机器学习-数据预处理-聚类-回归-分类-单车数据集
- 前言
- 一、数据预处理
- 1. 导入数据集
- 2. 数据预处理
- 3. 处理缺失值
- 4. 生成特征用于后续进一步的分析
- 二、数据分布可视化
- 1. 骑行时长分布
- 2. 起始站和终点站分布可视化
- 3. 高峰期与非高峰期骑行频次分布
- 三、聚类分析
- 1. K-means聚类
- 四、回归分析
- 1.线性回归
- 2. XGBoost回归
- 五、分类分析
- 1.使用随机森林进行分类
- 总结
前言
数据集已经上传到了我的资源里面,对于这个数据集,将进行数据预处理,然后进行k-means聚类、使用线性回归进行回归、使用XGBoost进行回归分析,并且进行分类预测。
一、数据预处理
1. 导入数据集
import pandas as pd
import numpy as np
df = pd.read_csv(r"YourPath\考查-单车.csv")
df.head(10)
2. 数据预处理
# 检查空缺值
print(df.isnull().sum())
# 转换时间格式
df['Start date'] = pd.to_datetime(df['Start date'])
df['End date'] = pd.to_datetime(df['End date'])
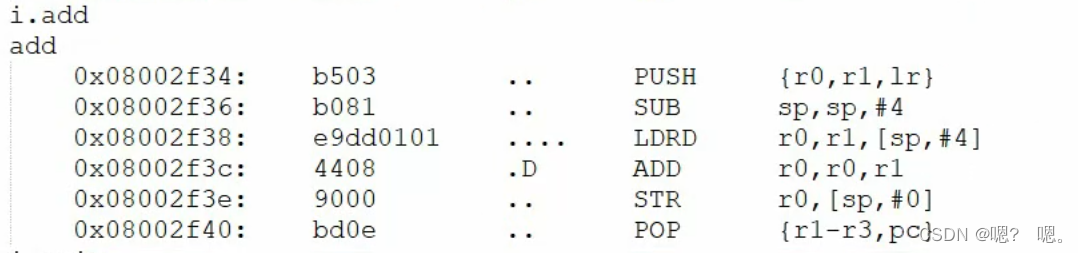
# 骑行时长合理性检查(假设合理时长为1分钟到4小时)
df = df[(df['Total duration (ms)'] >= 60000) & (df['Total duration (ms)'] <= 14400000)]
通过检查isnull()判断了是否有空缺值,然后把时间格式转化了一下,同时检查了一下骑行时长的合理性,得到的结果为:

3. 处理缺失值
从上面的结果可以看到“Start station number”和“End station number”列存在着缺失值,所以需要对这两个数据进行处理,可以直接的删去这一行,但是我这里选择的是用众数来进行填补,因为我觉得这行数据应该错误不是很大,还是有用的,因为他的持续时间啥的都是有的,如果是特别关键的元素值缺失了,就直接去掉这一行是最好的:
# 处理缺失值,使用众数填补
start_station_mode = df['Start station number'].mode()[0]
end_station_mode = df['End station number'].mode()[0]
df['Start station number'].fillna(start_station_mode, inplace=True)
df['End station number'].fillna(end_station_mode, inplace=True)
# 再次检查空缺值
print(df.isnull().sum())
通过再次检查这些缺失值,可以发现,确实没了缺失值,所以是正确的处理:

4. 生成特征用于后续进一步的分析
# 生成新特征:时间段
df['hour'] = df['Start date'].dt.hour
df['is_peak'] = df['hour'].apply(lambda x: 1 if (6 <= x <= 10) or (16 <= x <= 20) else 0)
# 生成新特征:工作日/周末
df['is_weekend'] = df['Start date'].dt.weekday.apply(lambda x: 1 if x >= 5 else 0)
print(df.head(10))
二、数据分布可视化
1. 骑行时长分布
import matplotlib.pyplot as plt
plt. rcParams [ 'font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt. rcParams [ 'axes.unicode_minus']=False #用来正常显示负号
# 骑行时长分布
plt.hist(df['Total duration (ms)'] / 60000, bins=50, color='blue', alpha=0.7)
plt.xlabel('骑行时长(分钟)')
plt.ylabel('频数')
plt.title('骑行时长分布')
plt.show()
直接就是导包然后很常规的解决这个matplotlib的中文的问题,然后统计出每次骑行的交互数据与骑行时长的关系,这样我们就可以很直观的看到每次骑行多久的人是最多的。

2. 起始站和终点站分布可视化
# 起始站分布
start_station_counts = df['Start station'].value_counts().head(10)
start_station_counts.plot(kind='bar', color='green', alpha=0.7)
plt.xlabel('起始站')
plt.ylabel('频数')
plt.title('前十起始站分布')
plt.show()
# 终点站分布
end_station_counts = df['End station'].value_counts().head(10)
end_station_counts.plot(kind='bar', color='red', alpha=0.7)
plt.xlabel('终点站')
plt.ylabel('频数')
plt.title('前十终点站分布')
plt.show()


3. 高峰期与非高峰期骑行频次分布
# 高峰期与非高峰期骑行频次分布
peak_counts = df['is_peak'].value_counts()
peak_counts.plot(kind='bar', color=['red', 'blue'], alpha=0.7)
plt.xlabel('是否高峰期')
plt.ylabel('频数')
plt.title('高峰期与非高峰期骑行频次分布')
plt.show()

上面的代码都比较类似,就是计算出每一类每一种的各种数量,然后作为Y轴然后自己选择的属性作为X轴可视化展示出来就行。
三、聚类分析
1. K-means聚类
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import silhouette_score
# 提取相关特征
features = df[['Start station number', 'End station number', 'Total duration (ms)']]
scaler = StandardScaler()
scaled_features = scaler.fit_transform(features)
# 使用KMeans进行聚类分析
kmeans = KMeans(n_clusters=5, random_state=0)
clusters = kmeans.fit_predict(scaled_features)
df['Cluster'] = clusters
# 聚类结果可视化
plt.scatter(df['Start station number'], df['End station number'], c=df['Cluster'], cmap='viridis', alpha=0.5)
plt.xlabel('起始站编号')
plt.ylabel('终点站编号')
plt.title('用户行为聚类分析')
plt.show()
# 计算轮廓系数
silhouette_avg = silhouette_score(scaled_features, clusters)
print("轮廓系数:", silhouette_avg)

也可以选用更多的聚类方法去实现,更多的关于聚类的信息可以看这篇文章:聚类
四、回归分析
1.线性回归
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# 特征和目标变量
X = df[['Start station number', 'End station number', 'Bike model']]
y = df['Total duration (ms)']
# 将分类变量转化为数值变量
X = pd.get_dummies(X, columns=['Bike model'], drop_first=True)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 训练线性回归模型
lr = LinearRegression()
lr.fit(X_train, y_train)
# 预测并评估模型
y_pred = lr.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print(f'均方误差: {mse}')
# 预测结果可视化
plt.scatter(y_test, y_pred, alpha=0.5)
plt.xlabel('实际骑行时长(毫秒)')
plt.ylabel('预测骑行时长(毫秒)')
plt.title('骑行时长预测')
plt.show()
这个就是直接使用线性回归,来预测骑行时长

均方误差还是比较大的,图形的拟合效果也并不好,说明可能不是很适合去使用线性回归,关于线性回归可以看这里:线性回归
2. XGBoost回归
XGBoost是一种高效的梯度提升树,并且使用了更多特征进行这个XGBoost回归分析:
import xgboost as xgb
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# 特征和目标变量
X = df[['Start station number', 'End station number', 'Bike model', 'hour', 'is_weekend']]
y = df['Total duration (ms)']
# 将分类变量转化为数值变量
X = pd.get_dummies(X, columns=['Bike model'], drop_first=True)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 训练XGBoost模型
xgb_model = xgb.XGBRegressor(objective='reg:squarederror', n_estimators=100, learning_rate=0.1)
xgb_model.fit(X_train, y_train)
# 预测并评估模型
y_pred = xgb_model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print(f'均方误差: {mse}')
# 预测结果可视化
plt.scatter(y_test, y_pred, alpha=0.5)
plt.xlabel('实际骑行时长(秒)')
plt.ylabel('预测骑行时长(秒)')
plt.title('骑行时长预测')
plt.show()

五、分类分析
其实这个数据集并不是适合或者需要分类,强行分类一下,我这里用的是随机森林,还可以用很多别的分类,可以看看这篇:分类
1.使用随机森林进行分类
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report
# 特征和目标变量
X = df[['Start station number', 'End station number', 'Bike model', 'Total duration (ms)', 'is_weekend']]
y = df['is_peak']
# 将分类变量转化为数值变量
X = pd.get_dummies(X, columns=['Bike model'], drop_first=True)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 训练随机森林分类器
rf = RandomForestClassifier(n_estimators=100, random_state=42)
rf.fit(X_train, y_train)
# 预测并评估模型
y_pred = rf.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f'准确率: {accuracy}')
print(classification_report(y_test, y_pred))
# 预测结果可视化
plt.scatter(X_test['Total duration (ms)'], y_test, alpha=0.5, label='Actual')
plt.scatter(X_test['Total duration (ms)'], y_pred, alpha=0.5, label='Predicted')
plt.xlabel('骑行时长(秒)')
plt.ylabel('是否高峰期')
plt.title('高峰期骑行预测')
plt.legend()
plt.show()

总结
这篇主要是完成了数据的预处理、特征工程、可视化分析和多种机器学习模型的应用。对这个单车数据进行了聚类、回归、分类并进行可视化。
如果您觉得这篇文章对您有帮助,希望您能给我点个赞,谢谢!