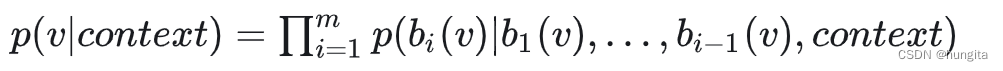前言
两种 Finetune 范式
增量预训练微调
使用场景:让基座模型学习到一些新知识,如某个垂类领域的常识 训练数据:文章、书籍、代码等
指令跟随微调
使用场景:让模型学会对话模板,根据人类指令进行对话 训练数据:高质量的对话、问答数据
不同数据集下使用微调
-
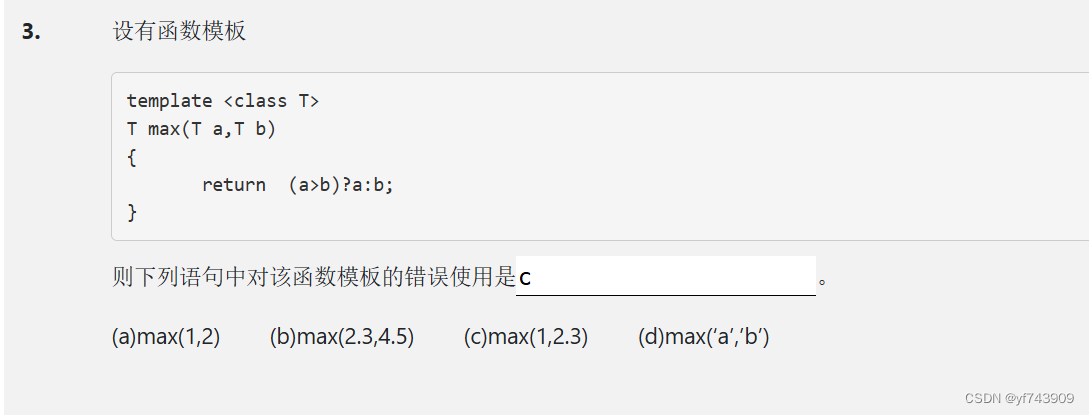
数据集1 - 数据量少,但数据相似度非常高在这种情况下,我们所做的只是修改最后几层或最终的softmax图层的输出类别。
-
数据集2 - 数据量少,数据相似度低在这种情况下,我们可以冻结预训练模型的初始层(比如k层),并再次训练剩余的(n-k)层。由于新数据集的相似度较低,因此根据新数据集对较高层进行重新训练具有重要意义。
-
数据集3 - 数据量大,数据相似度低在这种情况下,由于我们有一个大的数据集,我们的神经网络训练将会很有效。但是,由于我们的数据与用于训练我们的预训练模型的数据相比有很大不同。使用预训练模型进行的预测不会有效。因此,最好根据你的数据从头开始训练神经网络(Training from scatch)。
-
数据集4 - 数据量大,数据相似度高这是理想情况。在这种情况下,预训练模型应该是最有效的。使用模型的最好方法是保留模型的体系结构和模型的初始权重。然后,我们可以使用在预先训练的模型中的权重来重新训练该模型。
微调指导事项
使用较小的学习率来训练网络。由于我们预计预先训练的权重相对于随机初始化的权重已经相当不错,我们不想过快地扭曲它们太多。通常的做法是使初始学习率比用于从头开始训练(Training from scratch)的初始学习率小10倍。
其他方案
Adapt Tuning
每个 Adapter 模块由两个前馈子层组成,第一个前馈子层将 Transformer 块的输出作为输入,将原始输入维度 d 投影到 m,通过控制 m 的大小来限制 Adapter 模块的参数量,通常情况下 m << d。在输出阶段,通过第二个前馈子层还原输入维度,将 m 重新投影到 d,作为 Adapter 模块的输出
Prefix Tuning
在每一个输入 token 前构造一段与下游任务相关的 virtual tokens 作为 prefix,在微调时只更新 prefix 部分的参数,而其他参数冻结不变
模型可用序列长度减少。由于加入了 virtual tokens,占用了可用序列长度,因此越高的微调质量,模型可用序列长度就越低。
LoRa
思想
大模型是将数据映射到高维空间进行处理,对下游子任务可能只需要在某个子空间范围内就可以解决。这个子空间参数矩阵的秩就可以称为对应当前待解决问题的本征秩(intrinsic rank)
我们可以通过优化密集层在适应过程中变化的秩分解矩阵来间接训练神经网络中的一些密集层,从而实现仅优化密集层的秩分解矩阵来达到微调效果
原理
使用低秩分解来表示预训练的权重参数矩阵更新
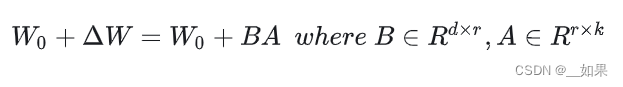
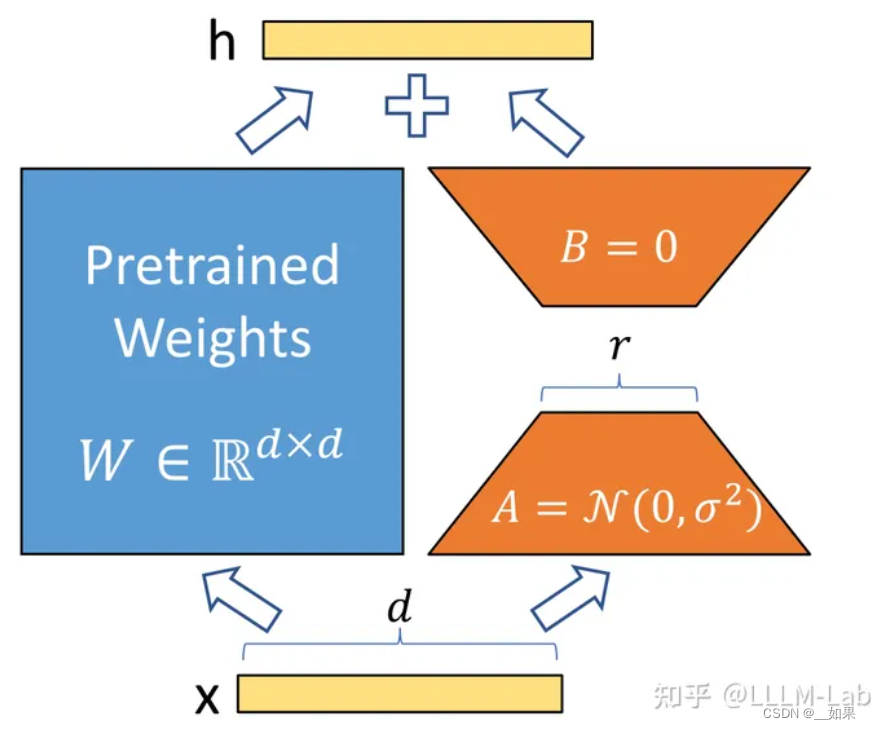
在训练过程中,W0冻结不更新,A、B 包含可训练参数
在开始训练时,对 A 使用随机高斯初始化,对 B 使用零初始化,然后使用 Adam 进行优化
在 Transformer 结构中,LoRA 技术主要应用在注意力模块的四个权重矩阵: 𝑊𝑞 、 𝑊𝑘 、 𝑊𝑣 、 𝑊0 ,而冻结 MLP 的权重矩阵
通过消融实验发现同时调整 𝑊𝑞 和 𝑊𝑣 会产生最佳结果
在上述条件下,可训练参数个数为:
Θ=2×𝐿𝐿𝑜𝑅𝐴×𝑑𝑚𝑜𝑑𝑒𝑙×𝑟
其中, 𝐿𝐿𝑜𝑅𝐴 为应用 LoRA 的权重矩阵的个数, 𝑑𝑚𝑜𝑑𝑒𝑙 为 Transformer 的输入输出维度,r 为设定的 LoRA 秩。
一般情况下,r 取到 4、8、16。
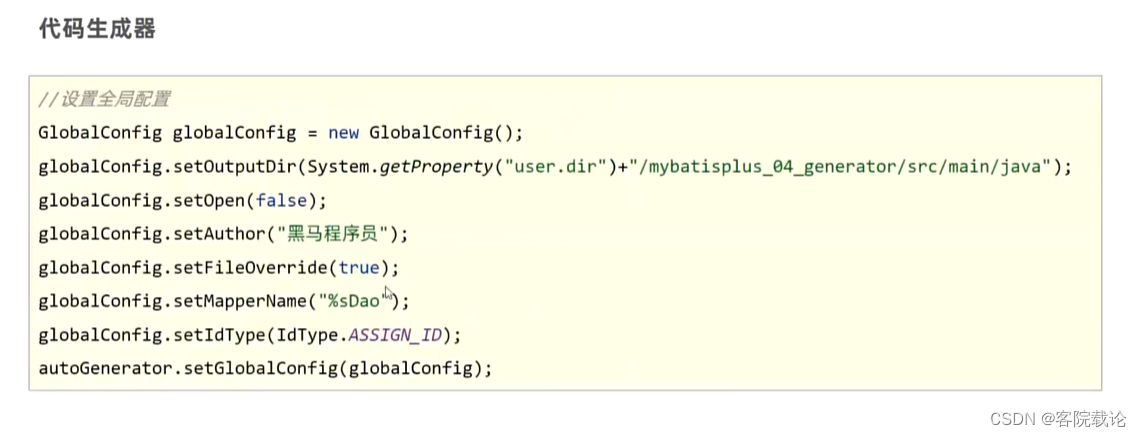
代码
pass