第1章 - 高性能计算介绍
1. 概念:
高性能计算(High performance computing,缩写HPC):
指通常使用很多处理器(作为单个机器的一部分)或者某一集群中组织的几台计算机(作为单个计算资源操作)的计算系统和环境,执行一般个人电脑无法处理的大量资料与高速运算,其基本组成组件与个人电脑的概念无太大差异, 但规格与性能则强大许多
2. 性能衡量
2.1. HPL(High Performance Linpack)
2.1.1. 概念
现代高性能计算机通用的基准测试程序 。Linpack是用于测试高性能计算机系统浮点性能的基准测试程序。通过对高性能计算机采用高斯消元法求解一元N次稠密线性代数方程组的测试,评价高性能计算的浮点性能。
2.1.2. 衡量性能单位:
每秒浮点运算次数 。
- FLOPS ( floating point operations per second )
指每秒浮点运算次数,用来衡量硬件的性能(注意全部大写 )
- FLOPs ( floating point of operations )
浮点运算次数, 用来衡量算法/模型复杂度。
浮点运算包括所有涉及小数的运算,比整数运算更费时间。 现今大部分处理器中都有浮点运算器。因此每秒浮点运算次数所测量的实际上就是浮点运算器的执行速度。

2.2. HPCC(High Performance Computing Challenge)
是面向高性能计算机的综合测试程序包,能够测试高性能计算机系统多个方面的性能,包括处理器速度、存储访问速度和网络通信速度,对各种应用都有一定的代表性和参考价值
HPL简单易操作,结果直接明了,但不够精细,HPL评测标准显得过于粗略。HPCC充分弥补了HPL的一些缺点,对性能跨度非常大的各个方面都进行了充分的测试。
但也存在一些问题,那就是没有一个统一的结果评价标准,评价体系的构建不方便。
2.3. HPCG(High Performance Conjugate Gradients) ——高性能共轭梯度基准测试
是现在主要测试超算性能程序之一,也是 TOP500的一项重要指标。一般来讲HPCG的测试结果会比 HPL低很多,常常只有百分几。
高性能共轭梯度算法(HPCG) 所使用的计算模式与HPL 相比,更符合当前实际应用业务的特点,给出的测试结论对于HPC的发展更有参考价值
2.4. 其他
- 计算峰值是指计算机每秒完成的浮点计算最大次数,它包括理论浮点峰值和实测浮点峰值。
- 运算性能(实测浮点峰值,Rmax)是Linpack值,也就是一台机器上运行Linpack测试程序,通过各种优化方法得到的最优 测试结果。
- 峰值性能(理论浮点峰值, Rpeak)是计算机在理论上能达到的每秒完成的浮点计算最大次数,它主要是由CPU的主频决定的
3. 并行程序
3.1. 概念
能够使用多个核(处理器)一起工作来解决单一 问题
作用
-
节省时间
-
- 使用更多的资源缩短执行时间,进而可能节约成本
- 缩短执行时间,进而允许运行更多的程序或有更多的调试 机
-
求解更大的问题
-
- 可解决在单台计算机上无法解决的问题
- 科学计算(Scientificcomputing
3.2. 并行程序的编写(任务并行和数据并行)
- 任务并行
将待解决问题的各个任务分配到各个核上执行
- 数据并行
将待解决问题需要处理的数据分配到各个核上,每个核在分配的数据集上执行大致相似的操作.


3.3. 协调
各个核之间经常需要协调工作.
- 通信:一个或多个核需要将自己的部分和发送给其他核.
- 负载平衡:将任务量平均分配给各个核.
- 同步:每个核都以自己的速度工作,核之间不会自动同步
3.4. 常见概念
- 并发计算(concurrentcomputing): 一个程序的多个任务在同一个时间段内可以同时执行;
- 并行计算(parallelcomputing): 一个程序通过多个任务紧密协作来解决某一个问题;
- 分布式计算(distributedcomputing): 一个程序需要与其它程序协作来解决某个问题;
并行计算与分布式计算都属于并发计算
并行计算与分布式计算的区别
相似点:都是为了实现比较复杂的任务,将大的任务分解成小的任务,在 多台计算机上同时计算


计算机体系结构的发展及相应的编程模型/模式(单核、多核、分布式 和异构)
4. 习题
- 为求全局总和例子中的my_first_i和my_last_i推导一 个公式。需要注意的是:在循环中,应该给各个核 分配大致相同的计算元素。提示:先考虑n能被p整 除的情况。
解答:
当 n n n 能被 p p p 整除时:
对于每个处理器核心 ## 第1章 - 高性能计算介绍
1. 概念:
高性能计算(High performance computing,缩写HPC):
指通常使用很多处理器(作为单个机器的一部分)或者某一集群中组织的几台计算机(作为单个计算资源操作)的计算系统和环境,执行一般个人电脑无法处理的大量资料与高速运算,其基本组成组件与个人电脑的概念无太大差异, 但规格与性能则强大许多
2. 性能衡量
2.1. HPL(High Performance Linpack)
2.1.1. 概念
现代高性能计算机通用的基准测试程序 。Linpack是用于测试高性能计算机系统浮点性能的基准测试程序。通过对高性能计算机采用高斯消元法求解一元N次稠密线性代数方程组的测试,评价高性能计算的浮点性能。
2.1.2. 衡量性能单位:
每秒浮点运算次数 。
- FLOPS ( floating point operations per second )
指每秒浮点运算次数,用来衡量硬件的性能(注意全部大写 )
- FLOPs ( floating point of operations )
浮点运算次数, 用来衡量算法/模型复杂度。
浮点运算包括所有涉及小数的运算,比整数运算更费时间。 现今大部分处理器中都有浮点运算器。因此每秒浮点运算次数所测量的实际上就是浮点运算器的执行速度。

2.2. HPCC(High Performance Computing Challenge)
是面向高性能计算机的综合测试程序包,能够测试高性能计算机系统多个方面的性能,包括处理器速度、存储访问速度和网络通信速度,对各种应用都有一定的代表性和参考价值
HPL简单易操作,结果直接明了,但不够精细,HPL评测标准显得过于粗略。HPCC充分弥补了HPL的一些缺点,对性能跨度非常大的各个方面都进行了充分的测试。
但也存在一些问题,那就是没有一个统一的结果评价标准,评价体系的构建不方便。
2.3. HPCG(High Performance Conjugate Gradients) ——高性能共轭梯度基准测试
是现在主要测试超算性能程序之一,也是 TOP500的一项重要指标。一般来讲HPCG的测试结果会比 HPL低很多,常常只有百分几。
高性能共轭梯度算法(HPCG) 所使用的计算模式与HPL 相比,更符合当前实际应用业务的特点,给出的测试结论对于HPC的发展更有参考价值
2.4. 其他
- 计算峰值是指计算机每秒完成的浮点计算最大次数,它包括理论浮点峰值和实测浮点峰值。
- 运算性能(实测浮点峰值,Rmax)是Linpack值,也就是一台机器上运行Linpack测试程序,通过各种优化方法得到的最优 测试结果。
- 峰值性能(理论浮点峰值, Rpeak)是计算机在理论上能达到的每秒完成的浮点计算最大次数,它主要是由CPU的主频决定的
3. 并行程序
3.1. 概念
能够使用多个核(处理器)一起工作来解决单一 问题
作用
-
节省时间
-
- 使用更多的资源缩短执行时间,进而可能节约成本
- 缩短执行时间,进而允许运行更多的程序或有更多的调试 机
-
求解更大的问题
-
- 可解决在单台计算机上无法解决的问题
- 科学计算(Scientificcomputing
3.2. 并行程序的编写(任务并行和数据并行)
- 任务并行
将待解决问题的各个任务分配到各个核上执行
- 数据并行
将待解决问题需要处理的数据分配到各个核上,每个核在分配的数据集上执行大致相似的操作.


3.3. 协调
各个核之间经常需要协调工作.
- 通信:一个或多个核需要将自己的部分和发送给其他核.
- 负载平衡:将任务量平均分配给各个核.
- 同步:每个核都以自己的速度工作,核之间不会自动同步
3.4. 常见概念
- 并发计算(concurrentcomputing): 一个程序的多个任务在同一个时间段内可以同时执行;
- 并行计算(parallelcomputing): 一个程序通过多个任务紧密协作来解决某一个问题;
- 分布式计算(distributedcomputing): 一个程序需要与其它程序协作来解决某个问题;
并行计算与分布式计算都属于并发计算
并行计算与分布式计算的区别
相似点:都是为了实现比较复杂的任务,将大的任务分解成小的任务,在 多台计算机上同时计算


计算机体系结构的发展及相应的编程模型/模式(单核、多核、分布式 和异构)
4. 习题
- 为求全局总和例子中的my_first_i和my_last_i推导一 个公式。需要注意的是:在循环中,应该给各个核 分配大致相同的计算元素。提示:先考虑n能被p整 除的情况。
解答:
当 n n n 能被 p p p 整除时:
对于每个处理器核心 


当  不能被
不能被  整除时:
整除时:
设  和
和  :
:
对于前  个核心(即 (
个核心(即 (  ):
):


对于后  个核心(即
个核心(即  :
:


- 全局总和例子的第一部分(每个核对分配给它的计算值求和),通常认为是数据并行的例子;而第一个求全局总和例 子的第二个部分(各个核将它们计算出的部分和发送给 master核,master核将这些部分和再累加求和),认为是任务 并行。 第二个树形结构的全局和例子(各个核使用树形结构累加它 们的部分和),是数据并行的例子还是任务并行的例子?为 什么?
该示例是任务和数据并行的组合。 在树结构全局求和的每个阶段,核心都在计算部分求和。 这可以看作是数据并行。 此外,在每个阶段,有两种类型的任务。 一些内核正在发送它们的总和,而一些内核正在接收另一个内核的部分总和。 这可以看作是任务并行。
第二章 - 并行硬件和并行软件
1. 基本概念
1.1. 冯诺依曼结构
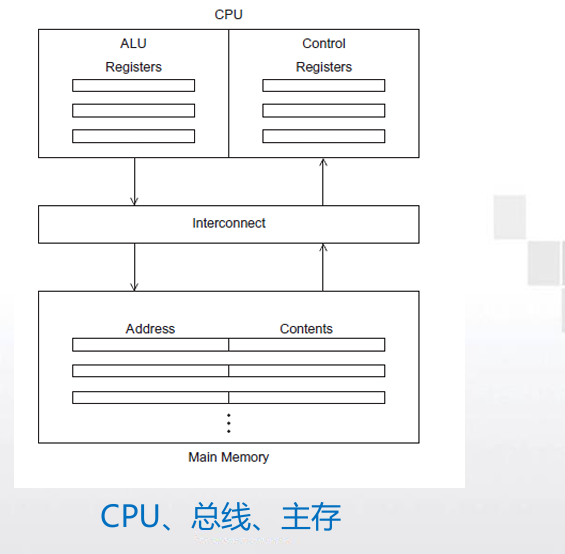
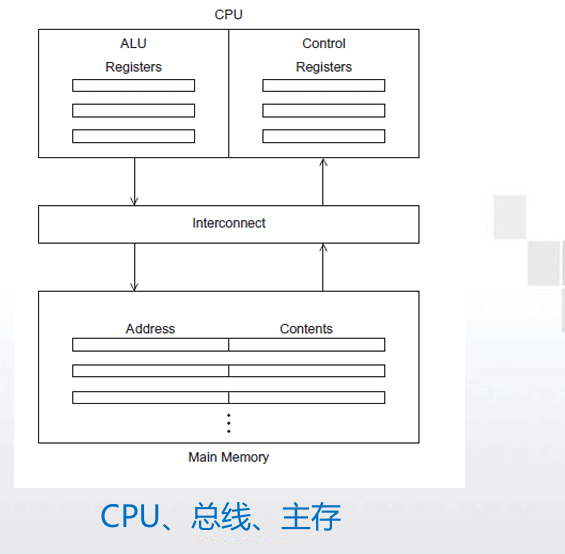
- 中央处理器(CPU)
- 控制单元-负责决定应该执行程序中的哪些指 令。(the boss)
- 算术逻辑单元(ALU) -负责执行指令。 (the worker )
- 关键术语
- CPU中的数据和程序执行时的状态信息存储在特殊的快速存储介质中,这种介质就是寄存器。
- 程序计数器:用来存放下一条指令的地址(控制单元的一 个特殊的寄存器).
- 总线:包括一组并行的线以及控制这些线的硬件。它是 CPU和主存之间的互连结构,能够进行传输指令和数据。
- 主存
- 主存中有许多区域,每个区域都可以存储指令和数据。
- 每个区域都有一个地址,可以通过这个地址来访问相应的区域及区域中存储的数据和指令。
- 冯诺依曼瓶颈
- 主存和CPU之间的分离称为冯诺依曼瓶颈。
- 互连结构限定了指令和数据访问的速率。
1.2. 缓存
-
冯诺依曼模型的改进
-
- 不再将所有的数据和指令存储在主存中,可以将部分数据块或者代码块存储在一个靠近CPU寄存器的特殊存储器里。
-
高速缓冲存储器简称缓存
-
- 访问它的时间比访问其它存储区域时间短。
- 相比于主存,CPU能更快速地访问的存储区域。(一般与CPU位于同一块芯片 )
1.3. 进程
正在运行的程序的实例
2. 并行硬件
2.1. Flynn经典分类
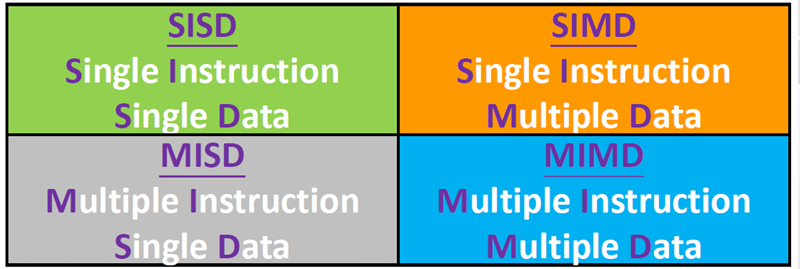
从处理器的角度进行分类:按照处理器能够同时管理的指令流数目和数据流数目来对系统分类。
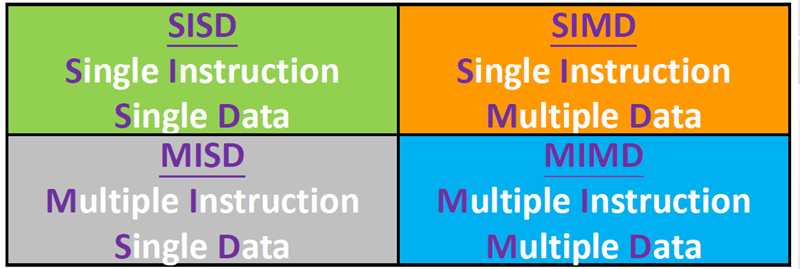
2.1.1. 单指令单数据流(SISD)
是一个串行的计算机系统
-
单指令:在一个时钟周期内只有一个指令流被CPU进行处理。
-
单数据:在一个时钟周期内只有一个数据流作为输入而使用。
-
Example:
-
- ✓冯诺依曼系统
- ✓单核处理器
2.1.2. 单指令多数据流(SIMD)
是并行系统。
-
单指令:在一个时钟周期内,所有的处理器单元执行相同的指令
-
多数据流:每个处理器单元能够作用在不同的数据单元上。
-
SIMD系统通过对多个数据执行相同的指令从而实现在多个数据流上的操作
-
通过在处理器之间划分数据实现并行性(数据并行)
-
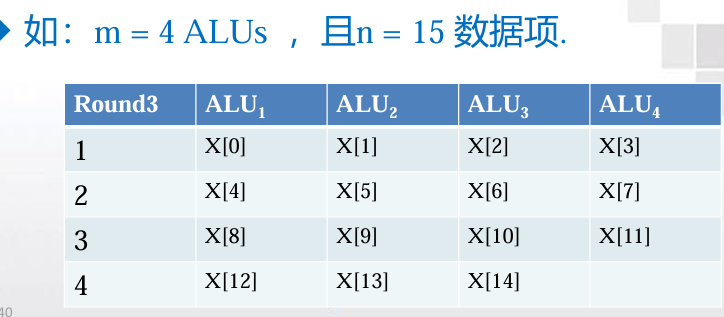
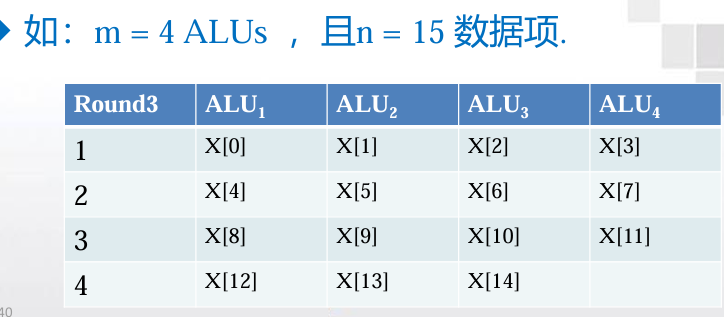
如果没有足够多的ALU分配给各个数据项应该怎么办?
划分工作,并进行迭代循环处理。
-
缺陷
-
- 在经典的SIMD设计中,ALU必须同步操作.
- 所有的ALU需要执行相同的指令或处于空闲状态.
- SIMD适合处理大型数据并行问题,但是在处理其它类型或更复杂问题上并不适合,性能较差
-
Example
-
- 向量处理器
- 图形处理单元(Graphics processing unit, GPU)
2.1.3. 多指令单数据流(MISD)
- 多指令:每个处理单元通过单独的指令流独立地对数据进行操作.
- 单数据流:单个数据流被输入多个处理单元
2.1.4. 多指令多数据流(MIMD)
- 多指令:每个处理器可能执行不同的指令流
- 多数据:每个处理器可能使用不同的数据流
- 支持多个指令流同时运行在多个数据流上
- 通常由完全独立的处理单元或核心组成,每个处理单元都有自己的控制单元和ALU.
- Example:大多数现代计算机,如多核CPU
2.2. 内存结构分类
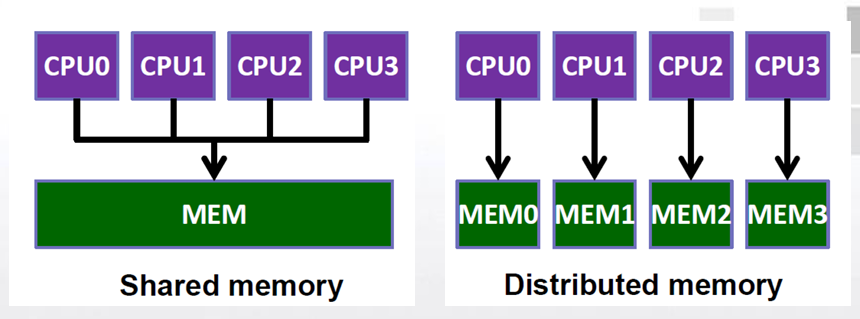
- 共享内存计算机体系结构
- 分布式内存计算机体系结构
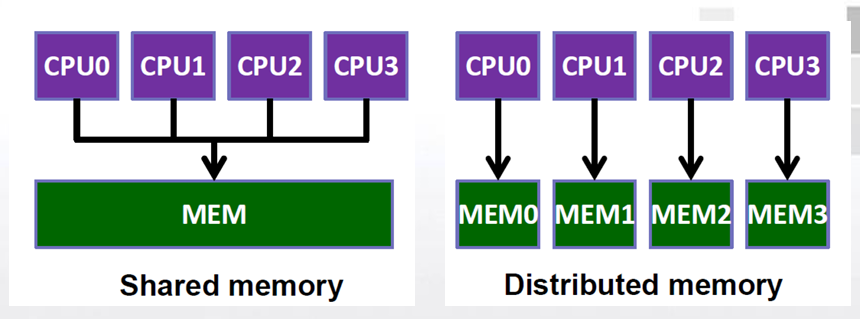
2.2.1. 共享内存系统
-
一组自治的处理器通过互连网络与内存系统连接.
-
各个核可以共享访问计算机的内存系统,每个处理器能够访问每个内存区域.
-
可以通过检测和更新内存系统来协调各个核,处理器通过访问共享的数据结构来隐式的通信
-
- 大多数共享内存系统使用一个多核处理器或者多个多核处理器
- 在一块芯片上 有多个CPU或者核
- 一致内存访问(UMA):互连网络将所有的处理器直接连到主存。
每个核访问内存任意位置的时间相等 。如:对称多处理器(SMP)
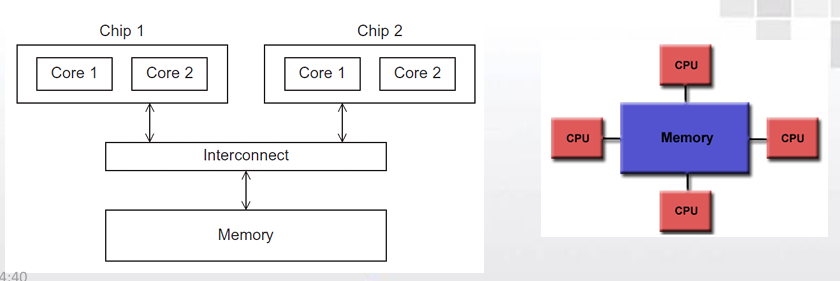
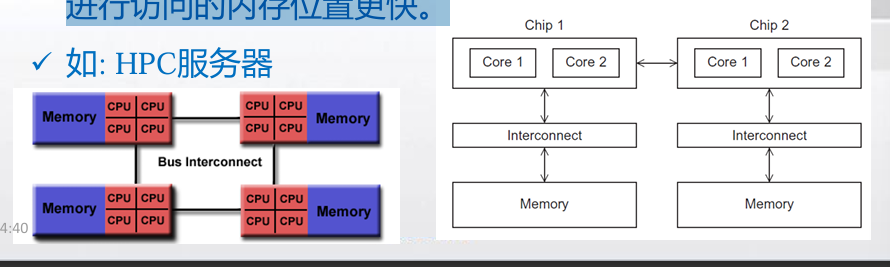
- 非一致内存访问(NUMA):将每个处理器直接连到单独的一 块内存上,然后通过处理器中内置的特殊硬件使得各个处理器可以访问内存中的其它块。
- 通常是通过物理连接两个或多个SMP来实现的
- 一个SMP可以直接访问另一个SMP的内存
- 访问核直接连接到的内存位置比必须通过另一个芯片 进行访问的内存位置更快。
- UMA与NUMA系统的特点:
- 一致内存访问(UMA)系统容易编程。
- 非一致内存访问(NUMA)系统拥有更大容量的内存
2.2.2. 分布式内存系统
- 每个核都有自己独立的私有的内存.
- 核之间的通信需要通过网络发送消息,进行显式的通信.
- 将多台计算机连接起来形成一个计算平台,而没有共享内存
网络提供一种基础架构,使地理上分布的计算机大型 网络转换成一个分布式内存系统。

2.3. 互连网络
两类: ✓共享内存互连 ✓分布式内存互连
3. 并行软件
-
共享内存程序:
-
- 启动单个进程和派生线程.
- 线程执行任务.
-
分布式内存程序:
-
- 启动多个进程.
- 进程执行任务
➢分布式内存编程模型(MPI、MapReduce)
➢共享内存编程模型(Pthreads、OpenMP)
➢异构系统的编程模型(CUDA、OpenCL)


第三章 - MPI
1. MPI简介
MPI(Message-Passing Interface)
分布式内存编程模型
- 编译: mpicc-g -Wall -o mpi_hello mpi_hello.c
- mpicc : 调用MPI编译器,将源代码编译成可执行文件。
- -g: 生成调试信息
- -Wall : 开启所有警告信息选项
- -o mpi_hello : 指定编译生成的可执行文件的名称
- mpi_hello.c : 源代码文件名。
- 执行: mpiexec -n 1 ./mpi_hello
- -n 1:指定运行的进程数,这里设置为1。
- ./mpi_hello:要运行的可执行文件路径和名称。
2. MPI点对点通信
2.1. 基本函数
-
MPI_Init(&argc, &argv);:初始化MPI环境,使得MPI库可以被使用。每个进程都需要调用一次 MPI_Init。
-
MPI_Finalize();:结束MPI环境,每个进程都需要调用一次 MPI_Finalize,表示MPI程序的结束。
-
MPI_Comm_size(MPI_COMM_WORLD, &comm_sz);:获取默认通信子 MPI_COMM_WORLD 中的总进程数,并将其存储在 comm_sz 变量中。例如,如果启动了4个进程,那么 comm_sz 的值就是4。
-
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);:获取当前进程在 MPI_COMM_WORLD 中的排名,并将其存储在 my_rank 变量中。每个进程都有一个唯一的 my_rank,在 0 到 comm_sz - 1 之间。
-
MPI_Send(buf,count,datatype,dest,tag,comm) -
- MPI_Send(greeting, strlen(greeting) + 1, MPI_CHAR, 0, 0, MPI_COMM_WORLD);:
- 定义:使用MPI_Send函数发送消息。
- 参数解释:
-
-
- greeting:要发送的消息数据。
- strlen(greeting) + 1:消息的长度,加1是为了包括字符串的终止符\0。
- MPI_CHAR:消息的数据类型,这里是字符数组。
- 0:消息接收者的排名,即将消息发送到排名为0的进程。
- 0:消息的标签(tag),可以用来区分不同类型的消息。
- MPI_COMM_WORLD:通信子,表示所有MPI进程的默认通信子。
-
-
- 作用:将格式化后的问候消息发送到排名为0的进程。
-
MPI_Recv(buf,count,datatype,source,tag,comm,status) -
- MPI_Recv(greeting, MAX_STRING, MPI_CHAR, q, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
-
-
- buf:greeting 是接收缓冲区,用于存储接收到的字符串。
- count:MAX_STRING 指定接收缓冲区的最大大小(100)。
- datatype:MPI_CHAR 指定接收的数据类型为字符。
- source:q 表示消息的发送者,q 从 1 到 comm_sz-1(非零进程)。
- tag:0 指定接收的消息标签。
- comm:MPI_COMM_WORLD 表示所有进程的默认通信子。
- status:MPI_STATUS_IGNORE 忽略接收消息的状态信息。
-
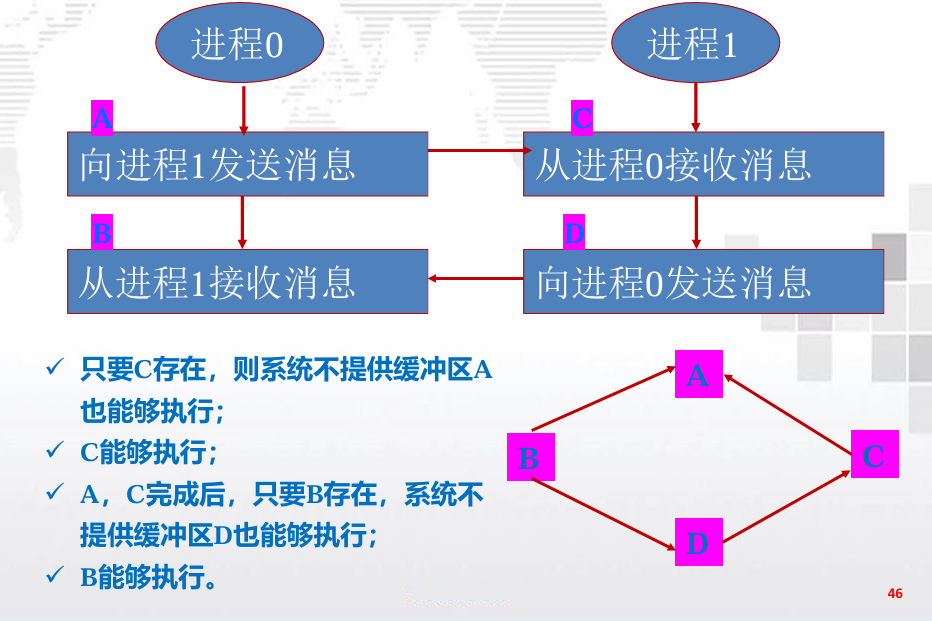
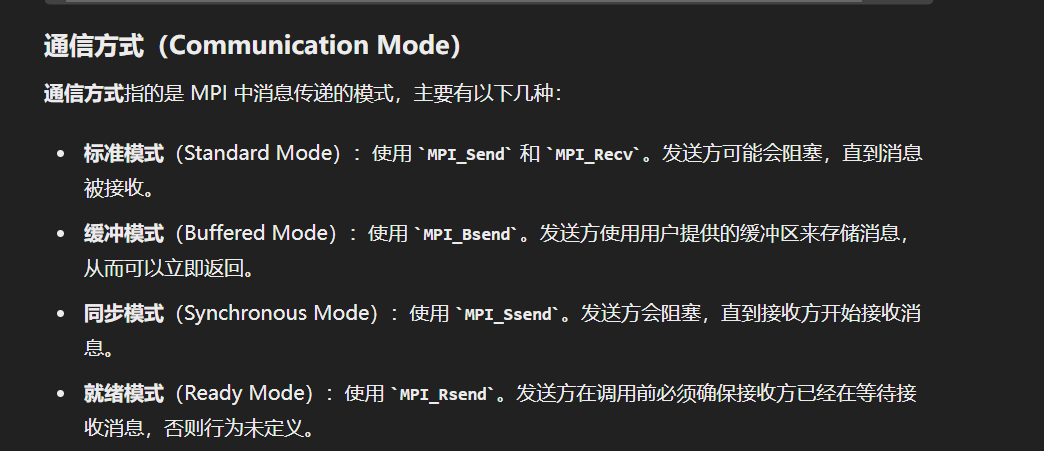
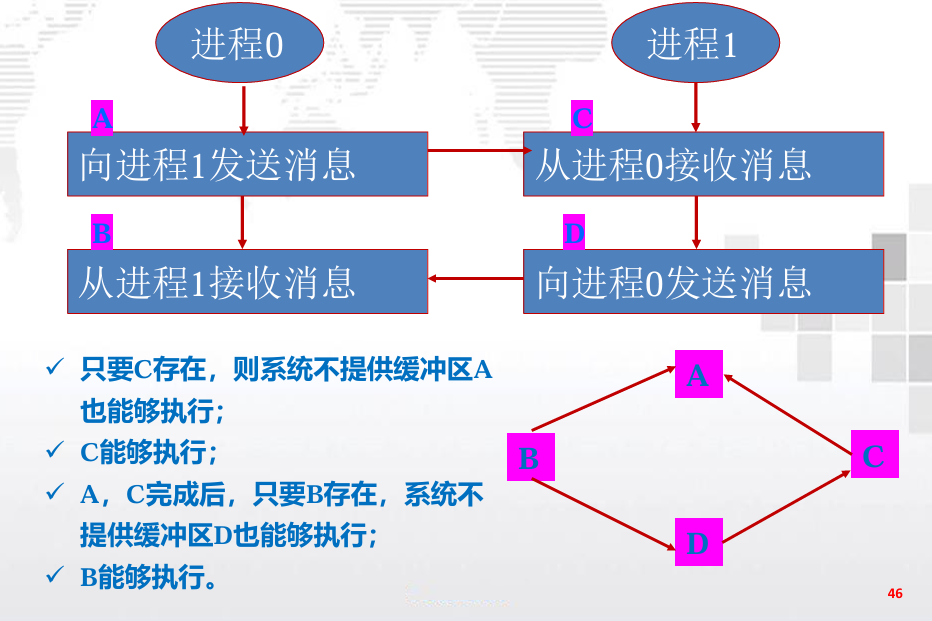
发送函数: 阻塞和缓冲
接收函数: 总是阻塞的
2.2. 基本概念
- 通信子
通信子是所有可以进行相互通信的进程的集合。
MPI_COMM_WORLD是MPI预定义的常量,是一个 包含所有用户启动进程的通信子。(MPI_Init)
一个进程可以属于多个通信子, 进程在不同通信子中的标识号可以不同
-
进程标识号(进程id):
-
- 进程在某个通信子中的标识号是唯一的;
- 一个进程可以属于不同的通信子,它在不同通信子 中的标识号不同;
- 进程号为从0开始的连续非负整数
- 通配符(Wildcard)
通配符允许消息传递操作中灵活地匹配消息源或标签。常用的通配符有:
- MPI_ANY_SOURCE:用于接收来自任意源进程的消息。
- MPI_ANY_TAG:用于接收具有任意标签的消息。
#include <stdio.h>
#include <stdlib.h>
#include <mpi.h>
double f(double x) {
return x * x; // 被积函数 x^2
}
double Trap(double local_a, double local_b, int local_n, double h) {
double integral = (f(local_a) + f(local_b)) / 2.0;
for (int i = 1; i <= local_n - 1; i++) {
double x = local_a + i * h;
integral += f(x);
}
integral *= h;
return integral;
}
int main(int argc, char* argv[]) {
int my_rank, comm_sz, n = 1024, local_n;
double a = -2.0, b = 2.0 h, local_a, local_b;
double local_int, total_int;
int source;
MPI_Init(NULL, NULL);
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
MPI_Comm_size(MPI_COMM_WORLD, &comm_sz);
h = (b - a) / n;
local_n = n / comm_sz;
local_a = a + my_rank * local_n * h;
local_b = local_a + local_n * h;
local_int = Trap(local_a, local_b, local_n, h);
if (my_rank != 0) {
MPI_Send(&local_integral, 1, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD);
} else {
total_integral = local_int;
for (int source = 1; source < comm_sz; source++) {
MPI_Recv(&local_integral, 1, MPI_DOUBLE, source, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
total_integral += local_integral;
}
printf("With n = %d trapezoids, integral from %f to %f = %f\n", n, a, b, total_integral);
}
MPI_Finalize();
return 0;
}
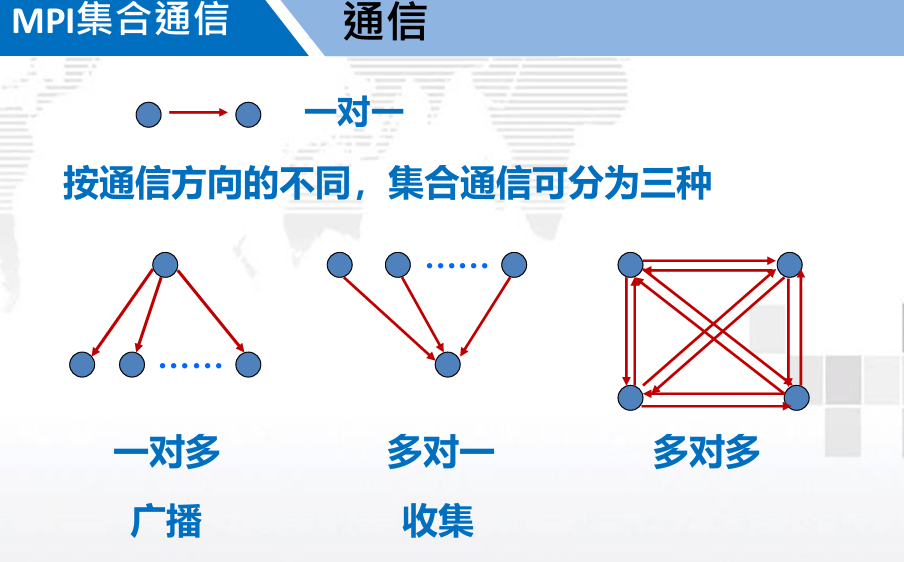
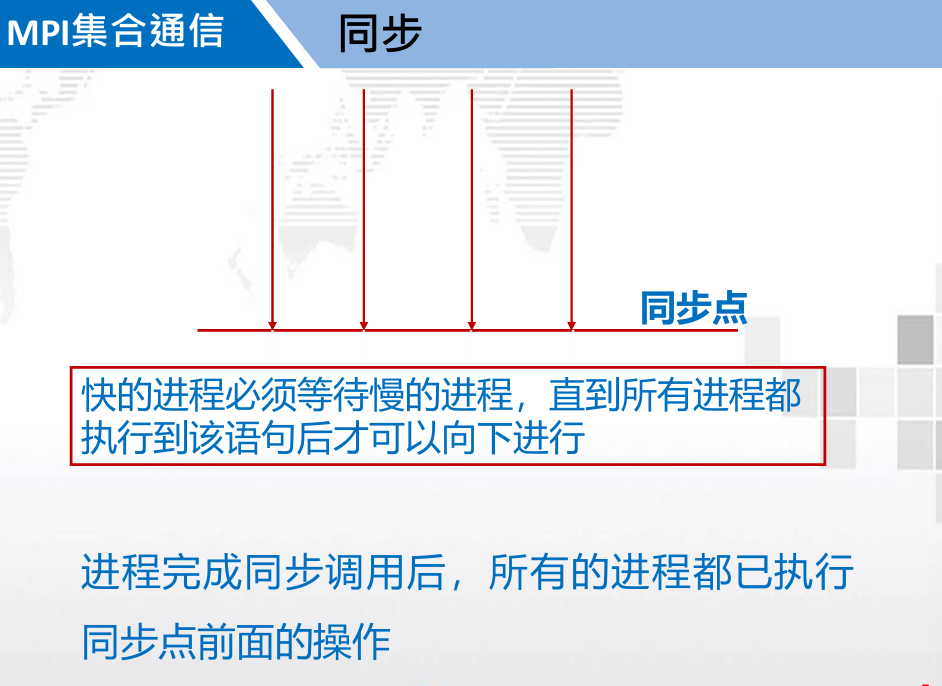
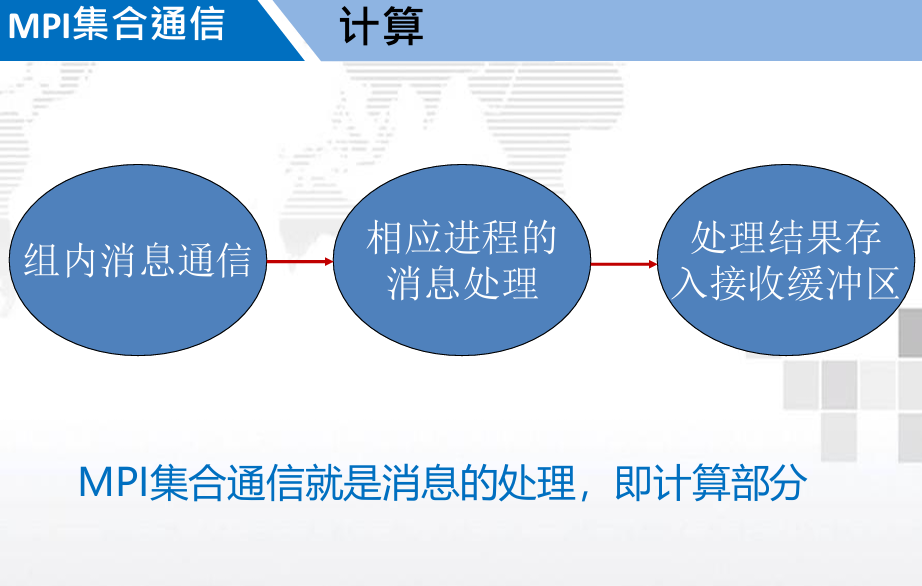
3. MPI 集合通信( Collective communication )
3.1. 概述
功能:
- 通信
- 同步
- 计算
3.2. 通信方式——广播规约
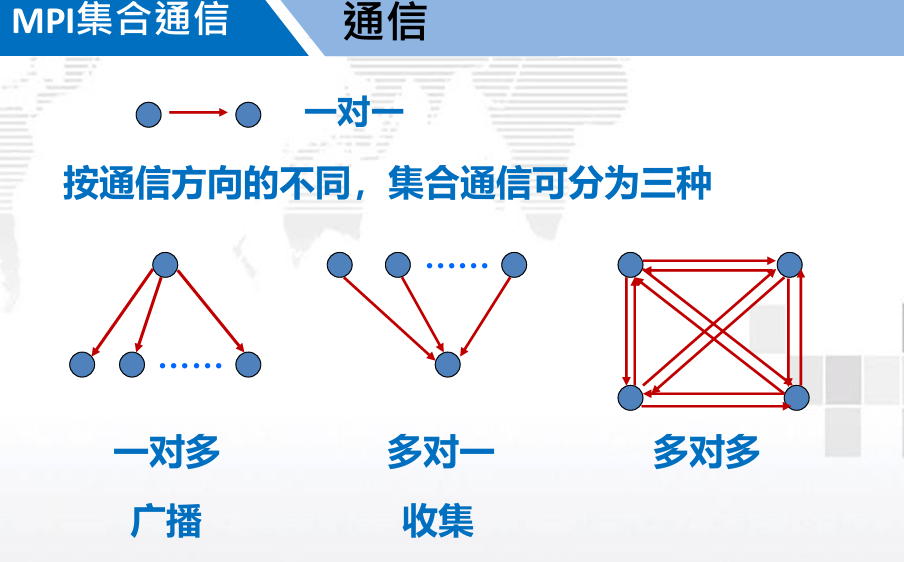
3.2.1. 广播
广播: 一个进程的数据被发送到通信子中的所有进程,即 广播 (一对多)
- 广播函数
MPI_Bcast(buffer,count,datatype,root,comm)
参数解释
- buffer(void *)
-
- 定义:指向要发送或接收数据的缓冲区的指针。
- 作用:在根进程中,这个缓冲区包含要广播的数据;在其他进程中,这个缓冲区用于存储接收到的数据。
- count(int)
-
- 定义:要发送或接收的数据项数目。
- 作用:指定数据缓冲区中的数据项数,即要广播的元素的数量。
- datatype(MPI_Datatype)
-
- 定义:数据类型。
- 作用:指定数据项的类型,如 MPI_INT(整数)、MPI_FLOAT(浮点数)等。
- root(int)
-
- 定义:广播数据的根进程的标识符(rank)。
- 作用:指定哪个进程的数据会被广播。进程的 rank 在通信子(comm)内唯一标识一个进程。
- comm(MPI_Comm)
-
- 定义:通信子。
- 作用:指定进程间通信的上下文,通常使用 MPI_COMM_WORLD 来表示所有进程。
int main(int argc, char* argv[]) {
int my_rank, comm_sz;
int data;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
MPI_Comm_size(MPI_COMM_WORLD, &comm_sz);
if (my_rank == 0) {
// Root process initializes the data
data = 42;
printf("Process %d broadcasting data: %d\n", my_rank, data);
} else {
// Other processes initialize data with a different value
data = -1;
}
// Broadcast the data from root process (rank 0) to all processes
MPI_Bcast(&data, 1, MPI_INT, 0, MPI_COMM_WORLD);
// All processes print the received data
printf("Process %d received data: %d\n", my_rank, data);
MPI_Finalize();
return 0;
}

3.2.2. 规约
规约: (多对一)
除完成消息传递功能之外,还能对所传递的数 据进行一定的操作或运算 在进行通信的同时完成一定的计算
- 规约函数
int MPI_Reduce(const void *sendbuf, void *recvbuf, int count, MPI_Datatype datatype, MPI_Op op, int root, MPI_Comm comm);
参数解释
- sendbuf(const void *)
-
- 定义:发送缓冲区的指针,指向包含要参与归约操作的数据的缓冲区。
- 作用:每个进程的数据会从这个缓冲区中取出。
- recvbuf(void *)
-
- 定义:接收缓冲区的指针,指向存储归约结果的缓冲区。
- 作用:在根进程中,存储归约操作的结果;在非根进程中,该参数可以是 NULL(因为它们不会接收结果)。
- count(int)
-
- 定义:每个进程参与归约操作的数据项数目。
- 作用:指定每个进程参与归约操作的数据元素的数量。
- datatype(MPI_Datatype)
-
- 定义:数据类型。
- 作用:指定数据项的类型,如 MPI_INT、MPI_FLOAT 等。
- op(MPI_Op)
-
- 定义:归约操作。
- 作用:指定归约操作的类型,如 MPI_SUM(求和)、MPI_PROD(乘积)、MPI_MAX(最大值)等。
- root(int)
-
- 定义:根进程的标识符(rank)。
- 作用:指定哪个进程将接收归约结果。
- comm(MPI_Comm)
-
- 定义:通信子。
- 作用:指定进程间通信的上下文,通常使用 MPI_COMM_WORLD。
int main(int argc, char* argv[]) {
int my_rank, comm_sz;
int local_data;
int global_sum;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
MPI_Comm_size(MPI_COMM_WORLD, &comm_sz);
// 每个进程的数据
local_data = my_rank + 1;
// 进行归约操作,求和
MPI_Reduce(&local_data, &global_sum, 1, MPI_INT, MPI_SUM, 0, MPI_COMM_WORLD);
// 只有根进程(rank 0)输出结果
if (my_rank == 0) {
printf("The sum of all ranks is %d\n", global_sum);
}
MPI_Finalize();
return 0;
}

#include <stdio.h>
#include <stdlib.h>
#include <mpi.h>
double f(double x) {
return x * x; // 被积函数 x^2
}
double Trap(double local_a, double local_b, int local_n, double h) {
double integral = (f(local_a) + f(local_b)) / 2.0;
for (int i = 1; i <= local_n - 1; i++) {
double x = local_a + i * h;
integral += f(x);
}
integral *= h;
return integral;
}
int main(int argc, char* argv[]) {
int my_rank, comm_sz, n, local_n;
double a, b, h, local_a, local_b;
double local_int, total_int;
int source;
MPI_Init(NULL, NULL);
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
MPI_Comm_size(MPI_COMM_WORLD, &comm_sz);
if (my_rank == 0) {
n = 1000;
a = -2.0;
b = 2.0;
}
MPI_Bcast(&a, 1, MPI_DOUBLE, 0, MPI_COMM_WORLD);
MPI_Bcast(&b, 1, MPI_DOUBLE, 0, MPI_COMM_WORLD);
MPI_Bcast(&n, 1, MPI_INT, 0, MPI_COMM_WORLD);
h = (b - a) / n;
local_n = n / comm_sz;
local_a = a + my_rank * local_n * h;
local_b = local_a + local_n * h;
local_int = Trap(local_a, local_b, local_n, h);
MPI_Reduce(&local_int, &total_int, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD);
if (my_rank == 0) {
printf("With n = %d trapezoids, integral from %f to %f = %f\n", n, a, b, total_int);
}
MPI_Finalize();
return 0;
}
3.2.3. 集合通信与点对点通信的区别
-
所有的进程都必须调用相同的集合通信函数
-
每个进程传送给MPI的集合通信函数的参数必须相容
-
参数recvbuf只用在dest_process上
-
MPI_Reduce(sendbuf, recvbuf, count, datatype, op, dest_process,comm)
-
所有进程仍需要传递一个与recvbuf相对应的实际 参数,即使它的值是NULL
-
点对点通信通过标签和通信子匹配,集合通信通 过通信子和调用顺序匹配

Time 1:
b = a + c + c = 1 + 4 + 6 = 11
Time 2:
d = 2 + 3 + 5 = 10
3.2.4. 规约—广播(N—N)
- 区别:与MPI_Reduce相比,缺少dest_process这 个参数,因为所有进程都能得到结果。
- 通信子内所有进程都作为目标进程执行一次规约 操作,操作完毕后所有进程接收缓冲区的数据均相 同。这个操作等价于首先进行一次MPI_Reduce,然 后再执行一次MPI_Bcast
#include <stdio.h>
#include <mpi.h>
int main(int argc, char* argv[]) {
MPI_Init(&argc, &argv);
int my_rank, comm_sz;
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
MPI_Comm_size(MPI_COMM_WORLD, &comm_sz);
int local_value = my_rank + 1; // 每个进程的局部值
int total_sum = 0;
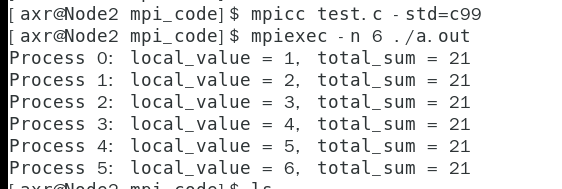
MPI_Allreduce(&local_value, &total_sum, 1, MPI_INT, MPI_SUM, MPI_COMM_WORLD);
printf("Process %d: local_value = %d, total_sum = %d\n", my_rank, local_value, total_sum);
MPI_Finalize();
return 0;
}
3.3. 通信方式——散射聚集
3.3.1. 散射
散射: 一对多
MPI_Scatter可以使0号进程读取整个向量,但是 只将分量发送给需要分量的其他进程
- 函数
MPI_Scatter(sendbuf,sendcount,sendtype,recvbuf,recvcount,recvty pe,src_proc,comm)
参数解释
- sendbuf: 指向发送缓冲区的指针。在根进程上,这是要分发的数据的起始地址。非根进程可以传递 NULL。
- sendcount: 每个进程要接收的数据项数量。发送的数据总量应为 sendcount * comm_sz,其中 comm_sz 是进程总数。
- sendtype: 发送数据项的类型,例如 MPI_INT。
- recvbuf: 指向接收缓冲区的指针。每个进程从 sendbuf 中接收的数据将存储在这里。
- recvcount: 每个进程接收的数据项数量。通常与 sendcount 相同。
- recvtype: 接收数据项的类型,例如 MPI_INT。
- root: 源进程的标识符(rank),即发送数据的进程。通常是 0。
- comm: 通信子,通常是 MPI_COMM_WORLD,表示所有进程都在这个通信子内。
int main(int argc, char* argv[]) {
int comm_sz; // 进程总数
int my_rank; // 当前进程的 rank
int *sendbuf = NULL;
int recvbuf;
int sendcount = 1;
int recvcount = 1;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
MPI_Comm_size(MPI_COMM_WORLD, &comm_sz);
// 根进程初始化发送缓冲区
if (my_rank == 0) {
sendbuf = (int *)malloc(comm_sz * sizeof(int));
for (int i = 0; i < comm_sz; i++) {
sendbuf[i] = i + 1; // 或者任意其他初始化方式
}
}
// 分发数据,每个进程接收一个整数
MPI_Scatter(sendbuf, sendcount, MPI_INT, &recvbuf, recvcount, MPI_INT, 0, MPI_COMM_WORLD);
// 打印接收到的数据
printf("Process %d received data %d\n", my_rank, recvbuf);
// 根进程释放发送缓冲区
if (my_rank == 0) {
free(sendbuf);
}
MPI_Finalize();
return 0;
}
Process 0 received data 1
Process 1 received data 2
Process 2 received data 3
Process 3 received data 4
3.3.2. 聚集
多对一
int MPI_Gather(const void *sendbuf, int sendcount, MPI_Datatype sendtype,
void *recvbuf, int recvcount, MPI_Datatype recvtype,
int root, MPI_Comm comm);
- sendbuf: 指向发送缓冲区的指针。每个进程要发送的数据的起始地址。
- sendcount: 每个进程发送的数据项数量。
- sendtype: 发送数据项的类型,例如 MPI_INT。
- recvbuf: 指向接收缓冲区的指针。只有根进程使用,其他进程传递 NULL。根进程接收到的数据将存储在这里。
- recvcount: 每个进程发送的数据项数量。注意:recvcount 通常等于 sendcount。
- recvtype: 接收数据项的类型,例如 MPI_INT。
- root: 目标进程的标识符(rank),即接收数据的进程。通常是 0。
- comm: 通信子,通常是 MPI_COMM_WORLD,表示所有进程都在这个通信子内。
int main(int argc, char* argv[]) {
int comm_sz; // 进程总数
int my_rank; // 当前进程的 rank
int sendbuf; // 每个进程要发送的数据
int *recvbuf = NULL;
int sendcount = 1;
int recvcount = 1;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
MPI_Comm_size(MPI_COMM_WORLD, &comm_sz);
// 每个进程初始化发送缓冲区
sendbuf = my_rank + 1;
// 根进程分配接收缓冲区
if (my_rank == 0) {
recvbuf = (int *)malloc(comm_sz * sizeof(int));
}
// 收集数据
MPI_Gather(&sendbuf, sendcount, MPI_INT, recvbuf, recvcount, MPI_INT, 0, MPI_COMM_WORLD);
// 根进程打印接收到的数据
if (my_rank == 0) {
printf("Root process received data:\n");
for (int i = 0; i < comm_sz; i++) {
printf("%d ", recvbuf[i]);
}
printf("\n");
free(recvbuf);
}
MPI_Finalize();
return 0;
}

4. 性能评估
4.1. 计时功能
double MPI_Wtime(void);
MPI_Wtime 返回一个双精度浮点数,表示自某个时间点(通常是程序开始执行时)到当前时间的秒数。
int main(int argc, char* argv[]) {
MPI_Init(&argc, &argv);
double start_time, end_time;
// 获取开始时间
start_time = MPI_Wtime();
// 模拟一些工作,假设用 sleep(2) 代表需要测量的代码段
// 在实际代码中应使用需要测量的代码段
sleep(2);
// 获取结束时间
end_time = MPI_Wtime();
// 计算并打印执行时间
printf("Execution time: %f seconds\n", end_time - start_time);
MPI_Finalize();
return 0;
}
MPI_Wtick
MPI_Wtick 返回一个双精度浮点数,表示计时器的分辨率(以秒为单位)。

4.2. 安全通信

第四章 Pthreads
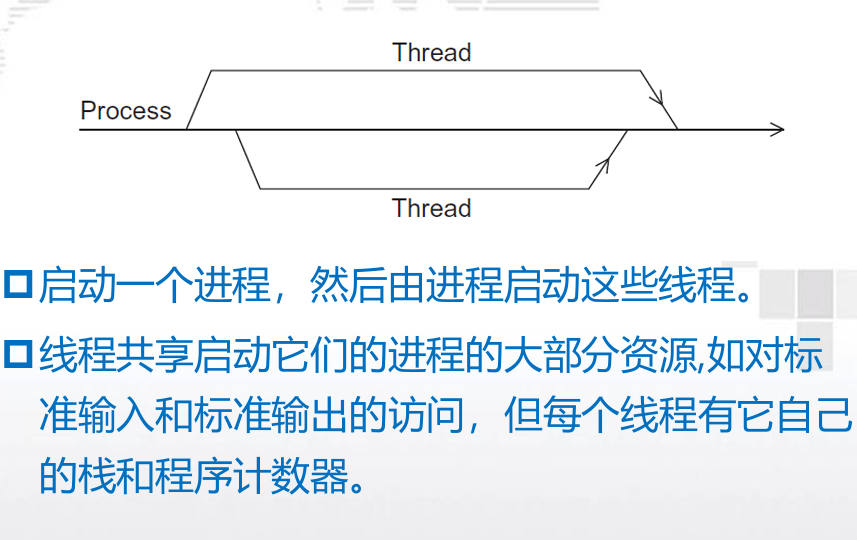
1. 进程、线程
- 进程、线程

2. Pthreads( 共享内存编程模型 )
POSIX线程库也称为Pthreads线程库,它定义了一套多线程编程的应用程序编程接口 。
2.1. 编译
gcc−g −Wall −o pth_hellopth_hello.c−lpthread
参数解释
- gcc:
-
- GNU Compiler Collection,指的是使用 GCC 编译器来编译代码。
- -g:
-
- 生成包含调试信息的目标文件。这些调试信息可以用来使用调试器(如 gdb)调试程序。这对于开发和调试程序非常有用。
- -Wall:
-
- 启用所有常见的编译器警告。这有助于捕捉代码中的潜在问题和错误,使代码更加健壮和可靠。
- -o pth_hello:
-
- 指定输出文件的名称为 pth_hello。编译器会将生成的可执行文件命名为 pth_hello,而不是默认的 a.out。
- pth_hello.c:
-
- 输入的源代码文件,包含程序的实际实现。在这个例子中,文件名是 pth_hello.c。
- -lpthread:
-
- 链接 pthread 库。-l 选项告诉编译器链接指定的库,pthread 是 POSIX 线程库,提供了线程创建和管理的 API。

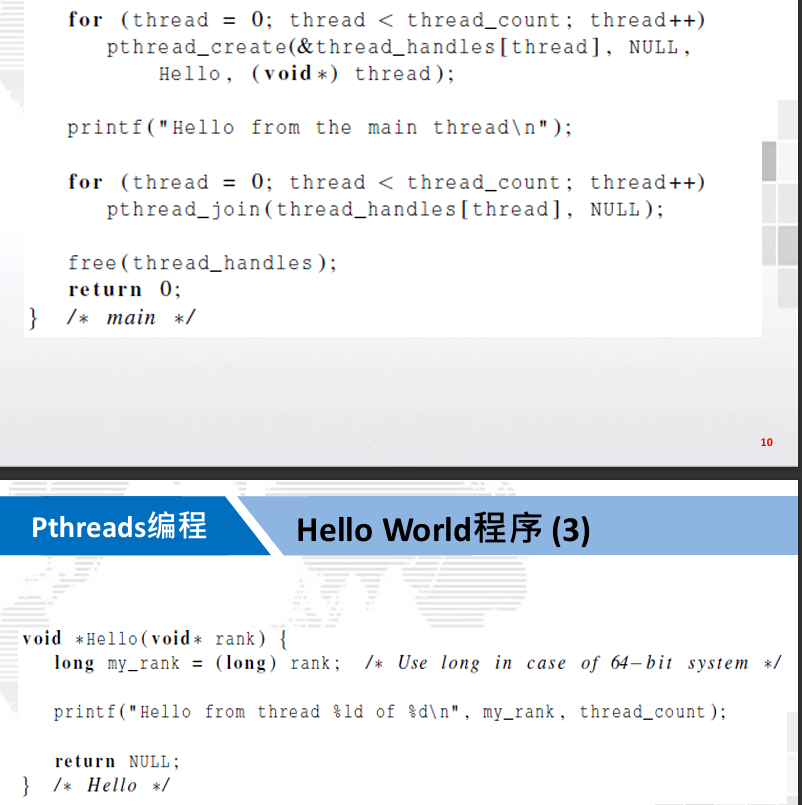

第五章 - 用OpenMP进行共享内存编程
1. OpenMP简介
OpenMP是一个针对共享内存编程的API。

2. 编译指导语句
2.1. 并行执行模式:
"Fork/Join”方式:
- Fork(分叉):
- 在程序执行过程中,主线程创建多个子线程,这些子线程可以并行地执行不同的任务。
- 每个子线程负责一个子任务,所有子任务可以同时运行。
- Join(汇合):
- 子线程完成各自的任务后,汇合到主线程。
- 主线程等待所有子线程完成,收集它们的结果,然后继续执行后续的任务。
#include <stdio.h>
#include <omp.h>
int main() {
int nthreads;
// Fork: 主线程创建多个子线程
#pragma omp parallel
{
int tid = omp_get_thread_num(); // 获取线程编号
nthreads = omp_get_num_threads(); // 获取总线程数
printf("Hello from thread %d of %d\n", tid, nthreads);
}
// Join: 所有子线程完成并行区域,汇合到主线程
printf("All threads have finished.\n");
return 0;
}
2.2. 程序编写
- OpenMP是“基于指令”的共享内存API。
- OpenMP的头文件为
omp.h omp.h是由一组函数和宏库组成
2.2.1. 预处理指令
-
预处理指令是在C和C++中用来允许不是基本C 语言规范部分的行为;eg:特殊的预处理器指令 pragma。
-
不支持pragma的编译器会忽略pragma指令提示 的那些语句.
-
- 如果有一个pragma在一行中放不下,那么新行需要被转 义—— ‘’
- OpenMP中,预处理器指令以#pragmaomp开头
2.2.2. OpenMP编译指导语句格式
- OpenMP编译指导语句由 directive (指令)和 clause list (子句列表)组成。
- 在C/C++中,OpenMP编译指导语句的使用格式为:
#pragmaompparallel[clause…]new-line Structured-block

#include <stdio.h>
#include <stdlib.h>
#include <omp.h>
int main(int argc, char *argv[]) {
int i;
int thread_count = strtol(argv[1], NULL, 10);
#pragma omp parallel for num_threads(thread_count)
for (i = 0; i < 10; i++) {
printf("i = %d\n", i);
}
printf("Finished.\n");
return 0;
}
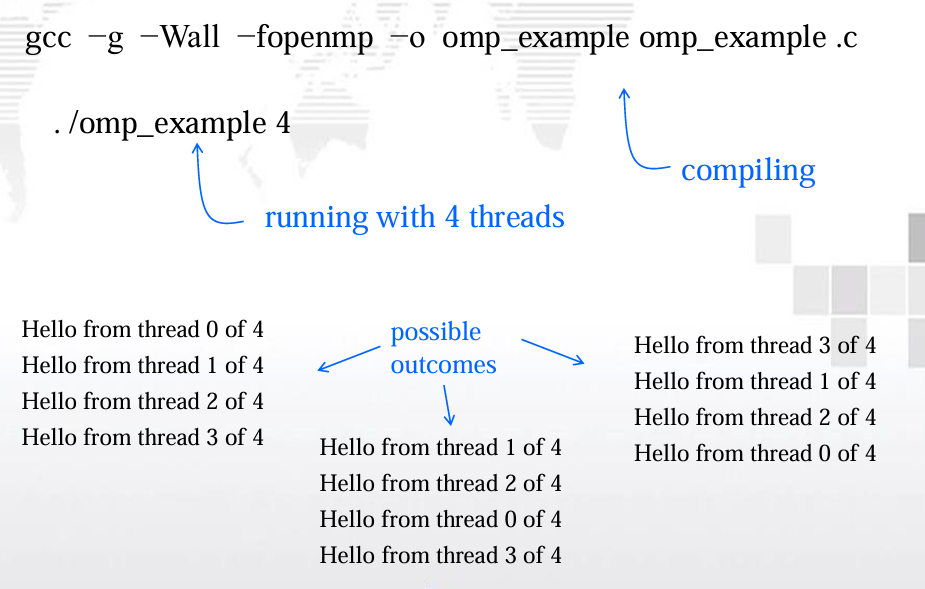
2.2.3. 编译运行
gcc -g -Wall -fopenmp -o omp_example omp_example.c
-fopenmp:
- 启用 OpenMP 支持。
# 分配四个 threads
./omp_example 4
2.2.4. helloworld 程序
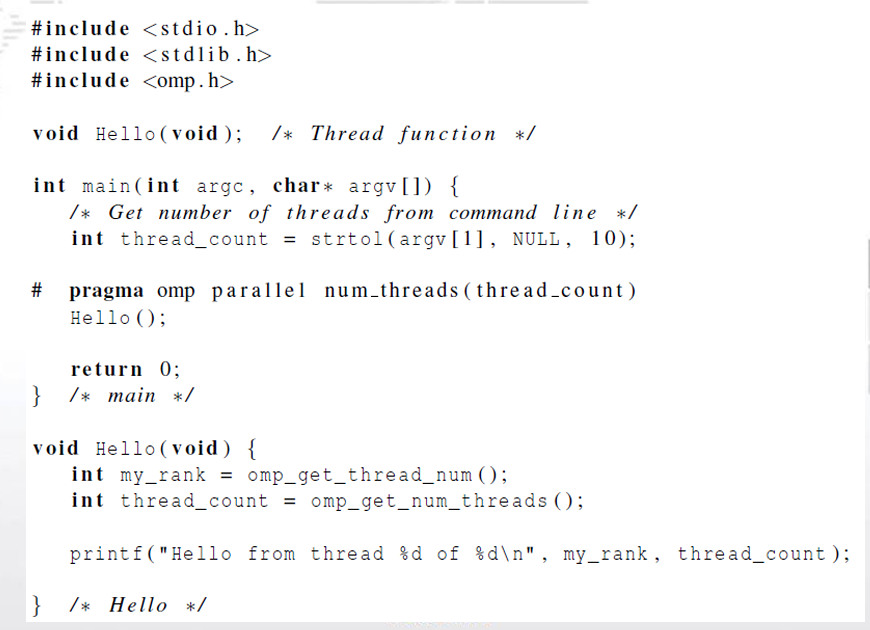

- OpenMP 指令
#pragma omp parallel
- 最基本的并行指令
- parallel指令是用来表示之后的结构化代码块应该被多个线程并行执行。
- 结构化代码块是一条C语言语句或者只有一个入口和出口的一组复合C语句
- OpenMP 子句
# pragma omp parallel num_threads(thread_count)
- 修改指令的文本
- num_threads子句加在parallel指令之后
- 用来指定执行之后的代码块的线程数目.
- OpenMP 线程

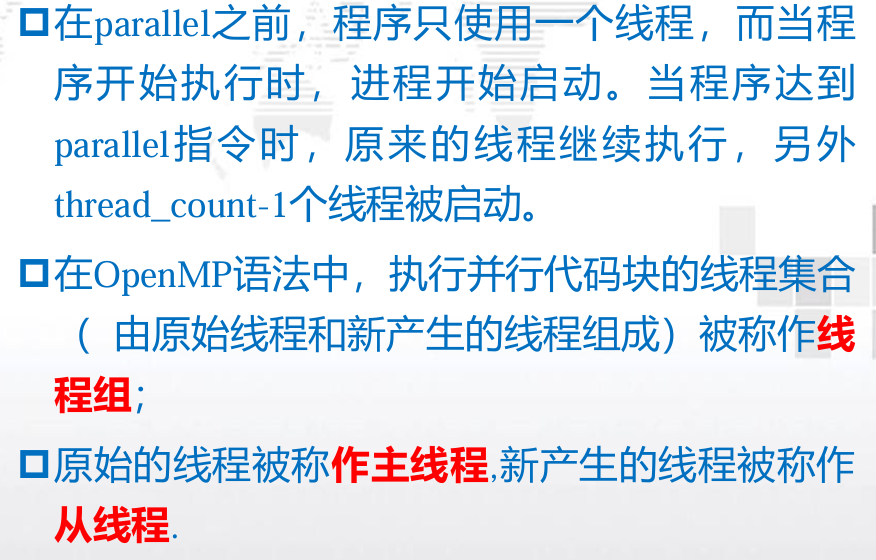

- OpenMP函数
int omp_get_thread_num(void);
- 获得每个线程的编号(0-thread_count-1)
int omp_get_num_threads(void)
- 获得线程组中的线程数
注意因为标准输出被所有线程共享,所以每个 线程都能够执行printf语句,打印它的线程编号 和线程数。由于对标准输出的访问没有调度, 因此线程打印它们结果的实际顺序不确定
2.3. OpenMP 编程
2.3.1. critical指令
引起竞争的代码,称为临界区
竞争:多个线程试图访问并更新一个共享资源
因此需要一些机制来确保一次只有一个线程执行 临界区,这种操作,我们称为互斥。
- critical指令用在一段代码临界区之前,临界区在 同一时间内只能有一个线程执行它,其他线程要 执行临界区则需要排队来执行它。
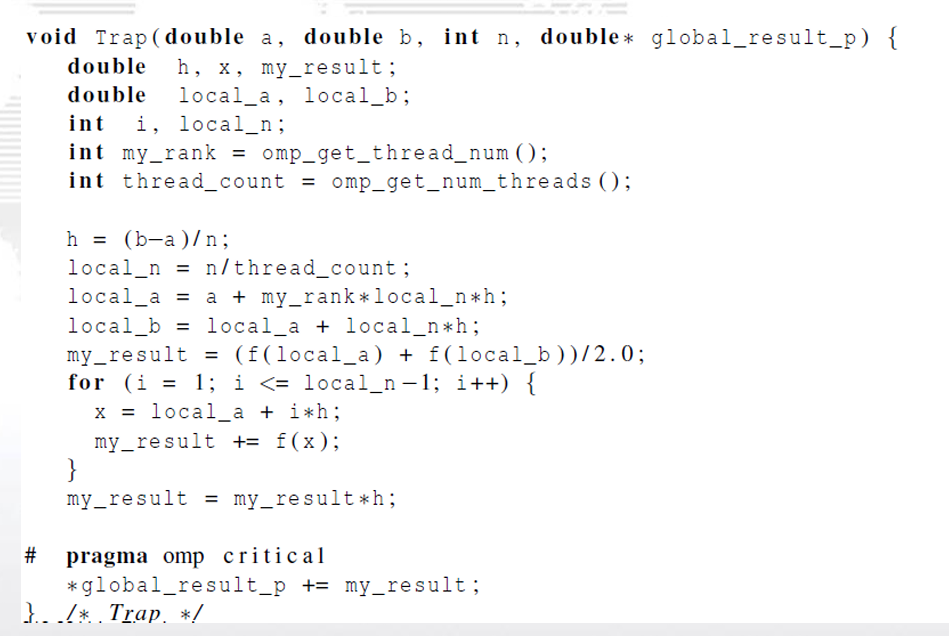
2.3.2. 变量作用域

2.3.3. 规约子句 reduction

注意:每个线程的私有拷贝值global_result初始化为0。
2.3.4. parallel for
for指令是用来将一个for循环分配到多个线程中执行。
for指令的使用方式:
- 单独用在parallel语句的并行块中;
- 与parallel指令合起来形成parallel for指令

parallel for指令





第二章 - 并行硬件和并行软件
1. 基本概念
1.1. 冯诺依曼结构
- 中央处理器(CPU)
- 控制单元-负责决定应该执行程序中的哪些指 令。(the boss)
- 算术逻辑单元(ALU) -负责执行指令。 (the worker )
- 关键术语
- CPU中的数据和程序执行时的状态信息存储在特殊的快速存储介质中,这种介质就是寄存器。
- 程序计数器:用来存放下一条指令的地址(控制单元的一 个特殊的寄存器).
- 总线:包括一组并行的线以及控制这些线的硬件。它是 CPU和主存之间的互连结构,能够进行传输指令和数据。
- 主存
- 主存中有许多区域,每个区域都可以存储指令和数据。
- 每个区域都有一个地址,可以通过这个地址来访问相应的区域及区域中存储的数据和指令。
- 冯诺依曼瓶颈
- 主存和CPU之间的分离称为冯诺依曼瓶颈。
- 互连结构限定了指令和数据访问的速率。
1.2. 缓存
-
冯诺依曼模型的改进
-
- 不再将所有的数据和指令存储在主存中,可以将部分数据块或者代码块存储在一个靠近CPU寄存器的特殊存储器里。
-
高速缓冲存储器简称缓存
-
- 访问它的时间比访问其它存储区域时间短。
- 相比于主存,CPU能更快速地访问的存储区域。(一般与CPU位于同一块芯片 )
1.3. 进程
正在运行的程序的实例
2. 并行硬件
2.1. Flynn经典分类
从处理器的角度进行分类:按照处理器能够同时管理的指令流数目和数据流数目来对系统分类。
2.1.1. 单指令单数据流(SISD)
是一个串行的计算机系统
-
单指令:在一个时钟周期内只有一个指令流被CPU进行处理。
-
单数据:在一个时钟周期内只有一个数据流作为输入而使用。
-
Example:
-
- ✓冯诺依曼系统
- ✓单核处理器
2.1.2. 单指令多数据流(SIMD)
是并行系统。
-
单指令:在一个时钟周期内,所有的处理器单元执行相同的指令
-
多数据流:每个处理器单元能够作用在不同的数据单元上。
-
SIMD系统通过对多个数据执行相同的指令从而实现在多个数据流上的操作
-
通过在处理器之间划分数据实现并行性(数据并行)
-
如果没有足够多的ALU分配给各个数据项应该怎么办?
划分工作,并进行迭代循环处理。
-
缺陷
-
- 在经典的SIMD设计中,ALU必须同步操作.
- 所有的ALU需要执行相同的指令或处于空闲状态.
- SIMD适合处理大型数据并行问题,但是在处理其它类型或更复杂问题上并不适合,性能较差
-
Example
-
- 向量处理器
- 图形处理单元(Graphics processing unit, GPU)
2.1.3. 多指令单数据流(MISD)
- 多指令:每个处理单元通过单独的指令流独立地对数据进行操作.
- 单数据流:单个数据流被输入多个处理单元
2.1.4. 多指令多数据流(MIMD)
- 多指令:每个处理器可能执行不同的指令流
- 多数据:每个处理器可能使用不同的数据流
- 支持多个指令流同时运行在多个数据流上
- 通常由完全独立的处理单元或核心组成,每个处理单元都有自己的控制单元和ALU.
- Example:大多数现代计算机,如多核CPU
2.2. 内存结构分类
- 共享内存计算机体系结构
- 分布式内存计算机体系结构
2.2.1. 共享内存系统
-
一组自治的处理器通过互连网络与内存系统连接.
-
各个核可以共享访问计算机的内存系统,每个处理器能够访问每个内存区域.
-
可以通过检测和更新内存系统来协调各个核,处理器通过访问共享的数据结构来隐式的通信
-
- 大多数共享内存系统使用一个多核处理器或者多个多核处理器
- 在一块芯片上 有多个CPU或者核
- 一致内存访问(UMA):互连网络将所有的处理器直接连到主存。
每个核访问内存任意位置的时间相等 。如:对称多处理器(SMP)
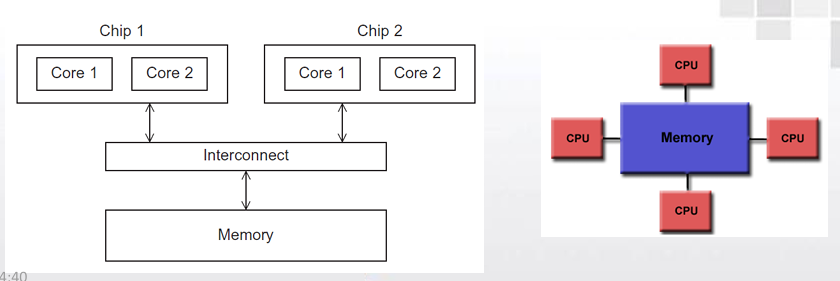
- 非一致内存访问(NUMA):将每个处理器直接连到单独的一 块内存上,然后通过处理器中内置的特殊硬件使得各个处理器可以访问内存中的其它块。
- 通常是通过物理连接两个或多个SMP来实现的
- 一个SMP可以直接访问另一个SMP的内存
- 访问核直接连接到的内存位置比必须通过另一个芯片 进行访问的内存位置更快。
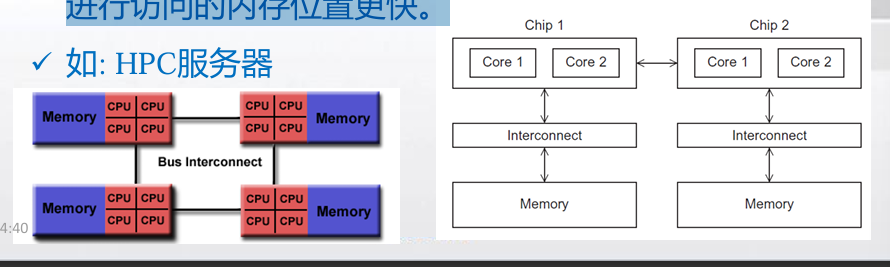
- UMA与NUMA系统的特点:
- 一致内存访问(UMA)系统容易编程。
- 非一致内存访问(NUMA)系统拥有更大容量的内存
2.2.2. 分布式内存系统
- 每个核都有自己独立的私有的内存.
- 核之间的通信需要通过网络发送消息,进行显式的通信.
- 将多台计算机连接起来形成一个计算平台,而没有共享内存
网络提供一种基础架构,使地理上分布的计算机大型 网络转换成一个分布式内存系统。

2.3. 互连网络
两类: ✓共享内存互连 ✓分布式内存互连
3. 并行软件
-
共享内存程序:
-
- 启动单个进程和派生线程.
- 线程执行任务.
-
分布式内存程序:
-
- 启动多个进程.
- 进程执行任务
➢分布式内存编程模型(MPI、MapReduce)
➢共享内存编程模型(Pthreads、OpenMP)
➢异构系统的编程模型(CUDA、OpenCL)


第三章 - MPI
1. MPI简介
MPI(Message-Passing Interface)
分布式内存编程模型
- 编译: mpicc-g -Wall -o mpi_hello mpi_hello.c
- mpicc : 调用MPI编译器,将源代码编译成可执行文件。
- -g: 生成调试信息
- -Wall : 开启所有警告信息选项
- -o mpi_hello : 指定编译生成的可执行文件的名称
- mpi_hello.c : 源代码文件名。
- 执行: mpiexec -n 1 ./mpi_hello
- -n 1:指定运行的进程数,这里设置为1。
- ./mpi_hello:要运行的可执行文件路径和名称。
2. MPI点对点通信
2.1. 基本函数
-
MPI_Init(&argc, &argv);:初始化MPI环境,使得MPI库可以被使用。每个进程都需要调用一次 MPI_Init。
-
MPI_Finalize();:结束MPI环境,每个进程都需要调用一次 MPI_Finalize,表示MPI程序的结束。
-
MPI_Comm_size(MPI_COMM_WORLD, &comm_sz);:获取默认通信子 MPI_COMM_WORLD 中的总进程数,并将其存储在 comm_sz 变量中。例如,如果启动了4个进程,那么 comm_sz 的值就是4。
-
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);:获取当前进程在 MPI_COMM_WORLD 中的排名,并将其存储在 my_rank 变量中。每个进程都有一个唯一的 my_rank,在 0 到 comm_sz - 1 之间。
-
MPI_Send(buf,count,datatype,dest,tag,comm) -
- MPI_Send(greeting, strlen(greeting) + 1, MPI_CHAR, 0, 0, MPI_COMM_WORLD);:
- 定义:使用MPI_Send函数发送消息。
- 参数解释:
-
-
- greeting:要发送的消息数据。
- strlen(greeting) + 1:消息的长度,加1是为了包括字符串的终止符\0。
- MPI_CHAR:消息的数据类型,这里是字符数组。
- 0:消息接收者的排名,即将消息发送到排名为0的进程。
- 0:消息的标签(tag),可以用来区分不同类型的消息。
- MPI_COMM_WORLD:通信子,表示所有MPI进程的默认通信子。
-
-
- 作用:将格式化后的问候消息发送到排名为0的进程。
-
MPI_Recv(buf,count,datatype,source,tag,comm,status) -
- MPI_Recv(greeting, MAX_STRING, MPI_CHAR, q, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
-
-
- buf:greeting 是接收缓冲区,用于存储接收到的字符串。
- count:MAX_STRING 指定接收缓冲区的最大大小(100)。
- datatype:MPI_CHAR 指定接收的数据类型为字符。
- source:q 表示消息的发送者,q 从 1 到 comm_sz-1(非零进程)。
- tag:0 指定接收的消息标签。
- comm:MPI_COMM_WORLD 表示所有进程的默认通信子。
- status:MPI_STATUS_IGNORE 忽略接收消息的状态信息。
-
发送函数: 阻塞和缓冲
接收函数: 总是阻塞的
2.2. 基本概念
- 通信子
通信子是所有可以进行相互通信的进程的集合。
MPI_COMM_WORLD是MPI预定义的常量,是一个 包含所有用户启动进程的通信子。(MPI_Init)
一个进程可以属于多个通信子, 进程在不同通信子中的标识号可以不同
-
进程标识号(进程id):
-
- 进程在某个通信子中的标识号是唯一的;
- 一个进程可以属于不同的通信子,它在不同通信子 中的标识号不同;
- 进程号为从0开始的连续非负整数
- 通配符(Wildcard)
通配符允许消息传递操作中灵活地匹配消息源或标签。常用的通配符有:
- MPI_ANY_SOURCE:用于接收来自任意源进程的消息。
- MPI_ANY_TAG:用于接收具有任意标签的消息。
#include <stdio.h>
#include <stdlib.h>
#include <mpi.h>
double f(double x) {
return x * x; // 被积函数 x^2
}
double Trap(double local_a, double local_b, int local_n, double h) {
double integral = (f(local_a) + f(local_b)) / 2.0;
for (int i = 1; i <= local_n - 1; i++) {
double x = local_a + i * h;
integral += f(x);
}
integral *= h;
return integral;
}
int main(int argc, char* argv[]) {
int my_rank, comm_sz, n = 1024, local_n;
double a = -2.0, b = 2.0 h, local_a, local_b;
double local_int, total_int;
int source;
MPI_Init(NULL, NULL);
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
MPI_Comm_size(MPI_COMM_WORLD, &comm_sz);
h = (b - a) / n;
local_n = n / comm_sz;
local_a = a + my_rank * local_n * h;
local_b = local_a + local_n * h;
local_int = Trap(local_a, local_b, local_n, h);
if (my_rank != 0) {
MPI_Send(&local_integral, 1, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD);
} else {
total_integral = local_int;
for (int source = 1; source < comm_sz; source++) {
MPI_Recv(&local_integral, 1, MPI_DOUBLE, source, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
total_integral += local_integral;
}
printf("With n = %d trapezoids, integral from %f to %f = %f\n", n, a, b, total_integral);
}
MPI_Finalize();
return 0;
}
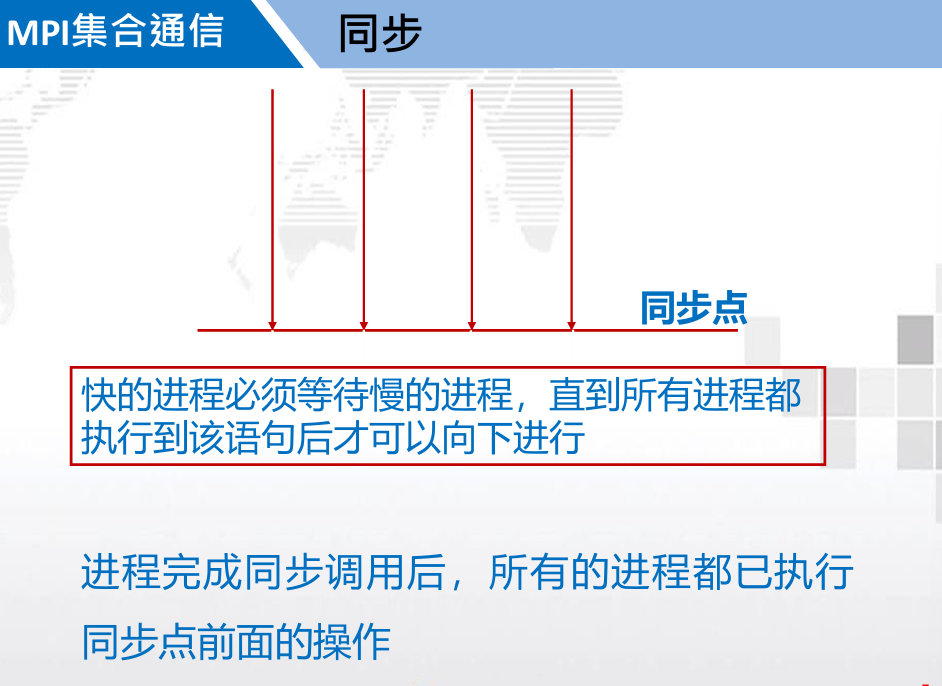
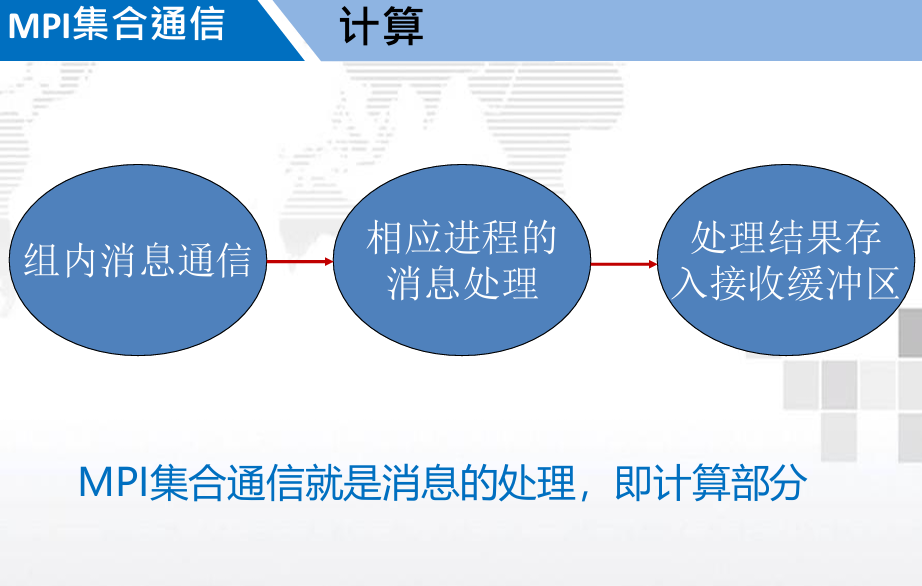
3. MPI 集合通信( Collective communication )
3.1. 概述
功能:
- 通信
- 同步
- 计算
3.2. 通信方式——广播规约
3.2.1. 广播
广播: 一个进程的数据被发送到通信子中的所有进程,即 广播 (一对多)
- 广播函数
MPI_Bcast(buffer,count,datatype,root,comm)
参数解释
- buffer(void *)
-
- 定义:指向要发送或接收数据的缓冲区的指针。
- 作用:在根进程中,这个缓冲区包含要广播的数据;在其他进程中,这个缓冲区用于存储接收到的数据。
- count(int)
-
- 定义:要发送或接收的数据项数目。
- 作用:指定数据缓冲区中的数据项数,即要广播的元素的数量。
- datatype(MPI_Datatype)
-
- 定义:数据类型。
- 作用:指定数据项的类型,如 MPI_INT(整数)、MPI_FLOAT(浮点数)等。
- root(int)
-
- 定义:广播数据的根进程的标识符(rank)。
- 作用:指定哪个进程的数据会被广播。进程的 rank 在通信子(comm)内唯一标识一个进程。
- comm(MPI_Comm)
-
- 定义:通信子。
- 作用:指定进程间通信的上下文,通常使用 MPI_COMM_WORLD 来表示所有进程。
int main(int argc, char* argv[]) {
int my_rank, comm_sz;
int data;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
MPI_Comm_size(MPI_COMM_WORLD, &comm_sz);
if (my_rank == 0) {
// Root process initializes the data
data = 42;
printf("Process %d broadcasting data: %d\n", my_rank, data);
} else {
// Other processes initialize data with a different value
data = -1;
}
// Broadcast the data from root process (rank 0) to all processes
MPI_Bcast(&data, 1, MPI_INT, 0, MPI_COMM_WORLD);
// All processes print the received data
printf("Process %d received data: %d\n", my_rank, data);
MPI_Finalize();
return 0;
}

3.2.2. 规约
规约: (多对一)
除完成消息传递功能之外,还能对所传递的数 据进行一定的操作或运算 在进行通信的同时完成一定的计算
- 规约函数
int MPI_Reduce(const void *sendbuf, void *recvbuf, int count, MPI_Datatype datatype, MPI_Op op, int root, MPI_Comm comm);
参数解释
- sendbuf(const void *)
-
- 定义:发送缓冲区的指针,指向包含要参与归约操作的数据的缓冲区。
- 作用:每个进程的数据会从这个缓冲区中取出。
- recvbuf(void *)
-
- 定义:接收缓冲区的指针,指向存储归约结果的缓冲区。
- 作用:在根进程中,存储归约操作的结果;在非根进程中,该参数可以是 NULL(因为它们不会接收结果)。
- count(int)
-
- 定义:每个进程参与归约操作的数据项数目。
- 作用:指定每个进程参与归约操作的数据元素的数量。
- datatype(MPI_Datatype)
-
- 定义:数据类型。
- 作用:指定数据项的类型,如 MPI_INT、MPI_FLOAT 等。
- op(MPI_Op)
-
- 定义:归约操作。
- 作用:指定归约操作的类型,如 MPI_SUM(求和)、MPI_PROD(乘积)、MPI_MAX(最大值)等。
- root(int)
-
- 定义:根进程的标识符(rank)。
- 作用:指定哪个进程将接收归约结果。
- comm(MPI_Comm)
-
- 定义:通信子。
- 作用:指定进程间通信的上下文,通常使用 MPI_COMM_WORLD。
int main(int argc, char* argv[]) {
int my_rank, comm_sz;
int local_data;
int global_sum;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
MPI_Comm_size(MPI_COMM_WORLD, &comm_sz);
// 每个进程的数据
local_data = my_rank + 1;
// 进行归约操作,求和
MPI_Reduce(&local_data, &global_sum, 1, MPI_INT, MPI_SUM, 0, MPI_COMM_WORLD);
// 只有根进程(rank 0)输出结果
if (my_rank == 0) {
printf("The sum of all ranks is %d\n", global_sum);
}
MPI_Finalize();
return 0;
}

#include <stdio.h>
#include <stdlib.h>
#include <mpi.h>
double f(double x) {
return x * x; // 被积函数 x^2
}
double Trap(double local_a, double local_b, int local_n, double h) {
double integral = (f(local_a) + f(local_b)) / 2.0;
for (int i = 1; i <= local_n - 1; i++) {
double x = local_a + i * h;
integral += f(x);
}
integral *= h;
return integral;
}
int main(int argc, char* argv[]) {
int my_rank, comm_sz, n, local_n;
double a, b, h, local_a, local_b;
double local_int, total_int;
int source;
MPI_Init(NULL, NULL);
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
MPI_Comm_size(MPI_COMM_WORLD, &comm_sz);
if (my_rank == 0) {
n = 1000;
a = -2.0;
b = 2.0;
}
MPI_Bcast(&a, 1, MPI_DOUBLE, 0, MPI_COMM_WORLD);
MPI_Bcast(&b, 1, MPI_DOUBLE, 0, MPI_COMM_WORLD);
MPI_Bcast(&n, 1, MPI_INT, 0, MPI_COMM_WORLD);
h = (b - a) / n;
local_n = n / comm_sz;
local_a = a + my_rank * local_n * h;
local_b = local_a + local_n * h;
local_int = Trap(local_a, local_b, local_n, h);
MPI_Reduce(&local_int, &total_int, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD);
if (my_rank == 0) {
printf("With n = %d trapezoids, integral from %f to %f = %f\n", n, a, b, total_int);
}
MPI_Finalize();
return 0;
}
3.2.3. 集合通信与点对点通信的区别
-
所有的进程都必须调用相同的集合通信函数
-
每个进程传送给MPI的集合通信函数的参数必须相容
-
参数recvbuf只用在dest_process上
-
MPI_Reduce(sendbuf, recvbuf, count, datatype, op, dest_process,comm)
-
所有进程仍需要传递一个与recvbuf相对应的实际 参数,即使它的值是NULL
-
点对点通信通过标签和通信子匹配,集合通信通 过通信子和调用顺序匹配

Time 1:
b = a + c + c = 1 + 4 + 6 = 11
Time 2:
d = 2 + 3 + 5 = 10
3.2.4. 规约—广播(N—N)
- 区别:与MPI_Reduce相比,缺少dest_process这 个参数,因为所有进程都能得到结果。
- 通信子内所有进程都作为目标进程执行一次规约 操作,操作完毕后所有进程接收缓冲区的数据均相 同。这个操作等价于首先进行一次MPI_Reduce,然 后再执行一次MPI_Bcast
#include <stdio.h>
#include <mpi.h>
int main(int argc, char* argv[]) {
MPI_Init(&argc, &argv);
int my_rank, comm_sz;
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
MPI_Comm_size(MPI_COMM_WORLD, &comm_sz);
int local_value = my_rank + 1; // 每个进程的局部值
int total_sum = 0;
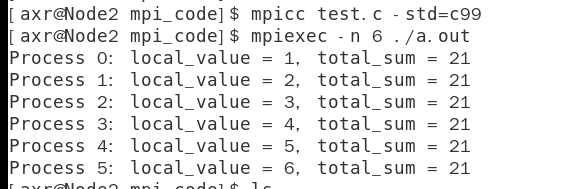
MPI_Allreduce(&local_value, &total_sum, 1, MPI_INT, MPI_SUM, MPI_COMM_WORLD);
printf("Process %d: local_value = %d, total_sum = %d\n", my_rank, local_value, total_sum);
MPI_Finalize();
return 0;
}
3.3. 通信方式——散射聚集
3.3.1. 散射
散射: 一对多
MPI_Scatter可以使0号进程读取整个向量,但是 只将分量发送给需要分量的其他进程
- 函数
MPI_Scatter(sendbuf,sendcount,sendtype,recvbuf,recvcount,recvty pe,src_proc,comm)
参数解释
- sendbuf: 指向发送缓冲区的指针。在根进程上,这是要分发的数据的起始地址。非根进程可以传递 NULL。
- sendcount: 每个进程要接收的数据项数量。发送的数据总量应为 sendcount * comm_sz,其中 comm_sz 是进程总数。
- sendtype: 发送数据项的类型,例如 MPI_INT。
- recvbuf: 指向接收缓冲区的指针。每个进程从 sendbuf 中接收的数据将存储在这里。
- recvcount: 每个进程接收的数据项数量。通常与 sendcount 相同。
- recvtype: 接收数据项的类型,例如 MPI_INT。
- root: 源进程的标识符(rank),即发送数据的进程。通常是 0。
- comm: 通信子,通常是 MPI_COMM_WORLD,表示所有进程都在这个通信子内。
int main(int argc, char* argv[]) {
int comm_sz; // 进程总数
int my_rank; // 当前进程的 rank
int *sendbuf = NULL;
int recvbuf;
int sendcount = 1;
int recvcount = 1;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
MPI_Comm_size(MPI_COMM_WORLD, &comm_sz);
// 根进程初始化发送缓冲区
if (my_rank == 0) {
sendbuf = (int *)malloc(comm_sz * sizeof(int));
for (int i = 0; i < comm_sz; i++) {
sendbuf[i] = i + 1; // 或者任意其他初始化方式
}
}
// 分发数据,每个进程接收一个整数
MPI_Scatter(sendbuf, sendcount, MPI_INT, &recvbuf, recvcount, MPI_INT, 0, MPI_COMM_WORLD);
// 打印接收到的数据
printf("Process %d received data %d\n", my_rank, recvbuf);
// 根进程释放发送缓冲区
if (my_rank == 0) {
free(sendbuf);
}
MPI_Finalize();
return 0;
}
Process 0 received data 1
Process 1 received data 2
Process 2 received data 3
Process 3 received data 4
3.3.2. 聚集
多对一
int MPI_Gather(const void *sendbuf, int sendcount, MPI_Datatype sendtype,
void *recvbuf, int recvcount, MPI_Datatype recvtype,
int root, MPI_Comm comm);
- sendbuf: 指向发送缓冲区的指针。每个进程要发送的数据的起始地址。
- sendcount: 每个进程发送的数据项数量。
- sendtype: 发送数据项的类型,例如 MPI_INT。
- recvbuf: 指向接收缓冲区的指针。只有根进程使用,其他进程传递 NULL。根进程接收到的数据将存储在这里。
- recvcount: 每个进程发送的数据项数量。注意:recvcount 通常等于 sendcount。
- recvtype: 接收数据项的类型,例如 MPI_INT。
- root: 目标进程的标识符(rank),即接收数据的进程。通常是 0。
- comm: 通信子,通常是 MPI_COMM_WORLD,表示所有进程都在这个通信子内。
int main(int argc, char* argv[]) {
int comm_sz; // 进程总数
int my_rank; // 当前进程的 rank
int sendbuf; // 每个进程要发送的数据
int *recvbuf = NULL;
int sendcount = 1;
int recvcount = 1;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
MPI_Comm_size(MPI_COMM_WORLD, &comm_sz);
// 每个进程初始化发送缓冲区
sendbuf = my_rank + 1;
// 根进程分配接收缓冲区
if (my_rank == 0) {
recvbuf = (int *)malloc(comm_sz * sizeof(int));
}
// 收集数据
MPI_Gather(&sendbuf, sendcount, MPI_INT, recvbuf, recvcount, MPI_INT, 0, MPI_COMM_WORLD);
// 根进程打印接收到的数据
if (my_rank == 0) {
printf("Root process received data:\n");
for (int i = 0; i < comm_sz; i++) {
printf("%d ", recvbuf[i]);
}
printf("\n");
free(recvbuf);
}
MPI_Finalize();
return 0;
}

4. 性能评估
4.1. 计时功能
double MPI_Wtime(void);
MPI_Wtime 返回一个双精度浮点数,表示自某个时间点(通常是程序开始执行时)到当前时间的秒数。
int main(int argc, char* argv[]) {
MPI_Init(&argc, &argv);
double start_time, end_time;
// 获取开始时间
start_time = MPI_Wtime();
// 模拟一些工作,假设用 sleep(2) 代表需要测量的代码段
// 在实际代码中应使用需要测量的代码段
sleep(2);
// 获取结束时间
end_time = MPI_Wtime();
// 计算并打印执行时间
printf("Execution time: %f seconds\n", end_time - start_time);
MPI_Finalize();
return 0;
}
MPI_Wtick
MPI_Wtick 返回一个双精度浮点数,表示计时器的分辨率(以秒为单位)。

4.2. 安全通信

第四章 Pthreads
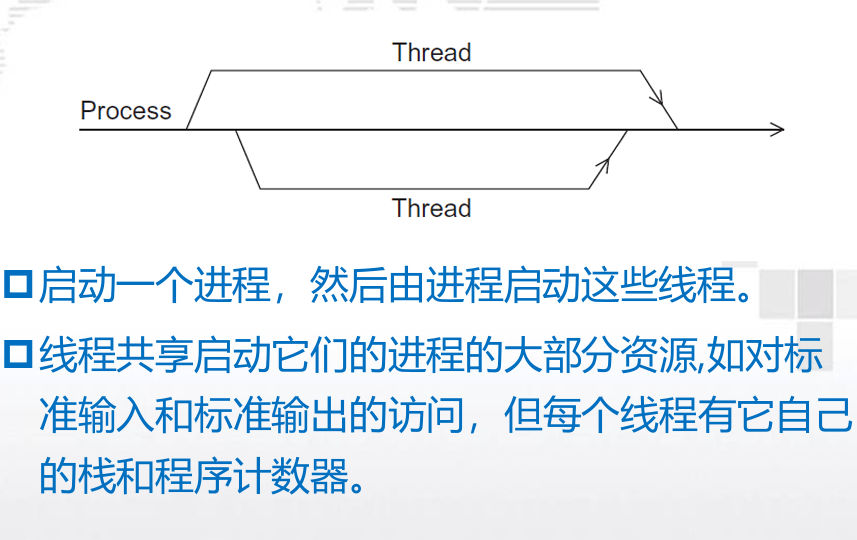
1. 进程、线程
- 进程、线程

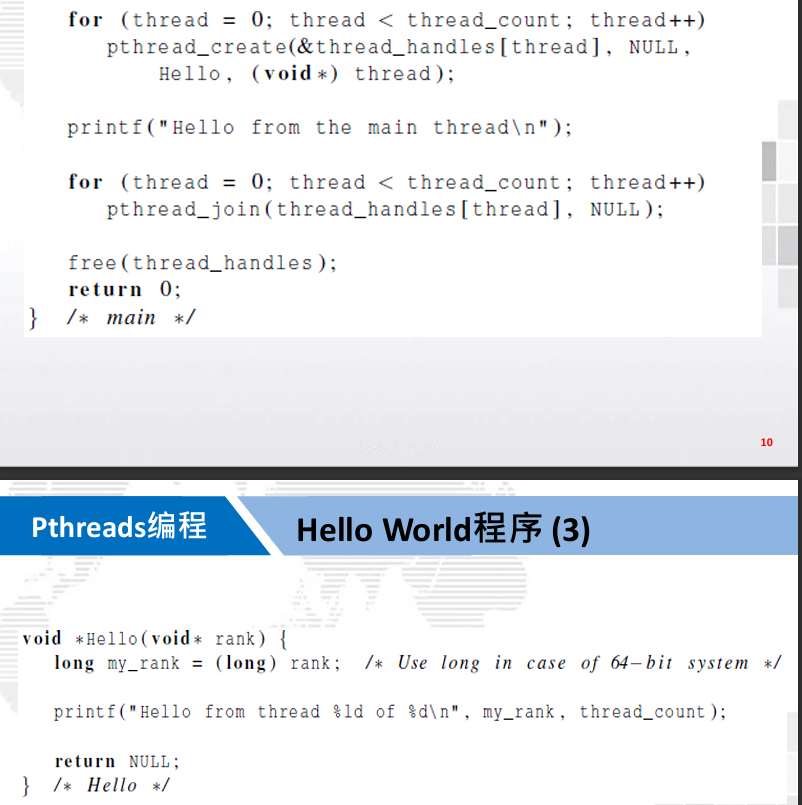
2. Pthreads( 共享内存编程模型 )
POSIX线程库也称为Pthreads线程库,它定义了一套多线程编程的应用程序编程接口 。
2.1. 编译
gcc−g −Wall −o pth_hellopth_hello.c−lpthread
参数解释
- gcc:
-
- GNU Compiler Collection,指的是使用 GCC 编译器来编译代码。
- -g:
-
- 生成包含调试信息的目标文件。这些调试信息可以用来使用调试器(如 gdb)调试程序。这对于开发和调试程序非常有用。
- -Wall:
-
- 启用所有常见的编译器警告。这有助于捕捉代码中的潜在问题和错误,使代码更加健壮和可靠。
- -o pth_hello:
-
- 指定输出文件的名称为 pth_hello。编译器会将生成的可执行文件命名为 pth_hello,而不是默认的 a.out。
- pth_hello.c:
-
- 输入的源代码文件,包含程序的实际实现。在这个例子中,文件名是 pth_hello.c。
- -lpthread:
-
- 链接 pthread 库。-l 选项告诉编译器链接指定的库,pthread 是 POSIX 线程库,提供了线程创建和管理的 API。


第五章 - 用OpenMP进行共享内存编程
1. OpenMP简介
OpenMP是一个针对共享内存编程的API。

2. 编译指导语句
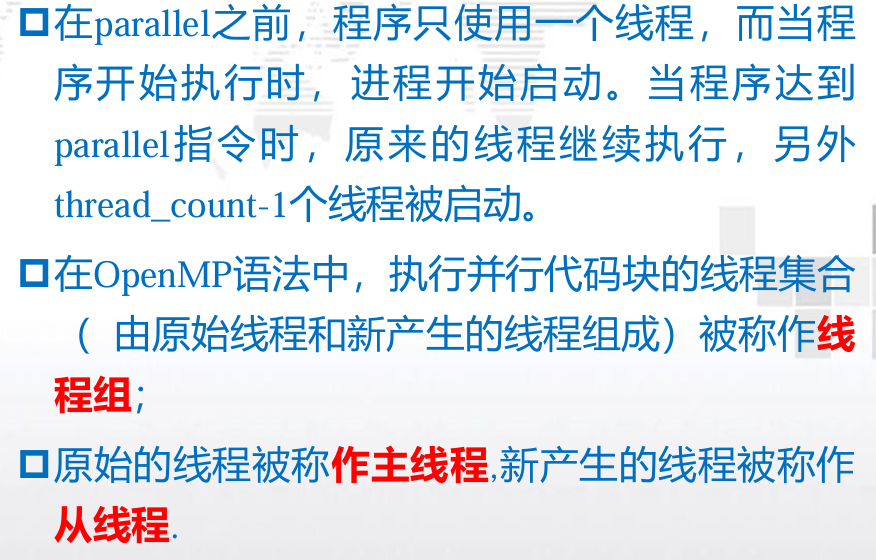
2.1. 并行执行模式:
"Fork/Join”方式:
- Fork(分叉):
- 在程序执行过程中,主线程创建多个子线程,这些子线程可以并行地执行不同的任务。
- 每个子线程负责一个子任务,所有子任务可以同时运行。
- Join(汇合):
- 子线程完成各自的任务后,汇合到主线程。
- 主线程等待所有子线程完成,收集它们的结果,然后继续执行后续的任务。
#include <stdio.h>
#include <omp.h>
int main() {
int nthreads;
// Fork: 主线程创建多个子线程
#pragma omp parallel
{
int tid = omp_get_thread_num(); // 获取线程编号
nthreads = omp_get_num_threads(); // 获取总线程数
printf("Hello from thread %d of %d\n", tid, nthreads);
}
// Join: 所有子线程完成并行区域,汇合到主线程
printf("All threads have finished.\n");
return 0;
}
2.2. 程序编写
- OpenMP是“基于指令”的共享内存API。
- OpenMP的头文件为
omp.h omp.h是由一组函数和宏库组成
2.2.1. 预处理指令
-
预处理指令是在C和C++中用来允许不是基本C 语言规范部分的行为;eg:特殊的预处理器指令 pragma。
-
不支持pragma的编译器会忽略pragma指令提示 的那些语句.
-
- 如果有一个pragma在一行中放不下,那么新行需要被转 义—— ‘’
- OpenMP中,预处理器指令以#pragmaomp开头
2.2.2. OpenMP编译指导语句格式
- OpenMP编译指导语句由 directive (指令)和 clause list (子句列表)组成。
- 在C/C++中,OpenMP编译指导语句的使用格式为:
#pragmaompparallel[clause…]new-line Structured-block

#include <stdio.h>
#include <stdlib.h>
#include <omp.h>
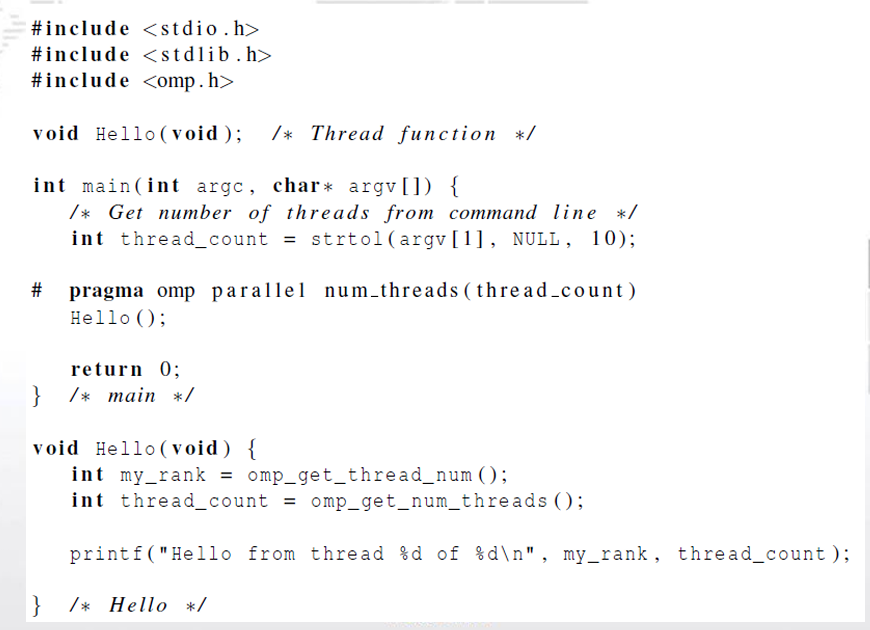
int main(int argc, char *argv[]) {
int i;
int thread_count = strtol(argv[1], NULL, 10);
#pragma omp parallel for num_threads(thread_count)
for (i = 0; i < 10; i++) {
printf("i = %d\n", i);
}
printf("Finished.\n");
return 0;
}
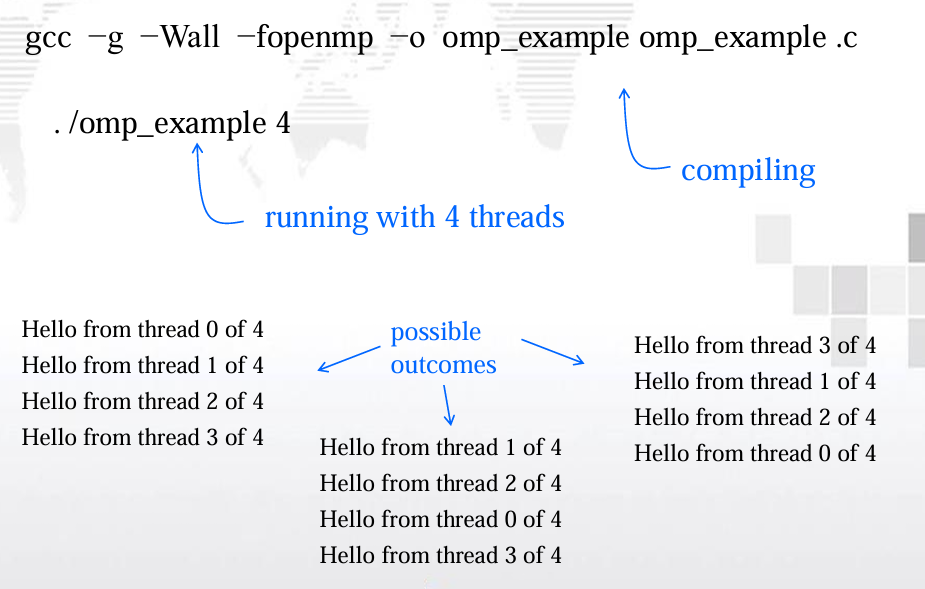
2.2.3. 编译运行
gcc -g -Wall -fopenmp -o omp_example omp_example.c
-fopenmp:
- 启用 OpenMP 支持。
# 分配四个 threads
./omp_example 4
2.2.4. helloworld 程序

- OpenMP 指令
#pragma omp parallel
- 最基本的并行指令
- parallel指令是用来表示之后的结构化代码块应该被多个线程并行执行。
- 结构化代码块是一条C语言语句或者只有一个入口和出口的一组复合C语句
- OpenMP 子句
# pragma omp parallel num_threads(thread_count)
- 修改指令的文本
- num_threads子句加在parallel指令之后
- 用来指定执行之后的代码块的线程数目.
- OpenMP 线程


- OpenMP函数
int omp_get_thread_num(void);
- 获得每个线程的编号(0-thread_count-1)
int omp_get_num_threads(void)
- 获得线程组中的线程数
注意因为标准输出被所有线程共享,所以每个 线程都能够执行printf语句,打印它的线程编号 和线程数。由于对标准输出的访问没有调度, 因此线程打印它们结果的实际顺序不确定
2.3. OpenMP 编程
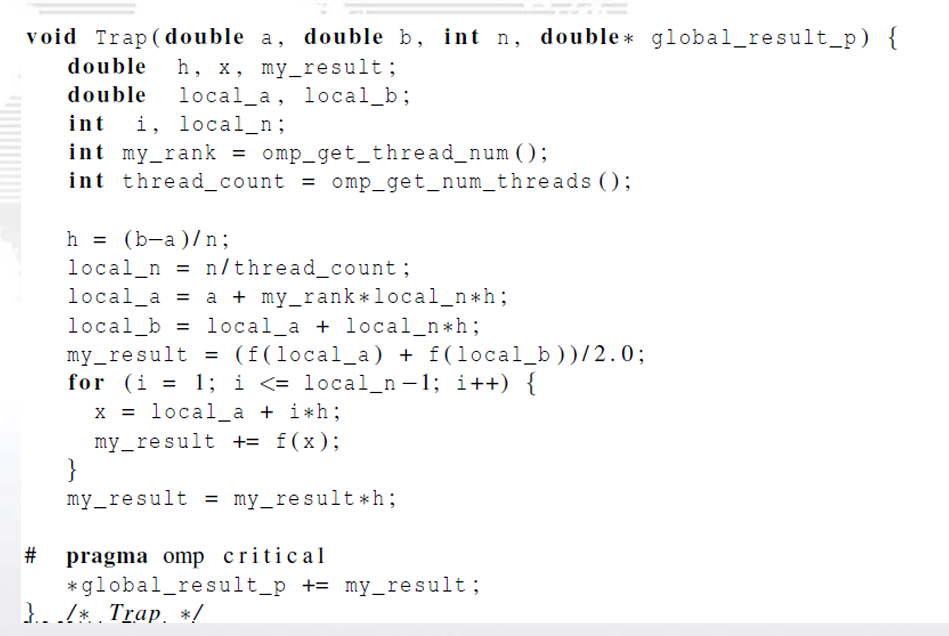
2.3.1. critical指令
引起竞争的代码,称为临界区
竞争:多个线程试图访问并更新一个共享资源
因此需要一些机制来确保一次只有一个线程执行 临界区,这种操作,我们称为互斥。
- critical指令用在一段代码临界区之前,临界区在 同一时间内只能有一个线程执行它,其他线程要 执行临界区则需要排队来执行它。
2.3.2. 变量作用域

2.3.3. 规约子句 reduction

注意:每个线程的私有拷贝值global_result初始化为0。
2.3.4. parallel for
for指令是用来将一个for循环分配到多个线程中执行。
for指令的使用方式:
- 单独用在parallel语句的并行块中;
- 与parallel指令合起来形成parallel for指令

parallel for指令