每个样本都有标签的机器学习称为监督学习。根据标签数值类型的不同,监督学习又可以分为回归问题和分类问题。分类和回归是监督学习的核心问题。
- 回归(regression)问题中的标签是连续值。
- 分类(classification)问题中的标签是离散值。分类问题根据其类别数量又可分为二分类(binary classification)和多分类(multi-class classification)问题。
线性分类
Logistic 回归
基本形式
给定的数据集
D
=
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
⋯
,
(
x
N
,
y
N
}
D=\{(\mathbf x_1,y_1),(\mathbf x_2,y_2),\cdots,(\mathbf x_N,y_N\}
D={(x1,y1),(x2,y2),⋯,(xN,yN}
包含
N
N
N 个样本,
p
p
p 个特征。其中,第
i
i
i 个样本的特征向量为
x
i
=
(
x
i
1
,
x
i
2
,
⋯
,
x
i
p
)
T
\mathbf x_i=(x_{i1},x_{i2},\cdots,x_{ip})^T
xi=(xi1,xi2,⋯,xip)T 。目标变量
y
i
∈
{
0
,
1
}
y_i\in \{0,1\}
yi∈{0,1} 。逻辑回归试图预测正样本的概率,那我们需要一个输出
[
0
,
1
]
[0,1]
[0,1] 区间的激活函数。假设二分类数据集服从均值不同、方差相同的正态分布
{
P
(
x
∣
y
=
1
)
=
N
(
x
;
μ
1
,
Σ
)
P
(
x
∣
y
=
0
)
=
N
(
x
;
μ
0
,
Σ
)
\begin{cases} \mathbb P(\mathbf x|y=1)=\mathcal N(\mathbf x;\mathbf \mu_1, \mathbf\Sigma) \\ \mathbb P(\mathbf x|y=0)=\mathcal N(\mathbf x;\mathbf \mu_0, \mathbf\Sigma) \end{cases}
{P(x∣y=1)=N(x;μ1,Σ)P(x∣y=0)=N(x;μ0,Σ)
其中,协方差矩阵
Σ
\mathbf\Sigma
Σ 为对称阵。正态分布概率密度函数为
N
(
x
;
μ
,
Σ
)
=
1
(
2
π
)
p
det
Σ
exp
(
−
1
2
(
x
−
μ
)
T
Σ
−
1
(
x
−
μ
)
)
\mathcal N(\mathbf x;\mathbf \mu, \mathbf\Sigma)=\frac{1}{\sqrt{(2\pi)^p\det\mathbf\Sigma}}\exp\left(-\frac{1}{2}(\mathbf x-\mathbf\mu)^T\mathbf\Sigma^{-1}(\mathbf x-\mathbf\mu)\right)
N(x;μ,Σ)=(2π)pdetΣ1exp(−21(x−μ)TΣ−1(x−μ))
利用贝叶斯定理,正样本条件概率
P
(
y
=
1
∣
x
)
=
P
(
x
∣
y
=
1
)
P
(
y
=
1
)
P
(
x
∣
y
=
0
)
P
(
y
=
0
)
+
P
(
x
∣
y
=
1
)
P
(
y
=
1
)
\mathbb P(y=1|\mathbf x)=\frac{\mathbb P(\mathbf x|y=1)\mathbb P(y=1)}{\mathbb P(\mathbf x|y=0)\mathbb P(y=0)+\mathbb P(\mathbf x|y=1)\mathbb P(y=1)}
P(y=1∣x)=P(x∣y=0)P(y=0)+P(x∣y=1)P(y=1)P(x∣y=1)P(y=1)
令 [^cdot]
z
=
ln
P
(
x
∣
y
=
1
)
P
(
y
=
1
)
P
(
x
∣
y
=
0
)
P
(
y
=
0
)
=
−
1
2
(
x
−
μ
1
)
T
Σ
−
1
(
x
−
μ
1
)
+
1
2
(
x
−
μ
0
)
T
Σ
−
1
(
x
−
μ
0
)
+
ln
P
(
y
=
1
)
P
(
y
=
0
)
=
(
μ
1
−
μ
0
)
T
Σ
−
1
x
−
1
2
μ
1
T
Σ
−
1
μ
1
+
1
2
μ
0
T
Σ
−
1
μ
0
+
ln
P
(
y
=
1
)
P
(
y
=
0
)
\begin{aligned} z&=\ln\frac{\mathbb P(\mathbf x|y=1)\mathbb P(y=1)}{\mathbb P(\mathbf x|y=0)\mathbb P(y=0)} \\ &=-\frac{1}{2}(\mathbf x-\mathbf \mu_1)^T\mathbf\Sigma^{-1}(\mathbf x-\mathbf \mu_1)+\frac{1}{2}(\mathbf x-\mathbf \mu_0)^T\mathbf\Sigma^{-1}(\mathbf x-\mathbf \mu_0)+\ln\frac{\mathbb P(y=1)}{\mathbb P(y=0)} \\ &=(\mathbf \mu_1-\mathbf \mu_0)^T\mathbf\Sigma^{-1}\mathbf x-\frac{1}{2}\mu_1^T\mathbf\Sigma^{-1}\mu_1+\frac{1}{2}\mu_0^T\mathbf\Sigma^{-1}\mu_0+\ln\frac{\mathbb P(y=1)}{\mathbb P(y=0)} \\ \end{aligned}
z=lnP(x∣y=0)P(y=0)P(x∣y=1)P(y=1)=−21(x−μ1)TΣ−1(x−μ1)+21(x−μ0)TΣ−1(x−μ0)+lnP(y=0)P(y=1)=(μ1−μ0)TΣ−1x−21μ1TΣ−1μ1+21μ0TΣ−1μ0+lnP(y=0)P(y=1)
其中先验概率
P
(
y
=
1
)
\mathbb P(y=1)
P(y=1) 和
P
(
y
=
0
)
\mathbb P(y=0)
P(y=0) 是常数,上式可简化为
z
=
w
T
x
+
b
z=\mathbf w^T\mathbf x+b
z=wTx+b
于是
P
(
y
=
1
∣
x
)
=
1
1
+
e
−
z
\mathbb P(y=1|\mathbf x)=\frac{1}{1+e^{-z}}
P(y=1∣x)=1+e−z1
上式称为 Sigmoid 函数(S型曲线),也称 logistic 函数。
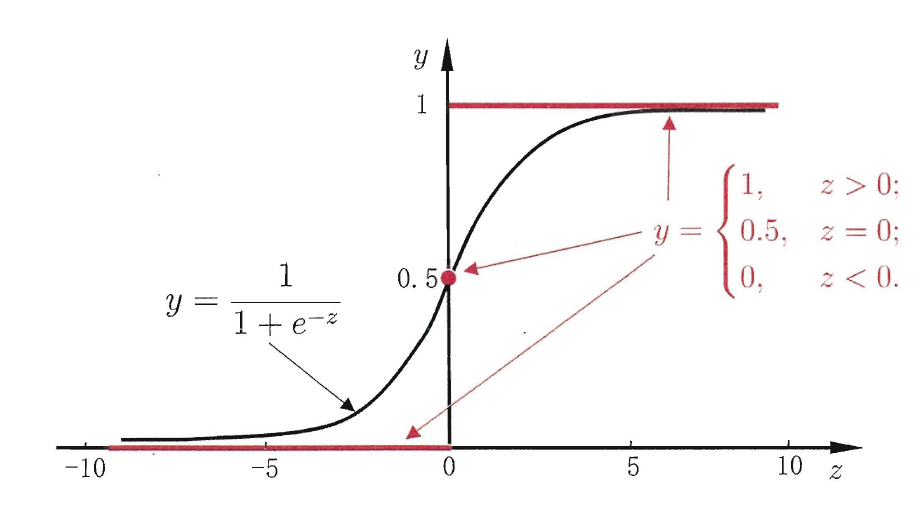
Model: 逻辑回归 (logistic regression, logit regression) 通过引入Sigmod 函数将输入值映射到
[
0
,
1
]
[0,1]
[0,1] 来实现分类功能。
f
w
,
b
(
x
)
=
g
(
w
T
x
+
b
)
f_{\mathbf{w},b}(\mathbf{x}) = g(\mathbf{w}^T \mathbf{x}+b)
fw,b(x)=g(wTx+b)
其中
g
(
z
)
=
1
1
+
e
−
z
g(z) = \frac{1}{1+e^{-z}}
g(z)=1+e−z1
式中特征向量
x
=
(
x
1
,
x
2
,
⋯
,
x
p
)
T
\mathbf x=(x_1,x_2,\cdots,x_p)^T
x=(x1,x2,⋯,xp)T,参数
w
=
(
w
1
,
w
2
,
⋯
,
w
p
)
T
\mathbf{w}=(w_1,w_2,\cdots,w_p)^T
w=(w1,w2,⋯,wp)T 称为系数 (coefficients) 或权重 (weights),标量
b
b
b 称为偏置项(bias) 。
为计算方便,模型简写为
f
w
(
x
)
=
1
1
+
exp
(
−
w
T
x
)
f_{\mathbf{w}}(\mathbf{x}) = \frac{1}{1+\exp(-\mathbf{w}^T\mathbf{x})}
fw(x)=1+exp(−wTx)1
其中,特征向量
x
=
(
1
,
x
1
,
x
2
,
⋯
,
x
p
)
T
\mathbf x=(1,x_1,x_2,\cdots,x_p)^T
x=(1,x1,x2,⋯,xp)T,权重向量
w
=
(
b
,
w
1
,
w
2
,
⋯
,
w
p
)
T
\mathbf{w}=(b,w_1,w_2,\cdots,w_p)^T
w=(b,w1,w2,⋯,wp)T
可以通过引入阈值(默认0.5)实现分类预测
y
^
=
{
1
if
f
w
(
x
)
⩾
0.5
0
if
f
w
(
x
)
<
0.5
\hat y=\begin{cases} 1 &\text{if } f_{\mathbf{w}}(\mathbf{x})\geqslant 0.5 \\ 0 &\text{if } f_{\mathbf{w}}(\mathbf{x})<0.5 \end{cases}
y^={10if fw(x)⩾0.5if fw(x)<0.5
模型的输出为正样本的概率
{
P
(
y
=
1
∣
x
)
=
f
w
(
x
)
P
(
y
=
0
∣
x
)
=
1
−
f
w
(
x
)
\begin{cases} \mathbb P(y=1|\mathbf x)=f_{\mathbf{w}}(\mathbf{x}) \\ \mathbb P(y=0|\mathbf x)=1-f_{\mathbf{w}}(\mathbf{x}) \end{cases}
{P(y=1∣x)=fw(x)P(y=0∣x)=1−fw(x)
可简记为
P
(
y
∣
x
)
=
[
f
w
(
x
)
]
y
[
1
−
f
w
(
x
)
]
1
−
y
\mathbb P(y|\mathbf x)=[f_{\mathbf{w}}(\mathbf{x})]^{y}[1-f_{\mathbf{w}}(\mathbf{x})]^{1-y}
P(y∣x)=[fw(x)]y[1−fw(x)]1−y
极大似然估计
logistic 回归若采用均方误差作为 cost function,是一个非凸函数(non-convex),会存在许多局部极小值,因此我们尝试极大似然估计。
极大似然估计:(maximum likelihood estimate, MLE) 使得观测样本出现的概率最大,也即使得样本联合概率(也称似然函数)取得最大值。
为求解方便,对样本联合概率取对数似然函数
log
L
(
w
)
=
log
∏
i
=
1
N
P
(
y
i
∣
x
i
)
=
∑
i
=
1
N
log
P
(
y
i
∣
x
i
)
=
∑
i
=
1
N
[
y
i
log
f
w
(
x
i
)
+
(
1
−
y
i
)
log
(
1
−
f
w
(
x
i
)
)
]
\begin{aligned} \log L(\mathbf w) & =\log\prod_{i=1}^{N} \mathbb P(y_i|\mathbf x_i)=\sum_{i=1}^N\log \mathbb P(y_i|\mathbf x_i) \\ &=\sum_{i=1}^{N}[y_i\log f_{\mathbf{w}}(\mathbf{x}_i)+(1-y_i)\log(1-f_{\mathbf{w}}(\mathbf{x}_i))] \end{aligned}
logL(w)=logi=1∏NP(yi∣xi)=i=1∑NlogP(yi∣xi)=i=1∑N[yilogfw(xi)+(1−yi)log(1−fw(xi))]
因此,可定义 loss function
L
(
f
w
(
x
)
,
y
)
=
−
y
log
f
w
(
x
)
−
(
1
−
y
)
log
(
1
−
f
w
(
x
)
)
=
−
y
w
T
x
+
log
(
1
+
e
w
T
x
)
\begin{aligned} L(f_{\mathbf{w}}(\mathbf{x}),y)&=-y\log f_{\mathbf{w}}(\mathbf{x})-(1-y)\log(1-f_{\mathbf{w}}(\mathbf{x})) \\ &=-y\mathbf{w}^T\mathbf{x}+\log(1+e^{\mathbf{w}^T\mathbf{x}}) \end{aligned}
L(fw(x),y)=−ylogfw(x)−(1−y)log(1−fw(x))=−ywTx+log(1+ewTx)
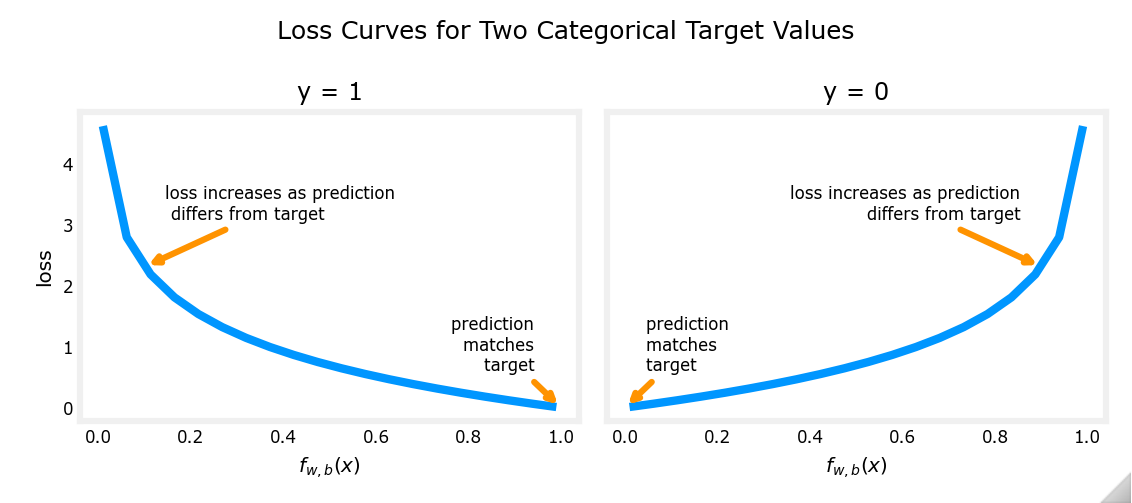
最大化似然函数等价于最小化 cost function
J
(
w
)
=
1
N
∑
i
=
1
N
(
−
y
i
w
T
x
+
log
(
1
+
e
w
T
x
)
)
J(\mathbf w)=\frac{1}{N}\sum_{i=1}^{N}(-y_i\mathbf{w}^T\mathbf{x}+\log(1+e^{\mathbf{w}^T\mathbf{x}}))
J(w)=N1i=1∑N(−yiwTx+log(1+ewTx))
参数估计 :(parameter estimation)
J
(
w
)
J(\mathbf w)
J(w) 是关于参数
w
\mathbf w
w 的高阶可导连续凸函数,经典的数值优化算法如梯度下降法 (gradient descent method) 、牛顿法 (Newton method) 等都可求得其最优解
arg
min
w
J
(
w
)
\arg\min\limits_{\mathbf w} J(\mathbf{w})
argwminJ(w)
最大期望算法
最大期望算法:(Expectation-Maximization algorithm, EM)与真实分布最接近的模拟分布即为最优分布,因此可以通过最小化交叉熵来求出最优分布。
对任意样本
(
x
i
,
y
i
)
(\mathbf x_i,y_i)
(xi,yi),真实分布可写为(真实分布当然完美预测)
P
(
y
i
∣
x
i
)
=
1
\mathbb P(y_i|\mathbf x_i)=1
P(yi∣xi)=1
模拟分布可写为
Q
(
y
i
∣
x
i
)
=
[
f
w
(
x
i
)
]
y
[
1
−
f
w
(
x
i
)
]
1
−
y
\mathbb Q(y_i|\mathbf x_i)=[f_{\mathbf{w}}(\mathbf{x}_i)]^{y}[1-f_{\mathbf{w}}(\mathbf{x}_i)]^{1-y}
Q(yi∣xi)=[fw(xi)]y[1−fw(xi)]1−y
交叉熵为
H
(
P
,
Q
)
=
−
∑
i
=
1
N
P
(
y
i
∣
x
i
)
log
Q
(
y
i
∣
x
i
)
=
∑
i
=
1
N
(
−
y
i
w
T
x
+
log
(
1
+
e
w
T
x
)
)
\begin{aligned} H(\mathbb P,\mathbb Q) &=-\sum_{i=1}^N \mathbb P(y_i|\mathbf x_i)\log \mathbb Q(y_i|\mathbf x_i) \\ &=\sum_{i=1}^{N}(-y_i\mathbf{w}^T\mathbf{x}+\log(1+e^{\mathbf{w}^T\mathbf{x}})) \end{aligned}
H(P,Q)=−i=1∑NP(yi∣xi)logQ(yi∣xi)=i=1∑N(−yiwTx+log(1+ewTx))
cost function
J
(
w
)
=
1
N
∑
i
=
1
N
(
−
y
i
w
T
x
+
log
(
1
+
e
w
T
x
)
)
J(\mathbf w)=\frac{1}{N}\sum_{i=1}^{N}(-y_i\mathbf{w}^T\mathbf{x}+\log(1+e^{\mathbf{w}^T\mathbf{x}}))
J(w)=N1i=1∑N(−yiwTx+log(1+ewTx))
与极大似然估计相同。
决策边界
决策边界:逻辑回归模型 f w , b ( x ) = g ( z ) = g ( w T x + b ) f_{\mathbf{w},b}(\mathbf{x})=g(z)= g(\mathbf{w}^T \mathbf{x}+b) fw,b(x)=g(z)=g(wTx+b)
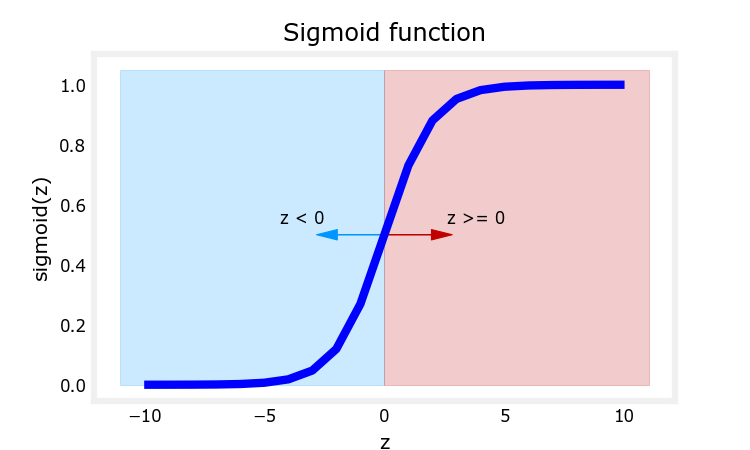
在 logistic 回归模型中,
z
=
w
T
x
+
b
z=\mathbf{w}^T\mathbf{x}+b
z=wTx+b 。对于 sigmoid 函数(如上图),
g
(
z
)
⩾
0.5
for
z
⩾
0
g(z)\geqslant 0.5 \text{ for } z\geqslant 0
g(z)⩾0.5 for z⩾0 。因此,模型预测
y
^
=
{
1
if
w
T
x
+
b
⩾
0
0
if
w
T
x
+
b
<
0
\hat y=\begin{cases} 1 &\text{if } \mathbf{w}^T\mathbf{x}+b\geqslant 0 \\ 0 &\text{if } \mathbf{w}^T\mathbf{x}+b<0 \end{cases}
y^={10if wTx+b⩾0if wTx+b<0
由此可见,logistic 回归输出一个线性决策边界 (linear decision boundary)
w
T
x
+
b
=
0
\mathbf{w}^T\mathbf{x}+b=0
wTx+b=0
我们也可以创建多项式特征拟合一个非线性边界。例如,模型
f
(
x
1
,
x
2
)
=
g
(
x
1
2
+
x
2
2
−
36
)
where
g
(
z
)
=
1
1
+
e
−
z
f(x_1,x_2) = g(x_1^2+x_2^2-36)\text{ where } g(z) = \cfrac{1}{1+e^{-z}}
f(x1,x2)=g(x12+x22−36) where g(z)=1+e−z1
决策边界方程为
x
1
2
+
x
2
2
−
36
=
0
x_1^2+x_2^2-36=0
x12+x22−36=0

Softmax 回归
基本形式
Softmax 回归是 Logistic 回归在多分类(Multi-Class)问题上的推广。给定的数据集
D
=
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
⋯
,
(
x
N
,
y
N
}
D=\{(\mathbf x_1,y_1),(\mathbf x_2,y_2),\cdots,(\mathbf x_N,y_N\}
D={(x1,y1),(x2,y2),⋯,(xN,yN}
包含
N
N
N 个样本,
p
p
p 个特征。其中,第
i
i
i 个样本的特征向量为
x
i
=
(
x
i
1
,
x
i
2
,
⋯
,
x
i
p
)
T
\mathbf x_i=(x_{i1},x_{i2},\cdots,x_{ip})^T
xi=(xi1,xi2,⋯,xip)T 。目标变量
y
i
∈
{
c
1
,
c
2
,
⋯
,
c
K
}
y_i\in \{c_1,c_2,\cdots,c_K\}
yi∈{c1,c2,⋯,cK} 。假设
K
K
K个类的数据集服从均值不同、方差相同的正态分布
P
(
x
∣
y
=
c
k
)
=
1
(
2
π
)
p
det
Σ
exp
(
−
1
2
(
x
−
μ
k
)
T
Σ
−
1
(
x
−
μ
k
)
)
,
k
=
1
,
2
,
⋯
,
K
\mathbb P(\mathbf x|y=c_k)=\frac{1}{\sqrt{(2\pi)^p\det\mathbf\Sigma}}\exp\left(-\frac{1}{2}(\mathbf x-\mathbf\mu_k)^T\mathbf\Sigma^{-1}(\mathbf x-\mathbf\mu_k)\right), \quad k=1,2,\cdots,K
P(x∣y=ck)=(2π)pdetΣ1exp(−21(x−μk)TΣ−1(x−μk)),k=1,2,⋯,K
其中,协方差矩阵
Σ
\mathbf\Sigma
Σ 为对称阵。利用贝叶斯定理,于类别
c
k
c_k
ck 的条件概率为
P
(
y
=
c
k
∣
x
)
=
P
(
x
∣
y
=
c
k
)
P
(
y
=
c
k
)
∑
s
=
1
K
P
(
x
∣
y
=
c
s
)
P
(
y
=
c
s
)
\mathbb P(y=c_k|\mathbf x)=\frac{\mathbb P(\mathbf x|y=c_k)\mathbb P(y=c_k)}{\sum_{s=1}^K\mathbb P(\mathbf x|y=c_s)\mathbb P(y=c_s)}
P(y=ck∣x)=∑s=1KP(x∣y=cs)P(y=cs)P(x∣y=ck)P(y=ck)
参考Logistic 回归,计算[^cdot]
ϕ
=
ln
P
(
x
∣
y
=
c
s
)
P
(
y
=
c
s
)
P
(
x
∣
y
=
c
t
)
P
(
y
=
c
t
)
=
−
1
2
(
x
−
μ
s
)
T
Σ
−
1
(
x
−
μ
s
)
+
1
2
(
x
−
μ
t
)
T
Σ
−
1
(
x
−
μ
t
)
+
ln
P
(
y
=
c
s
)
P
(
y
=
c
t
)
=
(
μ
s
−
μ
t
)
T
Σ
−
1
x
−
1
2
(
μ
s
T
Σ
−
1
μ
s
−
μ
t
T
Σ
−
1
μ
t
)
+
ln
P
(
y
=
c
s
)
−
ln
P
(
y
=
c
t
)
=
(
w
s
T
x
+
b
s
)
−
(
w
t
T
x
+
b
t
)
\begin{aligned} \phi&=\ln\frac{\mathbb P(\mathbf x|y=c_s)\mathbb P(y=c_s)}{\mathbb P(\mathbf x|y=c_t)\mathbb P(y=c_t)} \\ &=-\frac{1}{2}(\mathbf x-\mathbf \mu_s)^T\mathbf\Sigma^{-1}(\mathbf x-\mathbf \mu_s)+\frac{1}{2}(\mathbf x-\mathbf \mu_t)^T\mathbf\Sigma^{-1}(\mathbf x-\mathbf \mu_t)+\ln\frac{\mathbb P(y=c_s)}{\mathbb P(y=c_t)} \\ &=(\mathbf \mu_s-\mathbf \mu_t)^T\mathbf\Sigma^{-1}\mathbf x-\frac{1}{2}(\mu_s^T\mathbf\Sigma^{-1}\mu_s-\mu_t^T\mathbf\Sigma^{-1}\mu_t)+\ln\mathbb P(y=c_s)-\ln\mathbb P(y=c_t) \\ &=(\mathbf w_s^T\mathbf x+b_s)-(\mathbf w_t^T\mathbf x+b_t) \end{aligned}
ϕ=lnP(x∣y=ct)P(y=ct)P(x∣y=cs)P(y=cs)=−21(x−μs)TΣ−1(x−μs)+21(x−μt)TΣ−1(x−μt)+lnP(y=ct)P(y=cs)=(μs−μt)TΣ−1x−21(μsTΣ−1μs−μtTΣ−1μt)+lnP(y=cs)−lnP(y=ct)=(wsTx+bs)−(wtTx+bt)
其中
w
k
T
=
μ
k
T
Σ
−
1
,
b
k
=
−
1
2
μ
k
T
Σ
−
1
μ
k
+
ln
P
(
y
=
c
k
)
\mathbf w_k^T =\mu_k^T\mathbf\Sigma^{-1},\quad b_k =-\frac{1}{2}\mu_k^T\mathbf\Sigma^{-1}\mu_k+\ln\mathbb P(y=c_k)
wkT=μkTΣ−1,bk=−21μkTΣ−1μk+lnP(y=ck)
记
z
k
=
w
k
T
x
+
b
k
z_k=\mathbf w_k^T\mathbf x+b_k
zk=wkTx+bk,则后验概率
P
(
y
=
c
k
∣
x
)
=
1
∑
s
=
1
K
P
(
x
∣
y
=
c
s
)
P
(
y
=
c
s
)
P
(
x
∣
y
=
c
k
)
P
(
y
=
c
k
)
=
1
∑
s
=
1
K
exp
(
z
s
−
z
k
)
=
exp
(
z
k
)
∑
s
=
1
K
exp
(
z
s
)
\begin{aligned} \mathbb P(y=c_k|\mathbf x)&=\frac{1}{\sum\limits_{s=1}^K\dfrac{\mathbb P(\mathbf x|y=c_s)\mathbb P(y=c_s)}{\mathbb P(\mathbf x|y=c_k)\mathbb P(y=c_k)}} \\ &=\frac{1}{\sum_{s=1}^K\exp(z_s-z_k)} \\ &=\frac{\exp(z_k)}{\sum_{s=1}^K\exp(z_s)} \end{aligned}
P(y=ck∣x)=s=1∑KP(x∣y=ck)P(y=ck)P(x∣y=cs)P(y=cs)1=∑s=1Kexp(zs−zk)1=∑s=1Kexp(zs)exp(zk)
类别
c
k
c_k
ck 的条件概率可化简为
P
(
y
=
c
k
∣
x
)
=
softmax
(
w
k
T
x
)
=
exp
(
w
k
T
x
)
∑
k
=
1
K
exp
(
w
k
T
x
)
\mathbb P(y=c_k|\mathbf x)=\text{softmax}(\mathbf w_k^T\mathbf x)=\frac{\exp(\mathbf w_k^T\mathbf x)}{\sum_{k=1}^{K}\exp(\mathbf w_k^T\mathbf x)}
P(y=ck∣x)=softmax(wkTx)=∑k=1Kexp(wkTx)exp(wkTx)
其中,参数
w
k
=
(
b
k
,
w
k
1
,
w
k
2
,
⋯
,
w
k
p
)
T
\mathbf{w_k}=(b_k,w_{k1},w_{k2},\cdots,w_{kp})^T
wk=(bk,wk1,wk2,⋯,wkp)T 是类别
c
k
c_k
ck 的权重向量,特征向量
x
=
(
1
,
x
1
,
x
2
,
⋯
,
x
p
)
T
\mathbf x=(1,x_1,x_2,\cdots,x_p)^T
x=(1,x1,x2,⋯,xp)T。
Model: Softmax 回归输出每个类别的概率
f
(
x
;
W
)
=
1
∑
k
=
1
K
exp
(
w
k
T
x
)
(
exp
(
w
1
T
x
)
exp
(
w
2
T
x
)
⋮
exp
(
w
K
T
x
)
)
\mathbf f(\mathbf{x};\mathbf W) = \frac{1}{\sum_{k=1}^{K}\exp(\mathbf w_k^T\mathbf x)}\begin{pmatrix} \exp(\mathbf w_1^T\mathbf x) \\ \exp(\mathbf w_2^T\mathbf x) \\ \vdots \\ \exp(\mathbf w_K^T\mathbf x) \\ \end{pmatrix}
f(x;W)=∑k=1Kexp(wkTx)1
exp(w1Tx)exp(w2Tx)⋮exp(wKTx)
上式结果向量中最大值的对应类别为最终类别
y
^
=
arg
max
c
k
w
k
T
x
\hat y=\arg\max_{c_k}\mathbf w_k^T\mathbf x
y^=argckmaxwkTx
极大似然估计
为了方便起见,我们用
K
K
K 维的 one-hot 向量来表示类别标签。若第
i
i
i 个样本类别为
c
c
c,则向量表示为
y
i
=
(
y
i
1
,
y
i
2
,
⋯
,
y
i
K
)
T
=
(
I
(
c
1
=
c
)
,
I
(
c
2
=
c
)
,
⋯
,
I
(
c
K
=
c
)
)
T
\begin{aligned} \mathbf y_i&=(y_{i1},y_{i2},\cdots,y_{iK})^T \\ &=(\mathbb I(c_1=c),\mathbb I(c_2=c),\cdots,\mathbb I(c_K=c))^T \\ \end{aligned}
yi=(yi1,yi2,⋯,yiK)T=(I(c1=c),I(c2=c),⋯,I(cK=c))T
对样本联合概率取对数似然函数
log
L
(
W
)
=
log
∏
i
=
1
N
P
(
y
i
∣
x
i
)
=
∑
i
=
1
N
log
P
(
y
i
∣
x
i
)
=
∑
i
=
1
N
log
y
i
T
f
(
x
i
;
W
)
\begin{aligned} \log L(\mathbf W) & =\log\prod_{i=1}^{N} \mathbb P(y_i|\mathbf x_i)=\sum_{i=1}^N\log \mathbb P(y_i|\mathbf x_i) \\ &=\sum_{i=1}^{N}\log\mathbf y_i^T\mathbf f(\mathbf x_i;\mathbf W) \end{aligned}
logL(W)=logi=1∏NP(yi∣xi)=i=1∑NlogP(yi∣xi)=i=1∑NlogyiTf(xi;W)
参数估计:可通过梯度下降法、牛顿法等求解
K
×
(
p
+
1
)
K\times(p+1)
K×(p+1)权重矩阵
W
\mathbf W
W
W
^
=
arg
max
W
∑
i
=
1
N
log
y
i
T
f
(
x
i
;
W
)
\hat{\mathbf W}=\arg\max_{\mathbf W}\sum_{i=1}^{N}\log\mathbf y_i^T\mathbf f(\mathbf x_i;\mathbf W)
W^=argWmaxi=1∑NlogyiTf(xi;W)
对数似然函数
log
L
(
W
)
\log L(\mathbf W)
logL(W) 关于
W
\mathbf W
W 的梯度为
∂
log
L
(
W
)
∂
W
=
∑
i
=
1
N
x
i
(
y
i
−
f
(
x
i
;
W
)
)
T
\frac{\partial \log L(\mathbf W)}{\partial\mathbf W}=\sum_{i=1}^{N}\mathbf x_i(\mathbf y_i-\mathbf f(\mathbf x_i;\mathbf W))^T
∂W∂logL(W)=i=1∑Nxi(yi−f(xi;W))T
感知机
感知机(Perceptron)是线性二分类模型,适用于线性可分的数据集。
Model:感知机选取符号函数为激活函数
f
w
,
b
(
x
)
=
sign
(
w
T
x
+
b
)
f_{\mathbf{w},b}(\mathbf{x})=\text{sign}(\mathbf{w}^T\mathbf{x}+b)
fw,b(x)=sign(wTx+b)
这样就可以将线性回归的结果映射到两分类的结果上了。符号函数
sign
(
z
)
=
{
+
1
if
z
⩾
0
−
1
if
z
<
0
\text{sign}(z)=\begin{cases}+1 & \text{if }z\geqslant 0\\ -1 & \text{if }z<0\end{cases}
sign(z)={+1−1if z⩾0if z<0
为计算方便,引入
x
0
=
1
,
w
0
=
b
x_0=1,w_0=b
x0=1,w0=b 。模型简写为
f
w
(
x
)
=
sign
(
w
T
x
)
f_{\mathbf{w}}(\mathbf{x}) = \text{sign}(\mathbf{w}^T\mathbf{x})
fw(x)=sign(wTx)
其中,特征向量
x
=
(
x
0
,
x
1
,
x
2
,
⋯
,
x
p
)
T
\mathbf x=(x_0,x_1,x_2,\cdots,x_p)^T
x=(x0,x1,x2,⋯,xp)T,权重向量
w
=
(
w
0
,
w
1
,
w
2
,
⋯
,
w
p
)
T
\mathbf{w}=(w_0,w_1,w_2,\cdots,w_p)^T
w=(w0,w1,w2,⋯,wp)T
cost function:误分类点到分离超平面的总距离
J
(
w
)
=
−
∑
x
i
∈
M
y
i
w
T
x
i
J(\mathbf w)=-\sum_{\mathbf x_i\in M}y_i\mathbf{w}^T\mathbf{x}_i
J(w)=−xi∈M∑yiwTxi
其中,
M
M
M 是错误分类集合。
基于梯度下降法对代价函数的最优化算法,有原始形式和对偶形式。算法简单且易于实现。
损失函数的梯度
∇
J
(
w
)
=
−
∑
x
i
∈
M
y
i
x
i
\nabla J(\mathbf w)=-\sum_{\mathbf x_i\in M}y_i\mathbf{x}_i
∇J(w)=−xi∈M∑yixi
感知机有无穷多个解,其解由于不同的初始值或不同的迭代顺序而有所不同。
Perceptron 是另一种适用于大规模学习的简单分类算法。
- 它不需要设置学习率
- 它不需要正则项
- 它只用错误样本更新模型
最后一个特点意味着Perceptron的训练速度略快于带有合页损失(hinge loss)的SGD,因此得到的模型更稀疏。
被动感知算法 (Passive Aggressive Algorithms) 是一种大规模学习的算法。和感知机相似,因为它们不需要设置学习率。然而,与感知器不同的是,它们包含正则化参数。
多类别分类
Multi-class classification:目标变量包含两个以上离散值的分类任务 y ∈ { c 1 , c 2 , ⋯ , c K } y\in\{c_1,c_2,\cdots,c_K\} y∈{c1,c2,⋯,cK}。每个样本只能标记为一个类。例如,使用从一组水果图像中提取的特征进行分类,其中每一幅图像都可能是一个橙子、一个苹果或一个梨。每个图像就是一个样本,并被标记为三个可能的类之一。

-
One-Vs-Rest (OVR) 也称为one-vs-all,为每个类分别拟合一个二分类模型,这是最常用的策略,对每个类都是公平的。这种方法的一个优点是它的可解释性,每个类都可以查看自己模型的相关信息。
-
One-Vs-One (OVO) 是对每一对类分别拟合一个二分类模型。在预测时,选择得票最多的类别。在票数相等的两个类别中,它选择具有最高总分类置信度的类别,方法是对由底层二分类器计算的对分类置信度进行求和。
由于它需要拟合 K ( K − 1 ) 2 \frac{K(K-1)}{2} 2K(K−1) 个分类器,这种方法通常比one-vs-rest要慢,原因就在于其复杂度 O(K2) 。然而,这个方法也有优点,比如说是在没有很好的缩放样本数的核方法中。这是因为每个单独的学习问题只涉及一小部分数据,而对于一个 one-vs-rest,完整的数据集将会被使用 K 次。
One-Vs-Rest:为每个类分别拟合一个二分类模型
f
w
,
b
i
(
x
)
=
P
(
y
=
i
∣
x
;
w
,
b
)
f^i_{\mathbf{w},b}(\mathbf{x})=\mathbb P(y=i|\mathbf x;\mathbf w,b)
fw,bi(x)=P(y=i∣x;w,b)
模型预测值,一种方法是选择概率最大的类别
y
^
=
arg
max
i
f
w
,
b
i
(
x
)
\hat y=\arg\max\limits_{i} f^i_{\mathbf{w},b}(\mathbf{x})
y^=argimaxfw,bi(x)

多标签分类
包含多个目标变量的分类任务称为 Multilabel classification