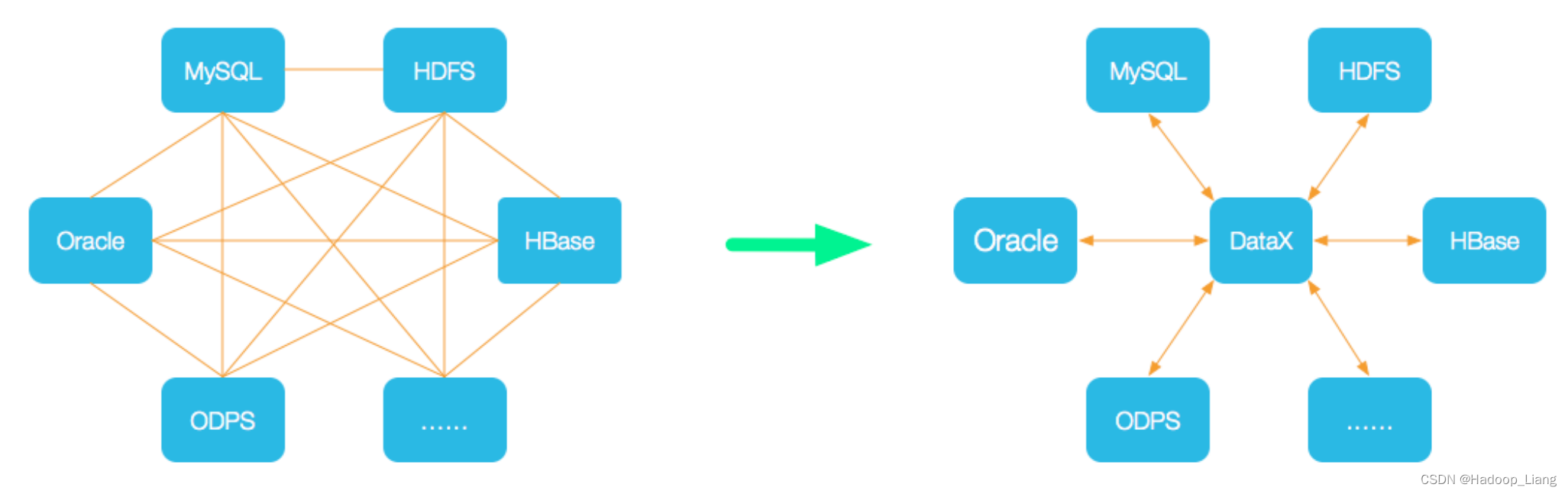
DataX概述
DataX 是阿里巴巴开源的一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。
Datax架构设计
DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。

DataX 3.0 开源版本支持单机多线程模式完成同步作业运行,本小节按一个DataX作业生命周期的时序图,从整体架构设计非常简要说明DataX各个模块相互关系。
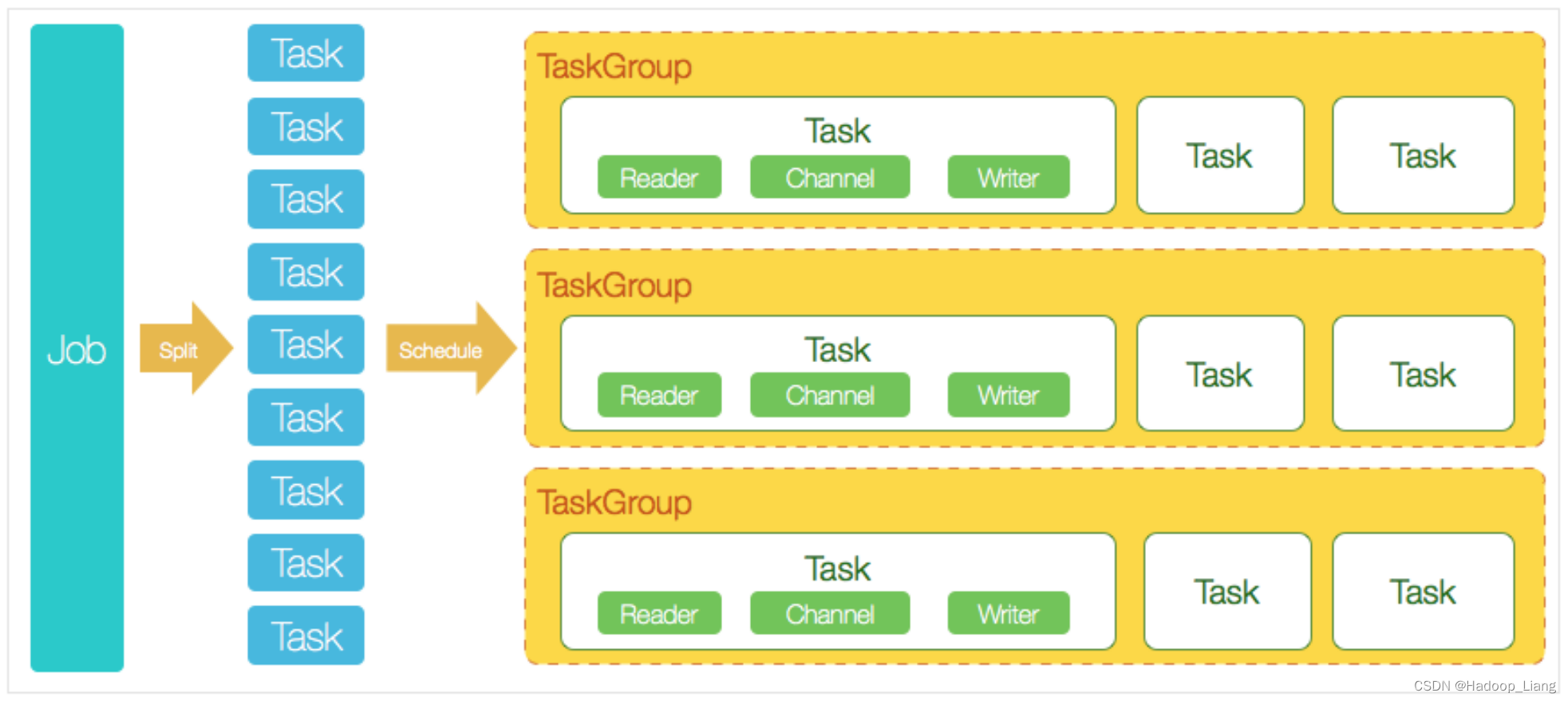
核心模块介绍
- DataX完成单个数据同步的作业,我们称之为Job,DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。DataX Job模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。
- DataXJob启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。
- 切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5。
- 每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader—>Channel—>Writer的线程来完成任务同步工作。
- DataX作业运行起来之后, Job监控并等待多个TaskGroup模块任务完成,等待所有TaskGroup任务完成后Job成功退出。否则,异常退出,进程退出值非0。
DataX与Sqoop对比
| 功能 | DataX | Sqoop |
|---|---|---|
| 运行模式 | 单进程多线程 | MR |
| 分布式 | 不支持,可以通过调度系统规避 | 支持 |
| 流控 | 有流控功能 | 需要定制 |
| 统计信息 | 已有一些统计,上报需定制 | 没有,分布式的数据收集不方便 |
| 数据校验 | 在core部分有校验功能 | 没有,分布式的数据收集不方便 |
| 监控 | 需要定制 | 需要定制 |
DataX的安装
前提条件
-
Linux,这里使用CentOS7
-
JDK1.8及以上,这里使用JDK1.8
-
Python2.x,这里使用Python2.7
在node4机器上操作
下载DataX安装包(安装包有800+M)
[hadoop@node4 installfile]$ wget http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
解压
[hadoop@node4 installfile]$ tar -zxvf datax.tar.gz -C ~/soft/
查看解压后的文件
[hadoop@node4 installfile]$ ls ~/soft/ ... datax ... [hadoop@node4 installfile]$ ls ~/soft/datax bin conf job lib log log_perf plugin script tmp [hadoop@node4 installfile]$ ls ~/soft/datax/bin/ datax.py dxprof.py perftrace.py [hadoop@node4 installfile]$ ls ~/soft/datax/job job.json
删除安装包
[hadoop@node4 installfile]$ rm -rf datax.tar.gz
运行官方自带案例
[hadoop@node4 installfile]$ python ~/soft/datax/bin/datax.py ~/soft/datax/job/job.json
执行报错如下:
2024-06-27 11:53:54.349 [main] WARN ConfigParser - 插件[streamreader,streamwriter]加载失败,1s后重试... Exception:Code:[Common-00], Describe:[您提供的配置文件存在错误信息,请检查您的作业配置 .] - 配置信息错误,您提供的配置文件[/home/hadoop/soft/datax/plugin/reader/._drdsreader/plugin.json]不存在. 请检查您的配置文件.
2024-06-27 11:53:55.358 [main] ERROR Engine -
经DataX智能分析,该任务最可能的错误原因是:
com.alibaba.datax.common.exception.DataXException: Code:[Common-00], Describe:[您提供的配置文件存在错误信息,请检查您的作业配置 .] - 配置信息错误,您提供的配置文件[/home/hadoop/soft/datax/plugin/reader/._drdsreader/plugin.json]不存在. 请检查您的配置文件.
at com.alibaba.datax.common.exception.DataXException.asDataXException(DataXException.java:26)
at com.alibaba.datax.common.util.Configuration.from(Configuration.java:95)
at com.alibaba.datax.core.util.ConfigParser.parseOnePluginConfig(ConfigParser.java:153)
at com.alibaba.datax.core.util.ConfigParser.parsePluginConfig(ConfigParser.java:125)
at com.alibaba.datax.core.util.ConfigParser.parse(ConfigParser.java:63)
at com.alibaba.datax.core.Engine.entry(Engine.java:137)
at com.alibaba.datax.core.Engine.main(Engine.java:204)
解决报错:
进入datax解压目录
[hadoop@node4 installfile]$ cd /home/hadoop/soft/datax
查找datax目录下文件名称带有er结尾的文件
[hadoop@node4 datax]$ find ./* -type f -name ".*er" ./plugin/._reader ./plugin/reader/._drdsreader ./plugin/reader/._hdfsreader ./plugin/reader/._otsstreamreader ./plugin/reader/._otsreader ./plugin/reader/._txtfilereader ./plugin/reader/._ftpreader ./plugin/reader/._streamreader ./plugin/reader/._odpsreader ./plugin/reader/._cassandrareader ./plugin/reader/._hbase11xreader ./plugin/reader/._oraclereader ./plugin/reader/._postgresqlreader ./plugin/reader/._mysqlreader ./plugin/reader/._rdbmsreader ./plugin/reader/._mongodbreader ./plugin/reader/._ossreader ./plugin/reader/._sqlserverreader ./plugin/reader/._hbase094xreader ./plugin/._writer ./plugin/writer/._oraclewriter ./plugin/writer/._ocswriter ./plugin/writer/._mysqlwriter ./plugin/writer/._postgresqlwriter ./plugin/writer/._rdbmswriter ./plugin/writer/._mongodbwriter ./plugin/writer/._osswriter ./plugin/writer/._adswriter ./plugin/writer/._hbase094xwriter ./plugin/writer/._sqlserverwriter ./plugin/writer/._hdfswriter ./plugin/writer/._otswriter ./plugin/writer/._drdswriter ./plugin/writer/._txtfilewriter ./plugin/writer/._cassandrawriter ./plugin/writer/._ftpwriter ./plugin/writer/._streamwriter ./plugin/writer/._odpswriter ./plugin/writer/._hbase11xsqlwriter ./plugin/writer/._hbase11xwriter
删除查到的文件
[hadoop@node4 datax]$ find ./* -type f -name ".*er" | xargs rm -rf
再次运行测试命令,成功如下:
[hadoop@node4 datax]$ python ~/soft/datax/bin/datax.py ~/soft/datax/job/job.json
DataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.
2024-06-27 12:13:32.138 [main] INFO VMInfo - VMInfo# operatingSystem class => sun.management.OperatingSystemImpl
2024-06-27 12:13:32.145 [main] INFO Engine - the machine info =>
osInfo: Oracle Corporation 1.8 25.212-b10
jvmInfo: Linux amd64 3.10.0-1160.el7.x86_64
cpu num: 4
totalPhysicalMemory: -0.00G
freePhysicalMemory: -0.00G
maxFileDescriptorCount: -1
currentOpenFileDescriptorCount: -1
GC Names [PS MarkSweep, PS Scavenge]
MEMORY_NAME | allocation_size | init_size
PS Eden Space | 256.00MB | 256.00MB
Code Cache | 240.00MB | 2.44MB
Compressed Class Space | 1,024.00MB | 0.00MB
PS Survivor Space | 42.50MB | 42.50MB
PS Old Gen | 683.00MB | 683.00MB
Metaspace | -0.00MB | 0.00MB
2024-06-27 12:13:32.162 [main] INFO Engine -
{
"content":[
{
"reader":{
"name":"streamreader",
"parameter":{
"column":[
{
"type":"string",
"value":"DataX"
},
{
"type":"long",
"value":19890604
},
{
"type":"date",
"value":"1989-06-04 00:00:00"
},
{
"type":"bool",
"value":true
},
{
"type":"bytes",
"value":"test"
}
],
"sliceRecordCount":100000
}
},
"writer":{
"name":"streamwriter",
"parameter":{
"encoding":"UTF-8",
"print":false
}
}
}
],
"setting":{
"errorLimit":{
"percentage":0.02,
"record":0
},
"speed":{
"byte":10485760
}
}
}
2024-06-27 12:13:32.191 [main] WARN Engine - prioriy set to 0, because NumberFormatException, the value is: null
2024-06-27 12:13:32.193 [main] INFO PerfTrace - PerfTrace traceId=job_-1, isEnable=false, priority=0
2024-06-27 12:13:32.193 [main] INFO JobContainer - DataX jobContainer starts job.
2024-06-27 12:13:32.195 [main] INFO JobContainer - Set jobId = 0
2024-06-27 12:13:32.226 [job-0] INFO JobContainer - jobContainer starts to do prepare ...
2024-06-27 12:13:32.226 [job-0] INFO JobContainer - DataX Reader.Job [streamreader] do prepare work .
2024-06-27 12:13:32.226 [job-0] INFO JobContainer - DataX Writer.Job [streamwriter] do prepare work .
2024-06-27 12:13:32.227 [job-0] INFO JobContainer - jobContainer starts to do split ...
2024-06-27 12:13:32.228 [job-0] INFO JobContainer - Job set Max-Byte-Speed to 10485760 bytes.
2024-06-27 12:13:32.229 [job-0] INFO JobContainer - DataX Reader.Job [streamreader] splits to [1] tasks.
2024-06-27 12:13:32.230 [job-0] INFO JobContainer - DataX Writer.Job [streamwriter] splits to [1] tasks.
2024-06-27 12:13:32.258 [job-0] INFO JobContainer - jobContainer starts to do schedule ...
2024-06-27 12:13:32.265 [job-0] INFO JobContainer - Scheduler starts [1] taskGroups.
2024-06-27 12:13:32.267 [job-0] INFO JobContainer - Running by standalone Mode.
2024-06-27 12:13:32.292 [taskGroup-0] INFO TaskGroupContainer - taskGroupId=[0] start [1] channels for [1] tasks.
2024-06-27 12:13:32.305 [taskGroup-0] INFO Channel - Channel set byte_speed_limit to -1, No bps activated.
2024-06-27 12:13:32.306 [taskGroup-0] INFO Channel - Channel set record_speed_limit to -1, No tps activated.
2024-06-27 12:13:32.336 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[0] attemptCount[1] is started
2024-06-27 12:13:32.441 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[0] is successed, used[120]ms
2024-06-27 12:13:32.442 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] completed it's tasks.
2024-06-27 12:13:42.303 [job-0] INFO StandAloneJobContainerCommunicator - Total 100000 records, 2600000 bytes | Speed 253.91KB/s, 10000 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.054s | All Task WaitReaderTime 0.077s | Percentage 100.00%
2024-06-27 12:13:42.303 [job-0] INFO AbstractScheduler - Scheduler accomplished all tasks.
2024-06-27 12:13:42.304 [job-0] INFO JobContainer - DataX Writer.Job [streamwriter] do post work.
2024-06-27 12:13:42.305 [job-0] INFO JobContainer - DataX Reader.Job [streamreader] do post work.
2024-06-27 12:13:42.306 [job-0] INFO JobContainer - DataX jobId [0] completed successfully.
2024-06-27 12:13:42.307 [job-0] INFO HookInvoker - No hook invoked, because base dir not exists or is a file: /home/hadoop/soft/datax/hook
2024-06-27 12:13:42.310 [job-0] INFO JobContainer -
[total cpu info] =>
averageCpu | maxDeltaCpu | minDeltaCpu
-1.00% | -1.00% | -1.00%
[total gc info] =>
NAME | totalGCCount | maxDeltaGCCount | minDeltaGCCount | totalGCTime | maxDeltaGCTime | minDeltaGCTime
PS MarkSweep | 0 | 0 | 0 | 0.000s | 0.000s | 0.000s
PS Scavenge | 0 | 0 | 0 | 0.000s | 0.000s | 0.000s
2024-06-27 12:13:42.311 [job-0] INFO JobContainer - PerfTrace not enable!
2024-06-27 12:13:42.312 [job-0] INFO StandAloneJobContainerCommunicator - Total 100000 records, 2600000 bytes | Speed 253.91KB/s, 10000 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.054s | All Task WaitReaderTime 0.077s | Percentage 100.00%
2024-06-27 12:13:42.315 [job-0] INFO JobContainer -
任务启动时刻 : 2024-06-27 12:13:32
任务结束时刻 : 2024-06-27 12:13:42
任务总计耗时 : 10s
任务平均流量 : 253.91KB/s
记录写入速度 : 10000rec/s
读出记录总数 : 100000
读写失败总数 : 0
DataX的使用
DataX任务提交命令
用户只需根据自己同步数据的数据源和目的地选择相应的Reader和Writer,并将Reader和Writer的信息配置在一个json文件中。提交命令如下:
python bin/datax.py path/to/your/job.json
DataX配置文件格式
可以使用如下命名查看DataX配置文件模板。
[hadoop@node4 ~]$ cd ~/soft/datax/ [hadoop@node4 datax]$ pyhton bin/datax.py -r mysqlreader -w hdfswriter
查到文件模板如下:
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [],
"connection": [
{
"jdbcUrl": [],
"table": []
}
],
"password": "",
"username": "",
"where": ""
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [],
"compress": "",
"defaultFS": "",
"fieldDelimiter": "",
"fileName": "",
"fileType": "",
"path": "",
"writeMode": ""
}
}
}
],
"setting": {
"speed": {
"channel": ""
}
}
}
}
MySQL数据准备
需要准备MySQL8环境,并且能够远程连接。 可参考:安装MySQL8
建库建表操作:这里在node3机器上的mysql上操作
create database if not exists test;
use test;
drop table if exists stu;
create table stu (id int, name varchar(100), age int);
insert into stu values(1,"张三",18);
insert into stu values(2,"李四",20);
insert into stu values(3,"王五",21);
insert into stu values(4,"赵六",22);同步MySQL数据到HDFS
要求:同步MySQL test数据库中stu表数据到HDFS的/stu目录。
编写配置文件
(1)创建配置文件stu.json
[hadoop@node4 ~]$ vim ~/soft/datax/job/stu.json
(2)配置文件内容如下
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
"id",
"name",
"age"
],
"where": "id>=3",
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://node3:3306/test?useSSL=false&serverTimezone=Asia/Shanghai&useUnicode=true&allowPublicKeyRetrieval=true&characterEncoding=utf-8"
],
"table": [
"stu"
]
}
],
"username": "root",
"password": "000000",
"splitPk": ""
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{
"name": "id",
"type": "int"
},
{
"name": "name",
"type": "string"
},
{
"name": "age",
"type": "int"
}
],
"compress": "gzip",
"defaultFS": "hdfs://node2:9820",
"fieldDelimiter": "\t",
"fileName": "stu",
"fileType": "text",
"path": "/stu",
"writeMode": "append"
}
}
}
],
"setting": {
"speed": {
"channel": 1
}
}
}
}提交任务
(1)在HDFS创建/stu目录
[hadoop@node2 ~]$ start-dfs.sh [hadoop@node2 ~]$ hadoop fs -mkdir /stu
(2)进入DataX根目录
[hadoop@node4 ~]$ cd ~/soft/datax [hadoop@node4 datax]$
(3)执行如下命令
[hadoop@node4 datax]$ python bin/datax.py job/stu.json
报错
2024-06-27 12:43:27.268 [job-0] WARN DBUtil - test connection of [jdbc:mysql://node3:3306/test?serverTimezone=Asia/Shanghai&useUnicode=true&allowPublicKeyRetrieval=true&characterEncoding=utf-8] failed, for Code:[DBUtilErrorCode-10], Description:[连接数据库失败. 请检查您的 账号、密码、数据库名称、IP、Port或者向 DBA 寻求帮助(注意网络环境).]. - 具体错误信息为:com.mysql.jdbc.exceptions.jdbc4.MySQLNonTransientConnectionException: Could not create connection to database server..
解决报错:
经过一番折腾,例如:配置bind-address=0.0.0.0,依然同样的报错。
发现Root Cause是MySQL驱动版本不兼容的问题。
查看mysqlreader/libs下的驱动包
[hadoop@node4 datax]$ ls plugin/reader/mysqlreader/libs/ commons-collections-3.0.jar druid-1.0.15.jar logback-core-1.0.13.jar commons-io-2.4.jar fastjson-1.1.46.sec01.jar mysql-connector-java-5.1.34.jar commons-lang3-3.3.2.jar guava-r05.jar plugin-rdbms-util-0.0.1-SNAPSHOT.jar commons-math3-3.1.1.jar hamcrest-core-1.3.jar slf4j-api-1.7.10.jar datax-common-0.0.1-SNAPSHOT.jar logback-classic-1.0.13.jar [hadoop@node4 datax]$
发现驱动包是mysql5版本的
mysql-connector-java-5.1.34.jar
换成mysql8版本的驱动包
mysql-connector-j-8.0.31.jar
将mysql8驱动包上传到plugin/reader/mysqlreader/libs目录下,同时删除或重命名mysql5的驱动包(重命名后让mysql5驱动不可用),这里重命名mysql5驱动包。
[hadoop@node4 datax]$ mv plugin/reader/mysqlreader/libs/mysql-connector-java-5.1.34.jar plugin/reader/mysqlreader/libs/mysql-connector-java-5.1.34.jar.bak [hadoop@node4 datax]$ ls plugin/reader/mysqlreader/libs/ commons-collections-3.0.jar druid-1.0.15.jar logback-core-1.0.13.jar commons-io-2.4.jar fastjson-1.1.46.sec01.jar mysql-connector-j-8.0.31.jar commons-lang3-3.3.2.jar guava-r05.jar mysql-connector-java-5.1.34.jar.bak commons-math3-3.1.1.jar hamcrest-core-1.3.jar plugin-rdbms-util-0.0.1-SNAPSHOT.jar datax-common-0.0.1-SNAPSHOT.jar logback-classic-1.0.13.jar slf4j-api-1.7.10.jar
重新执行成功如下
[hadoop@node4 datax]$ python bin/datax.py job/stu.json ... ... ... 2024-06-28 00:30:48.367 [job-0] INFO JobContainer - 任务启动时刻 : 2024-06-28 00:30:35 任务结束时刻 : 2024-06-28 00:30:48 任务总计耗时 : 13s 任务平均流量 : 1B/s 记录写入速度 : 0rec/s 读出记录总数 : 2 读写失败总数 : 0
查看hdfs数据
[hadoop@node2 ~]$ hdfs dfs -cat /stu/* | zcat 2024-06-28 00:39:43,030 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false 3 王五 21 4 赵六 22
同步HDFS数据到MySQL
要求:同步HDFS上的/stu目录下的数据到MySQL test数据库下的stu1表。
在MySQL中创建test.stu1表
create database if not exists test; use test; drop table if exists stu1; create table stu1 like stu;
编写配置文件
(1)创建配置文件stu1.json
[hadoop@node4 ~$ vim ~/soft/datax/job/stu1.json
(2)配置文件内容如下
{
"job": {
"content": [
{
"reader": {
"name": "hdfsreader",
"parameter": {
"defaultFS": "hdfs://node2:9820",
"path": "/stu",
"column": [
"*"
],
"fileType": "text",
"compress": "gzip",
"encoding": "UTF-8",
"nullFormat": "\\N",
"fieldDelimiter": "\t",
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"username": "root",
"password": "000000",
"connection": [
{
"table": [
"stu1"
],
"jdbcUrl": "jdbc:mysql://node3:3306/test?useSSL=false&serverTimezone=Asia/Shanghai&useUnicode=true&allowPublicKeyRetrieval=true&characterEncoding=utf-8"
}
],
"column": [
"id",
"name",
"age"
],
"writeMode": "replace"
}
}
}
],
"setting": {
"speed": {
"channel": 1
}
}
}
}执行同步数据任务
[atguigu@hadoop102 datax]$ cd ~/soft/datax [atguigu@hadoop102 datax]$ python bin/datax.py job/stu1.json
报错
2024-06-28 00:48:40.431 [job-0] ERROR RetryUtil - Exception when calling callable, 异常Msg:Code:[DBUtilErrorCode-10], Description:[连接数据库失败. 请检查您的 账号、密码、数据库名称、IP、Port或者向 DBA 寻求帮助(注意网络环境).]. - 具体错误信息为:com.mysql.jdbc.exceptions.jdbc4.MySQLNonTransientConnectionException: Could not create connection to database server.
com.alibaba.datax.common.exception.DataXException: Code:[DBUtilErrorCode-10], Description:[连接数据库失败. 请检查您的 账号、密码、数据库名称、IP、Port或者向 DBA 寻求帮助(注意网络环境).]. - 具体错误信息为:com.mysql.jdbc.exceptions.jdbc4.MySQLNonTransientConnectionException: Could not create connection to database server.
at com.alibaba.datax.common.exception.DataXException.asDataXException(DataXException.java:26) ~[datax-common-0.0.1-SNAPSHOT.jar:na]
查看writer下的mysql驱动,发现也是mysql5的驱动mysql-connector-java-5.1.34.jar
[hadoop@node4 datax]$ ls plugin/writer/mysqlwriter/libs/
commons-collections-3.0.jar druid-1.0.15.jar logback-core-1.0.13.jar
commons-io-2.4.jar fastjson-1.1.46.sec01.jar mysql-connector-java-5.1.34.jar
commons-lang3-3.3.2.jar guava-r05.jar plugin-rdbms-util-0.0.1-SNAPSHOT.jar
commons-math3-3.1.1.jar hamcrest-core-1.3.jar slf4j-api-1.7.10.jar
datax-common-0.0.1-SNAPSHOT.jar logback-classic-1.0.13.jar
复制mysql8的驱动到writer的libs目录,并重命名mysql5驱动
[hadoop@node4 datax]$ cp plugin/reader/mysqlreader/libs/mysql-connector-j-8.0.31.jar plugin/writer/mysqlwriter/libs/ [hadoop@node4 datax]$ mv plugin/writer/mysqlwriter/libs/mysql-connector-java-5.1.34.jar plugin/writer/mysqlwriter/libs/mysql-connector-java-5.1.34.jar.bak [hadoop@node4 datax]$ ls plugin/writer/mysqlwriter/libs/ commons-collections-3.0.jar druid-1.0.15.jar logback-core-1.0.13.jar commons-io-2.4.jar fastjson-1.1.46.sec01.jar mysql-connector-j-8.0.31.jar commons-lang3-3.3.2.jar guava-r05.jar mysql-connector-java-5.1.34.jar.bak commons-math3-3.1.1.jar hamcrest-core-1.3.jar plugin-rdbms-util-0.0.1-SNAPSHOT.jar datax-common-0.0.1-SNAPSHOT.jar logback-classic-1.0.13.jar slf4j-api-1.7.10.jar
重新执行
[hadoop@node4 datax]$ python bin/datax.py job/stu1.json
DataX打印日志
2024-06-28 00:57:08.442 [job-0] INFO JobContainer - 任务启动时刻 : 2024-06-28 00:56:55 任务结束时刻 : 2024-06-28 00:57:08 任务总计耗时 : 12s 任务平均流量 : 1B/s 记录写入速度 : 0rec/s 读出记录总数 : 2 读写失败总数 : 0
查看node3 MySQL表stu1表数据,能看到从hdfs导入到mysql的数据。
mysql> select * from stu1; +------+--------+------+ | id | name | age | +------+--------+------+ | 3 | 王五 | 21 | | 4 | 赵六 | 22 | +------+--------+------+ 2 rows in set (0.00 sec)
导入导出到数据库时,注意修改reader和writer下的mysql驱动版本改为连接mysql所需要的驱动版本。
完成!enjoy it!