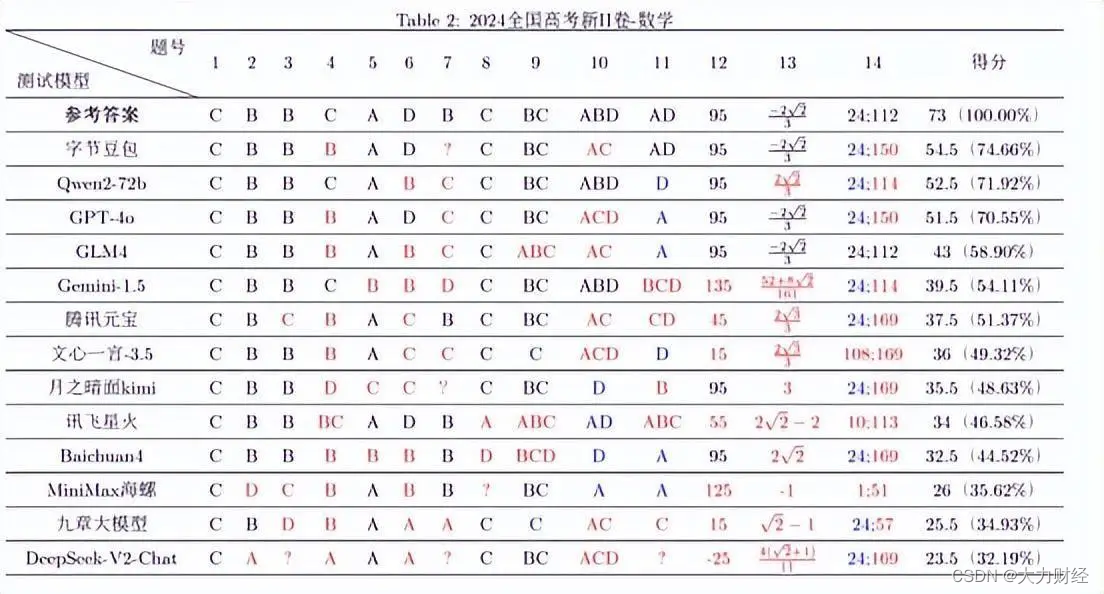
目录
- 1 字符串
- 2 列表
- 3 字典
- 4 列表中是字典
- 5 if语句
- 6 案例:使用爬虫爬取联通新闻并在页面渲染
模板语法本质上:在HTML中写一些占位符,由数据对这些占位符进行替换和处理。模板语法主要是方便对方法返回的数据在前端进行渲染,这些数据类型包括如下几个:
- 字符串
- 列表
- 字典
- 列表中是字典数据等
首先定义返回tpl函数
path('tpl', views.tpl),
新建tpl函数
def tpl(request):
return render(request, 'tpl.html')
1 字符串
定义字符串变量,并返回给tpl.html页面
def tpl(request):
name = '不写八个'
return render(request, 'tpl.html', {"label": name})
在页面渲染
<div class="panel panel-primary">
<div class="panel-heading">模板语法学习</div>
<div class="panel-body">
<!--字符串-->
<h3>{{label}}</h3>
</div>
</div>
渲染效果

2 列表
定义列表数据并返回
def tpl(request):
roles = ['作者', '学生', '程序员']
return render(request, 'tpl.html', {"roles": roles})
在页面渲染
<!--列表-->
<div style="margin-top: 10px">
<ul class="list-group" style="width: 200px">
<li class="list-group-item list-group-item-success">{{roles.0}}</li>
<li class="list-group-item list-group-item-info">{{roles.1}}</li>
<li class="list-group-item list-group-item-warning">{{roles.2}}</li>
</ul>
</div>
<div>
{% for item in roles %}
<span>{{item}}</span>
{% endfor %}
</div>
渲染效果

3 字典
定义字典数据并返回
def tpl(request):
user_info = {
"name": name,
"role": "CEO",
"salary": 20000,
}
return render(request, 'tpl.html', {"user_info": user_info})
在页面渲染
<!--字典-->
{{user_info.name}}
{{user_info.role}}
{{user_info.salary}}
<div>
{% for k,v in user_info.items %}
<span>{{k}}=={{v}}</span>
{% endfor %}
</div>
渲染效果
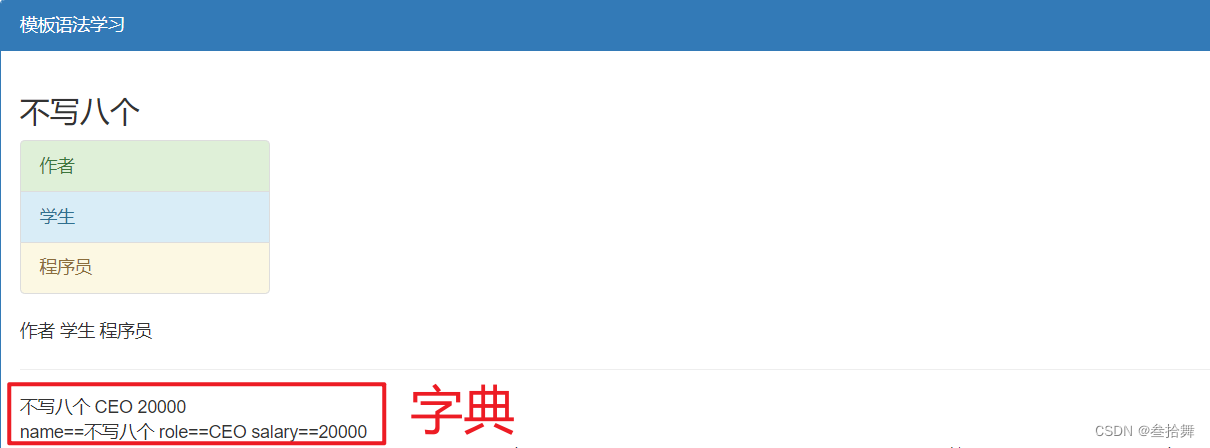
4 列表中是字典
定义数据
def tpl(request):
data_list = [
{
"name": '杜兰特',
"role": "小前锋",
"salary": 2000000,
},
{
"name": '欧文',
"role": "分卫",
"salary": 2000000,
},
{
"name": '哈登',
"role": "控卫",
"salary": 2000000,
}
]
return render(request, 'tpl.html', {"data_list": data_list})
在页面渲染
<!--列表里面有字典-->
<div>
{{data_list}}
{{data_list.1.name}}
</div>
<table class="table table-striped" style="width: 300px">
<thead>
<tr>
<th>姓名</th>
<th>位置</th>
<th>工资</th>
</tr>
</thead>
<tbody>
{% for item in data_list %}
<tr>
<td>{{item.name}}</td>
<td>{{item.role}}</td>
<td>{{item.salary}}</td>
</tr>
{% endfor %}
</tbody>
</table>
渲染效果
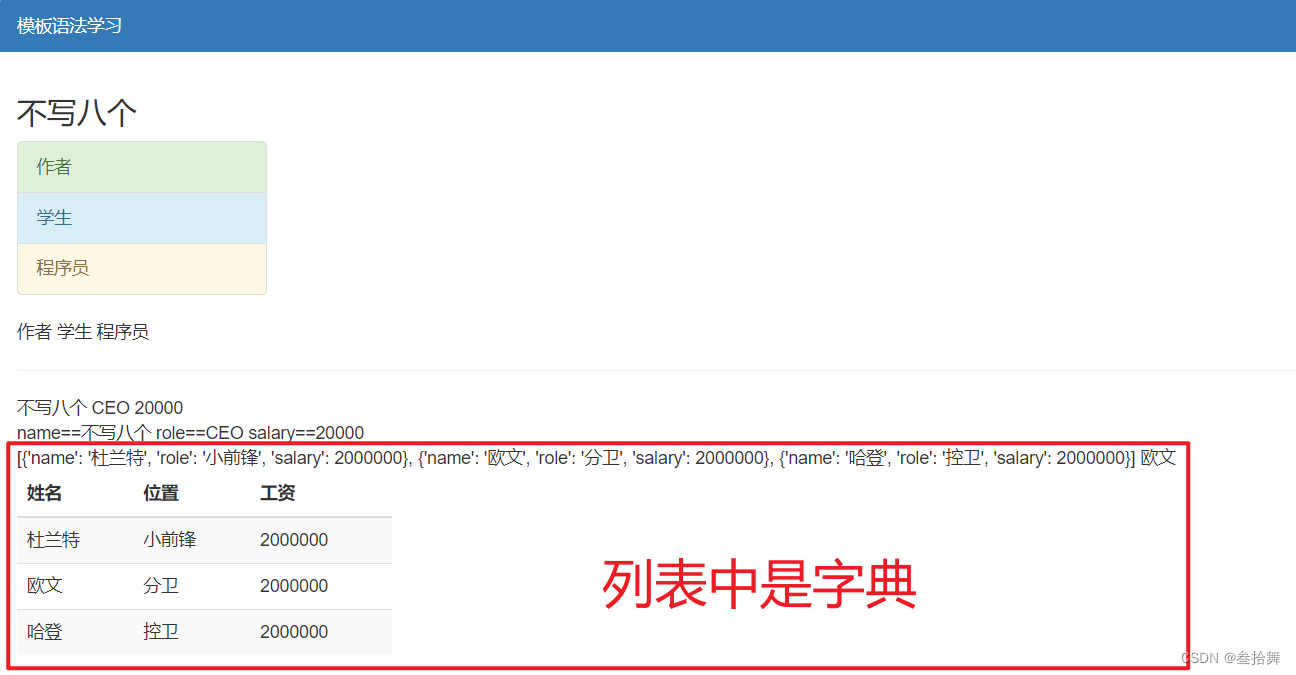
5 if语句
{% if label == "不写八个" %}
<h3>是作者</h3>
{% else %}
<h3>不是作者</h3>
{% endif %}
效果
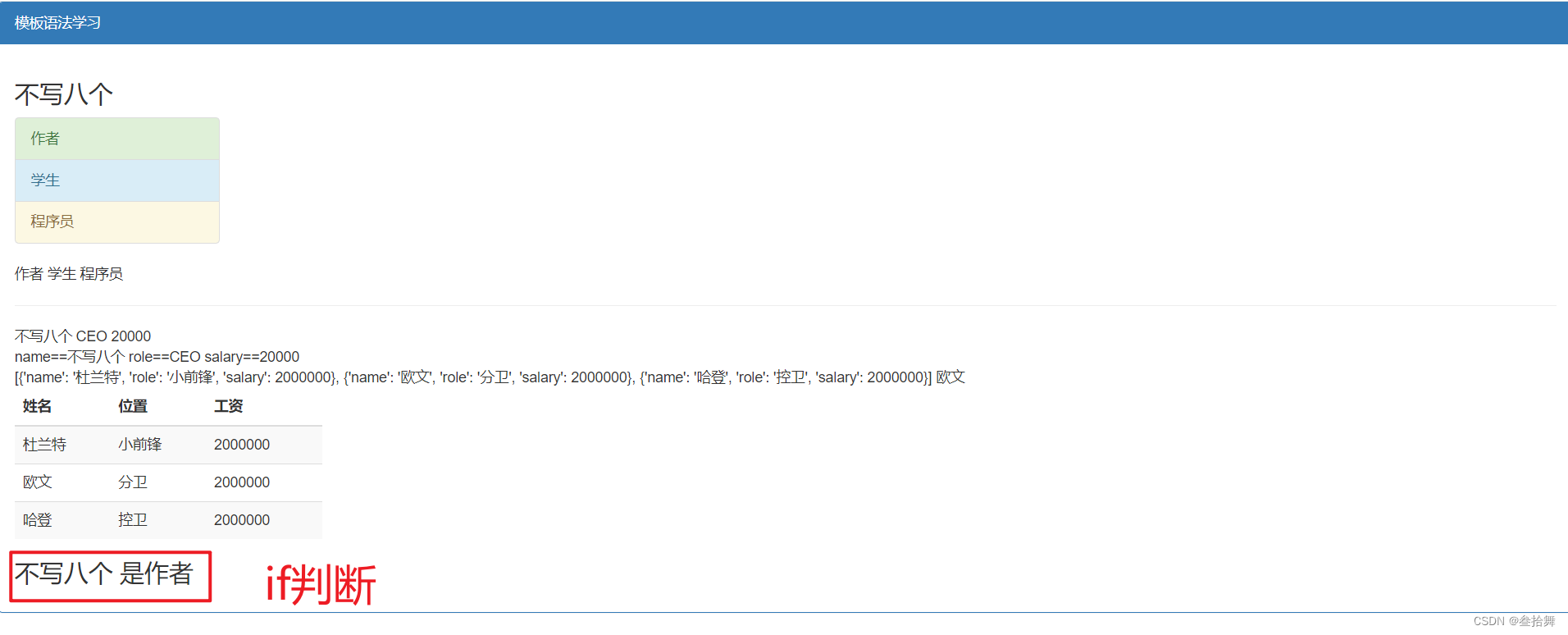
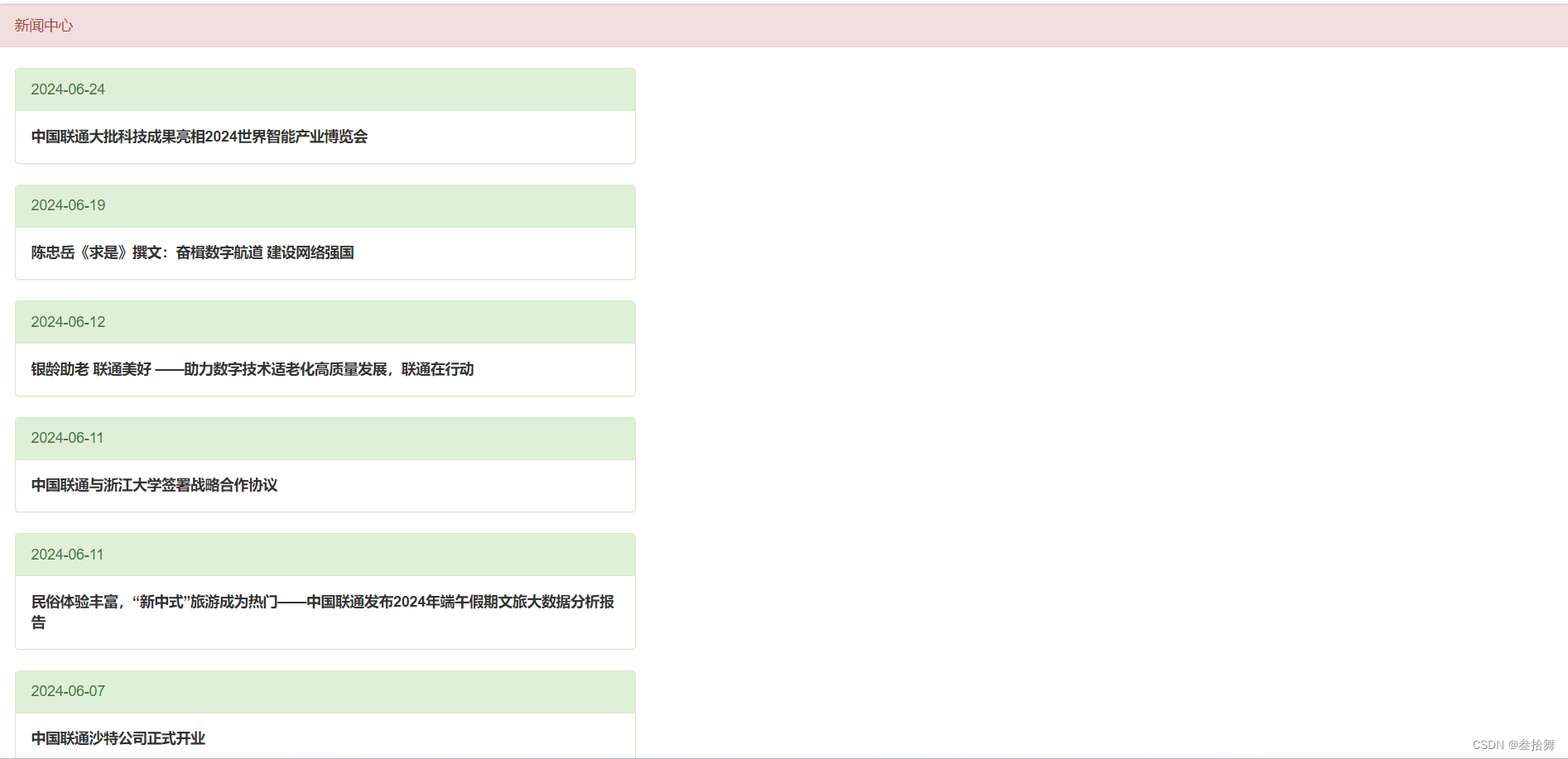
6 案例:使用爬虫爬取联通新闻并在页面渲染
创建url,调用新闻news函数
path('news', views.news),
创建新闻news函数:
爬取联通新闻,使用BeautifulSoup库解析爬取到的html,
soup = BeautifulSoup(res.text, 'html.parser')
requests和BeautifulSoup库的安装
pip install requests pip install bs4
获取解析结果中的tr中的内容,并将结果添加到new_list中,返回给页面,完整代码如下:
def news(request):
# 定义一些新闻(字典或者列表)或数据库,或者网络请求
# 向地址发送请求 https://www.chinaunicom.com.cn/43/menu01/1/column05
res = requests.get('https://www.chinaunicom.com.cn/43/menu01/1/column05', headers={"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36"})
new_list = []
soup = BeautifulSoup(res.text, 'html.parser')
tr_list = soup.find_all('tr')
for tr in tr_list:
td_list = tr.find_all('td')
news_info = {
'title': td_list[0].text.strip(),
'date': td_list[1].text.strip(),
}
new_list.append(news_info)
return render(request, 'news.html', {"new_list": new_list})
新建news.html页面,并渲染新闻数据
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<link rel="stylesheet" href="/static/plugins/bootstrap-3.4.1-dist/css/bootstrap.css">
<script src="/static/js/jquery.min.js"></script>
<script src="/static/plugins/bootstrap-3.4.1-dist/js/bootstrap.js"></script>
</head>
<body>
<div>
<div class="panel panel-danger">
<div class="panel-heading">新闻中心</div>
<div class="panel-body">
{% for item in new_list %}
<div class="panel panel-success" style="margin-top: 5px;width: 600px">
<div class="panel-heading">{{item.date}}</div>
<div class="panel-body" style="font-weight: bold">
{{item.title}}
</div>
</div>
{% endfor %}
</div>
</div>
</div>
</body>
</html>
渲染效果