"""可持续加速深层网络的收敛速度"""
import torch
from torch import nn
import liliPytorch as lp
import matplotlib. pyplot as plt
def batch_norm ( X, gamma, beta, moving_mean, moving_var, eps, momentum) :
"""实现一个具有张量的批量规范化层。"""
if not torch. is_grad_enabled( ) :
X_hat = ( X - moving_mean) / torch. sqrt( moving_var + eps)
else :
assert len ( X. shape) in ( 2 , 4 )
if len ( X. shape) == 2 :
mean = X. mean( dim= 0 )
var = ( ( X - mean) ** 2 ) . mean( dim= 0 )
else :
mean = X. mean( dim= ( 0 , 2 , 3 ) , keepdim= True )
var = ( ( X - mean) ** 2 ) . mean( dim= ( 0 , 2 , 3 ) , keepdim= True )
X_hat = ( X - mean) / torch. sqrt( var + eps)
moving_mean = momentum * moving_mean + ( 1.0 - momentum) * mean
moving_var = momentum * moving_var + ( 1.0 - momentum) * var
Y = gamma * X_hat + beta
return Y, moving_mean. data, moving_var. data
class BatchNorm ( nn. Module) :
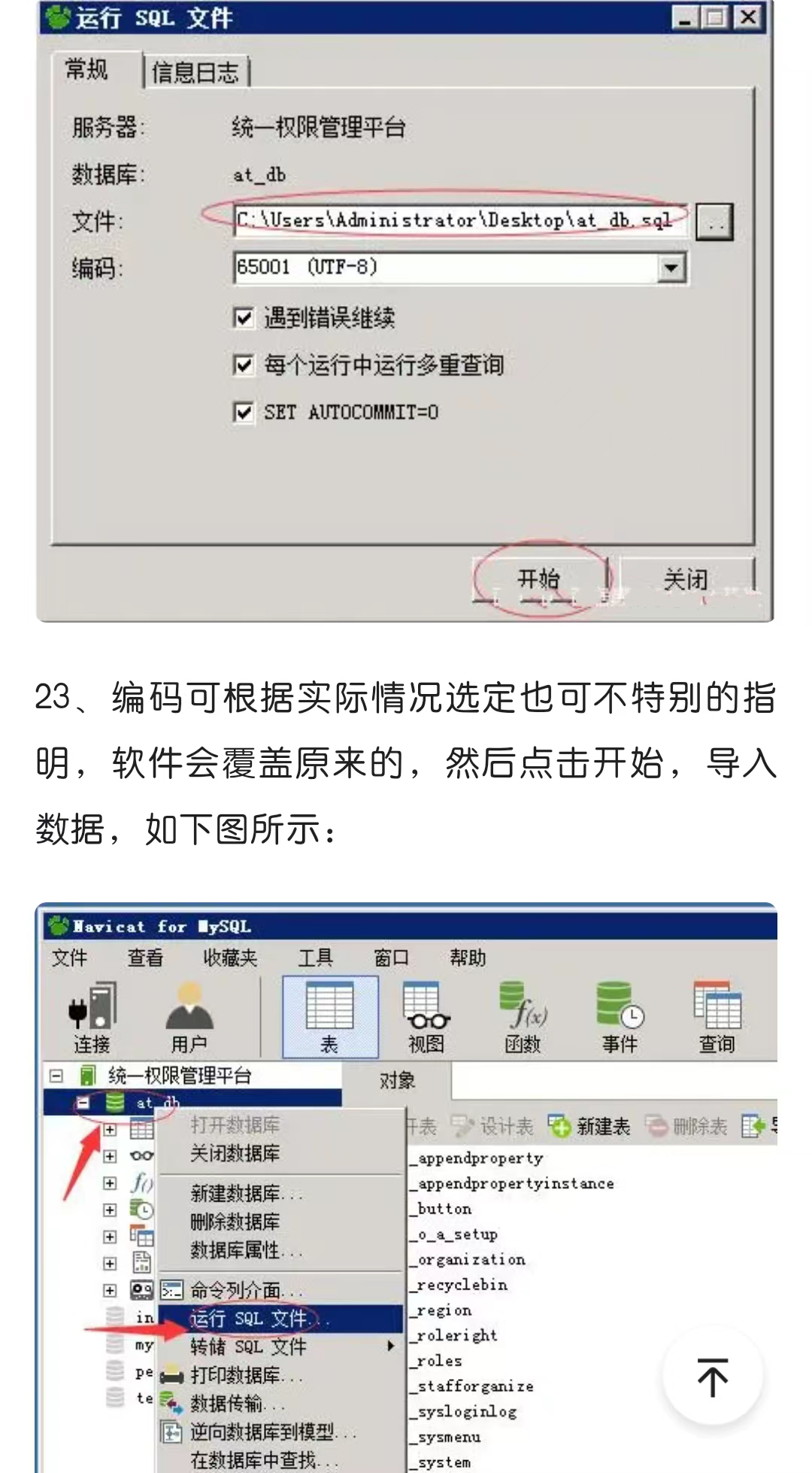
def __init__ ( self, num_features, num_dims) :
super ( ) . __init__( )
if num_dims == 2 :
shape = ( 1 , num_features)
else :
shape = ( 1 , num_features, 1 , 1 )
self. gamma = nn. Parameter( torch. ones( shape) )
self. beta = nn. Parameter( torch. zeros( shape) )
self. moving_mean = torch. zeros( shape)
self. moving_var = torch. ones( shape)
def forward ( self, X) :
if self. moving_mean. device != X. device:
self. moving_mean = self. moving_mean. to( X. device)
self. moving_var = self. moving_var. to( X. device)
Y, self. moving_mean, self. moving_var = batch_norm(
X, self. gamma, self. beta, self. moving_mean,
self. moving_var, eps= 1e-5 , momentum= 0.9 )
return Y
net = nn. Sequential(
nn. Conv2d( 1 , 6 , kernel_size= 5 , padding= 2 ) ,
BatchNorm( num_features= 6 , num_dims= 4 ) ,
nn. ReLU( ) ,
nn. AvgPool2d( kernel_size= 2 , stride= 2 ) ,
nn. Conv2d( 6 , 16 , kernel_size= 5 ) ,
BatchNorm( num_features= 16 , num_dims= 4 ) ,
nn. ReLU( ) ,
nn. AvgPool2d( kernel_size= 2 , stride= 2 ) ,
nn. Flatten( ) ,
nn. Linear( 16 * 5 * 5 , 120 ) ,
BatchNorm( num_features= 120 , num_dims= 2 ) ,
nn. ReLU( ) ,
nn. Linear( 120 , 84 ) ,
BatchNorm( num_features= 84 , num_dims= 2 ) ,
nn. ReLU( ) ,
nn. Linear( 84 , 10 )
)
lr, num_epochs, batch_size = 1.0 , 10 , 256
train_iter, test_iter = lp. loda_data_fashion_mnist( batch_size)
net = nn. Sequential(
nn. Conv2d( 1 , 6 , kernel_size= 5 ) , nn. BatchNorm2d( 6 ) , nn. ReLU( ) ,
nn. AvgPool2d( kernel_size= 2 , stride= 2 ) ,
nn. Conv2d( 6 , 16 , kernel_size= 5 ) , nn. BatchNorm2d( 16 ) , nn. ReLU( ) ,
nn. AvgPool2d( kernel_size= 2 , stride= 2 ) , nn. Flatten( ) ,
nn. Linear( 256 , 120 ) , nn. BatchNorm1d( 120 ) , nn. ReLU( ) ,
nn. Linear( 120 , 84 ) , nn. BatchNorm1d( 84 ) , nn. ReLU( ) ,
nn. Linear( 84 , 10 )
)
lp. train_ch6( net, train_iter, test_iter, num_epochs, lr, lp. try_gpu( ) )
plt. show( )
"""
通常高级API变体运行速度快得多,因为它的代码已编译为C++或CUDA,而我们的自定义代码由Python实现。
"""