本文字数:8721;估计阅读时间:22 分钟
审校:庄晓东(魏庄)
本文在公众号【ClickHouseInc】首发

在 Trip.com,我们为用户提供广泛的数字产品,包括酒店和机票预订、景点、旅游套餐、商务旅行管理和与旅行相关的内容。正如你所猜的那样,我们需要一个可扩展、可靠且快速的日志平台,这对于我们的运营至关重要。
在我们开始之前,为了激起你的好奇心,让我展示一些我们在 ClickHouse 上构建的平台的关键数据:

这篇博客文章将讲述我们日志平台的故事,包括为什么我们最初构建它、我们使用的技术,以及我们在 ClickHouse 上利用 SharedMergeTree 等功能对其未来的规划。
以下是我们在旅程中将讨论的不同主题:
-
我们如何构建一个集中的日志平台
-
我们如何扩展日志平台并从 Elasticsearch 迁移到 ClickHouse
-
我们如何改进我们的运营体验
-
我们如何在阿里云上测试 ClickHouse Cloud
为了简化,让我们把这些内容放在一个时间线上:

构建一个集中的日志平台
每个伟大的故事都始于一个巨大的挑战。在我们的案例中,这个项目起源于 2012 年之前,因为 Trip.com 没有统一或集中的日志平台。每个团队和业务单元(BU)各自收集和管理自己的日志,这带来了许多不同的问题:
-
需要大量人力来开发、维护和操作所有这些环境,不可避免地导致了大量重复工作。
-
数据治理和控制变得复杂。
-
公司内部没有统一的标准。
基于这些问题,我们意识到需要构建一个集中和统一的日志平台。
2012 年,我们推出了第一个平台。它建立在 Elasticsearch 之上,开始定义 ETL、存储、日志访问和查询的标准。
尽管我们不再使用 Elasticsearch 作为我们的日志平台,但值得探讨我们当初是如何实现这个解决方案的。它驱动了我们后来的许多工作,这是我们在后续迁移到 ClickHouse 时必须考虑的。
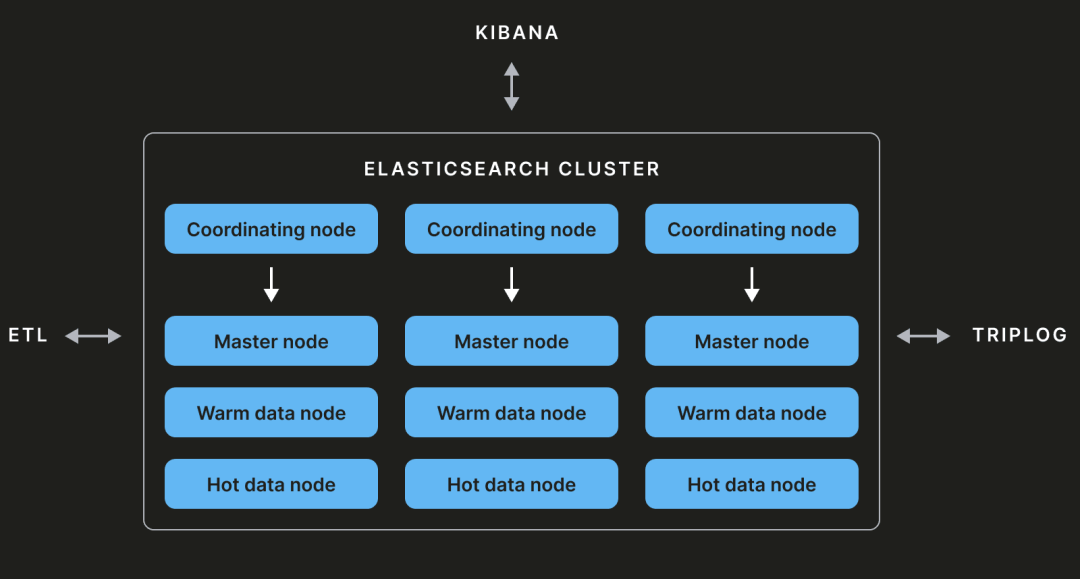
存储
我们的 Elasticsearch 集群主要由主控节点、协调节点和数据节点组成。
主控节点
每个 Elasticsearch 集群至少由三个主控节点组成。其中一个将被选为主节点,负责维护集群状态。集群状态是包含有关各种索引、分片、副本等信息的元数据。任何修改集群状态的操作都会由主控节点执行。
数据节点
数据节点存储数据并用于执行增删改查(CRUD)操作。它们可以分为多个层次:热层、暖层等。
协调节点
这种类型的节点没有其他功能(如主控、数据、摄取、转换等),并通过考虑集群状态作为智能负载均衡器。如果协调节点接收到带有 CRUD 操作的查询,它会被发送到数据节点。相反,如果接收到添加或删除索引的查询,它会被发送到主控节点。
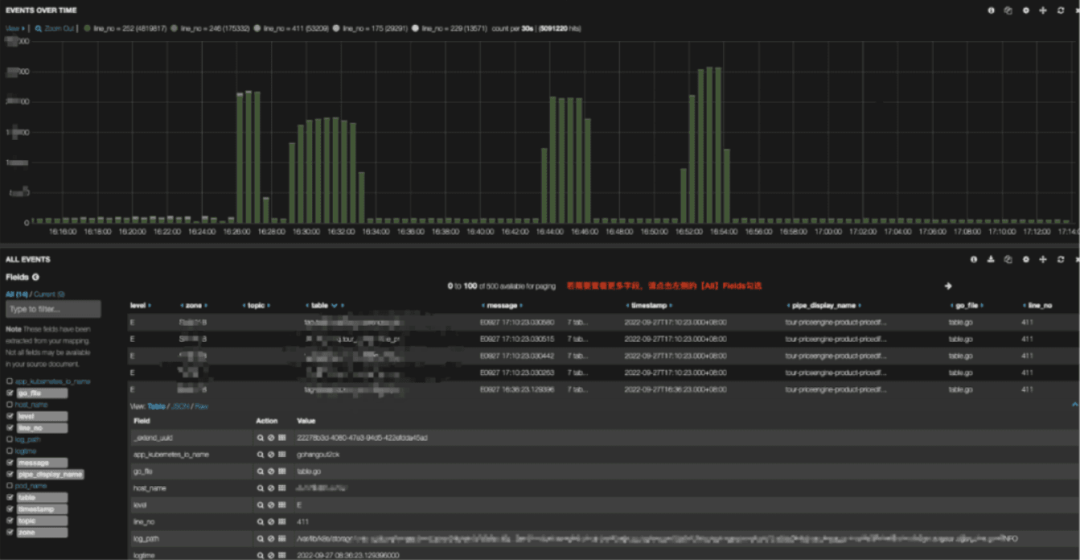
可视化
基于 Elasticsearch 我们使用 Kibana 作为可视化层。你可以在下方看到一个可视化示例:
日志插入
我们的用户有两种方式将日志发送到平台:通过 Kafka 和通过代理。
通过 Kafka
第一种方法是使用公司的框架 TripLog 将数据导入 Kafka 消息代理(使用 Hermes)。
private static final Logger log = LoggerFactory.getLogger(Demo.class);
public void demo (){
TagMarker marker = TagMarkerBuilder.newBuilder().scenario("demo").addTag("tagA", "valueA").addTag("tagA", "valueA").build();
log.info(marker, "Hello World!");
}这为用户提供了一个轻松将日志发送到平台的框架。
通过代理工具
另一种方法是使用代理工具,如 Filebeat、Logstash、Logagent 或定制客户端,直接写入 Kafka。你可以在下面看到一个 Filebeat 配置示例:
filebeat.config.inputs:
enabled: true
path: "/path/to/your/filebeat/config"
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/history.log
- /var/log/auth.log
- /var/log/secure
- /var/log/messages
harvester_buffer_size: 102400
max_bytes: 100000
tail_files: true
fields:
type: os
ignore_older: 30m
close_inactive: 2m
close_timeout: 40m
close_removed: true
clean_removed: true
output.kafka:
hosts: ["kafka_broker1", "kafka_broker2"]
topic: "logs-%{[fields.type]}"
required_acks: 0
compression: none
max_message_bytes: 1000000
processors:
- rename:
when:
equals:
source: "message"
target: "log_message"
ETL
无论用户选择哪种方法,数据最终都会进入 Kafka,然后可以通过 gohangout 管道传输到 Elasticsearch。
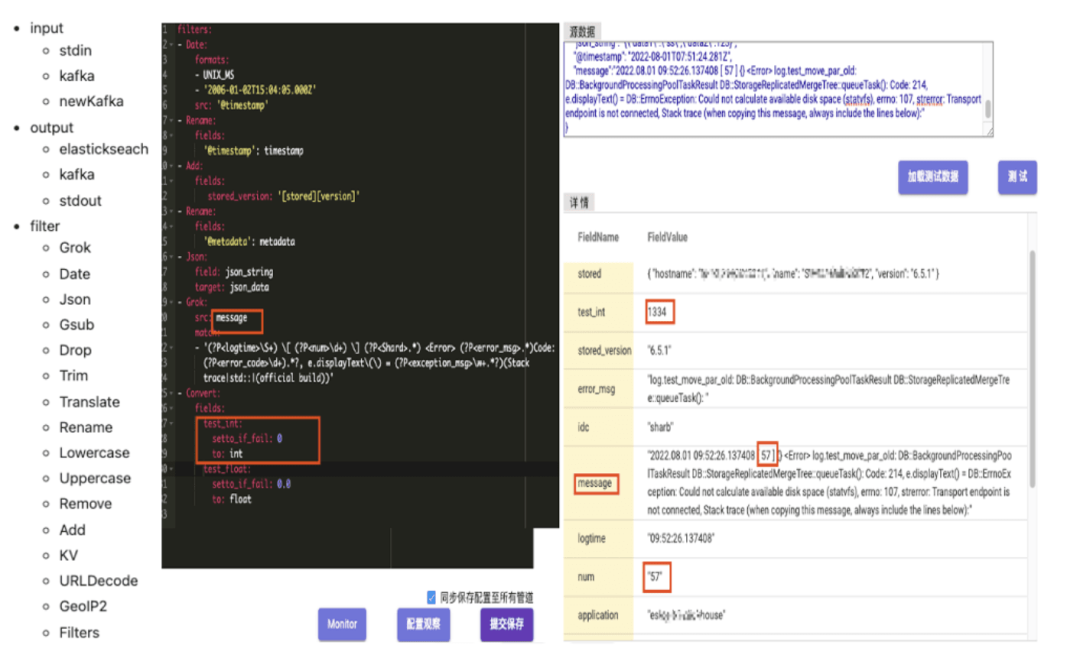
Gohangout 是由 trip.com 开发和维护的开源应用程序,作为 Logstash 的替代方案。它旨在从 Kafka 获取数据,执行 ETL 操作,最终将数据输出到各种存储介质中,如 ClickHouse 和 Elasticsearch。Filter 模块中的数据处理包括常见的数据清洗功能,如 JSON 处理、Grok 模式匹配和时间转换(如下所示)。在下面的示例中,GoHangout 使用正则表达式匹配从 Message 字段提取 num 数据,并将其存储为单独的字段。
达到瓶颈
许多人使用 Elasticsearch 进行可观测性,在处理较小数据量时表现出色。它提供易于使用的软件、无模式体验、广泛的功能和流行的 Kibana 界面。然而,当我们这种大规模部署时,它存在一些众所周知的挑战。
当我们在 Elasticsearch 中存储 4PB 数据时,我们开始面临集群稳定性的多个问题:
-
集群上的高负载导致许多请求被拒绝、写入延迟和查询缓慢
-
每日将 200 TB 数据从热节点迁移到冷节点导致显著的性能下降
-
分片分配是一个挑战,导致一些节点过载
-
大查询导致内存不足 (OOM) 异常
关于集群性能:
-
查询速度受到整体集群状态的影响
-
由于摄取过程中高 CPU 使用率,我们难以提高插入吞吐量
最后,关于成本:
-
数据量大、数据结构复杂且缺乏压缩导致需要大量存储空间
-
较弱的压缩率对业务产生影响,迫使我们缩短保留期
-
Elasticsearch 的 JVM 和内存限制导致更高的 TCO(总体拥有成本)
所以,在意识到以上所有问题后,我们寻找替代方案,于是 ClickHouse 出现了!
ClickHouse vs Elasticsearch
Elasticsearch 和 ClickHouse 之间存在一些基本差异;让我们来看看它们。
查询 DSL vs SQL
Elasticsearch 依赖于一种特定的查询语言,称为查询 DSL(领域专用语言)。尽管现在有更多的选项,但这仍然是主要语法。另一方面,ClickHouse 依赖于 SQL,这是一种非常主流且非常用户友好的语言,并且与许多不同的集成和 BI 工具兼容。
内部机制
Elasticsearch 和 ClickHouse 在内部行为上有一些相似之处,Elasticsearch 生成段,而 ClickHouse 写入部分。虽然两者都会随着时间的推移异步合并,创建更大的部分和段,但 ClickHouse 通过列式模型区分自己,其中数据通过 ORDER BY 键排序。这允许构建稀疏索引,从而实现快速过滤和高效的存储使用,因为压缩率很高。你可以在这篇出色的指南中了解更多关于此索引机制的信息。
索引 vs 表
Elasticsearch 中的数据存储在索引中,并分解为分片。这些需要保持在相对较小的大小范围内(在我们使用时,推荐的是大约 50GB 的分片)。相比之下,ClickHouse 的数据存储在显著更大的表中(在 TB 范围内,如果不受磁盘大小限制的话,还可以更大)。除此之外,ClickHouse 允许你创建分区键,这会将数据物理上分隔到不同的文件夹中。如果需要,可以高效地操作这些分区。
总体而言,我们对 ClickHouse 的功能和特性印象深刻:它的列式存储、向量化查询执行、高压缩率和高插入吞吐量。这些满足了我们对日志解决方案在性能、稳定性和成本效益方面的需求。因此,我们决定使用 ClickHouse 来替换我们的存储和查询层。
下一个挑战是如何无缝地从一种存储迁移到另一种存储而不中断服务。
日志平台 2.0:迁移到 ClickHouse
在决定迁移到 ClickHouse 之后,我们确定了需要完成的几个任务:
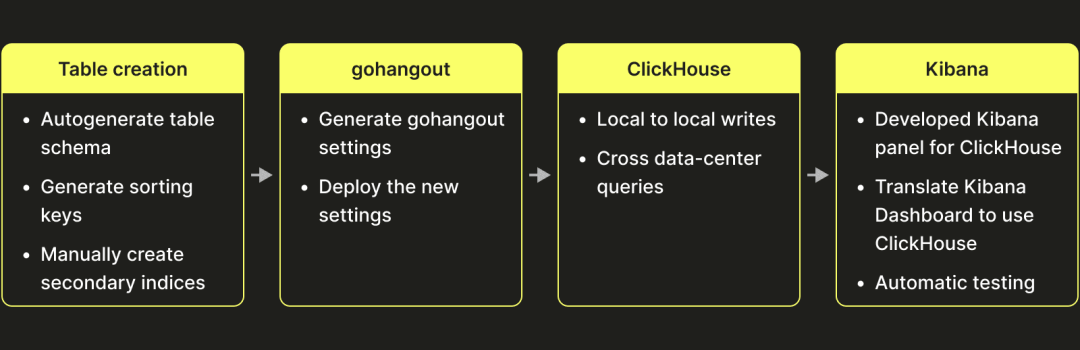
表设计
这是我们当时确定的初始表设计(请记住,那是几年前的事了,当时 ClickHouse 还没有现在的所有数据类型,例如 maps):
CREATE TABLE log.example
(
`timestamp` DateTime64(9) CODEC(ZSTD(1)),
`_log_increment_id` Int64 CODEC(ZSTD(1)),
`host_ip` LowCardinality(String) CODEC(ZSTD(1)),
`host_name` LowCardinality(String) CODEC(ZSTD(1)),
`log_level` LowCardinality(String) CODEC(ZSTD(1)),
`message` String CODEC(ZSTD(1)),
`message_prefix` String MATERIALIZED substring(message, 1, 128) CODEC(ZSTD(1)),
`_tag_keys` Array(LowCardinality(String)) CODEC(ZSTD(1)),
`_tag_vals` Array(String) CODEC(ZSTD(1)),
`log_type` LowCardinality(String) CODEC(ZSTD(1)),
...
INDEX idx_message_prefix message_prefix TYPE tokenbf_v1(8192, 2, 0) GRANULARITY 16,
...
)
ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/example', '{replica}')
PARTITION BY toYYYYMMDD(timestamp)
ORDER BY (log_level, timestamp, host_ip, host_name)
TTL toDateTime(timestamp) + toIntervalHour(168)-
我们使用双数组方法来存储动态变化的标签(我们计划未来使用 maps),即有两个数组分别存储键和值。
-
按天分区以便于数据操作。对于我们的数据量,每日分区是合适的,但大多数情况下,较高的粒度如每月或每周更好。
-
根据你在查询中使用的过滤器,你可能希望有一个与上表不同的 ORDER BY 键。上面的键是针对使用 log_level 和时间的查询进行优化的。例如,如果你的查询不使用 log_level,那么在键中只包含时间列是有意义的。
-
Tokenbf_v1 布隆过滤器用于优化关键词查询和模糊查询。
-
_log_increment_id 列包含一个全局唯一的增量 ID,以实现高效的滚动分页和精确的数据定位。
-
ZSTD 数据压缩方法,节省了超过 40% 的存储成本。
集群设置
鉴于我们在 Elasticsearch 上的历史设置和经验,我们决定复制一个相似的架构。我们的 ClickHouse-Keeper 实例充当主节点(类似于 Elasticsearch)。部署了多查询节点,这些节点不存储数据,而是持有指向 ClickHouse 服务器的分布式表。这些服务器托管数据节点,存储和写入数据。以下显示了我们最终的架构:
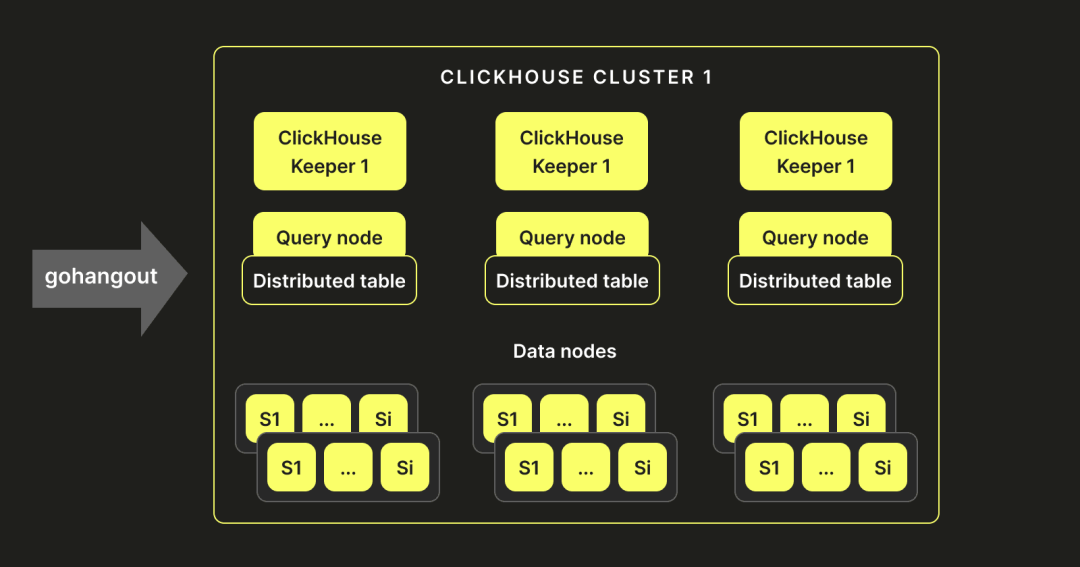
数据可视化
在迁移到 ClickHouse 后,我们希望为用户提供无缝体验。为此,我们需要确保所有的可视化和仪表板都能使用 ClickHouse。这带来了一个挑战,因为 Kibana 是一个最初在 Elasticsearch 上开发的工具,不支持其他存储引擎。因此,我们必须对其进行自定义,以确保它能够与 ClickHouse 接口。这需要我们在 Kibana 中创建新的数据面板,可以与 ClickHouse 一起使用:chhistogram、chhits、chpercentiles、chranges、chstats、chtable、chterms 和 chuniq。
然后,我们创建了脚本,将 95% 的现有 Kibana 仪表板迁移到使用 ClickHouse。最后,我们增强了 Kibana,使用户可以编写 SQL 查询。
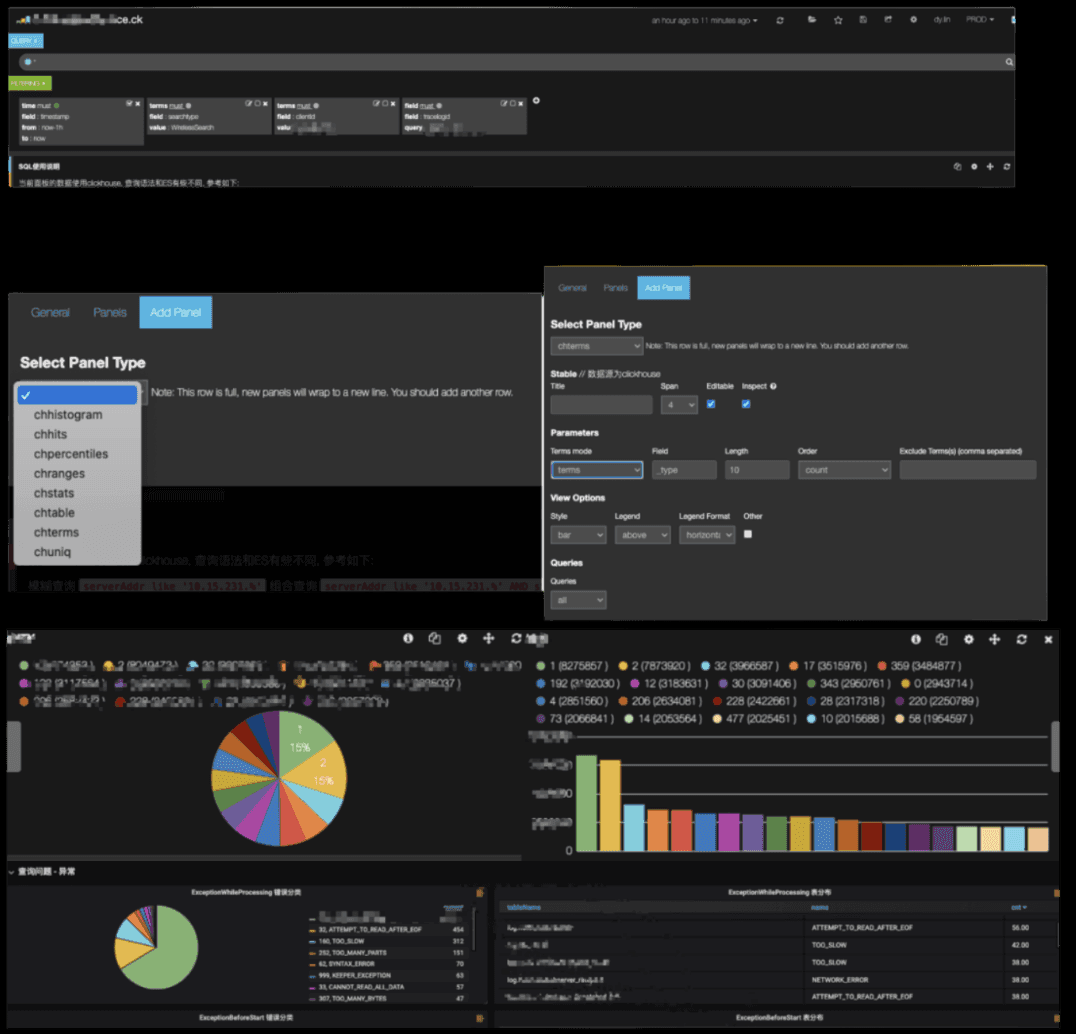
Triplog
我们的日志管道是自助服务,允许用户发送日志。这些用户需要能够创建索引并定义所有权、权限和 TTL 策略。因此,我们创建了一个名为 Triplog 的平台,为用户提供管理表、用户和角色的接口,监控其数据流,并创建警报。
回顾
现在一切都已迁移完毕,是时候看看我们平台的新性能了!尽管我们自动化了 95% 的迁移并实现了无缝过渡,但回顾我们的成功指标并查看新平台的表现仍然很重要。两个最重要的指标是查询性能和总体拥有成本(TCO)。
TCO
我们最初成本的一个重要组成部分是存储。让我们比较一下 Elasticsearch 和 ClickHouse 在相同数据样本上的存储情况:
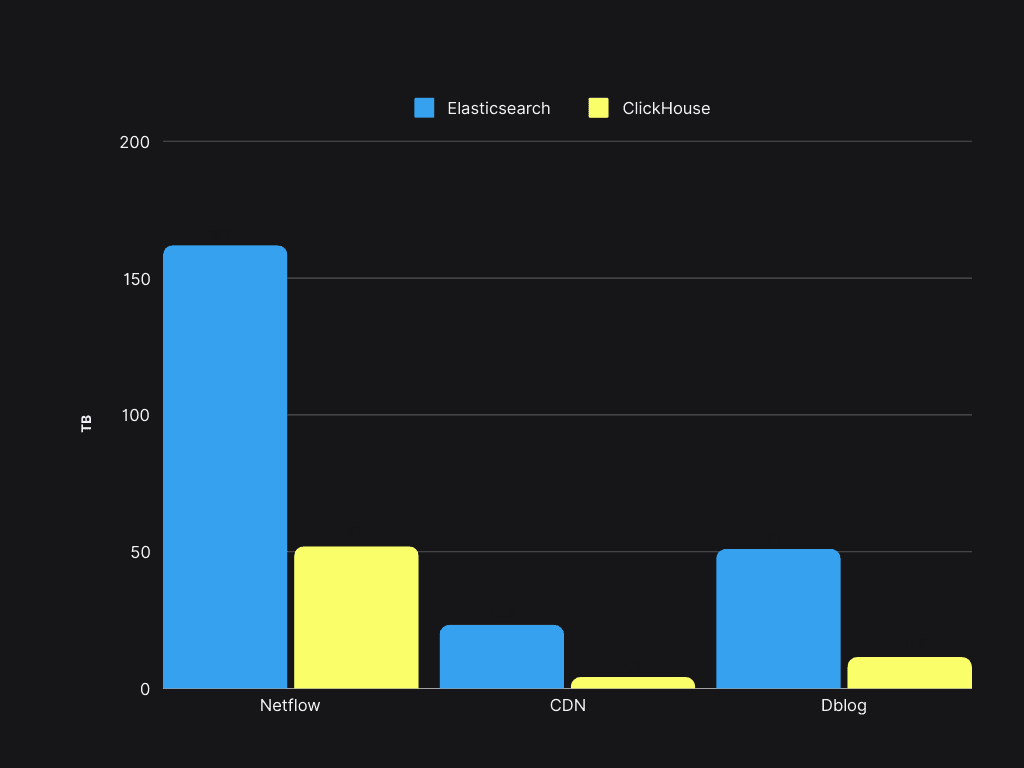
存储空间节省超过 50%,使现有的 Elasticsearch 服务器能够支持 4 倍的数据量增加。
查询性能
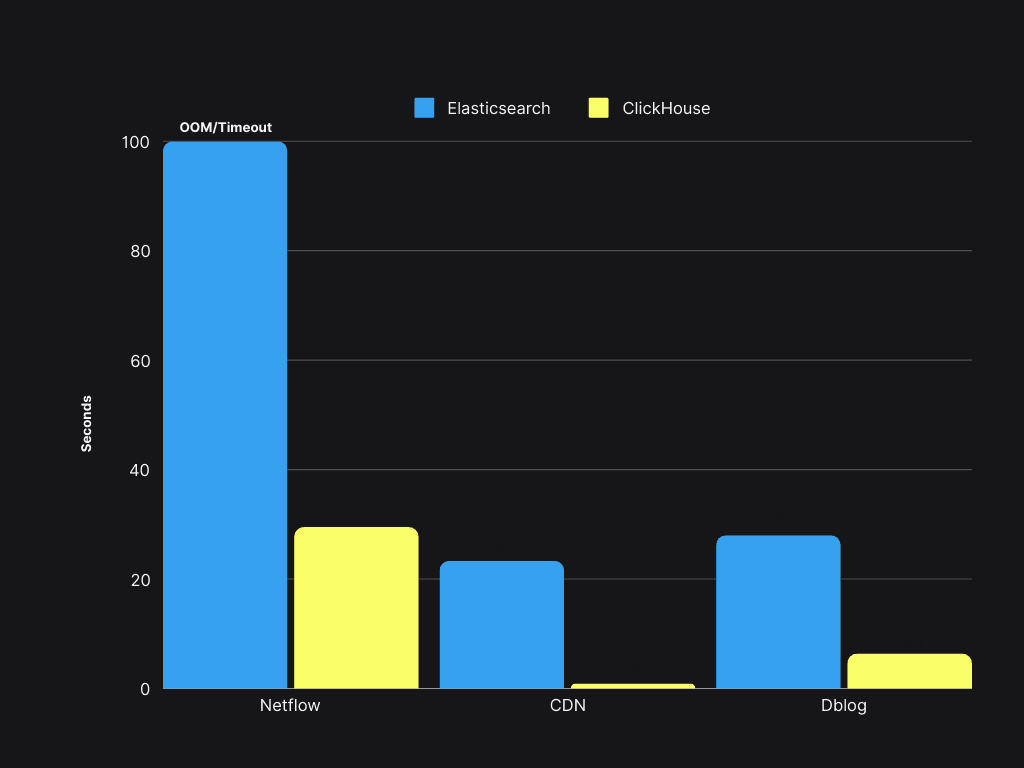
查询速度比 Elasticsearch 快 4 到 30 倍,P90 小于 300 毫秒,P99 小于 1.5 秒。
日志 3.0:改进基于 ClickHouse 的平台
自从我们在 2022 年完成从 Elasticsearch 的迁移以来,我们在平台上增加了更多日志用例,使其从 4PB 增长到 20PB。随着它继续增长并扩展到 30PB,我们遇到了新的挑战。
性能和功能瓶颈
-
在这种规模下管理单个 ClickHouse 集群是具有挑战性的。在部署时,没有 ClickHouse-Keeper 或 SharedMergeTree,我们面临着 Zookeeper 的性能瓶颈,导致 DDL 超时异常。
-
用户的不良索引选择导致查询性能不佳,需要使用更好的模式重新插入数据。
-
未优化的查询导致性能问题。
操作挑战
-
集群构建依赖于 Ansible,导致长部署周期(数小时)。
-
我们当前的 ClickHouse 实例版本落后于社区版本,当前的集群部署模式不便于进行更新。
为了解决上述性能挑战,我们首先放弃了单集群的架构。在我们的规模下,没有 SharedMergeTree 和 ClickHouse Keeper,元数据的管理变得困难,由于 Zookeeper 的瓶颈,我们会遇到 DDL 语句的超时问题。因此,我们创建了多个集群,而不是保留一个单一的集群,如下所示:
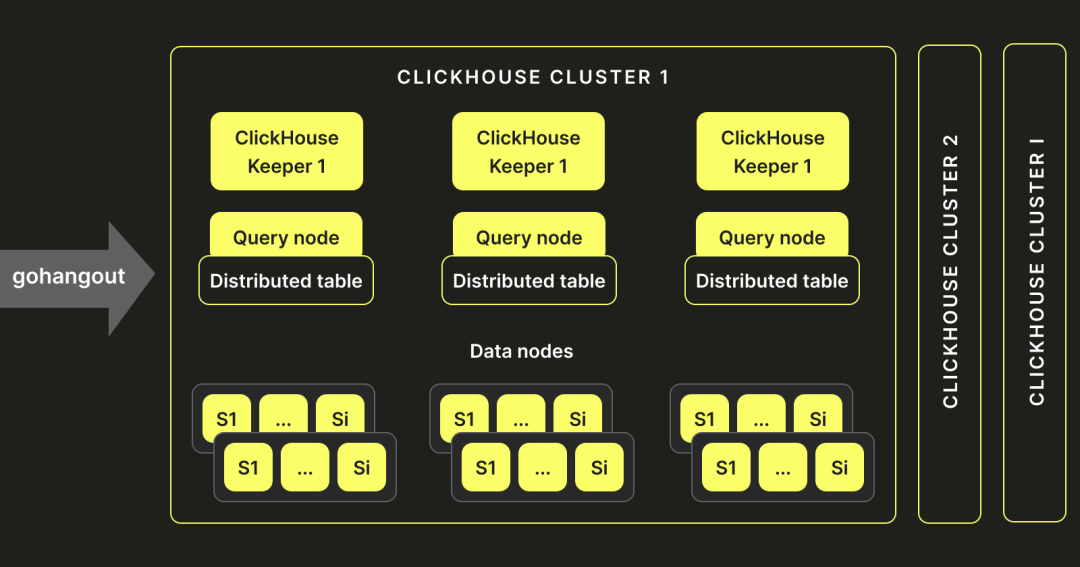
这种新架构帮助我们扩展并克服了 Zookeeper 的限制。我们将这些集群部署到 Kubernetes,使用 StatefulSets、反亲和和 ConfigMaps。这将单个集群的交付时间从 2 天减少到 5 分钟。同时,我们标准化了部署架构,简化了全球多个环境中的部署流程。这种方法显著降低了我们的运营成本,并有助于实施上述方法。
查询路由
尽管上述方案解决了一些挑战,但它引入了新的复杂性,即如何将用户的查询路由到特定的集群。
让我们举个例子来说明:
假设我们有三个集群:集群1、集群2和集群3,以及三个表:A、B和C。在我们实施下面描述的虚拟表分区方法之前,一个表(如A)只能存在于一个数据集群中(例如集群1)。这种设计限制意味着当集群1的磁盘空间用满时,我们没有快速的方法将表A的数据迁移到集群2的空闲磁盘空间。相反,我们不得不使用双写操作,同时将表A的数据写入集群1和集群2。然后,在集群2中的数据过期后(例如七天后),我们可以从集群1中删除表A的数据。这个过程繁琐且缓慢,需要大量手动工作来管理集群。
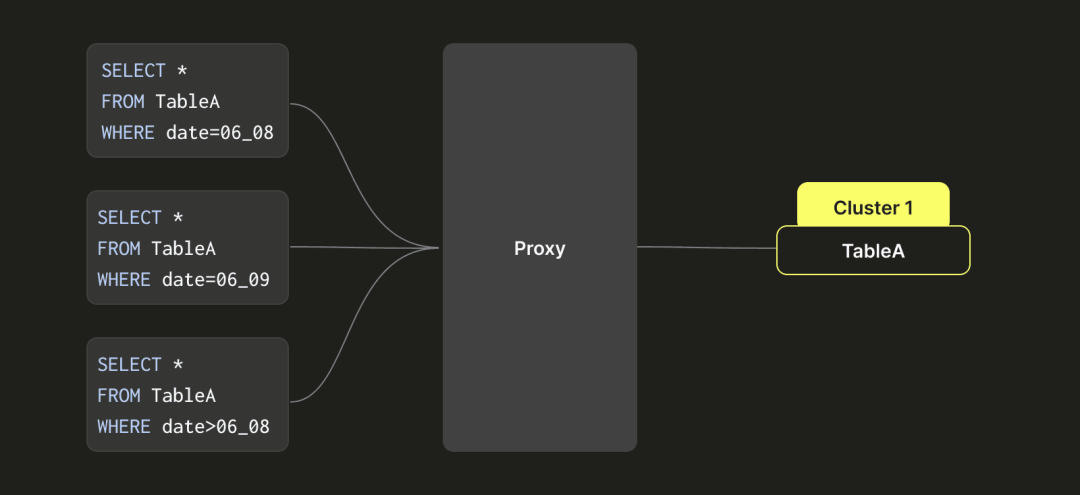
为了解决这个问题,我们设计了一个类似类的分区架构,使表A能够在多个集群(集群1、集群2和集群3)之间来回移动。如右侧所示,转换后,表A的数据基于时间间隔进行分区(可以精确到秒,但这里为了简单起见使用天作为例子)。例如,6月8日的数据写入集群1,6月9日的数据写入集群2,6月10日的数据写入集群3。当查询命中6月8日的数据时,我们只查询集群1的数据。当查询需要6月9日和10日的数据时,我们同时查询集群2和集群3的数据。
我们通过建立不同的分布式表实现了这一功能,每个分布式表表示特定时间段的数据,并且与多个集群(如集群1、集群2和集群3)的逻辑组合相关联。这种方法解决了跨集群表的问题,使不同集群之间的磁盘使用更加平衡。
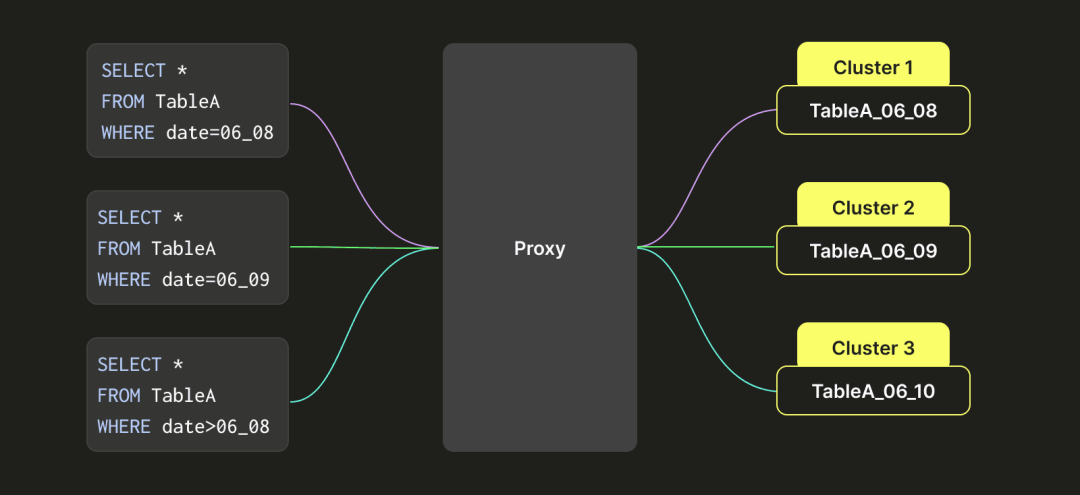
如上图所示,每个查询会根据其 WHERE 子句由代理智能重定向到包含所需表的正确集群。
这种架构有助于模式的演变。由于可以添加和删除列,有些表可以有更多或更少的列。上述路由可以在列级别应用,代理可以过滤不包含查询所需列的表。
此外,这种架构帮助我们支持演变的 ORDER BY 键——通常在 ClickHouse 中,无法动态更改表的 ORDER BY 键。通过上述方法,你只需更改新表上的 ORDER BY 键,并让旧表过期(得益于 TTL)。
Antlr4 SQL 解析
在查询层,我们使用 Antlr4 技术将用户的 SQL 查询解析为抽象语法树(AST)。通过 AST 树,我们可以快速获取 SQL 查询中的表名、过滤条件和聚合维度等信息。利用这些信息,我们可以轻松实现针对 SQL 查询的实时策略,例如数据统计、查询重写和流量控制。

我们为所有用户的 SQL 查询实现了一个统一的查询网关代理。该程序基于元数据信息和策略重写用户的 SQL 查询,实现精确路由和自动性能优化等功能。此外,它记录了每个查询的详细上下文,用于统一管理集群查询,限制 QPS、大表扫描和查询执行时间,从而提高系统稳定性。
我们平台的未来是什么?
我们的平台在 40PB+ 规模下已经得到验证,但仍有许多需要改进的地方。我们希望能够更加动态地扩展,以便在假期等高峰期间更优雅地应对高峰需求。为了应对这种扩展需求,我们开始探索 ClickHouse 企业服务(通过阿里云),引入了 SharedMergeTree 表引擎。这一新架构提供了存储和计算的原生分离。通过这种新架构,我们可以提供几乎无限的存储,以支持 trip.com 内部更多的日志用例。
阿里云上提供的 ClickHouse 企业服务与 ClickHouse Cloud 使用相同版本的 ClickHouse。
在阿里云上测试 ClickHouse 企业服务
为了测试 ClickHouse 企业服务,我们首先将数据双写,插入到现有部署和利用 SharedMergeTree 的新服务中。为了模拟真实的工作负载,我们:
-
将 3TB 数据加载到两个集群中,然后继续插入负载。
-
收集各种查询模板用作测试集。
-
使用脚本构建查询,这些查询将在特定值保证非空结果集的情况下查询随机的 1 小时时间间隔。
关于使用的基础设施:
-
3 个节点,每个节点 32 个 CPU 和 128 GiB 内存,使用对象存储用于 ClickHouse 企业版(带 SMT)
-
2 个节点,每个节点 40 个 CPU 和 176 GiB 内存,使用 HDD 用于社区版(开源)
为了执行我们的查询工作负载,我们使用了 clickhouse-benchmark 工具(ClickHouse 自带)对两种服务进行测试。
-
企业版和社区版都配置为使用文件系统缓存,因为我们希望重现生产环境的条件(生产环境中数据量更大,缓存命中率较低)
-
我们将以 2 的并发运行第一次测试,每个查询执行 3 次。
| Testing Round | P50 | P90 | P99 | P9999 | Avg | |
|---|---|---|---|---|---|---|
| Alicloud Enterprise Edition | 1st | 0.26 | 0.62 | 7.2 | 22.99 | 0.67 |
| 2nd | 0.24 | 0.46 | 4.4 | 20.61 | 0.52 | |
| 3rd | 0.24 | 0.48 | 16.75 | 21.71 | 0.70 | |
| Avg | 0.246 40.3% | 0.52 22.2% | 7.05 71.4% | 21.77 90.3 | 0.63 51.6% | |
| Alicloud Community Edition | 1st | 0.63 | 3.4 | 11.06 | 29.50 | 1.39 |
| 2nd | 0.64 | 1.92 | 9.35 | 23.50 | 1.20 | |
| 3rd | 0.58 | 1.60 | 9.23 | 19.3 | 1.07 | |
| Avg | 0.61 100% | 2.31 100% | 9.88 100% | 24.1 100% | 1.07 100% |
ClickHouse 企业服务的结果显示为黄色,阿里云社区版的结果显示为红色。相对于社区版的性能百分比显示为绿色(越低越好)。
随着并发增加,社区版很快无法处理工作负载并开始返回错误。这实际上意味着企业版能够有效地处理三倍的并发查询。
尽管 ClickHouse 企业服务使用对象存储作为数据存储方式,但它在高并发工作负载方面表现更好。我们认为这种无缝的就地升级可以大大减轻我们的运营负担。
因此,我们决定开始将业务指标迁移到企业服务。这包括支付完成率、订单统计等信息。我们建议所有社区用户试用企业服务!
征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com

联系我们
手机号:13910395701
邮箱:Tracy.Wang@clickhouse.com
满足您所有的在线分析列式数据库管理需求