加载,减少CPU负载。
这段代码展示了如何在PyTorch中配置多GPU训练和优化数据加载。这样可以有效利用多GPU的计算能力,并优化CPU资源使用。
为了将多GPU并行训练设置在代码中的适当位置并优化数据加载器,你需要在运行的第一个文件的开头设置os.environ["CUDA_VISIBLE_DEVICES"],并根据设备情况设置模型的多GPU并行。以下是如何进行这些设置的步骤和示例代码。
配置多GPU并行和数据加载器
1. 设置CUDA_VISIBLE_DEVICES
在运行的第一个文件的最前面,添加设置环境变量的代码。这会使得后续的代码只看到指定的GPU设备:
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0,1,6,7"
2. 配置PyTorch设备和模型
根据设备情况,使用torch.nn.DataParallel进行多GPU并行:
import torch
import torch.nn as nn
import torch.optim as optim
# 定义设备
globalDevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 假设你有一个cnn模型
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv = nn.Conv2d(3, 16, 3, 1)
self.fc = nn.Linear(16 * 26 * 26, 10)
def forward(self, x):
x = self.conv(x)
x = torch.relu(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
cnn = CNN().to(globalDevice)
# 如果有多个GPU,使用DataParallel
if torch.cuda.device_count() > 1:
print(f"Using {torch.cuda.device_count()} GPUs")
net = nn.DataParallel(cnn)
else:
print("Using single GPU or CPU")
net = cnn
3. 优化数据加载器
使用num_workers参数优化数据加载,通常设置为CPU核心数的一半或略低于核心数。对于高效的训练,可以设置为20或40,这取决于你的CPU能力和任务需求。
from torch.utils.data import DataLoader, Dataset
# 假设你有一个简单的数据集
class SimpleDataset(Dataset):
def __init__(self, size):
self.size = size
def __len__(self):
return self.size
def __getitem__(self, idx):
return torch.randn(3, 28, 28), torch.tensor(1)
dataset = SimpleDataset(1000)
dataloader = DataLoader(dataset, batch_size=64, shuffle=True, num_workers=20)
整合后的代码示例
以下是整合后的代码示例,涵盖了从配置GPU、定义模型、设置数据加载器到运行训练过程的完整流程。
import os
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
# 设置环境变量
os.environ["CUDA_VISIBLE_DEVICES"] = "0,1,6,7"
# 定义设备
globalDevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 定义简单的CNN模型
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv = nn.Conv2d(3, 16, 3, 1)
self.fc = nn.Linear(16 * 26 * 26, 10)
def forward(self, x):
x = self.conv(x)
x = torch.relu(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
# 实例化模型
cnn = CNN().to(globalDevice)
# 检查GPU数量并设置DataParallel
if torch.cuda.device_count() > 1:
print(f"Using {torch.cuda.device_count()} GPUs")
net = nn.DataParallel(cnn)
else:
print("Using single GPU or CPU")
net = cnn
# 定义数据集和数据加载器
class SimpleDataset(Dataset):
def __init__(self, size):
self.size = size
def __len__(self):
return self.size
def __getitem__(self, idx):
return torch.randn(3, 28, 28), torch.tensor(1)
dataset = SimpleDataset(1000)
dataloader = DataLoader(dataset, batch_size=64, shuffle=True, num_workers=20)
# 定义优化器和损失函数
optimizer = optim.SGD(net.parameters(), lr=0.01)
criterion = nn.CrossEntropyLoss()
# 简单的训练过程
for epoch in range(2):
for inputs, labels in dataloader:
inputs, labels = inputs.to(globalDevice), labels.to(globalDevice)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
print(f"Epoch {epoch+1}, Loss: {loss.item()}")
欢迎大家添加好友交流。