背景
以ChatGPT为代表的大语言模型服务在2023年初开始大规模爆发,AI技术从来没有如此接近普通民众。随着以Microsoft, Google, Meta (Facebook)为代表的科技巨头在AI技术领域相继发布重量级产品和服务,国内一众科技公司如百度,阿里,讯飞等也相继跟进,全球开源界(包括知名大学,AI初创公司等)呈现百家争鸣,技术成果百花齐放的局面。当前基于大语言模型的公有服务普遍以网页或API方式提供AI能力。同时,也要关注到还有很多需要离线应用AI能力的行业和场景,比如:
- 无公共网络接入的场所(偏远地区,灾难地区,航天深空空间等)
- 隐私敏感和数据安全领域(政务,医疗,法律,金融,科技等)
- 国防军事应用领域
本文将探讨私有化部署ChatGPT的可行方案。
一些缩写词汇
| 缩写 | 词汇解释 |
|---|---|
| GPT | Generative Pre-trained Transformer,生成式预训练转换器,一种自然语言处理的技术实现 |
| LLM | Large Language Model, 大型语言模型, 它可以被想象为一个黑盒子,这个黑盒子的输入是一段文字,输出也是一段文字 |
| LoRA | Low-Rank Adaptation (LoRA), Microsoft 于2021 年推出的一项新技术,用于微调大型语言模型(LLM) |
ChatGPT相关概念
ChatGPT是什么
ChatGPT是美国OpenAI公司发布的一个网页对话应用(不对中国大陆开放)。它摆脱了以前聊天机器人给人以“人工智障”的印象,能够流畅地与人对话,处理任何语言相关的任务。2022年11月发布以来,5天用户破百万,目前用户超过16亿,是有史以来用户增长最快的互联网服务。
ChatGPT本质上是大语言模型(LLM)的应用,当前最新版本基于GPT-4模型,也是目前最先进的大语言模型服务。跟它类似的服务还有
| 服务名 | 所属公司 | 简介 |
|---|---|---|
| Claude | Anthropic | 目前效果仅次于GPT-4的LLM服务 |
| 讯飞星火 | 科大讯飞 | 优秀的中文LLM服务 |
| 文心一言 | 百度 | 最先发布的中文LLM服务 |
为了便于理解,本文中用ChatGPT来指代大语言模型。私有化部署ChatGPT本质是离线部署和应用大语言模型。
LLM是什么
大型语言模型是深度学习的一个子集,可以预训练并进行特定目的的微调。这些模型经过训练,可以解决诸如文本分类、问题回答、文档摘要、跨行业的文本生成等常见语言问题。然后,可以利用相对较小的领域数据集对这些模型进行定制,以解决零售、金融、娱乐等不同领域的特定问题。
大型语言模型的三个主要特征是:大型、通用性和预训练微调。
- "大型"既指训练数据集的巨大规模,也指参数的数量。
- "通用性"意味着这些模型足够解决常见问题。
- "预训练和微调"是指用大型数据集对大型语言模型进行一般性的预训练,然后用较小的数据集对其进行特定目的的微调。
使用大型语言模型的好处包括:
- 一种模型可用于不同的任务;
- 微调大型语言模型需要的领域训练数据较少;
- 随着数据和参数的增加,大型语言模型的性能也在持续增长.
可以做个简单的比喻,ChatGPT相当于一个大学本科生,拥有出色的语言能力,拥有2021年9月之前互联网上所有公开的知识。如果给它加以训练(微调),就能成为特定领域的专职助手甚至专家。如果让它能联网获取实时最新的信息,让它能使用各种工具(比如图像识别,数学计算),它甚至可以成为一个全能的助手。所以,以ChatGPT为代表的大语言模型是最有可能成为通用人工智能(AGI)的解决方案。
GitHub上有一个开源的AutoGPT项目 3个月内获得超过13万星(收藏),它展现出的正是LLM作为AGI,自主分析目标,生成计划,并一步步调用外部工具来实现目的的能力。
LLM私有化部署
私有化部署类ChatGPT服务,需要考虑三个主要的因素:LLM模型,计算资源,上层应用。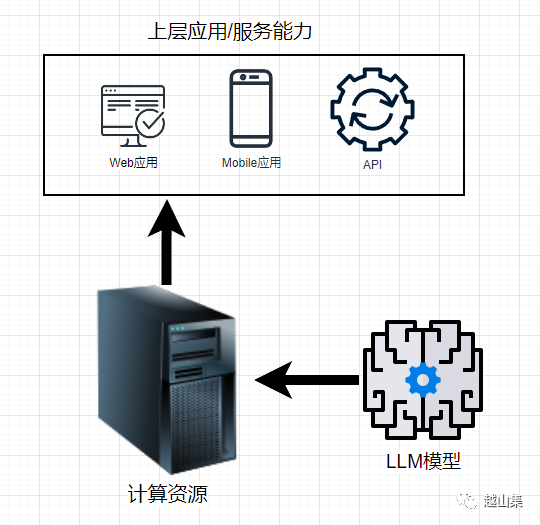
LLM模型准备
使用商用LLM
就跟云计算厂商支持部署私有云一样,商用LLM比如百度的文心一言,阿里的通义千问等都会支持私有部署。
自训练LLM
因为算力需求太大,一般企业和组织不可能从头自训练大语言模型。
BERT, T5和GPT是三种具有代表性的预训练语言模型路径。
- BERT:BERT是一个预训练的Transformer编码器,它使用了一种称为掩码语言模型的训练策略。在训练过程中,BERT会随机掩盖输入句子中的一些词,然后试图预测这些被掩盖的词。这种方法使得BERT可以看到上下文的两边,因此它能更好地理解词的含义和句子的结构。然而,BERT不是一个生成式模型,它更适合用于分类、实体识别等任务。
- T5:T5是一个预训练的Transformer模型,它将所有NLP任务都视为文本到文本的转换问题。在训练过程中,T5会接收一段包含任务描述的输入文本,并生成相应的输出文本。这种方法使得T5可以用同一种方式处理各种不同的NLP任务,包括翻译、摘要、问答等。T5的这种设计使其在许多NLP任务上都表现出色。
- GPT:GPT是一个生成式的预训练模型,它使用了一个单向的Transformer架构。在训练过程中,GPT试图预测给定上下文中的下一个词,这被称为自回归语言建模。这种方法使得GPT在生成连贯和流畅的文本方面表现出色,但它只能从左到右看到上下文,无法看到后续的词。
大语言模型进化树 via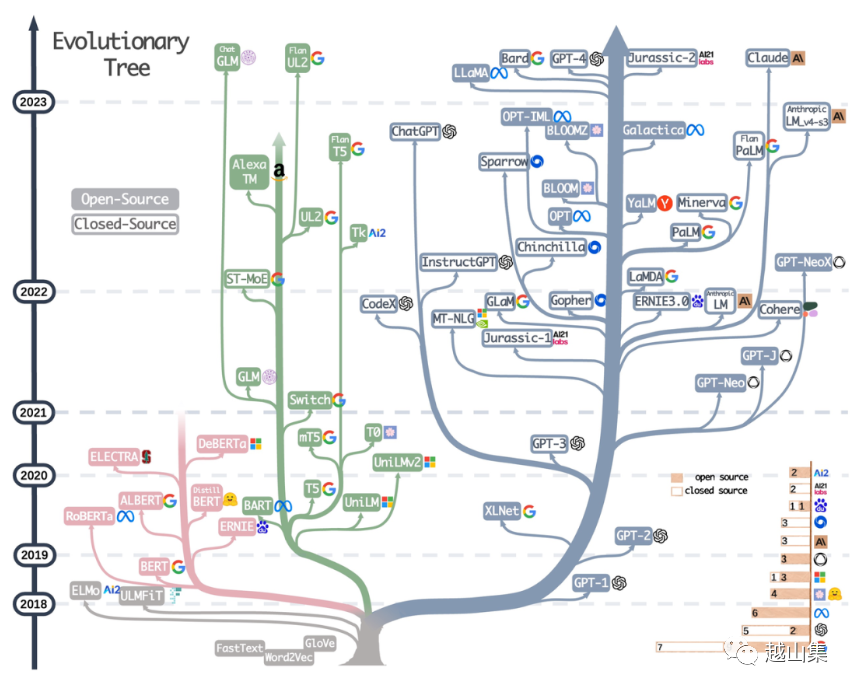
虽然模型训练方式的相关论文都是公开的,但训练模型所需要的深度学习工程技术,计算资源和训练数据都有相当高的门槛。比如微软Azure为OpenAI开发的超级计算机,具有超过28.5万个CPU核心、1万个GPU和400GB/s的GPU服务器网络传输带宽。根据英伟达的数据,使用单个Tesla架构的V100 GPU (32G显存) 对1746亿参数的GPT-3模型进行一次训练,需要用288年时间。据测算训练一次1746亿参数的GPT-3模型,所需花费的算力成本超过460万美元。
 PFlop/s-day 表示以每秒一千万亿次浮点计算能力跑24小时
PFlop/s-day 表示以每秒一千万亿次浮点计算能力跑24小时
使用开源LLM
为促进研究和应用的发展,一些大公司或组织开源了自家的大语言模型,包括OPT、BLOOM、LLaMA, Dolly2,GPT-2, GPT-J等。其中Meta公司开源的LLaMa影响较大,在此基础上,微调出了许多表现更优的LLM,包括Stanford Alpaca,Vicuna, GPT4All, Chinese-LLaMA-Alpaca等。开源中文大语言模型主要有清华大学的GLM-130B, ChatGLM-6B, 复旦大学的MOSS, 哈工大的LAC等。
插播一点无用的知识,2023年2月份Meta发布LLaMa (Large Language Model Meta AI)以来,以美洲无峰驼命名的LLM层出不穷。”草泥马“名字不够用了,还可以用其它动物。比如华中师范大学和商汤的开源中文大语言模型「骆驼」(Luotuo), 哈工大基于中文医学知识的LLaMA微调模型,命名为华驼。

使用开源预训练LLM,加高质量数据进行微调训练 (Instruct微调或LoRa微调)得到新的LLM,是目前最常见的LLM准备方案。
使用开源LLM面临的问题
模型的许可问题
开源不等于免费,免费不等于可以任意使用。在使用开源模型前,特别是用于商业目的,需要研究清楚对应的开源许可证说明。比如中文能力不错的ChatGLM-6B商用需要180万/年。表现不错的Vicuna虽然是Apache2.0许可,但二次训练它的数据来源于GPT-3.5, 而OpenAI使用条款中声明不允许用其生成的数据来训练与OpenAI竞争的产品。而Dolly2的MIT是最宽松的,其数据也是Databricks自家员工准备的,所以他们敢宣称Dolly2是第一个真正开源的LLM。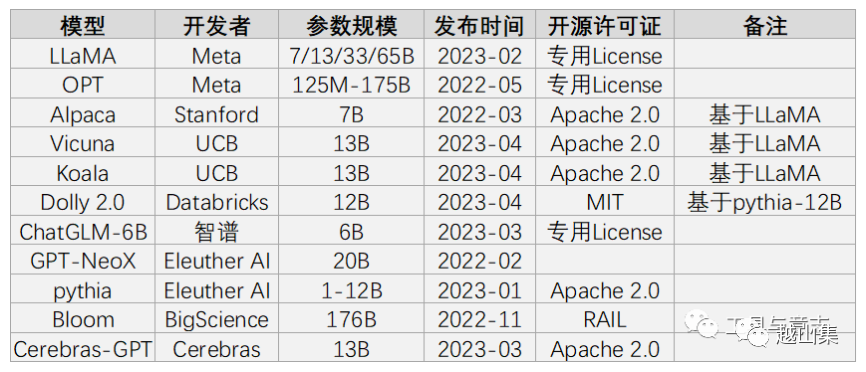 via
via
如果涉及商用,请一定重视软件许可问题。
模型效果不确定
各个LLM模型效果不一,业内目前也还没有统一的评价LLM模型效果的标准。可以确定的是,开源模型通用效果肯定不及闭源的商业服务,但开源技术日新月异,新的模型层出不穷。而如果把具体应用定位到特定场景,比如只需要服装店客服能力,或者只需要辅助办公提取周报概要,那微调训练一个满足需求的模型难度不大。UC伯克利打造的大模型Chatbot Arena排行榜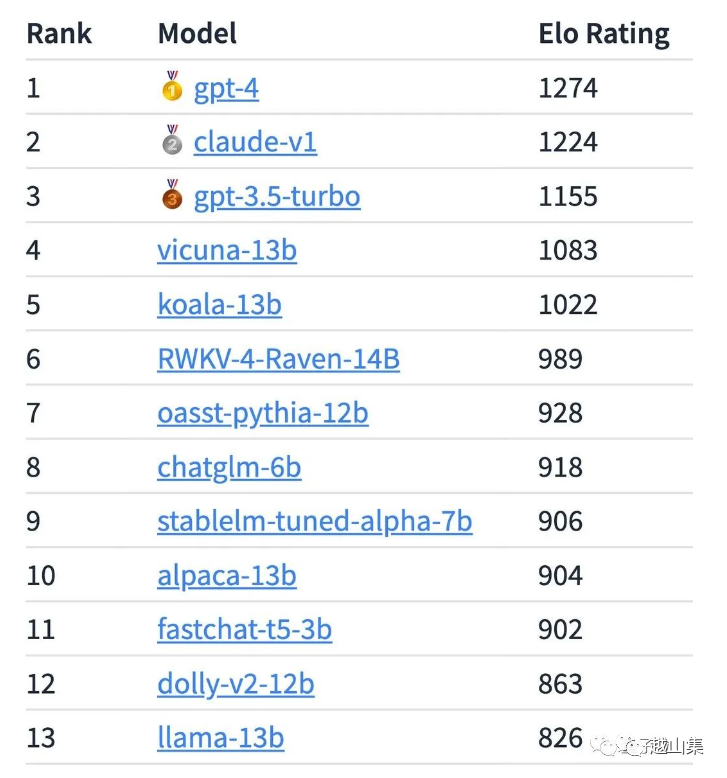
中文能力不足
主流的LLM还是以英文为主。要想LLM有优秀的中文表现能力,需要在数据和训练方法上做改进。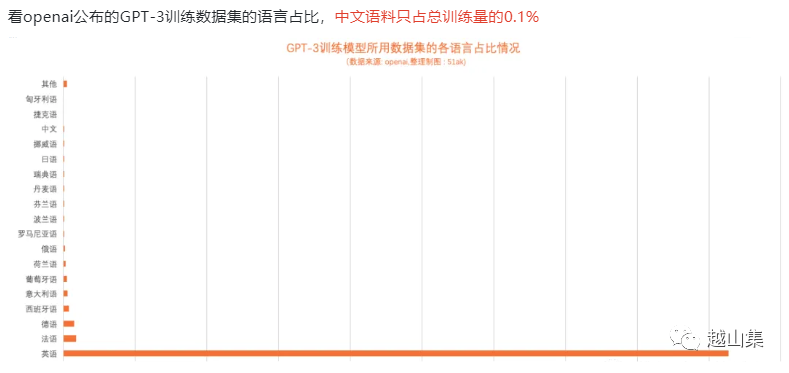
- 数据: 首先,我们需要大量的高质量中文数据来训练模型,对模型的性能有直接影响。目前公开可用的中文数据集相对于英文数据集可能数量和类型较少。因此,需要积极寻找、整理、甚至自行收集多样性的中文数据,包括但不限于新闻报道、社交媒体帖子、文学作品、学术文章等。对于中文数据的清洗和预处理也十分重要,如中文分词、去除无关符号等,以适应中文语法和结构的差异。
- 训练方法: 除了采用LLM通常使用的预训练+微调的训练流程外,我们还需要针对中文特性进行特定的优化。例如,由于中文无空格分隔字词,可能需要采用适合中文的Tokenization方法,如基于词汇的Tokenization。另外,由于中文存在大量多义词和短语,可能需要在模型注意力机制或嵌入层进行特定调整。最后,为验证模型效果,需在中文任务和数据集上进行充分测试和调优,包括文本分类、命名实体识别、情感分析等。
缺少高质量的训练数据
大语言模型的能力提升,最关键的一环就是高质量的训练数据。做微调的数据量相对来说可以很少,比如10K量级的数据就可以做LoRA微调,对于通用的 LoRA 训练来说,通常采用的是下面的格式来训练:
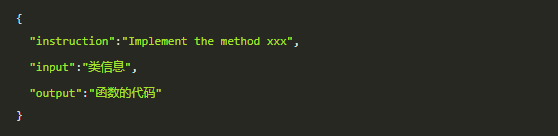
准备微调数据一般可以:
- 爬虫采集。中文互联网上抓取下来的内容质量并不高。
- 人工标注。使用脱敏后的真实数据,加人工筛选和标注。这样能保证数据质量,但成本高。
- 用ChatGPT生成。使用最先进的LLM生成特定的微调数据,质量和成本居中。
算力成本
训练和使用LLM都需要强大的算力。Nvidia GPU算力已是深度学习领域的主流需求。以ChatGLM-6B为例,它的硬件需求如下。这还只是保证能基本跑起来。要想更好的模型效果,支持更快的反应速度和更高的并发需求,加显卡。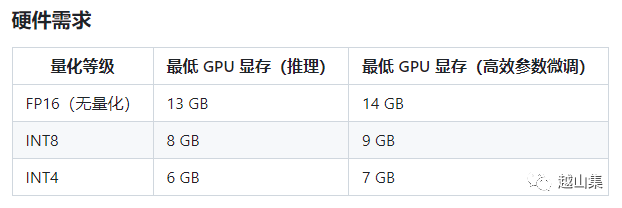
通常,深度学习模型需要GPU(图形处理单元)提供的并行处理能力来训练和推理,这样可以优化处理大量数据、矩阵运算和卷积操作等任务。虽然通过软件优化和增加数量可以在一定程度上提高CPU在深度学习中的表现,但考虑到GPU的优势,目前在深度学习中仍然首选GPU。然而,由于成本、功耗和体积等因素,某些情况下CPU仍然更优。这是一个不断发展和改进的领域,未来可能会出现更多提升CPU在深度学习中表现的方法。
在深度学习模型中,模型的参数通常以32位浮点数(float32)的形式存储。而在模型量化过程中,我们可以将这些参数转化为16位(float16)甚至8位(int8)的形式,大大减小了模型的存储空间和计算需求。
如果计算能力不足,可以折中使用量化后的模型,也就是降低计算精度以减少算力需求。就好比玩PC游戏时降低帧数和分辨率换取流畅度。
模型更新问题
私有化部署环境中,因为更为严苛的网络条件,甚至没有网络,模型更新和分发更具挑战。需要制作符合实际情况的模型更新和分发策略。
演示
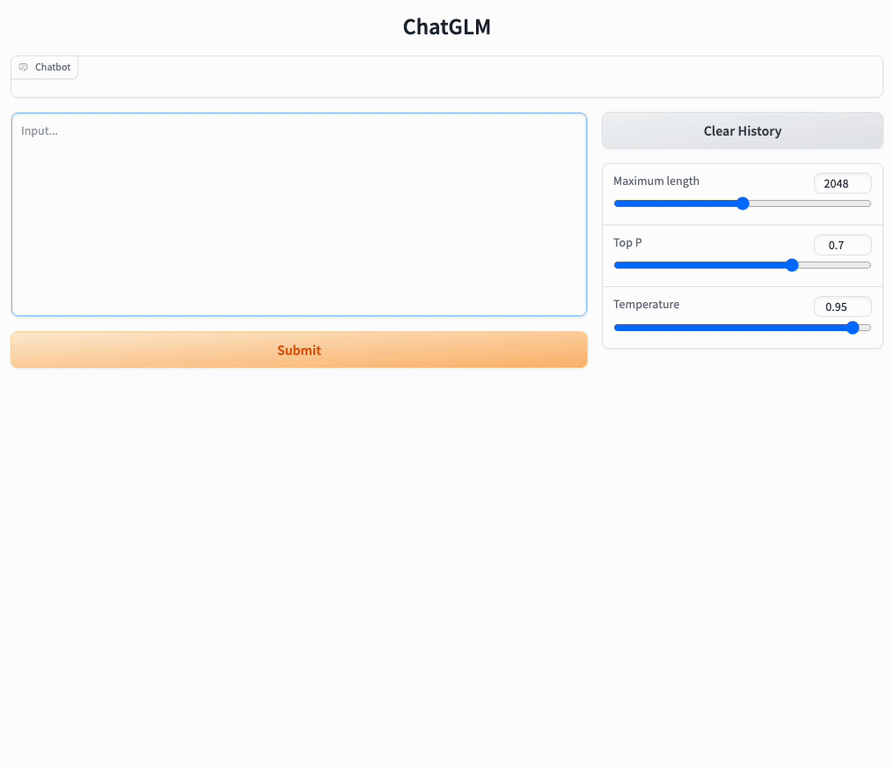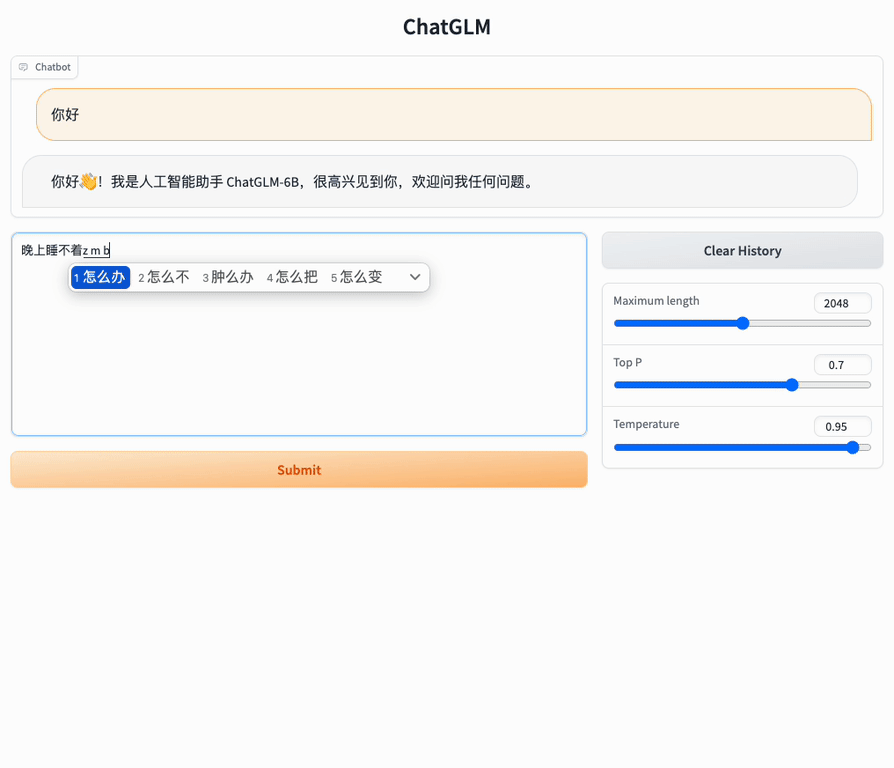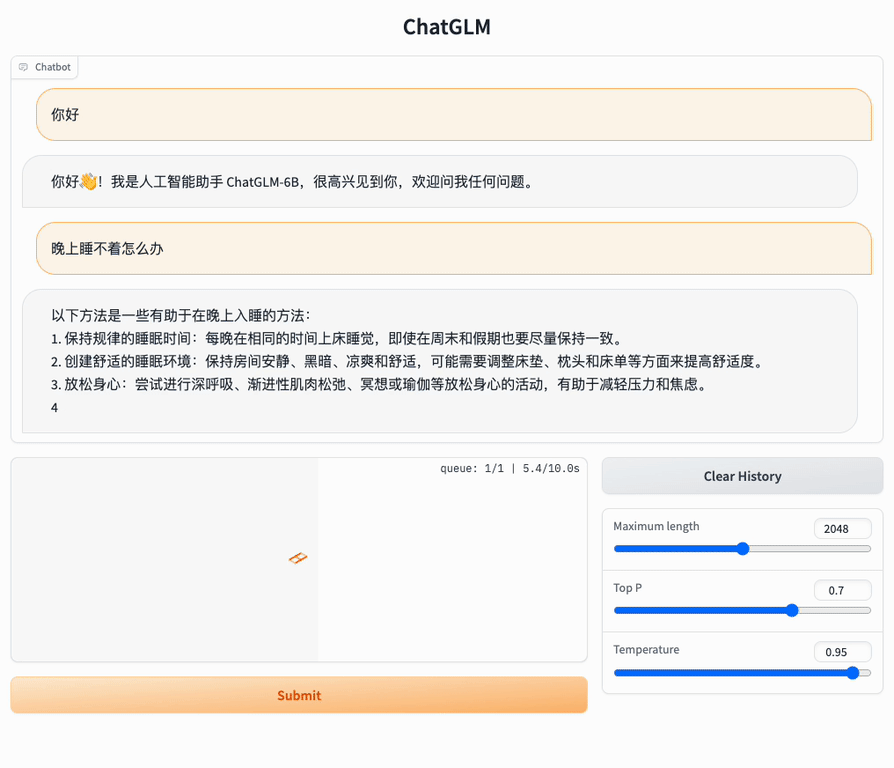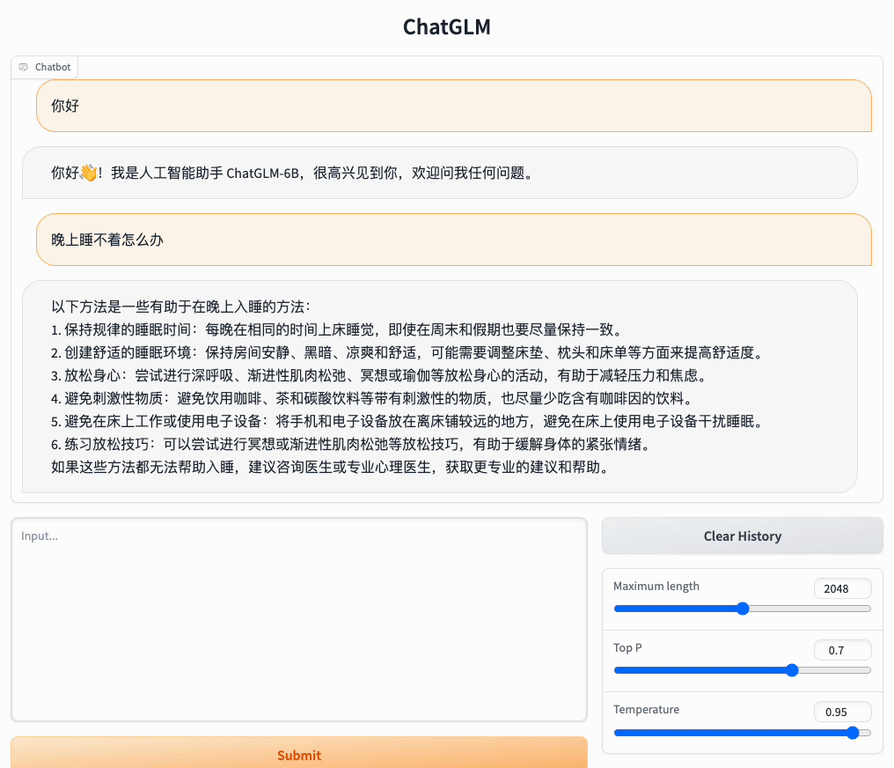
ChatGLM-6B的对话能力演示
总结
在2023年初的AI大爆发时期,ChatGPT的广泛应用极大地降低了人们使用AI的门槛。AI的民主化浪潮正在全球范围内兴起,使得普通人与经验丰富的专业人员在知识上的差距被大大缩小。在这场浪潮中,微软投资的OpenAI占据了先机,而其他国内外厂商也在紧随其后,你追我赶,频繁发布重量级AI产品。这个时刻被许多人形象地称为AI的"iPhone时刻",有人甚至认为,此轮技术更新带来的影响将超越当年Windows的发布。
科技巨头Meta(Facebook)选择了开源的道路,期望通过开源社区来提升自身的影响力和竞争力。2023年2月,Meta发布的预训练模型LLaMa成为了许多优秀大语言模型微调的基准。OpenAI也计划在近期发布重磅的开源模型。全球开源社区的活跃程度达到了前所未有的高度。尽管开源LLM的效果还有待提升,商用许可也尚未明确,但技术发展的趋势已经清晰可见。2023年5月11日,Google在其最新的Chrome浏览器中加入了WebGPU的支持,这意味着可以在浏览器中加载并离线运行LLM。未来,我们可以预见各种规格、各种功能的模型将被部署在各种计算设备上,AI能力将像水、电、气、网络一样,无处不在。
通过利用开源LLM,我们可以微调训练特定领域的LLM,并通过模型量化技术,在有限的硬件资源上实现私有化部署。
跬步千里,现在就是最好的起步时刻。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。