公共部分
```
# 引入数据分析工具 Pandas
import pandas as pd
# 引入数据可视化工具 Matplotlib
import matplotlib.pyplot as plt
# 引入科学计算库numpy
import numpy as np
from scipy import stats
#解决输出时列名对齐问题
pd.set_option('display.unicode.east_asian_width', True)
# 解决输出中文乱码问题
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置显示中文字体
plt.rcParams['axes.unicode_minus'] = False # 设置正常显示符号
# 读取成绩表数据
data = pd.read_excel('E:\\practiceCode\\pythonCode\\source\\成绩表.xlsx')
# 计算男女生总成绩
data['总成绩'] = data.iloc[:, 2:-1].sum(axis=1)
# 获取列
subjects = data.columns[2:]
```
平均成绩与标准差
```
# 计算男生和女生在每个科目的平均成绩 与 标准差
subjects = data.columns[2:]
for subject in subjects:
male_mean = data[data['性别'] == '男'][subject].mean()
male_std = data[data['性别'] == '男'][subject].std()
female_mean = data[data['性别'] == '女'][subject].mean()
female_std = data[data['性别'] == '女'][subject].std()
print(f'{subject} 男生平均成绩: {male_mean}, 标准差: {male_std}')
print(f'{subject} 女生平均成绩: {female_mean}, 标准差: {female_std}')
```

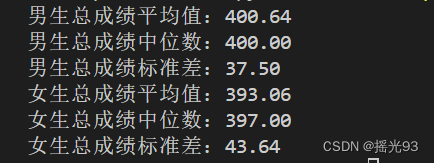
总成绩差异(平均值/标准差/中位数)
```
# 计算男女生的总成绩
data['总成绩'] = data.iloc[:,2:-1].sum(axis=1)
# 比较男女生总成绩差异 (平均值/中位数/标准差)
male_total_mean = data[data['性别'] == '男']['总成绩'].mean()
male_total_median = data[data['性别'] == '男']['总成绩'].median()
male_total_std = data[data['性别'] == '男']['总成绩'].std()
female_total_mean = data[data['性别'] == '女']['总成绩'].mean()
female_total_median = data[data['性别'] == '女']['总成绩'].median()
female_total_std = data[data['性别'] == '女']['总成绩'].std()
# 输出比较结果
print(f'男生总成绩平均值:{male_total_mean:.2f}')
print(f'男生总成绩中位数:{male_total_median:.2f}')
print(f'男生总成绩标准差:{male_total_std:.2f}')
print(f'女生总成绩平均值:{female_total_mean:.2f}')
print(f'女生总成绩中位数:{female_total_median:.2f}')
print(f'女生总成绩标准差:{female_total_std:.2f}' )
```
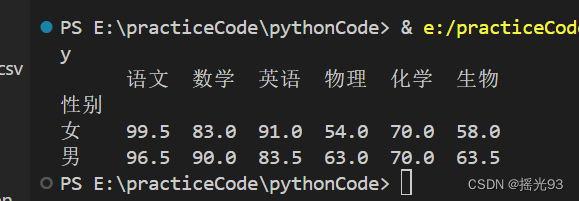
按性别统计各个科目成绩的中位数
```
subjects = data.columns[2:]
# 按性别统计各个科目成绩的中位数
subjects_median = data.groupby('性别')[subjects].median()
print(subjects_median)
```
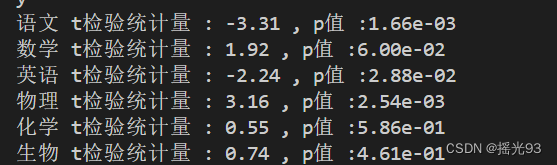
使用t检验 计算男生与女生在每个科目上的成绩差异性
```
from scipy import stats
#解决输出时列名对齐问题
pd.set_option('display.unicode.east_asian_width', True)
# 读取成绩表数据
data = pd.read_excel('E:\\practiceCode\\pythonCode\\source\\成绩表.xlsx')
subjects = data.columns[2:]
# 计算男生和女生在每个科目上成绩的差异显著性(例如使用t检验),即使用Pandas与SxiPy库计算
for subject in subjects:
t_stat,p_value=stats.ttest_ind(data[data['性别']=='男'][subject],data[data['性别']=='女'][subject])
print(f'{subject} t检验统计量 : {t_stat:.2f} , p值 :{p_value:.2e}')
```
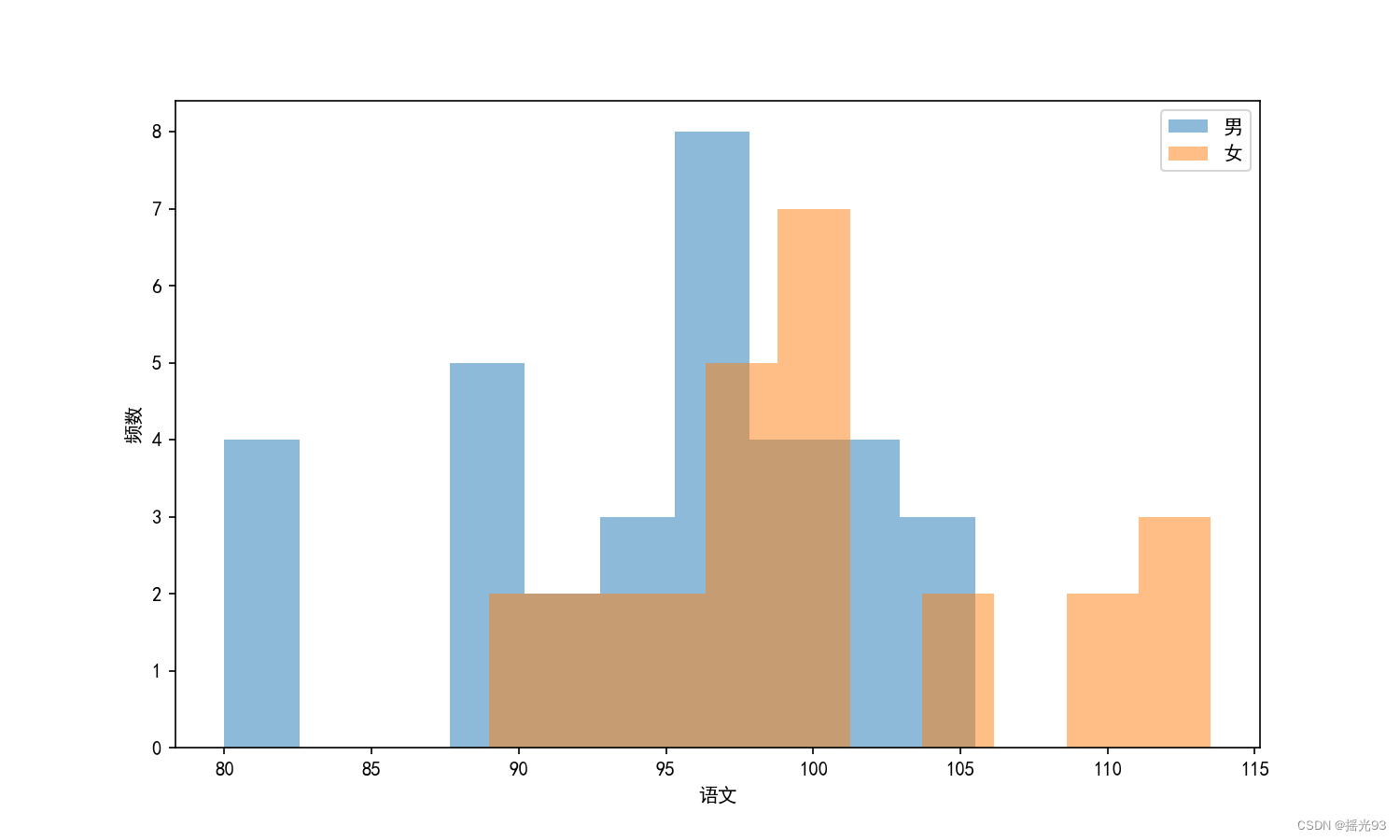
男女生在各科目的成绩分布直方图
```
subjects = data.columns[2:]
# 绘制男生 女生 在各个科目上的成绩分布直方图 , 使用Matplotlib库
for subject in subjects:
plt.figure(figsize=(10,6))
plt.hist(data[data['性别'] == '男'][subject], alpha=0.5, label='男')
plt.hist(data[data['性别'] == '女'][subject], alpha=0.5, label='女')
plt.xlabel(subject)
plt.ylabel('频数')
plt.legend()
plt.show()
```
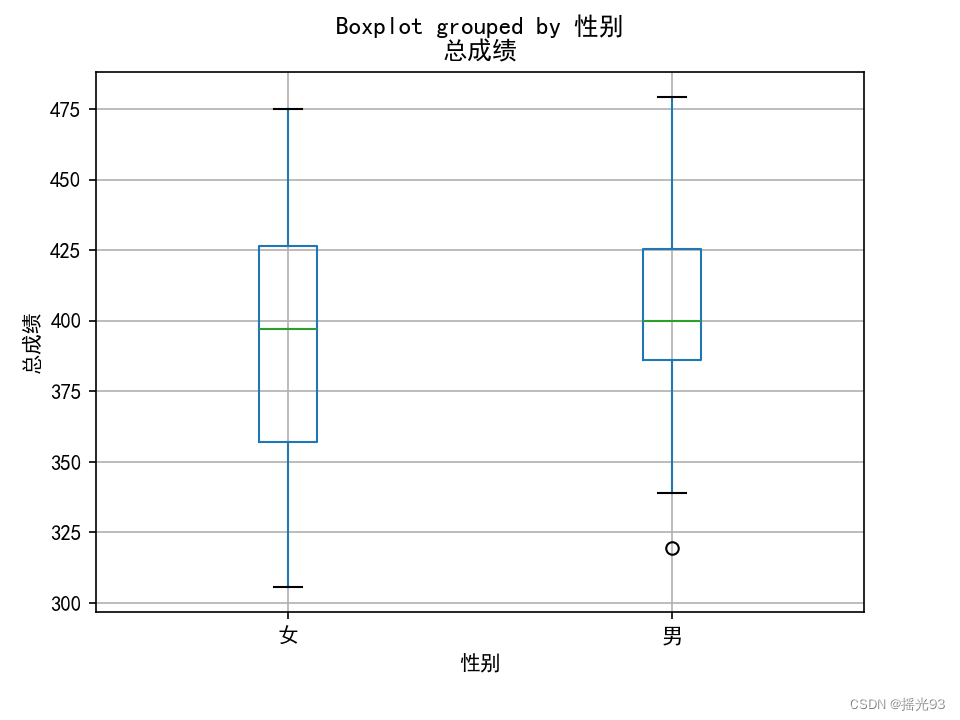
用箱型图表示男女生总成绩
```
# 绘制男女生总成绩的箱型图 , 使用matplotlib库
data.boxplot(column='总成绩',by='性别')
plt.ylabel('总成绩')
plt.show()
```
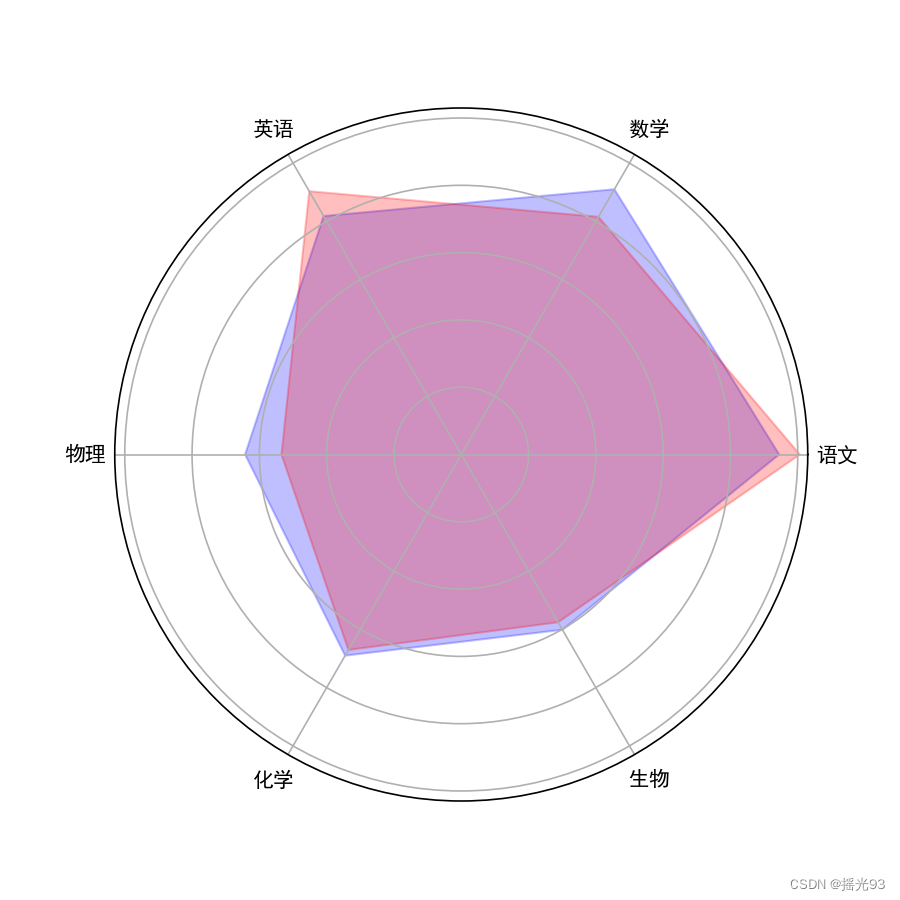
绘制男生女生在各个科目上的平均成绩雷达图
```
# 绘制男女生 在各个科目上的平均成绩雷达图
labels = np.array(subjects)
num_vars = len(labels)
angles = np.linspace(0, 2 * np.pi, num_vars, endpoint=False).tolist()
male_means = [data[data['性别'] == '男'][subject].mean() for subject in subjects]
female_means = [data[data['性别'] == '女'][subject].mean() for subject in subjects]
fig, ax = plt.subplots(figsize=(6, 6), subplot_kw=dict(polar=True))
ax.fill(angles, male_means, color='blue', alpha=0.25)
ax.fill(angles, female_means, color='red', alpha=0.25)
ax.set_yticklabels([])
ax.set_xticks(angles)
ax.set_xticklabels(labels)
plt.show()
```


![[漏洞复现] MetInfo5.0.4文件包含漏洞](https://img-blog.csdnimg.cn/direct/6007b1743dc44277b731aec7d9f0de8c.png#pic_center)
![[BUUCTF从零单排] Web方向 02.Web入门篇之『常见的搜集』解题思路(dirsearch工具详解)](https://img-blog.csdnimg.cn/direct/9f7b8152d18b433daa91bfbb8a8aed8e.png#pic_center)