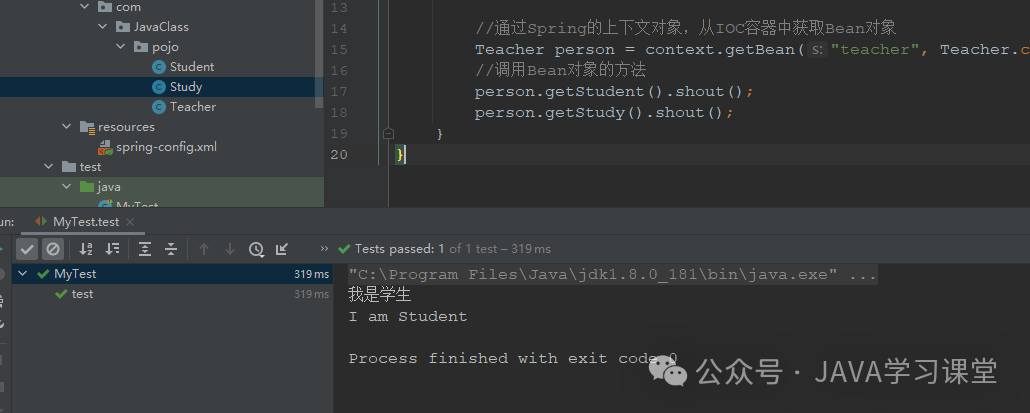
一、概念
1.概述
(1)数据本身不会产生价值 只有经过分析才有可能产生价值。
(2)Google的Dremel是第一个在嵌套数据模型基础上实现列存储的系统。
(3)列存储有其便利之处,因为在不同列中相同位置的数据必然属于原数据库中的同一行。
(4)Dremel和MapReduce并不是互相替代,而是相互补充的技术。在不同的应用场景下各有其用武之地。
2.用户希望提交完请求后,在一个相对可接受的合理时间内收到返回结果,mapreduce批处理效率太低。
MapReduce ←→ Hadoop
Dremel ←→ Apache Drill
3.两方面的技术支撑
(1)统一的存储平台实现高效的数据存储,Dremel使用的底层数据存 储平台是GFS
(2)统一的数据存储格式
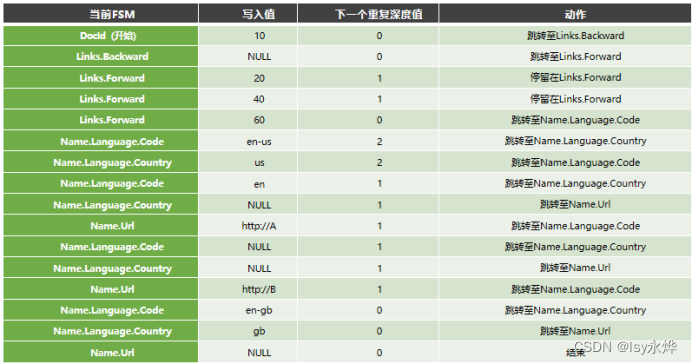
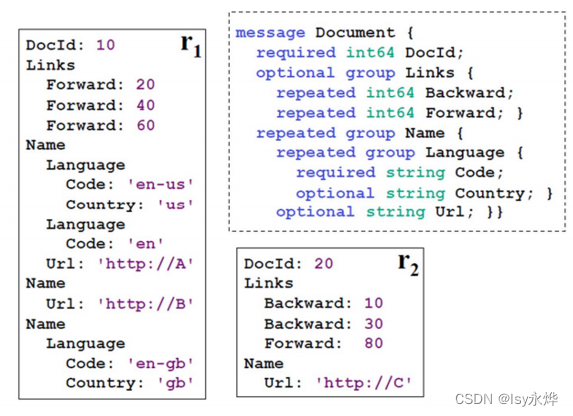
4.数据结构的无损表示(重点)
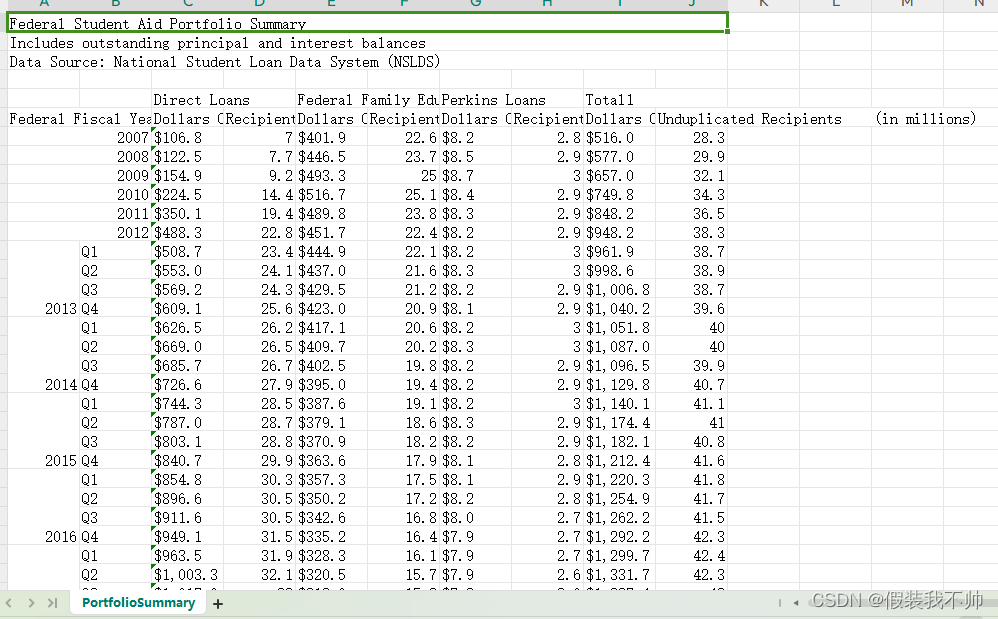
首先明确标题头,那个一定精确到最末项,如Name.Language.Code。这里成name是首项,后面依次是二项,三项,除此之外最后那个项称它叫末项。
还有就是空值也要进行判断r和d,值那一栏要写null。
(1)重复深度r:姑且可以称为第几次出现,但是只有在不同表的第一次出现该末项时是0,出现之后在该表,如果不是同一个项的下个项,例如Url,不是同一个name,这统一都是1,要明确这个不是出现了几次的意思,但是如language.code,同时出现在那么这个二项下,那第二个的code就要写2了,再次注意这个数字不是出现了几次,或者说第几个出现的意思,你可以把他当做一种极致简单的代指,说这是一条狗,那是一只猫这样的。
(2)定义深度d:如果只有一项,就是1。如果有两项,如name.url就是2,如果有三项,如name.language.country,就是3.但是
如果这只是最大值,如name.url,第一张表的第三个name,没有存在url项,则此时视作为1,此时可以认为只有name这一项。
同时为什么name.language.code不是3而是2,请注意右上角的代码上写的code和docid是required,即类似key值的意思。所以不计入。所以docid都是0,也就是可重复度为0。code同理。
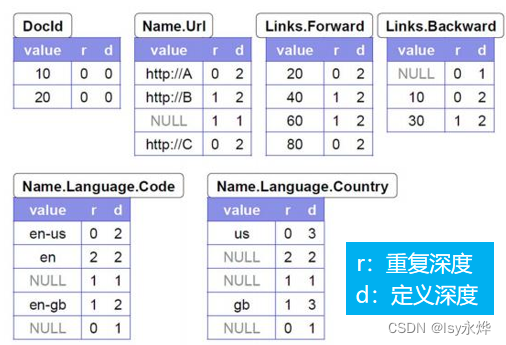
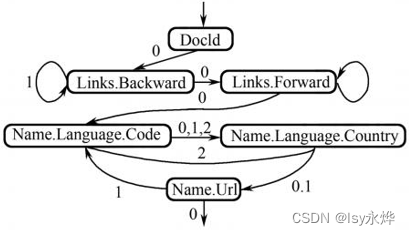
5.数据重组(重点)
(1)就是让上面的表2变成表1。
(2)核心思想是为每个字段创建一个有限状态机(FSM)。
(3)从一个方框到一个方框上的数是r,自循环上是d,
依次出现几个repeated就是几,例如name.url,虽然Name本身是,但是url只是个optional,所以自循环是0,不用写,但是links.backword,link是optional,但是backward这个末项是repeated,所以自循环是1,同理links.forward上应该也是1,但是没打印上。
这种一定要看清末项是不是repeated,不然容易乌龙。
(4)剩下的就是按下方图二中的顺序从上到下,画出图一中的线,写上数即可,像其中的0,1,2那里你画三条线才是最正确的,但是这里图省事画一起了。