1. Prefix-tuning
1.背景
2021年论文《Prefix-Tuning: Optimizing Continuous Prompts for Generation》中提出了 Prefix Tuning 方法。与Full-finetuning 更新所有参数的方式不同,该方法是在输入 token 之前构造一段任务相关的 virtual tokens 作为 Prefix,然后训练的时候只更新 Prefix 部分的参数,而 Transformer 中的其他部分参数固定。主要的创新点在于对之前传统的人工构造prompt模板方式进行了改进。因为之前的人工构建的template是离散的,且针对不同的下游任务,需要构建不同的模版。而没有通用的标准去评价模板效果的优劣。所以Prefix Tuning旨在创建一种连续的可学习的模板,将prompt转换为virtual tokens embedding,并将其添加至输入中,作为输入的前缀。
2.技术原理
前缀微调(prefix-tunning),用于生成任务的轻量微调。前缀微调将一个连续的特定于任务的向量序列添加到输入,称之为前缀,如下图中的红色块所示。与提示(prompt)不同的是,前缀完全由自由参数组成,与真正的 token 不对应。相比于传统的微调,前缀微调只优化了前缀。因此,我们只需要存储一个大型 Transformer 和已知任务特定前缀的副本,对每个额外任务产生非常小的开销。
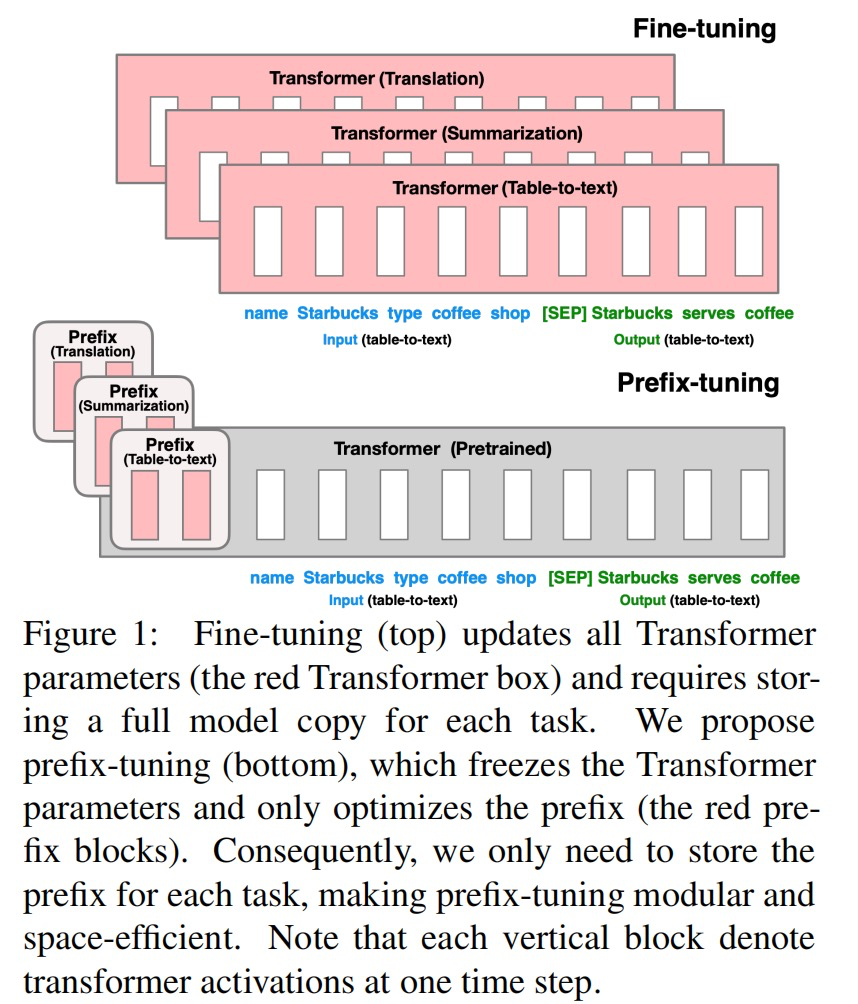
prefix-tuning技术,相对于fine-tuning,在调节模型的过程中只优化一小段可学习的continuous task-specific vector(prefix)而不是整个模型的参数。该方法其实和构造 Prompt 类似,只是 Prompt 是人为构造的“显式”的提示,并且无法更新参数,而Prefix 则是可以学习的“隐式”的提示。手动尝试最优的提示无异于大海捞针,于是便有了自动离散提示搜索的方法,但提示是离散的,神经网络是连续的,所以寻找的最优提示可能是次优的。
针对不同的模型结构,需要构造不同的Prefix。
1.针对自回归架构模型:在句子前面添加前缀,得到 z = [PREFIX; x; y],合适的上文能够在固定 LM 的情况下去引导生成下文(比如:GPT3的上下文学习)。
2.针对编码器-解码器架构模型:Encoder和Decoder都增加了前缀,得到 z = [PREFIX; x; PREFIX0; y]。Encoder端增加前缀是为了引导输入部分的编码,Decoder 端增加前缀是为了引导后续token的生成。

对于transformer的每一层 (不只是输入层,且每一层transformer的输入不是从上一层输出,而是随机初始化的embedding作为输入),都在真实的句子表征前面插入若干个连续的可训练的"virtual token" embedding,这些伪token不必是词表中真实的词,而只是若干个可调的自由参数。

为了防止直接更新 Prefix 的参数导致训练不稳定的情况,在 Prefix 层前面加了 MLP 结构(相当于将Prefix 分解为更小维度的 Input 与 MLP 的组合后输出的结果),训练完成后,只保留 Prefix 的参数。
另外,实验还对比了位置对于生成效果的影响,Prefix-tuning也是要略优于Infix-tuning的。其中,Prefix-tuning形式为 [PREFIX; x; y],Infix-tuning形式为 [x; INFIX; y]。
peft_config = PrefixTuningConfig(task_type="CAUSAL_LM", num_virtual_tokens=20)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, return_dict=True)
model = get_peft_model(model, peft_config)2. Prompt Tuning
1.背景
大模型全量微调对每个任务训练一个模型,开销和部署成本都比较高。同时,离散的prompts(指人工设计prompts提示语加入到模型)方法,成本比较高,并且效果不太好。
基于此,2021年谷歌在论文提出了《The Power of Scale for Parameter-Efficient Prompt Tuning》方法(Prompt Tuning)通过反向传播更新参数来学习prompts,而不是人工设计prompts;同时冻结模型原始权重,只训练prompts参数,训练完以后,用同一个模型可以做多任务推理。
Prompt Tuning 是中提出的微调方法。该方法可以看作是 Prefix Tuning 的简化版本,只在输入层加入 prompt tokens,并不需要加入 MLP 进行调整来解决难训练的问题,主要在 T5 预训练模型上做实验。似乎只要预训练模型足够强大,其他的一切都不是问题。作者也做实验说明随着预训练模型参数量的增加,Prompt Tuning的方法会逼近 Fine-tune 的结果。
2.技术原理
固定预训练参数,它给每个任务定义了自己的Prompt embedding,并只训练这些 embedding,然后拼接到数据上作为输入,但只在输入层加入prompt tokens,并且不需要加入 MLP 进行调整来解决难训练的问题。左图为单任务全参数微调,右图为 Prompt tuning。

对于给定的GPT模型,soft prompt embedding被初始化为一个二维矩阵,其size为(total_virtual_tokens, hidden_size)。每个任务都有它自己的矩阵(下面称为task embedding),这些矩阵相互独立。在训练过程中,整个GPT模型的参数都会被冻结,只有任务的矩阵会被更新(以gradient descent的方式)。
task embedding有两种初始化的方式:
1.随机分布
2.用现有的vocabulary embeddings初始化(即指定token,比如"请分析这句话的情感",再转换为embedding)--更推荐的方式
同时,Prompt Tuning 还提出了 Prompt Ensembling,也就是在一个批次(Batch)里同时训练同一个任务的不同 prompt(即采用多种不同方式询问同一个问题),这样相当于训练了不同模型,比模型集成的成本小多了。

Prompt Tuning 论文中还探讨了 Prompt token 的初始化方法和长度对于模型性能的影响。通过消融实验结果发现,与随机初始化和使用样本词汇表初始化相比,Prompt Tuning采用类标签初始化模型的效果更好。不过随着模型参数规模的提升,这种gap最终会消失。
Prompt token 的长度在20左右时的表现已经不错(超过20之后,提升Prompt token长度,对模型的性能提升不明显了),同样的,这个gap也会随着模型参数规模的提升而减小(即对于超大规模模型而言,即使 Prompt token 长度很短,对性能也不会有太大的影响)。
对于T5的XXL的model来说,全量的model tuning每个下游任务需要11B的参数量,用prompt tuning只需要20480个参数。需要注意跟prefix-tuning不同点:这里的prompt-tuning没有包含中间层的prefix,也没有对下游任务的输出网络进行修改。在prefix-tuning中使用了MLP进行prefix的reparameter。
class PromptEmbedding(torch.nn.Module):
......
def forward(self, indices):
# Just get embeddings
prompt_embeddings = self.embedding(indices)
return prompt_embeddings






![[JS]对象](https://img-blog.csdnimg.cn/img_convert/d11c90b3175d4a4d3bb29625a244659a.png)