0. Abstract
最近在看一个用 RNNs 网络做 Translation 任务的程序, 关于数据处理部分, 主要用到工具包 sentencepiece 和 fairseq, 前者主要是对文本进行分词处理, 后者则是对已分词的文本进行二进制化和快速加载. 包越方便使用, 就说明包装得越狠, 也就越令人一头雾水, 本文简要记录学习过程.
1. Installation
pip install sentencepiece
pip install fairseq
注意, Windows 下安装 fairseq 需要 Visual C++ 构建工具, 否则会报错:
error: Microsoft Visual C++ 14.0 or greater is required. Get it with "Microsoft C++ Build Tools": https://visualstudio.microsoft.com/visual-cpp-build-tools/"
去官网下载 Microsoft C++ Build Tools 并安装就好了, 安装时须选择以下组件:

[注]: 不建议在 Windows 下跑这些程序, 很多包在 Windows 下问题太多, 甚至不支持. Microsoft C++ Build Tools 会占用 C 盘好几个 G (即使安装在其他盘).
小结: 建议在 Linux 系统下玩这些程序.
2. 用 sentencepiece 分词
翻译任务的数据集一般是这样的:



以中英文翻译任务为例, 有 {train/test}.{en/zh} 共 4 个文件, 文件中每一行代表一段文字, 中英文件内相同的行是彼此对应的.
2.1 字符全角转半角
这些数据内容是原始的 (raw), 首先要做的是进行数据清理: 字符编码统一化, 去除过长或过短的文本. “字符编码统一化” 值得记录一下:
def _str_q2b(ustring: str):
"""
把字串全形轉半形, 參考來源: https://ithelp.ithome.com.tw/articles/10233122;
全形(全角): 中文标点符号, 有时中文输入法输入英文字母也是全形, 类似 word 中输入英文, 字体是宋体
东亚文字一般是全形, 而西文字母和数字是半形(且对应有全形值).
那么为了使相同的字符在后端表示统一, 则把 65281 <= unicode <= 65374 范围内的全形字符转换到半形.
"""
rchars = []
for uchar in ustring:
unicode = ord(uchar) # unicode 码
if unicode == 12288: # 全形空格直接轉換
unicode = 32
elif 65281 <= unicode <= 65374: # 全形字元(除空格)根據關係轉化
unicode -= 65248
rchars.append(chr(unicode))
return ''.join(rchars)
关于全角和半角:
print('A', 'a', '0')
print(
chr(ord('A') + 65248),
chr(ord('a') + 65248),
chr(ord('0') + 65248)
)
会输出:

小结: Unicode 字符有全半角之分, 数据预处理时需先进行全角转半角, 统一化.
2.2 训练分词模型
spm.SentencePieceTrainer.train(
input=','.join([
f'{self._path_clean}/train.{self._lang_src}',
f'{self._path_clean}/train.{self._lang_tgt}'
]),
# will get 2 files: model_prefix.model, model_prefix.vocab
model_prefix=self._path_tokens / f'spm{vocab_size}',
vocab_size=vocab_size,
character_coverage=1,
model_type='unigram', # 'bpe' 也可
input_sentence_size=1e6,
shuffle_input_sentence=True,
normalization_rule_name='nmt_nfkc_cf'
)
这段代码展示了如何使用 sentencepiece 库中的 SentencePieceTrainer.train() 方法来训练一个 SentencePiece 分词模型, 特别适用于机器翻译任务, 其中涉及到两种不同的语言: [来自通义千问]
input: 指定了用于训练模型的文本文件. 在这个例子中, 使用的是源语言和目标语言的训练数据, 它们被拼接成一个字符串并用逗号分隔;model_prefix: 定义输出模型文件的前缀. 模型训练后会生成两个文件: 一个是 .model 模型文件, 另一个是 .vocab 的词汇表文件;vocab_size: 指定了词汇表的大小, 即模型将学习的词汇单元数量. 较大的词汇表可能会提供更好的表达能力, 但也可能导致过拟合或增加计算成本;character_coverage: 设置为 1 表示模型应该覆盖输入文本中的所有字符. 较小的值(如 0.995)意味着模型将忽略最不常见的 0.5% 的字符, 这可能有助于减少词汇表的大小;model_type: 设置为 ‘unigram’ 意味着模型将使用 Unigram 算法进行训练. 另一种选择是 ‘bpe’, 即 Byte-Pair Encoding, 也是一个常用的子词分割算法;input_sentence_size: 控制着用于训练的句子数量.1e6表示一百万句. 如果数据集非常大, 你可能想要抽样一定数量的句子以加快训练速度;shuffle_input_sentence: 如果设置为True, 则在训练过程中输入句子会被随机打乱, 有助于提高模型的泛化能力;normalization_rule_name: 这个参数确定了如何规范化输入文本.'nmt_nfkc_cf'是一个预定义的规则, 通常用于机器翻译任务, 它会执行一些文本清洗操作, 如转换为半角字符等.
呃!!! 前面还特意搞了一下字符转换, 可能多虑了. 那就看一下在 normalization_rule_name='nmt_nfkc_cf' 的情况下不进行半角转换, 模型会不会自动转换字符吧:
input=','.join([
f'{self._path_raw}/train.{self._lang_src}', # 使用 raw 中的数据进行分词
f'{self._path_raw}/train.{self._lang_tgt}'
]),
直接使用 raw 文件夹下的文本文件进行分词, 果然发现 spm.SentencePieceTrainer.train() 进行了半角转换:

没骗我们, 逗点变成英文的了, 但引号没有, 因为中文引号和英文引号不是全角和半角的关系.
小结: 使用 sentencepiece 库中的 SentencePieceTrainer.train() 方法可训练一个 SentencePiece 分词模型, 输入为 train.{en/zh} 文件, 输出为两个文件: model_prefix.model, model_prefix.vocab.
2.3 加载分词模型进行分词
spm_model = spm.SentencePieceProcessor()
spm_model.load(str(self._path_tokens / f'spm{vocab_size}.model'))
for file_name, lang in itertools.product(['train', 'valid', 'test'], [self._lang_src, self._lang_tgt]):
out_path = self._path_tokens / f'{file_name}.{lang}'
if not re_tokenize and out_path.exists():
print(f'{out_path} exists. skipping spm_encode.')
else:
with (
open(self._path_split / f'{file_name}.{lang}', 'r') as in_file,
open(out_path, 'w') as out_file
):
for line in in_file:
tokens = spm_model.encode(line.strip(), out_type=str) # 编码结果是 str
print(' '.join(tokens), file=out_file)
创建一个 SentencePieceProcessor() 实例, 并加载刚才训练所的的分词模型, 然后用 spm_model.encode(...) 对文本文件进行编码, 也就是分词.
3. fairseq 的使用
fairseq 的使用包括很多内容, 包括: 数据的二进制化、数据的加载、模型的定义与训练等.
3.1 数据的二进制化
经过 sentencepiece 的分词处理, 得到了分词后的文本. 下一步要对文本执行二进制化, 以便于快速加载到内存中. 注意不是写 python 代码, 而是执行命令行:
python -m fairseq_cli.preprocess \
--source-lang {src_lang}\
--target-lang {tgt_lang}\
--trainpref {prefix/'train'}\
--validpref {prefix/'valid'}\
--testpref {prefix/'test'}\
--destdir {binpath}\
--joined-dictionary\
--workers 2
此命令执行几个关键任务: [来自通义千问]
- 数据准备: 从指定的文件(‘train’, ‘valid’, ‘test’ 前缀)读取源语言和目标语言数据, 并将二进制格式的结果写入目的地目录(binpath);
- 字典创建: 通过指定
--joined-dictionary, 它为源语言和目标语言创建一个统一的字典. 这对于低资源场景或者当希望模型学习两种语言之间相似单词的映射时是有益的;
参数解析:
--source-lang {src_lang}: 源语言;--target-lang {tgt_lang}: 目标语言;--trainpref {prefix/'train'}: 训练数据文件的前缀; 实际的文件名将是{prefix}/train.{src_lang}和{prefix}/train.{tgt_lang}, 分别对应源语言和目标语言的文件;--validpref {prefix/'valid'}: 与上述相同, 但针对验证数据;--testpref {prefix/'test'}: 与上述相同, 但针对测试数据;--destdir {binpath}: 数据以二进制格式保存的目录;--joined-dictionary: 是否为源语言和目标语言创建共享词汇表.
运行此命令后, 应该能在 {binpath} 目录中找到多个二进制文件, 包括词典和已标记好的数据, 这些数据已经准备好用于训练神经机器翻译模型.

=== dict.{en/zh}.txt ===
两个词典文件是特殊的, 可能是词典内容往往不会很多, 所以没必要用二进制格式存储. 注意, 词典的根据仅仅是 train.{en/zh} 中的文本内容, 而不包括 {valid/test}.{en/zh}. 其内容是这样的:

统计了每个 token 的词频. 由于使用了 --joined-dictionary, 两个词典的内容是一样的. 倘若不使用这个参数, 则会将中英文的词典分开.
=== preprocess.log ===
preprocess.log 文件是数据预处理过程的日志文件, 里面会记录配置参数, 以及处理结果的数据统计:

可以看到有少量词被 <unk> 替代了, 但我们不知道替代的机制是什么, 也不打算追究了.
== 二进制文件 ==
二进制文件命名的前缀都是 {train/valid/test}.en-zh.{en/zh}, 后缀是 {bin/idx}, 以下解释来自通义千问:
bin 目录下的 .bin 和 .idx 文件是预处理阶段生成的二进制数据文件, 它们用于加速模型的训练过程. 这些文件由 fairseq-preprocess 工具生成, 当处理大规模文本数据时, 使用二进制格式可以显著减少数据加载和处理的时间.
=== .bin 文件 ===
.bin 文件包含了经过 Tokenization[?]、Numericalization 和 Padding 处理后的序列数据. 每个 .bin 文件通常对应于一个特定的数据集(如训练集、验证集或测试集), 并且分为源语言和目标语言两部分. 例如, 对于英语到德语的翻译任务, 你可能会看到 train.en-de.en.bin 和train.en-de.de.bin 这样的文件名.
在 .bin 文件中, 通常包含了以下信息:
- 每个样本的 Token ID 序列;
- 对应的长度信息;
- 可能还包括特殊标记, 如开始标记(BOS)和结束标记(EOS).
=== .idx 文件 ===
.idx 文件是一个索引文件, 它为对应的 .bin 文件提供快速随机访问的能力. 这是因为直接从二进制文件中随机读取数据通常是低效的, 尤其是当数据量很大时, .idx 文件存储了每个样本在 .bin 文件中的起始位置和长度信息, 使得模型在训练时可以直接跳转到所需的样本位置, 无需从头开始顺序读取整个文件.
还不知道有没有可以直接写在程序中的 python 代码 API.
上面说 “经过 Tokenization[?]、… 和 … 处理后”, 也不知道fairseq_cli.preprocess是否真的执行了分词操作.
将在附录中解答这两个问题.
小结: 使用 fairseq_cli.preprocess 命令可对数据进行二进制化, 可节省存储空间以及加快数据的加载速度, 同时提供数据的随机读取; 在过程中, 会对文本进行分词, 创建词典.
3.2 数据的加载
这种二进制文件让人讨厌的地方就在于你没法打开文件看一看.
任务配置及 task 对象的创建 → 用 task 对象 load 数据 → 遍历数据.
3.2.1 任务配置及 task 对象的创建
经过 fairseq_cli.preprocess 的处理, bin 目录中的各种文件就可以被 fairseq 中的数据加载工具加载了. 首先需要创建一个 task:
task_cfg = translation.TranslationConfig(
data=str(self._path_bin),
source_lang=self._lang_src,
target_lang=self._lang_tgt,
train_subset='train',
required_seq_len_multiple=8,
dataset_impl='mmap',
upsample_primary=1
)
task = translation.TranslationTask.setup_task(task_cfg)
TranslationConfig 是一个用于封装翻译任务相关配置的类, 它允许你设定训练和数据处理的多个方面. 下面详细解释一下这段代码中的参数:
data=str(self._path_bin): 数据目录的路径. 这个目录应该包含预处理后的数据, 如 .bin 和 .idx 文件;source_lang=self._lang_src: 源语言代码, 这将决定模型将哪种语言的文本作为输入. 例如, 如果源语言是英语, 则设置为"en";target_lang=self._lang_tgt: 目标语言代码, 这将决定模型将哪种语言的文本作为输出. 例如, 如果目标语言是汉语, 则设置为"zh";train_subset='train': 用于训练的子集名称. 在预处理阶段, 数据通常会被划分为训练、验证和测试三个子集, 这里选择的是"train"子集;required_seq_len_multiple=8: 设定序列长度需要是某个正整数的倍数. 在某些情况下, 特别是涉及到卷积神经网络(CNN)或注意力机制时, 要求输入序列长度是特定数值的倍数以优化计算效率. 这里设置为 8, 意味着序列长度必须会被填充为 8 的倍数;dataset_impl='mmap': 数据集的实现方式."mmap"表示使用内存映射文件的方式加载数据, 这种方式可以提高数据读取的速度, 尤其是在处理大量数据时;upsample_primary=1: 如果你使用的是多个训练数据集,upsample_primary参数用于控制主数据集(primary dataset)的上采样倍数. 设置为 1 意味着不进行上采样, 即主数据集的样本数量保持不变;
上采样(Upsampling)主要用于增加数据集中的样本数量. 上采样通常有以下两种主要的应用场景:
- 处理不平衡数据集: 当数据集中某一类别的样本数量远少于其他类别时, 少数类别的模型训练效果可能会受到影响, 因为模型容易偏向于多数类别. 上采样可以通过复制少数类别的样本或合成新的样本(如通过 SMOTE 算法)来平衡数据集, 从而改进模型在少数类别上的预测能力.
- 图像和序列数据的生成: 在生成对抗网络(GANs)或自编码器(Autoencoders)等模型中, 上采样层用于从较低分辨率或较短序列恢复高分辨率图像或长序列. 例如, 超分辨率重建就是一种典型的上采样应用, 旨在从低分辨率图像生成高分辨率图像.
上采样可以通过多种方式进行, 包括但不限于:
- 重复样本: 直接复制数据集中的少数类别样本, 增加其在数据集中的比例.
数据增强: 通过对现有样本进行变换(如旋转、翻转、缩放等)来合成新的样本, 这种方法常用于图像数据.- 插值: 在信号处理中, 上采样可以通过插入零值并在相邻点之间进行插值来实现, 从而提高信号的分辨率.
- 基于模型的方法: 如 GANs 和 Autoencoders 可以生成新的样本, 这种方法通常用于图像和序列数据的上采样.
这些配置通常会在训练脚本中被传入到 fairseq-train 或相关的训练函数中, 以启动模型的训练过程.
点开 TranslationConfig, 查看源码, 可以看到里面还有很多其他的设置, 包括:
left_pad_source: bool = field(
default=True, metadata={"help": "pad the source on the left"}
) # 默认情况下是在左侧 pad source 句子
left_pad_target: bool = field( # 而target 句子不 pad
default=False, metadata={"help": "pad the target on the left"}
)
max_source_positions: int = field(
default=1024, metadata={"help": "max number of tokens in the source sequence"}
)
max_target_positions: int = field(
default=1024, metadata={"help": "max number of tokens in the target sequence"}
)
task = translation.TranslationTask.setup_task(task_cfg) 是根据 task_cfg 创建了一个 TranslationTask 实例对象, 其中 setup_task(...) 是工厂方法:
@classmethod
def setup_task(cls, cfg: TranslationConfig, **kwargs):
"""
Setup the task (e.g., load dictionaries).
Args:
args (argparse.Namespace): parsed command-line arguments
"""
paths = utils.split_paths(cfg.data)
...
# load dictionaries
src_dict = cls.load_dictionary(
os.path.join(paths[0], "dict.{}.txt".format(cfg.source_lang))
)
tgt_dict = cls.load_dictionary(
os.path.join(paths[0], "dict.{}.txt".format(cfg.target_lang))
)
...
return cls(cfg, src_dict, tgt_dict)
首先加载了 dictionary, 然后连同 cfg 一起作为参数, 创建了一个 TranslationTask 实例对象, 其属性包括(继承自父类FairseqTask的属性和两个 dictionary):


小结: 根据 TranslationConfig 创建 TranslationTask 实例对象是一切的开始, 里面封装了很多操作, 如 数据集的加载与管理, 模型输入输出格式的定义等.
3.2.2 用 task 对象 load 数据
值得注意的是, path 不是直接来源于 cfg.data, 而是经过处理的:
paths = utils.split_paths(cfg.data)
>>>
def split_paths(paths: str, separator=os.pathsep) -> List[str]:
return (
paths.split(separator) if "://" not in paths else paths.split(MANIFOLD_PATH_SEP)
)
而 os.pathsep 是 :, 这让我想起来 Ubuntu 中一些环境变量配置时的 :, 我估摸着这就是多个路径的分隔符. 所以, cfg.data 有可能是多个路径. 这也呼应了前面的:

def load_dataset(self, split, epoch=1, combine=False, **kwargs):
"""
Load a given dataset split.
Args:
split (str): name of the split (e.g., train, valid, test)
"""
paths = utils.split_paths(self.cfg.data)
assert len(paths) > 0
if split != self.cfg.train_subset:
# if not training data set, use the first shard for valid and test
paths = paths[:1]
data_path = paths[(epoch - 1) % len(paths)]
# infer langcode
src, tgt = self.cfg.source_lang, self.cfg.target_lang
self.datasets[split] = load_langpair_dataset(
data_path,
split,
src, self.src_dict,
tgt, self.tgt_dict,
combine=combine,
dataset_impl=self.cfg.dataset_impl,
...
)
先解除一个疑惑: 训练文件的命名已经是 train.xxx, 且二进制预处理时也使用了参数 --trainpref, 文件名也是 fairseq 包生成的, 为何还要在 TranslationConfig 中使用 train_subset='train' 设置训练文件名?
在 load_dataset(...) 中也许有了答案:
if split != self.cfg.train_subset:
# if not training data set, use the first shard for valid and test
paths = paths[:1]
这里用于判断 split 是否是 train_subset, 如果不是, 则去掉其他数据路径, 只保留第一个路径. 而后面的一句:
data_path = paths[(epoch - 1) % len(paths)] # path[(epoch-1) % 1] = path[0]
data_path 就只取第一个路径. 所以猜测:
cfg.data是由:分隔的多个数据集路径;- 训练数据集可能存在于多个路径中, 而
valid/test数据则只存在于第一个路径中, 即 primary 数据集; - 若
split == self.cfg.train_subset', 即读取训练集, 则读取数据的路径随epoch滚动.
那为什么不直接 if split != 'train' 呢? 呃! 咱也不知道, 可能还能设置 train_subset='valid'?
好! 接下来使用 load_langpair_dataset(...) 函数加载数据集:
def load_langpair_dataset(...):
...
src_datasets = []
tgt_datasets = []
# 迭代 k, 意思是文件夹内可能存在 {train/valid/test}{k} 多个文件, 需要 append 到 [] 中
for k in itertools.count(): # 无限迭代器
split_k = split + (str(k) if k > 0 else "") # train, train1, train2, ...
# prefix = ./bin/train.en-zh.
if split_exists(split_k, src, tgt, src, data_path):
prefix = os.path.join(data_path, "{}.{}-{}.".format(split_k, src, tgt))
elif split_exists(split_k, tgt, src, src, data_path):
prefix = os.path.join(data_path, "{}.{}-{}.".format(split_k, tgt, src))
else:
if k > 0: # 如果 ./bin/train1.en-zh.en.{bin/idx} 和 ./bin/train1.zh-en.en.{bin/idx} 都没找到
break
else:
raise FileNotFoundError(
"Dataset not found: {} ({})".format(split, data_path)
)
src_dataset = data_utils.load_indexed_dataset(
prefix + src, src_dict, dataset_impl
)
...
src_datasets.append(src_dataset)
tgt_dataset = data_utils.load_indexed_dataset(
prefix + tgt, tgt_dict, dataset_impl
)
if tgt_dataset is not None:
tgt_datasets.append(tgt_dataset)
...
if not combine:
break
...
# >>> 合并多个文件中的文本 >>>
if len(src_datasets) == 1:
src_dataset = src_datasets[0]
tgt_dataset = tgt_datasets[0] if len(tgt_datasets) > 0 else None
else:
sample_ratios = [1] * len(src_datasets)
sample_ratios[0] = upsample_primary # 增加主文件的采样权重
src_dataset = ConcatDataset(src_datasets, sample_ratios)
if len(tgt_datasets) > 0:
tgt_dataset = ConcatDataset(tgt_datasets, sample_ratios)
else:
tgt_dataset = None
...
eos = None
...
align_dataset = None
...
tgt_dataset_sizes = tgt_dataset.sizes if tgt_dataset is not None else None
return LanguagePairDataset(
src_dataset,
src_dataset.sizes,
src_dict,
tgt_dataset,
tgt_dataset_sizes,
tgt_dict,
...cfg.xxx...
)
这段代码假设 bin 文件夹内存在 {train/valid/test}{k} 多个文件, 读到多个 {src/tgt}_datasets = [] 中, 并通过 ConcatDataset(src_datasets, sample_ratios) 合并到一个 dataset 中, 最后通过 LanguagePairDataset(...) 创建语言对数据集. 所以这里我们要继续看三个东西:
data_utils.load_indexed_dataset(...);ConcatDataset(xxx_datasets, sample_ratios);LanguagePairDataset(src_dataset, src_dataset.sizes, src_dict, tgt_dataset, tgt_dataset_sizes, tgt_dict, ...).
3.2.2.1 data_utils.load_indexed_dataset(...)
src_dataset = data_utils.load_indexed_dataset(
prefix + src, src_dict, dataset_impl
)
这里的 prefix+src = './bin/train.en-zh.en', 连同 src_dict, dataset_impl 传入 data_utils.load_indexed_dataset(...), 进行数据加载:
def load_indexed_dataset(
path, dictionary=None, dataset_impl=None, combine=False, default="cached"
):
import fairseq.data.indexed_dataset as indexed_dataset
from fairseq.data.concat_dataset import ConcatDataset
datasets = []
for k in itertools.count():
path_k = path + (str(k) if k > 0 else "")
try: # 有后缀 '.bin/.idx' 的 path 去掉后缀, 这里的 path =
# prefix+src = './bin/train.en-zh.en' 无, 故保持不变
path_k = indexed_dataset.get_indexed_dataset_to_local(path_k)
except Exception as e:
...
...
dataset = indexed_dataset.make_dataset(
path_k,
impl=dataset_impl_k or default,
fix_lua_indexing=True,
dictionary=dictionary
)
if dataset is None:
break # 加载完毕
datasets.append(dataset)
if not combine:
break # not combine, 则仅使用一个数据文件
if len(datasets) == 0:
return None
elif len(datasets) == 1:
return datasets[0]
else:
return ConcatDataset(datasets)
这里依然假设有多个文件要加载, 由 combine 参数决定加载多个, 还是只加载头一个:
combine (bool, optional): automatically load and combine multiple datasets.
For example, if *path* is 'data-bin/train', then we will combine
'data-bin/train', 'data-bin/train1', ... and
return a single ConcatDataset instance.
只可惜, 这里的调用使用了默认值 False, 也就是只有一个文件. 我们只需要看:
dataset = indexed_dataset.make_dataset(
path_k,
impl=dataset_impl_k or default,
fix_lua_indexing=True,
dictionary=dictionary
)
def make_dataset(path, impl, fix_lua_indexing=False, dictionary=None):
if ...:
...
elif impl == "mmap" and MMapIndexedDataset.exists(path):
return MMapIndexedDataset(path) // 我们使用的, 也是默认的
...
return None
它是根据 impl 决定加载方式的, 对于我们使用的 'mmap', 它不需要 fix_lua_indexing, dictionary 这两个参数, 仅仅有加载路径就行了. 下面是真正的重点, 展现了如何加载二进制文件:
class MMapIndexedDataset(torch.utils.data.Dataset):
def __init__(self, path):
super().__init__()
self._path = None
self._index = None
self._bin_buffer = None
self._do_init(path)
def _do_init(self, path):
self._path = path
self._index = self.Index(index_file_path(self._path)) # idx 文件加载
# >>> .bin 文件加载 >>>
_warmup_mmap_file(data_file_path(self._path)) # 加载测试, 啥都没干
self._bin_buffer_mmap = np.memmap(
data_file_path(self._path), mode="r", order="C"
)
self._bin_buffer = memoryview(self._bin_buffer_mmap)
@lru_cache(maxsize=8)
def __getitem__(self, i):
ptr, size = self._index[i]
np_array = np.frombuffer(
self._bin_buffer, dtype=self._index.dtype, count=size, offset=ptr
)
if self._index.dtype != np.int64:
np_array = np_array.astype(np.int64)
return torch.from_numpy(np_array)
可以看到, 构建这个 MMapIndexedDataset 主要干了两件事: (1) 加载 .idx 文件, (2) 用 np.memmap(...) 构建了 .idx 文件的内存映射. 然后 __getitem__(self, i) 使用 np.frombuffer(...) 读取 .bin 文件, 将数据转化为 torch.long 返回. 至于 self.Index, 这个对象里有数据的一些元信息以及每条数据在 .bin 文件中的位置与长度, 详情在附录中(包含以内存映射方式读取二进制文件).
3.2.2.2 ConcatDataset(xxx_datasets, sample_ratios)
虽然此例中, 我们只有一个数据集, 但还是要了解一下多数据集是如何拼接的:
class ConcatDataset(FairseqDataset):
def __init__(self, datasets, sample_ratios=1):
super(ConcatDataset, self).__init__()
self.datasets = list(datasets)
if isinstance(sample_ratios, int):
sample_ratios = [sample_ratios] * len(self.datasets)
self.sample_ratios = sample_ratios
# 根据每个数据集的采样权重, 设置整个数据集的累计下标, 也即把数据集挨个摆放, 样本下标是累计的;
# 如果有 3 个数据集, 大小分别为: 100, 300, 200; sample_ratios = [2, 4, 3];
# 那么, cumulative_sizes = [200, 1400, 2000]
self.cumulative_sizes = self.cumsum(self.datasets, sample_ratios)
self.real_sizes = [len(d) for d in self.datasets] # 各数据集的实际大小: [100, 300, 200]
def __len__(self):
return self.cumulative_sizes[-1]
def __getitem__(self, idx):
# 根据 real_sizes, cumulative_sizes 等信息, 计算出该取哪个数据集的哪个样本
dataset_idx, sample_idx = self._get_dataset_and_sample_index(idx)
return self.datasets[dataset_idx][sample_idx]
3.2.2.3 LanguagePairDataset(src_dataset, src_dataset.sizes, src_dict, tgt_dataset, tgt_dataset_sizes, tgt_dict, ...)
其实这个 LanguagePairDataset 就没什么好说的了, 它只是将源和目标数据集放在一块, 一起加载而已. 如果非要说点什么, 无非就是它除了拼装之外, 还进行了一些额外的操作:
class LanguagePairDataset(FairseqDataset):
"""
A pair of torch.utils.data.Datasets.
Args:
left_pad_source (bool, optional): pad source tensors on the left side
(default: True).
left_pad_target (bool, optional): pad target tensors on the left side
(default: False).
input_feeding (bool, optional): create a shifted version of the targets
to be passed into the model for teacher forcing (default: True).
remove_eos_from_source (bool, optional): if set, removes eos from end
of source if it's present (default: False).
append_eos_to_target (bool, optional): if set, appends eos to end of
target if it's absent (default: False).
append_bos (bool, optional): if set, appends bos to the beginning of
source/target sentence.
num_buckets (int, optional): if set to a value greater than 0, then
batches will be bucketed into the given number of batch shapes.
"""
其中我们能通过 TranslationConfig 设置的参数有:
left_pad_source=self.cfg.left_pad_source, # default=True
left_pad_target=self.cfg.left_pad_target, # default=False
num_buckets=self.cfg.num_batch_buckets, # default=0
pad_to_multiple=self.cfg.required_seq_len_multiple
起码在使用 task 对象加载数据的过程中, LanguagePairDataset 的其他参数都是默认固定好的.
其样本的样式是这样的:
def __getitem__(self, index):
tgt_item = self.tgt[index] if self.tgt is not None else None
src_item = self.src[index]
if self.append_eos_to_target:
...
if self.append_bos:
...
if self.remove_eos_from_source:
...
example = {
"id": index,
"source": src_item,
"target": tgt_item,
}
...
return example
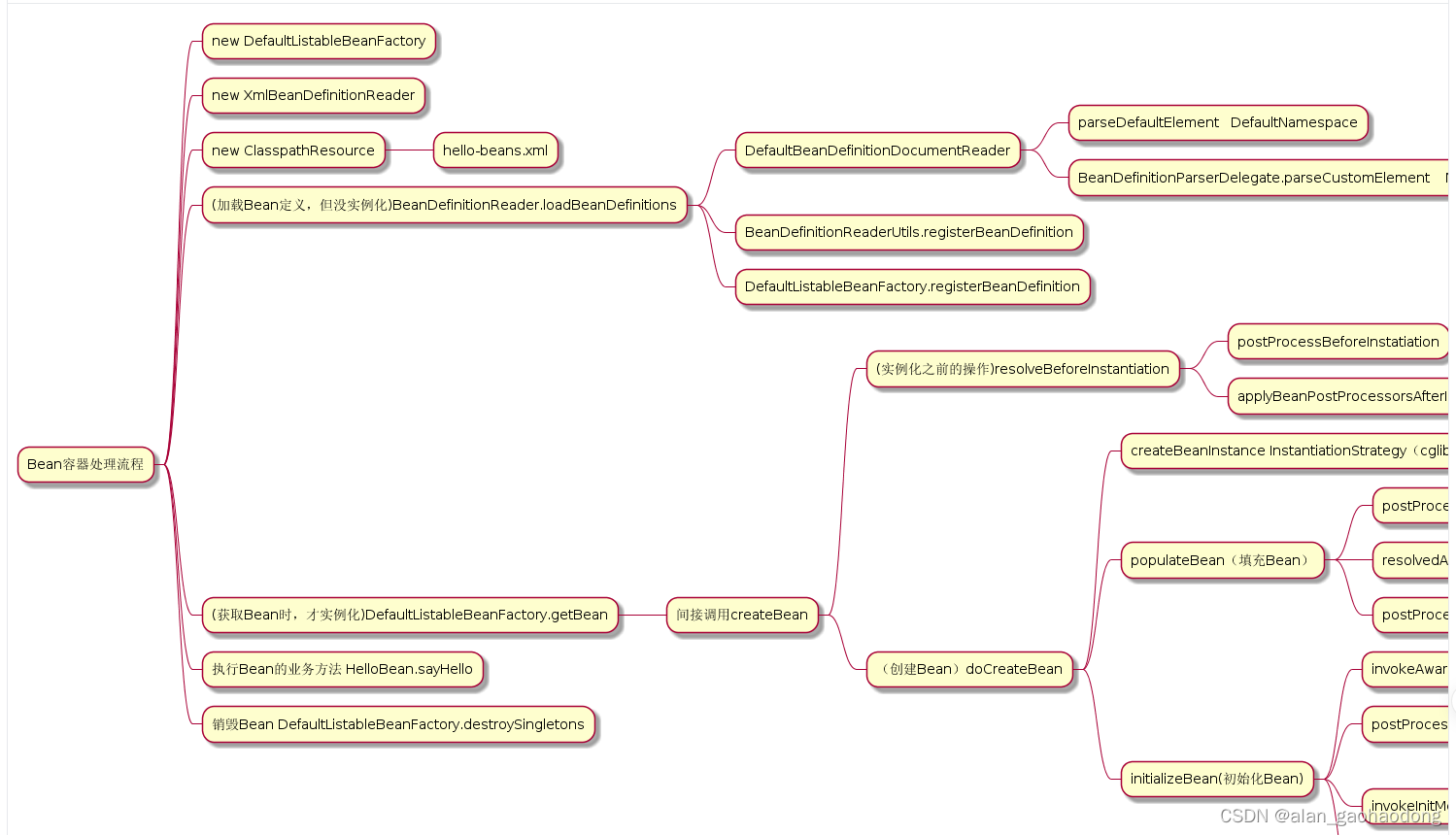
小结: 至此, 漫长的数据加载之路就结束了, 太过漫长, 以至于我们"不识大体". 画一张图来"识一下大体"吧:

3.2.3 数据集的遍历
加载完数据之后, 就可以遍历数据了, 我们把 valid 数据拿出来看看:
sample = task.dataset("valid")[0] # valid 数据集的第 1 个样本
pprint.pprint(sample)
pprint.pprint( # 将下标张量转化为 str 的句子
"Source: " + task.source_dictionary.string(
sample['source'],
"sentencepiece", # 说明预处理时的分词工具, 以便还原句子
)
)
pprint.pprint(
"Target: " + task.target_dictionary.string(
sample['target'],
"sentencepiece",
)
)
{
'id': 0,
'source': tensor([22, 59, 12, 2601, 13, 452, 16, 5, 326, 13, 21, 6, 7, 2]),
'target': tensor([51, 760, 1488, 792, 442, 1591, 1564, 10, 2])
}
'Source: we have to buy a lot of those ads .'
'Target: 我們必須買很多那些廣告 。'
可见结果如 LanguagePairDataset 中写的那样, 返回了一个形如
example = {
"id": index,
"source": src_item,
"target": tgt_item,
}
的样本, 包含着样本的 id, 源语言的句子 src_item, 目标语言的句子 tgt_item. 句子是由单词对应的下标张量所表示, 还没有经过 padding 等操作, 还是比较原始的, 仅仅在末尾添加了一个 2, 从
class Dictionary:
def __init__(
self,
*, # begin keyword-only arguments
bos="<s>",
pad="<pad>",
eos="</s>",
unk="<unk>",
extra_special_symbols=None,
):
self.bos_word, self.unk_word, self.pad_word, self.eos_word = bos, unk, pad, eos
self.symbols = [] # 单词列表
self.count = [] # # 对应词频
self.indices = {} # 单词在 symbol 和 count 中的下标
self.bos_index = self.add_symbol(bos) # 首先添加四个特殊标记
self.pad_index = self.add_symbol(pad) # 并返回其下标
self.eos_index = self.add_symbol(eos)
self.unk_index = self.add_symbol(unk)
来看, 2 是 eos="</s>", 表示句子的结束. 0 是句子的开始 <s>, 1 是 <pad>, 3 是 <unk>.
上面只是拿出来一个样本看看, 如何迭代呢?
for i, sample in enumerate(task.dataset("valid")):
if i < 3:
pprint.pprint(sample)
像普通数据集一样迭代? 自然不是, 还得组成 batch 呢! 然而并不是放到 DataLoader 里面, fairseq 里有专门的迭代器:
batch_iterator = task.get_batch_iterator(
dataset=task.dataset(split),
max_tokens=config.max_tokens,
max_sentences=None,
max_positions=utils.resolve_max_positions(task.max_positions(), config.max_tokens),
ignore_invalid_inputs=True,
seed=config.seed,
num_workers=config.num_workers,
epoch=epoch,
disable_iterator_cache=not cached
)
似乎 batch_size 并不是由一个叫 batch_size 的参数决定, 而是由:
max_tokens=config.max_tokens,
max_sentences=None,
max_positions=utils.resolve_max_positions(task.max_positions(), config.max_tokens)
等参数决定. 输出两个batch 看看:
{
'id': tensor([1960, 3713, 1096, 441, 2897, 2340, 493, 2309, 1383, 2517]),
'net_input': {
'prev_output_tokens': tensor(
[[2, 138, ..., 10, 1, 1, 1, 1],
[2, 5, ..., 869, 1, 1, 1, 1],
...,
[2, 115, ..., 2178, 10, 1, 1, 1]]
),
'src_lengths': tensor([30, 30, 30, 30, 30, 30, 30, 30, 30, 30]),
'src_tokens': tensor(
[[1, ..., 1, 17, ..., 6, 7, 2],
...,
[1, ..., 1, 33, ..., 6, 7, 2]]
)
},
'nsentences': 10,
'ntokens': 207,
'target': tensor(
[[138, ..., 10, 2, 1, 1, 1, 1],
[ 5, ..., 869, 2, 1, 1, 1, 1],
...,
[115, ..., 10, 2, 1, 1, 1, 1]]
)
}
{
'id': tensor([2488, 3873, 1464, 387]),
'net_input': {
'prev_output_tokens': tensor(
[[ 2, 148, ..., 1170, 4, 1, ..., 1],
[ 2, 51, ..., 8, 10, 1, ..., 1],
[ 2, 5, ..., 4293, 10, 1, ..., 1],
[ 2, 627, ..., 3082, 231, 1, 1, 1]]
),
'src_lengths': tensor([57, 57, 57, 57]),
'src_tokens': tensor(
[[1, 1, 1, 32, ..., 2405, 7, 2],
[1, 1, 1, 11, ..., 6, 7, 2],
[1, 1, 1, 12, ..., 643, 7, 2],
[1, 1, 1, 32, ..., 1456, 7, 2]]
)
},
'nsentences': 4,
'ntokens': 231,
'target': tensor(
[[148, ..., 1170, 4, 2, 1, ..., 1],
[ 51, ..., 8, 10, 2, 1, ..., 1],
[ 5, ..., 4293, 10, 2, 1, ..., 1],
[627, ..., 3082, 231, 2, 1, 1, 1]]
)
}
可以看到, 两个 batch 的 ntokens 和 nsentences 都不一样, 说明 batch 中 sample 的数量不是由这两者决定. 来看看通义千问的解释:
max_tokens=None, # 每个批次的最大令牌数
max_sentences=None, # 每个批次的最大句子数
max_positions=None, # 输入序列的最大长度
在函数 task.get_batch_iterator(...) 内确实能找到:
# filter examples that are too large
if max_positions is not None:
indices = self.filter_indices_by_size(
indices, dataset, max_positions, ignore_invalid_inputs
)
# create mini-batches with given size constraints
batch_sampler = dataset.batch_by_size(
indices,
max_tokens=max_tokens,
max_sentences=max_sentences,
required_batch_size_multiple=required_batch_size_multiple
)
所以, max_position 是用来过滤掉过长的句子的. 实际上模型也有这个最大句长限制:
# 解决最大位置限制
max_positions = utils.resolve_max_positions(
model.max_positions(),
task.max_positions(),
default_max_positions=(1024, 1024)
)
由模型、数据和用户设置三者决定, 默认都是 None, 可能就是没有限制的意思. 具体细节就不追究了.
而 max_tokens 和 max_sentences 共同决定了 batch 的大小. 每个batch 所含的 tokens 数量不会超过 max_tokens, 句子数量也不会超过 max_sentences. (注意, 计数不包括填充.)
再来看一下 batch 的内部, 字典内有 'id', 'net_input', 'nsentences', 'ntokens', 'target' 等五部分组成, 真正输入到网络里的是 'net_input'(后面再说). 值得注意是:
- 数据都是经过填充的, 一个
batch内的src_tokens,'target'和'prev_output_tokens'都是各自在内部对其的, 这样才能在表示在一个二维张量里. 默认情况下,src是在左侧填充,tgt是在右侧填充; - 真正输入到解码器的不是
'target'而是batch['net_input']['prev_output_tokens'], 其是把'target'的2移到开端; - 一个
batch内的句子长度都是接近的, 这似乎是由于句子已经按长度排好序了. 设置shuffle=False, 会发现batch[nsentences]越来越小, 说明句子是越来越长的; - 填充句子时, 会将句子张量的长度
batch['src_tokens'].shape[-1]等填充到cfg.required_seq_len_multiple的倍数, 据说是为了内存的高效利用.
3.3 Seq2Seq 模型
class Seq2Seq(FairseqEncoderDecoderModel):
def __init__(self, args, encoder, decoder):
super().__init__(encoder, decoder)
self.args = args
def forward(
self,
src_tokens,
src_lengths,
prev_output_tokens,
return_all_hiddens: bool = True
):
"""
Run the forward pass for an encoder-decoder model.
"""
encoder_out = self.encoder(
src_tokens, src_lengths=src_lengths, return_all_hiddens=return_all_hiddens
)
logits, extra = self.decoder(
prev_output_tokens,
encoder_out=encoder_out,
src_lengths=src_lengths,
return_all_hiddens=return_all_hiddens
)
return logits, extra
这是翻译任务的模型架构, 由一个 encoder 和一个 decoder 组成, 继承 fairseq 中的 FairseqEncoderDecoderModel, 并实现其抽象方法 forward 方法. 可以看到, 其所需参数恰好跟 batch_iterator = task.get_batch_iterator(...) 迭代器所返回的样本中 batch['net_input'] 内容是一致的. 然后, 数据经过 encoder 和 decoder 的处理, 得到了 logits, 我们知道, 它就是输入到损失函数的东西.
下面, 我们分别详细地看一下 encoder 和 decoder 是什么样的.
3.3.1 FairseqEncoder
class RNNEncoder(FairseqEncoder):
def __init__(self, args, dictionary, embed_tokens):
super().__init__(dictionary)
self.embed_tokens = embed_tokens
self.embed_dim = args.encoder_embed_dim
self.hidden_dim = args.encoder_ffn_embed_dim
self.num_layers = args.encoder_layers
self.dropout_in_module = nn.Dropout(args.dropout)
self.rnn = nn.GRU(
self.embed_dim,
self.hidden_dim,
self.num_layers,
dropout=args.dropout,
batch_first=False, # True 时, 输入和输出的形状应为 (batch, seq, feature), 而不是默认的 (seq, batch, feature)
bidirectional=True
)
self.dropout_out_module = nn.Dropout(args.dropout)
self.padding_idx = dictionary.pad()
def combine_bidir(self, outs, bsz: int):
out = outs.view(self.num_layers, 2, bsz, -1).transpose(1, 2).contiguous()
return out.view(self.num_layers, bsz, -1)
def forward(self, src_tokens, src_lengths=None, **kwargs):
bsz, seqlen = src_tokens.size() # batch_size 在前
# get embeddings
x = self.embed_tokens(src_tokens) # (batch_size, seq_len, embd_dim)
x = self.dropout_in_module(x) # 输入前就进行 dropout
# B x T x C -> T x B x C
x = x.transpose(0, 1) # 换了 (seq_len, batch_size, embd_dim)
# 過雙向 RNN
h0 = x.new_zeros(2 * self.num_layers, bsz, self.hidden_dim)
x, final_hiddens = self.rnn(x, h0)
outputs = self.dropout_out_module(x) # 输出 dropout
# outputs = [seq_len, batch_size, hid_dim * directions] 是最上層 RNN 的輸出
# hidden = [num_layers * directions, batch_size, hid_dim]
# 因為 Encoder 是雙向的 RNN,所以需要將同一層兩個方向的 hidden_state 接在一起
final_hiddens = self.combine_bidir(final_hiddens, bsz)
# hidden = [num_layers x batch x num_directions*hidden]
encoder_padding_mask = src_tokens.eq(self.padding_idx).t()
return (
outputs, # seq_len x batch x hidden
final_hiddens, # num_layers x batch x num_directions*hidden
encoder_padding_mask # seq_len x batch
)
def reorder_encoder_out(self, encoder_out, new_order):
# 這個 beam search 時會用到,意義並不是很重要
return (
encoder_out[0].index_select(1, new_order),
encoder_out[1].index_select(1, new_order),
encoder_out[2].index_select(1, new_order),
)
附录
1. fairseq_cli.preprocess 对应的 Python API
对于 fairseq_cli.preprocess 命令行, 想要把该功能融合进程序中, 得把命令行内容写进一个 shell 脚本, 这里假设脚本文件名为 'tobin.sh', 然后调用 python 的 subprocess.run(...) 函数以执行 shell 脚本:
#!/bin/bash
python -m fairseq_cli.preprocess \
--source-lang $1\
--target-lang $2\
--trainpref $3\
--validpref $4\
--testpref $5\
--destdir $6\
--joined-dictionary\
--workers 4
result = subprocess.run(
[
'bash', './tobin.sh',
f'{self._lang_src}',
f'{self._lang_tgt}',
f'{self._path_tokens}/train',
f'{self._path_tokens}/valid',
f'{self._path_tokens}/test',
f'{self._path_bin}'
],
capture_output=True, text=True
)
if result.returncode == 0:
print(result.stdout)
else:
print(result.stderr)
那有没有对应的 python API 可调用呢? 答案是肯定的, 我们找到了 fairseq_cli.preprocess.py 文件, 里面是数据处理代码:
def cli_main():
parser = options.get_preprocessing_parser()
args = parser.parse_args()
main(args)
操作主要在 main(args) 函数中, 其中 args 中充满了各种配置, 来自于命令行, 那我们自然可以自己构建一个 args, 然后调用 main(args). 只可惜, 我们不知道里面到底需要哪些配置, 因为 args = parser.parse_args() 中可是有很多默认配置的, 要是盲目地这么干:
args = { # 设置参数
'source_lang': 'en',
'target_lang': 'zh',
'trainpref': './data/tokens/train',
'validpref': './data/tokens/valid',
'testpref': './data/tokens/test',
'destdir': './data/bin',
'joined_dictionary': True,
'workers': 2
}
args = argparse.Namespace(**args) # 转换命名空间
os.makedirs(args.destdir, exist_ok=True) # 创建输出目录
preprocess.main(args) # 调用预处理函数
则:
AttributeError: 'Namespace' object has no attribute 'dataset_impl'
那么我们可以这么干:
import argparse
import os
from fairseq import options
from fairseq_cli import preprocess
parser = options.get_preprocessing_parser()
args = vars(parser.parse_args()).update({ # 设置参数
'source_lang': 'en',
'target_lang': 'zh',
'trainpref': './data/tokens/train',
'validpref': './data/tokens/valid',
'testpref': './data/tokens/test',
'destdir': './data/bin',
'joined_dictionary': True,
'workers': 2
})
args = argparse.Namespace(**args) # 转换命名空间
os.makedirs(args.destdir, exist_ok=True) # 创建输出目录
preprocess.main(args) # 调用预处理函数
拿到默认配置, 然后用设置我们的参数.
2. fairseq_cli.preprocess 预处理时 ‘Tokenization’ 了吗?
为了验证这个问题, 我们直接将未经 sentencepiece 处理过的数据用 fairseq_cli.preprocess 进行二进制化:
args.update({ # 设置参数
...
'trainpref': f'{self._path_split}/train',
'validpref': f'{self._path_split}/valid',
'testpref': f'{self._path_split}/test',
...
})
会得到:
[en] Dictionary: 846872 types
[en] ./data/split/train.en: 389051 sents, 7972723 tokens, 0.0% replaced (by <unk>)
[en] Dictionary: 846872 types
[en] ./data/split/valid.en: 3929 sents, 80476 tokens, 0.588% replaced (by <unk>)
[en] Dictionary: 846872 types
[en] ./data/split/test.en: 1000 sents, 20242 tokens, 0.558% replaced (by <unk>)
[zh] Dictionary: 846872 types
[zh] ./data/split/train.zh: 389051 sents, 2011056 tokens, 0.0% replaced (by <unk>)
[zh] Dictionary: 846872 types
[zh] ./data/split/valid.zh: 3929 sents, 20342 tokens, 36.4% replaced (by <unk>)
[zh] Dictionary: 846872 types
[zh] ./data/split/test.zh: 1000 sents, 5903 tokens, 35.7% replaced (by <unk>)
天呐, 得到了 846904 个词单元? 点击 dict.en.txt 文件, 提示文件太大无法打开. 更令人震惊的是, {valid/test}.zh 文件中 35% 以上的 tokens 被 replaced (by <unk>).
怎么办? 问了 Kimi: fairseq_cli.preprocess 分词时如何设置词单元数量?
答:
--nwordssrc 10000 \
--nwordstgt 10000 \
好吧, 试试:
args.update({ # 设置参数
...
'nwordssrc': 10000,
'nwordstgt': 10000,
...
})
输出:
[en] Dictionary: 10000 types
[en] ./data/split/train.en: 389051 sents, 7972723 tokens, 4.82% replaced (by <unk>)
[en] Dictionary: 10000 types
[en] ./data/split/valid.en: 3929 sents, 80476 tokens, 5.01% replaced (by <unk>)
[en] Dictionary: 10000 types
[en] ./data/split/test.en: 1000 sents, 20242 tokens, 4.54% replaced (by <unk>)
[zh] Dictionary: 10000 types
[zh] ./data/split/train.zh: 389051 sents, 2011056 tokens, 39.4% replaced (by <unk>)
[zh] Dictionary: 10000 types
[zh] ./data/split/valid.zh: 3929 sents, 20342 tokens, 39.5% replaced (by <unk>)
[zh] Dictionary: 10000 types
[zh] ./data/split/test.zh: 1000 sents, 5903 tokens, 38.4% replaced (by <unk>)
(⊙o⊙)?更多的 tokens 被 replaced (by <unk>) 了. 打开 dict.en.txt 文件, 发现里面是比较符合逻辑的整个单词或汉语词语. 那应该是分词算法的问题, 样本量太小, 以至于学习到的 tokens 太少, 导致 {valid/test}.zh 文件中大量 tokens 被 replaced (by <unk>).[英语还好]. 于是想起来 sentencepiece 的分词适合东亚语言, 也适合英语, 它分词的结果是字母片段, 汉字短语.
问 Kimi: 能设置设置分词算法吗?
--tokenizer moses # 指定分词算法, 例如 moses, nltk, space 等
好吧, 试试:
args.update({ # 设置参数
...
'nwordssrc': 10000,
'nwordstgt': 10000,
'tokenizer': 'moses'
...
})
输出:
[en] Dictionary: 10000 types
[en] ./data/split/train.en: 389051 sents, 7972723 tokens, 4.82% replaced (by <unk>)
[en] Dictionary: 10000 types
[en] ./data/split/valid.en: 3929 sents, 80476 tokens, 5.01% replaced (by <unk>)
[en] Dictionary: 10000 types
[en] ./data/split/test.en: 1000 sents, 20242 tokens, 4.54% replaced (by <unk>)
[zh] Dictionary: 10000 types
[zh] ./data/split/train.zh: 389051 sents, 2011056 tokens, 39.4% replaced (by <unk>)
[zh] Dictionary: 10000 types
[zh] ./data/split/valid.zh: 3929 sents, 20342 tokens, 39.5% replaced (by <unk>)
[zh] Dictionary: 10000 types
[zh] ./data/split/test.zh: 1000 sents, 5903 tokens, 38.4% replaced (by <unk>)
很遗憾, 情况没有好转, 试试其他算法 nltk, space 也都没好转. 当使用 'tokenizer': 'sentencepiece' 时, 告诉我只支持 moses, nltk, space 三种分词工具. 汉语的话, 还是老老实实用 sentencepiece 吧.
3. 二进制文件的读取过程
首先看 .idx 文件的读取:
class Index:
def __init__(self, path):
with open(path, "rb") as stream:
magic_test = stream.read(9)
...
version = struct.unpack("<Q", stream.read(8))
...
(dtype_code,) = struct.unpack("<B", stream.read(1))
...
self._len = struct.unpack("<Q", stream.read(8))[0]
offset = stream.tell()
...
self._bin_buffer_mmap = np.memmap(path, mode="r", order="C")
self._bin_buffer = memoryview(self._bin_buffer_mmap)
self._sizes = np.frombuffer(
self._bin_buffer, dtype=np.int32, count=self._len, offset=offset
)
self._pointers = np.frombuffer(self._bin_buffer, dtype=np.int64, count=self._len, offset=offset + self._sizes.nbytes)
@lru_cache(maxsize=8)
def __getitem__(self, i):
return self._pointers[i], self._sizes[i]
首先以 'rb' 模式打开了 '.idx' 文件, 依次读取了 9, 8, 1, 8 个字节的内容, 分别是 magic_test 用于检查存储方式是否符合本类的读取方式; version 记录存储文件版本, dtype_code 是文件中数据的类型; self._len 是文件的数据长度. offset = stream.tell() 是数据开始的位置.
好! 在读取了文件的元信息之后, 后面的四行代码我们求助通义千问:
这段代码展示了如何使用 NumPy 的 memmap 功能结合 memoryview 和 NumPy 的数组操作, 高效地从磁盘上的二进制文件中读取和处理数据. 下面是对每一步的详细解释:
=== 创建内存映射 ===
self._bin_buffer_mmap = np.memmap(path, mode="r", order="C")
创建了一个内存映射文件 self._bin_buffer_mmap, 将磁盘上的二进制文件 path 映射到内存中, 允许像访问内存中的数组那样访问文件内容. mode="r" 表示只读模式, order="C" 指定数据的布局为 C 风格的行优先顺序.
=== 创建 memoryview ===
self._bin_buffer = memoryview(self._bin_buffer_mmap)
这一行创建了一个 memoryview 对象 self._bin_buffer, 它提供了对 self._bin_buffer_mmap 的低级内存视图, 允许对内存映射文件进行高效、低开销的切片操作, 且不会复制数据, 这对于处理大型数据集特别有用.
=== 从 buffer 中读取数据 ===
接下来的两行代码使用 np.frombuffer 方法从 self._bin_buffer 中读取数据:
self._sizes = np.frombuffer(
self._bin_buffer, dtype=np.int32, count=self._len, offset=offset
)
self._pointers = np.frombuffer(self._bin_buffer, dtype=np.int64, count=self._len, offset=offset + self._sizes.nbytes)
self._sizes 读取了数据集中每个样本的大小信息, 存储为 np.int32 类型的数组. count=self._len 表示读取 self._len 个这样的元素, offset=offset 指定从 self._bin_buffer 的哪个位置开始读取.
self._pointers 读取了指向每个样本起始位置的指针, 存储为 np.int64 类型的数组. 读取的起点是从 self._sizes 数组的末尾开始, 即 offset + self._sizes.nbytes.
根据上面通义千问的解释, 我们可以认为, self._pointers, self._sizes 分别是存储了数据位置和大小的两个 numpy 数组, 只不过它们是由内存映射实现的. 然后就可以 return self._pointers[i], self._sizes[i] 作为 __getitem__ 的结果了.