1. 官方文档
collections --- 容器数据类型 — Python 3.12.4 文档
Python 的 collections 模块提供了许多有用的数据类型(包括 OrderedDict、Counter、defaultdict、deque 和 namedtuple)用于扩展 Python 的标准数据类型。掌握 collections 中的数据类型可以丰富你的编程工具包。
2. deque
Python中,在列表对象的左侧进行追加和弹出操作效率低下,时间复杂度为O(n),如果是大型列表,这些操作的开销会特别大,因为必须将所有的项都向右移动,以便在列表的开头插入新项。另一方面,列表右侧的追加和弹出操作通常是高效的O(1),除非 Python 需要重新分配内存以增加列表以接受新项。
Python 的 deque 就是为了克服这个问题而创建的。deque(该名称的发音为 "deck",是 "double-ended queue" 双端队列的简写形式) 是 collections 中的第一个数据结构。这种类似序列的数据类型,是堆栈和队列的泛化,旨在支持在数据结构两端高效的追加和弹出操作。在 deque 对象的两边进行追加和弹出操作是稳定且同样高效的,因为 deque 是作为一个双链表实现的。
以队列为例(以先进先出 FIFO 的方式管理条目),它的工作原理类似于一个管道,在管道的一端放入新项目,在另一端弹出旧项目。将项目添加到队列的末尾称为入队 enqueue,从队列的最前端删除一个项目称为出队 dequeue。
2.1 创建 deque
deque 初始化器接受两个可选参数:Iterable(一个可迭代对象)和 maxlen(一个整数,指定队列的最大长度)。如果不提供 iterable,则将会得到一个空的 deque;如果为 maxlen 提供一个值,那么 deque 最多只能存储 maxlen 项。

from collections import deque
# Use different iterables to create deques
deque((1, 2, 3, 4))
# deque([1, 2, 3, 4])
deque([1, 2, 3, 4])
# deque([1, 2, 3, 4])
deque("abcd")
# deque(['a', 'b', 'c', 'd'])
deque()
# deque([])
在某些场景下,需要维护一个固定长度的队列,比如保存最近的 N 个日志记录,或者限制缓存中的数据量,这时使用 maxlen 参数就会非常方便。
from collections import deque
recent_files = deque(["core.py", "README.md", "__init__.py"], maxlen=3)
recent_files.appendleft("database.py")
print(recent_files)
# deque(['database.py', 'core.py', 'README.md'], maxlen=3)
recent_files.appendleft("requirements.txt")
print(recent_files)
# deque(['requirements.txt', 'database.py', 'core.py'], maxlen=3)2.2 属性和方法
deque 为.append()、.pop()和.extend()提供了姊妹方法,即带后缀left,表明它们在 deque 的左端执行相应的操作。
| 属性 | 说明 |
| maxlen | Deque 的最大尺寸,如果没有限定的话就是 None 。 |
| 方法 | 说明 |
| append(x) | 添加 x 到右端。 |
| appendleft(x) | 添加 x 到左端。 |
| pop() | 移去并且返回一个元素,deque 最右侧的那一个。 如果没有元素的话,就引发一个 IndexError。 # Unlike lists, deque doesn't support .pop() with arbitrary indices |
| popleft() | 移去并且返回一个元素,deque 最左侧的那一个。 如果没有元素的话,就引发 IndexError。 |
| extend(iterable) | 通过添加 iterable 参数中的元素扩展 deque 的右侧。 |
| extendleft(iterable) | 通过添加 iterable 参数中的元素扩展 deque 的左侧。 注意,左添加时,在结果中 iterable 参数中的顺序将被反过来添加。 |
| index(x[, start[, stop]]) | 返回 x 在 deque 中的位置(在索引 start 之后,索引 stop 之前)。 返回第一个匹配项,如果未找到则引发 ValueError。 deque 支持使用 index 访问 deque 中的元素,但是不支持切片如 [2:5],在链表上执行切片操作效率很低,因此该操作不可用。 |
| insert(i, x) | 在位置 i 插入 x 。 |
| count(x) | 计算 deque 中元素等于 x 的个数。 |
| remove(value) | 移除找到的第一个 value。 如果没有的话就引发 ValueError。 |
| copy() | 创建一份浅拷贝。 |
| clear() | 移除所有元素,使其长度为0. |
| reverse() | 将deque逆序排列。返回 None 。 |
| rotate(n=1) | 向右循环移动 n 步。 如果 n 是负数,就向左循环。 如果deque不是空的,向右循环移动一步就等价于 d.appendleft(d.pop()) , 向左循环一步就等价于 d.append(d.popleft()) 。 |
(1)matlen\index
from collections import deque
q = deque(["first", "second", "third"])
print(q[1])
# second
print(numbers.maxlen)
# None
# 切片引发 TypeError
# q[0:2]
## TypeError: sequence index must be integer, not 'slice'(2)extend\extendleft\insert
# Extend an existing deque
numbers = deque([1, 2])
numbers.extend([3, 4, 5])
print(numbers)
# deque([1, 2, 3, 4, 5])
numbers.extendleft([-1, -2, -3, -4, -5])
print(numbers)
# deque([-5, -4, -3, -2, -1, 1, 2, 3, 4, 5])
# Insert an item at a given position
numbers.insert(5, 0)
print(numbers)
# deque([-5, -4, -3, -2, -1, 0, 1, 2, 3, 4, 5])(3)rotate
from collections import deque
q = deque(["first", "second", "third", "fourth", "fifth"])
q.rotate()
print(q)
# deque(['fifth', 'first', 'second', 'third', 'fourth'])
q.rotate(2)
print(q)
# deque(['third', 'fourth', 'fifth', 'first', 'second'])
q.rotate(-1)
print(q)
# deque(['fourth', 'fifth', 'first', 'second', 'third'])
q.rotate(-2)
print(q)
# deque(['first', 'second', 'third', 'fourth', 'fifth'])2.3 应用
模拟买票队列:创建 deque、使用 popleft 和 append 方法添加和删除条目
假设你正在模拟一排等待买票看电影的人,可以用 deque 来实现:每次有新人到来时,让他们加入排队;当排在队伍前面的人拿到票时,让他们离开队伍。
from collections import deque
ticket_queue = deque()
print(ticket_queue)
# deque([])
# 使用 append
# People arrive to the queue
ticket_queue.append("Jane")
ticket_queue.append("John")
ticket_queue.append("Linda")
print(ticket_queue)
# deque(['Jane', 'John', 'Linda'])
# 使用 popleft
# People bought their tickets
ticket_queue.popleft()
# 'Jane'
ticket_queue.popleft()
# 'John'
ticket_queue.popleft()
# 'Linda'
print(ticket_queue)
# deque([])
# 空队列调用 popleft 报错,引发 IndexError
# No people on the queue
# ticket_queue.popleft()
## IndexError: pop from an empty deque
3. defaultdict
在 Python 中使用字典时,一个常见问题是如何处理不存在的键(missing keys)。直接访问一个在给定字典中不存在的键,会引发 KeyError。有几种方法可以解决此问题:
(1)使用 .setdefault() 方法:dict.setdefault(key, default=None)
如果这个键不存在,创建一个键,并将默认值设置为这个键的值;如果这个键已经存在,返回这个键的值,不会做任何修改。
(2)使用 .get() 方法:dict.get(key, default=None)
如果这个键不存在,返回一个默认值,但不会改变原字典,不会创建键值对。
d = {"pet": "dog", "color": "blue", "language": "Python"}
# d["fruit"]
# KeyError: 'fruit'
d.setdefault("fruit", "orange")
# 'orange'
d
# 新增键值对 furit-orange
# {'pet': 'dog', 'color': 'blue', 'language': 'Python', 'fruit': 'orange'}
d.setdefault("color", "orange")
# 'blue'
d
# 无变化
# {'pet': 'dog', 'color': 'blue', 'language': 'Python', 'fruit': 'orange'}
d.get("name", "nothing")
# 'Andy'
d.get("color", "noting")
# 'blue'
3.1. 创建 defaultdict
由于处理字典中不存在的键是一种常见需求,Python collections 模块为此提供了一个工具:defaultdict,defaultdict 是 dict 的子类,可以像使用 dict 一样使用 defaultdict。
defaultdict 的构造函数接受一个函数对象作为它的第一个参数 default_factory(默认为 None), 所有其他参数(包括关键字参数)都相当于传递给 dict 的构造函数。
defaultdict 将此参数存储在 .default_factory 属性中,重写 .__missing__()。在访问一个不存在的键时,defaultdict 会自动调用 default_factory,不带参数,为此键创建一个合适的默认值,这个值和 key 作为一对键值对被插入到字典中,并作为本方法的返回值返回。

可以使用任何可调用对象作为构造函数的输入参数,比如 int()、list()。
a = defaultdict(int)
a['1']
a
# defaultdict(int, {1: 0})
# 创建 default 实例时没有提供参数
# b = defaultdict()
# b['1']
# b
# KeyError: '1'3.2 应用
3.2.1 使用 int 作为 default_factory -- 计数
函数 int() 总是返回 0,使用 int 函数作为 default_factory 可以使 defaultdict 具有计数功能:当第一次遇到某个 key 时,查询失败,则 default_factory 会调用 int() 来提供一个整数 0 作为默认值,后续的自增操作将建立起对每个 key 的计数。
假设有一组关于宠物信息的原始数据,是一个以元组为元素的列表,每个元组中有两项:宠物的类型和名字。现在想整理原有信息,汇总每种宠物类型下有几只宠物。
from collections import defaultdict
from time import perf_counter
pets = [
("dog", "Affenpinscher"),
("dog", "Terrier"),
("dog", "Boxer"),
("cat", "Abyssinian"),
("cat", "Birman"),
]
counter = defaultdict(int)
for pet,name in pets:
counter[pet] += 1
print(counter)
# defaultdict(<class 'int'>, {'dog': 3, 'cat': 2})3.2.2 使用 list 作为 default_factory -- 分组
使用 list 函数作为 default_factory 可以很轻松地将(键-值对组成的)序列转换为(键-列表组成的)字典。还是上面的例子,如果想整理原有信息,汇总每种宠物类型下,具体有哪些宠物,可以考虑使用以 list() 为输入参数的 defaultdict。当第一次遇见某个 key 时,它还没有在字典里面,自动创建条目,即调用 default_factory 方法,返回一个空的 list,然后用 list.append() 操作添加值到这个新的列表里。当再次存取该键时,就正常操作,用 list.append() 添加另一个值到列表中。
from collections import defaultdict
pets = [
("dog", "Affenpinscher"),
("dog", "Terrier"),
("dog", "Boxer"),
("cat", "Abyssinian"),
("cat", "Birman"),
]
group_pets = defaultdict(list)
for pet, breed in pets:
group_pets[pet].append(breed)
for pet, breeds in group_pets.items():
print(pet, "->", breeds)
# dog -> ['Affenpinscher', 'Terrier', 'Boxer']
# cat -> ['Abyssinian', 'Birman']使用 setdefault 也可以实现上述需求,不过使用 defaultdict 代码更简洁,速度也更快。
from collections import defaultdict
from time import perf_counter
pets = [
("dog", "Affenpinscher"),
("dog", "Terrier"),
("dog", "Boxer"),
("cat", "Abyssinian"),
("cat", "Birman"),
]
s1 = perf_counter()
group_pets1 = {}
for pet, breed in pets:
group_pets1.setdefault(pet, []).append(breed)
e1 = perf_counter()
t1 = e1 - s1
s2 = perf_counter()
group_pets2 = defaultdict(list)
for pet, breed in pets:
group_pets2[pet].append(breed)
e2 = perf_counter()
t2 = e2 - s2
print(t1, t2)
# 6.529991514980793e-05 6.0999998822808266e-054. OrderedDict
有时需要字典记住键值对插入的顺序,例如,需要按照添加顺序来记录用户的操作记录,或者需要按照添加顺序来记录日志信息等。Python 的 OrderedDict 是一个有序的字典,它将键值对按照插入顺序进行排序。相比于普通字典,OrderedDict 可以保证元素的顺序不变,普通字典的元素顺序是不确定的。
OrderedDict 迭代键和值的顺序与键首次插入字典的顺序相同;如果将新值分配给现有键,则键-值对的顺序保持不变;如果条目被删除并重新插入,那么它将被移动到字典的末尾。
OrderedDict 在 Python 3.1 中引入,继承自dict类,它的接口基本上与 dict 相同,可以直接使用 dict 类的方法和属性,同时也支持其他 Python 标准库中使用字典的方法和属性。
Python 3.6 引入了 dict 的新实现,该实现提供了一个意想不到的新特性:常规字典中键值对的顺序与其第一次插入的顺序相同。最初,这一特性被视为实现细节,文档建议不要依赖它,不过,从 Python 3.7 开始,该特性正式成为语言规范的一部分。这种情况下,使用 OrderedDict 的意义是什么呢?
OrderedDict 的一些特性仍然使它很有价值:
- 体现意图:使用 OrderedDict,能够清楚地表明字典中项的顺序是重要的,传达出代码需要或依赖于字典中项的顺序这一信息。
- 调整项的顺序:OrderedDict 可以通过访问 .move_to_end() 方法,操作字典中键值对的顺序;还可以使用 .popitem() ,从字典的两端删除键值对。对于常规的 dict,使用 d.popitem() 等同于 OrderedDict 的 od.popitem(last=True),其保证会返回最右边(最后)的项。
- 相等性测试顺序敏感:两个 OrderedDict 之间的相等性测试会考虑条目的顺序。如果有两个有序的字典,它们具有相同的一组键值对,但顺序不同,那么这两个字典仍会被认做不相等。
- 向后兼容性:如果依靠常规的 dict 对象维持项的顺序,在 Python 3.6 之前版本中运行代码时,有可能违背初始意图。
4.1 创建 OrderedDict

可以在不带参数的情况下实例化类(空的有序字典),然后根据需要插入键值对。当迭代字典时,得到键值对的顺序与它们插入字典的顺序相同。事实上,保证项的顺序是 OrderedDict 主要需要解决的问题。
from collections import OrderedDict
life_stages = OrderedDict()
life_stages["childhood"] = "0-9"
life_stages["adolescence"] = "9-18"
life_stages["adulthood"] = "18-65"
life_stages["old"] = "+65"
for stage, years in life_stages.items():
print(stage, "->", years)
# childhood -> 0-9
# adolescence -> 9-18
# adulthood -> 18-65
# old -> +654.2 属性和方法
4.2.1 使用 move_to_end 方法调整顺序
.move_to_end() 可用来移动项目,对字典元素重新排序,.move_to_end() 接受一个名为 last 的可选参数,该参数控制要将项移动到字典的哪一端。
from collections import OrderedDict
letters = OrderedDict(b=2, d=4, a=1, c=3)
print(letters)
# OrderedDict([('b', 2), ('d', 4), ('a', 1), ('c', 3)])
# Move b to the right end
letters.move_to_end("b")
print(letters)
# OrderedDict([('d', 4), ('a', 1), ('c', 3), ('b', 2)])
# Move b to the left end
letters.move_to_end("b", last=False)
print(letters)
# OrderedDict([('b', 2), ('d', 4), ('a', 1), ('c', 3)])
# Sort letters by key
for key in sorted(letters):
letters.move_to_end(key)
print(letters)
OrderedDict([('a', 1), ('b', 2), ('c', 3), ('d', 4)])4.2.2 使用 popitem 方法删除首(尾)键值对
from collections import OrderedDict
d1 = {"a": 1, "b": 2, "c": 3, "d": 4}
d2 = OrderedDict(d1)
d1.popitem()
print(d1)
{'a': 1, 'b': 2, 'c': 3}
d2.popitem(last=False)
print(d2)
# OrderedDict([('b', 2), ('c', 3), ('d', 4)])
d2.popitem()
print(d2)
# OrderedDict([('b', 2), ('c', 3)])4.2.3 相等性测试 equality test
from collections import OrderedDict
# Regular dictionaries compare the content only
letters_0 = dict(a=1, b=2, c=3, d=4)
letters_1 = dict(b=2, a=1, d=4, c=3)
print(letters_0 == letters_1)
# True
# Ordered dictionaries compare content and order
letters_0 = OrderedDict(a=1, b=2, c=3, d=4)
letters_1 = OrderedDict(b=2, a=1, d=4, c=3)
print(letters_0 == letters_1)
# False
letters_2 = OrderedDict(a=1, b=2, c=3, d=4)
print(letters_0 == letters_2)
# True5. namedtuple
对于常规元组,使用索引访问元组中的值很烦人,难以读取,而且容易出错。特别是,元组中元素较多,且使用位置与元组创建的位置较远时,查看第 i 项是什么内容需要频繁翻页,十分麻烦。
namedtuple 是一个工厂函数,工厂函数是一种创建对象的函数,但本身并不返回任何值,而是返回一个用于创建对象的函数。namedtuple 用于创建带有命名字段的元组,有了这些字段,可以用点表示法直接访问此命名元组中的值,就像 obj.attr。与常规元组相比,由 namedtuple 构建的元组子类在代码可读性方面具有很大的优势。
5.1 使用 namedtuple

要使用 namedtuple() 创建新的元组子类,需要两个必需的参数:
- Typename 是正在创建的类的名称,必须是一个有效的 Python 标识符字符串;
- Field_names 是用于访问元组中的项的字段名列表。它可以是:字符串的可迭代对象,如 ["field1", "field2",…“fieldN”]、用空格分隔字段名的字符串,如 "field1 field2…"fieldN”、由逗号分隔的字段名组成的字符串,如 "field1, field2,…", fieldN”
使用 namedtuple() 创建命名元组子类示例
在下面的示例中,首先使用 namedtuple 创建 Point,然后实例化 Point 来创建一个 Point 对象 point,可以通过字段名和索引访问 point 中的两个元素。其余的示例展示了如何使用 ‘由逗号分隔的字段名字符串’、生成器表达式和 ‘由空格分隔的字段名字符串’ 创建等效的命名元组。
from collections import namedtuple
# 1. Use a list of strings as field names
Point = namedtuple("Point", ["x", "y"])
point = Point(2, 4)
print(point)
# Point(x=2, y=4)
point.x # Access the coordinates
# 2
point.y
# 4
point[0]
# 2
# 2. Use a generator expression as field names
Point = namedtuple("Point", (field for field in "xy"))
Point(2, 4)
# Point(x=2, y=4)
# 3. Use a string with comma-separated field names
Point = namedtuple("Point", "x, y")
Point(2, 4)
# Point(x=2, y=4)
# 4. Use a string with space-separated field names
Point = namedtuple("Point", "x y")
Point(2, 4)
# Point(x=2, y=4)为了更好地理解代码可读性问题,考虑 divmod() 这个内置函数,它接受两个数字,并返回一个元组,其中包含输入的两个数字做整数除法得到的商和余数,如 divmod(12, 5) 的返回值为:(2,2),在这个结果中,两个位置分别是什么含义并不明确,可以应用 namedtuple 对此加以完善。
from collections import namedtuple
def custom_divmod(x, y):
DivMod = namedtuple("DivMod", "quotient remainder")
return DivMod(*divmod(x, y))
result = custom_divmod(12, 5)
print(result)
# DivMod(quotient=2, remainder=2)
result.quotient
# 2
result.remainder
# 25.2 属性和方法
除了继承自元组的方法,命名元组还支持三个额外的方法(_make\_asdict\_replace)和两个属性(_fields\_field_defaults),为了防止字段名冲突,方法和属性以下划线开始。
| 方法 | 说明 |
| _make(iterable) | 基于已存在的序列或迭代实例创建一个新实例。 |
| _asdict() | 返回一个新的 dict ,字段名称映射到对应的值。 |
| _replace(**kwargs) | 返回一个新的命名元组实例,并将指定字段替换为新的值。 注:此方法不会就地更新元组,而是返回新的命名元组,新值存储在相应的字段中。 |
| 属性 | 说明 |
| _fields | 字符串元组,列出字段名,可用于基于当前元组创建一个新的命名元组。 |
| _field_defaults | 字典,将字段名称映射到默认值。 |
from collections import namedtuple
Person = namedtuple("Persion", ("name", "age", "job"), defaults=("15", "teacher"))
Person("Amy")
# Persion(name='Amy', age='15', job='teacher')
p1 = Person("Mary", "18", "student")
p1.name
# 'Mary'
p1._fields
# ('name', 'age', 'job')
p1._field_defaults
# {'age': '15', 'job': 'teacher'}
p1._asdict()
# {'name': 'Mary', 'age': '18', 'job': 'student'}
p1._replace(**{"age": "20"})
# Persion(name='Mary', age='20', job='student')
p1._replace(age="22")
# Persion(name='Mary', age='22', job='student')
p1._make(["Ann", "35", "doctor"])
# Persion(name='Ann', age='35', job='doctor')6. Counter
对对象进行计数是编程中常见的操作,在计算给定项在列表或可迭代对象中出现的次数时,如果清单很短,那么计算各项的频次可以很快;但如果是一个很长的清单,计数将是具挑战性的工作。
对对象进行计数时,通常使用计数器或初始值为 0 的整数变量。然后增加计数器以反映给定对象出现的次数。Python中,可以使用字典一次对几个不同的对象进行计数,用键来保存单个对象,对应的值保存此对象的重复次数或对象的计数。
下面是一个使用常规字典和 for 循环计算单词 “mississippi” 中的字母的例子:
from collections import defaultdict
word = "mississippi"
# 1. 常规字典
counter1 = {}
for letter in word:
if letter not in counter:
counter1[letter] = 0
counter1[letter] += 1
counter1
# {'m': 1, 'i': 4, 's': 4, 'p': 2}
# 2. defaultdict
counter2 = defaultdict(int)
for letter in word:
counter2[letter] += 1
counter2
# defaultdict(int, {'m': 1, 'i': 4, 's': 4, 'p': 2})6.1 使用 Counter
就像处理其他常见的编程问题一样,Python 也有一个处理计数问题的有效工具 collections.Counter,它是专门为计算对象而设计的字典子类。
Counter 类与其他语言中的 bag 或 multiset 很相似,multiset 类似于 set,但不要求元素互异,一个元素的实例数量称为它的多重性,例如 {1,1,2,3,3,3,4,4} 。
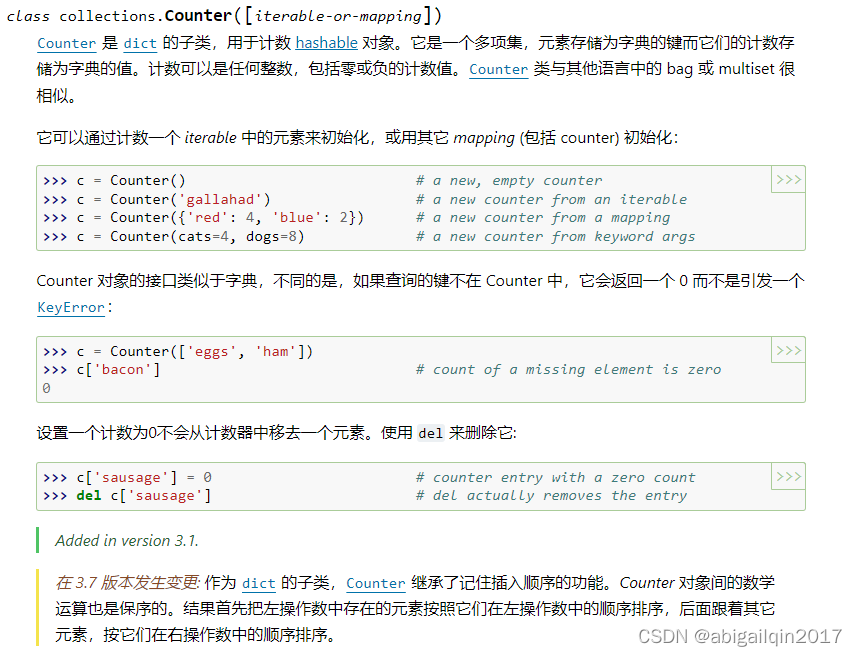
from collections import Counter
Counter("mississippi")
# Counter({'i': 4, 's': 4, 'p': 2, 'm': 1})有几种不同的方法来实例化 Counter,可以使用列表、元组或任何具有重复对象的可迭代对象,唯一的限制是这个对象需要是可哈希的。可哈希意味着这个对象有一个在其生命周期内永远不会改变的哈希值,在Python中,不可变对象也是可哈希的。这一点是必要的,因为这些对象将用作字典键。
from collections import Counter
Counter([1, 1, 2, 3, 3, 3, 4])
# Counter({3: 3, 1: 2, 2: 1, 4: 1})
# 使用不可哈希对象将报错,引发 TypeError
# Counter(([1], [1]))
# TypeError: unhashable type: 'list'6.2 方法
Counter 是 dict 的子类,它们的接口基本相同,但仍有一些微妙的区别。
- Counter 未实现 .fromkeys(),从而避免冲突:dict.fromkeys("abbbc",2) 要求每个字母的初始值为 2,而 Counter("abbbc") 要求字母对应它在可迭代对象中出现的次数。
- .update() 不会用新计数替换现有对象(键)的计数(值),而是将两者相加作为最终值。
- Counter 和 dict 的另一个区别是,访问缺失的键将返回 0,而不会引发 KeyError。
Counter 对象在对所有字典可用的方法以外还支持一些附加方法。
| 方法 | 说明 |
| elements() | 返回一个迭代器,其中每个元素将重复出现计数值所指定次。 元素会按首次出现的顺序返回。 如果一个元素的计数值小于1,elements() 将会忽略它。 c = Counter(a=4, b=2, c=0, d=-2) sorted(c.elements()) ['a', 'a', 'a', 'a', 'b', 'b'] |
| most_common([n]) | 返回一个列表,其中包含 n 个最常见的元素及出现次数,按常见程度由高到低排序。 如果 n 被省略或为 None,most_common() 将返回计数器中的 所有 元素。 计数值相等的元素按首次出现的顺序排序。 Counter('abracadabra').most_common(3) [('a', 5), ('b', 2), ('r', 2)] |
| subtract([iterable-or-mapping]) | 减去一个 可迭代对象 或 映射对象 (或 counter) 中的元素。类似于 dict.update() 但是是减去而非替换。输入和输出都可以是 0 或负数 c = Counter(a=4, b=2, c=0, d=-2) d = Counter(a=1, b=2, c=3, d=4) c.subtract(d) c # Counter({'a': 3, 'b': 0, 'c': -3, 'd': -6}) |
| update([iterable-or-mapping]) | 加上一个 可迭代对象 或 映射对象 (或 counter) 中的元素。类似于 dict.update() 但是是加上而非替换。另外,可迭代对象 应当是一个元素序列,而不是一个 (key, value) 对的序列。 |
| total() Added in version 3.10. | 计算总计数值。 c = Counter(a=10, b=5, c=0) c.total() # 15 |
| fromkeys(iterable) | 这个类方法没有在 Counter 中实现。 |
from collections import Counter
letters = Counter("mississippi")
letters
# Counter({'i': 4, 's': 4, 'p': 2, 'm': 1})
# Update the counts of m and i
letters.update(m=3, i=4)
letters
# Counter({'i': 8, 'm': 4, 's': 4, 'p': 2})
# Update with another counter
letters.update(Counter(["s", "s", "p"]))
letters
# Counter({'i': 8, 's': 6, 'm': 4, 'p': 3})
dict.fromkeys('mmpp', 2)
# {'m': 2, 'p': 2}
# Counter 没有实现 fromkeys,调用将报错
# Counter.fromkeys('mmpp', 2)
# Counter.fromkeys() is undefined. Use Counter(iterable) instead.Counter 对象支持相等性、子集和超集关系等富比较运算符: ==, !=, <, <=, >, >=。 所有这些检测会将不存在的元素当作计数值为零,因此 Counter(a=1) == Counter(a=1, b=0) 将返回真值。
from collections import Counter
inventory = Counter(dogs=23, cats=14, pythons=7)
adopted1 = Counter(dogs=2, cats=5, pythons=1)
inventory.subtract(adopted1)
inventory
# Counter({'dogs': 21, 'cats': 9, 'pythons': 6})
adopted2 = Counter(dogs=2, cats=3, pythons=1)
inventory -= adopted2
inventory
# Counter({'dogs': 19, 'cats': 6, 'pythons': 5})
new_pets1 = {"dogs": 4, "cats": 1}
inventory.update(new_pets1)
inventory
# Counter({'dogs': 23, 'cats': 7, 'pythons': 5})
new_pets2 = Counter(dogs=2, cats=3, pythons=1)
inventory += new_pets2
inventory
# Counter({'dogs': 25, 'cats': 10, 'pythons': 6})




![[AI开发配环境]VSCode远程连接ssh服务器](https://img-blog.csdnimg.cn/direct/c5304e9f50c948aca5b37bb6c49865ae.png)