📜文献卡
| 题目: Depth Anything V2 |
|---|
| 作者: Lihe Yang; Bingyi Kang; Zilong Huang; Zhen Zhao; Xiaogang Xu; Jiashi Feng; Hengshuang Zhao |
| DOI: 10.48550/arXiv.2406.09414 |
| 摘要: This work presents Depth Anything V2. Without pursuing fancy techniques, we aim to reveal crucial findings to pave the way towards building a powerful monocular depth estimation model. Notably, compared with V1, this version produces much finer and more robust depth predictions through three key practices: 1) replacing all labeled real images with synthetic images, 2) scaling up the capacity of our teacher model, and 3) teaching student models via the bridge of large-scale pseudo-labeled real images. Compared with the latest models built on Stable Diffusion, our models are significantly more efficient (more than 10x faster) and more accurate. We offer models of different scales (ranging from 25M to 1.3B params) to support extensive scenarios. Benefiting from their strong generalization capability, we fine-tune them with metric depth labels to obtain our metric depth models. In addition to our models, considering the limited diversity and frequent noise in current test sets, we construct a versatile evaluation benchmark with precise annotations and diverse scenes to facilitate future research. |
| GitHub: DepthAnything/Depth-Anything-V2: Depth Anything V2. A More Capable Foundation Model for Monocular Depth Estimation (github.com) |

⚙️ 内容
实现了一种名为“深度任意物V2”的单目深度估计算法,旨在通过三个关键实践:使用合成图像代替真实标记图、增加教师模型容量以及通过大规模伪标记的真实图像教授学生模型等方法,提高深度预测精度和鲁棒性。与基于Stable Diffusion的最新模型相比,该算法更加高效(比其快10倍以上)且准确度更高。作者提供了不同规模(从25M到1.3B参数)的模型以支持各种场景,并利用它们的强大泛化能力,在带有深度标签的数据集上进行微调,从而获得我们的深度测量模型。此外,考虑到当前测试数据集的有限多样性和频繁噪声,作者还构建了一个具有精确注释和多样化场景的灵活评估基准,以促进未来的研究。

模型优点:
- 高效性:更快的推理速度
- 精度:更高的深度精度
- 轻量级模型:参数少(从25M到1.3B)
💡 创新点
-
数据驱动的深度学习优化:通过全面采用高质量合成图像作为训练数据源,克服了真实图像标签噪声的问题。
-
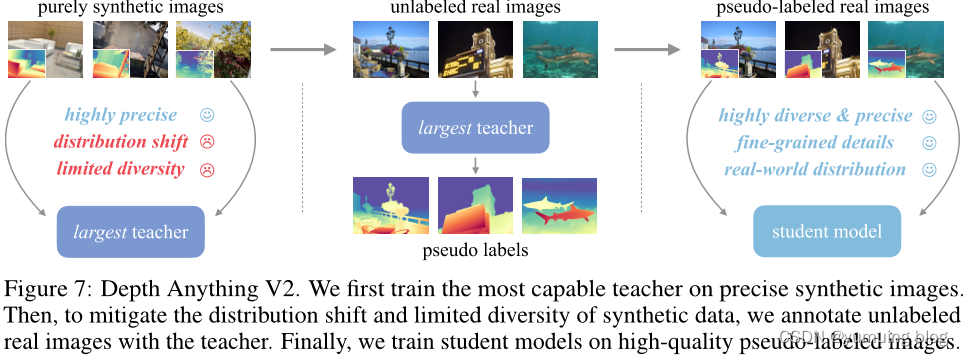
模型架构与训练策略:引入了教师-学生模型框架,其中大型教师模型先在合成数据上训练,然后生成伪标签用于训练小型学生模型,有效转移知识并提升模型的泛化性能。
-
深度预测的精度与多样性:无需依赖复杂技术,仅通过数据和模型结构的优化,显著提升了深度预测的准确度,尤其是在透明表面等挑战性对象上的表现。
-
多功能评估基准:构建了新的测试基准,以促进未来单目深度估计研究的发展。
🧩 不足
- 合成数据的局限性:尽管合成图像在提供精确标签方面有优势,但它们缺乏真实世界的多样性和复杂性,即存在合成图像与真实图像之间存在分布漂移问题和合成图像的场景覆盖不足问题,可能导致模型在某些特定或罕见场景下的表现不佳。
- 深度预测的泛化能力:虽然模型在训练数据集上表现优异,但在未见过的极端或新奇环境下可能仍面临挑战。
- 特殊场景表现不佳:透明对象和反射表面处理不佳
🔁 实验卡
💧 数据
- 来源与预处理:研究使用了五个精确的合成数据集(含595K张图像)和八个大型的伪标签真实数据集(共62M张图像)。合成数据集如Hypersim和vKITTI提供了高精度的深度标签,而真实图像则用于生成大规模的伪标签。
- 忽略噪声区域:在训练过程中,对于每个伪标签样本,会忽略其损失最大的前10%区域,视为潜在的噪声标签。
方法改进
与V1相比,该方法采用了更精确的合成数据集和更大的伪标签真实数据集,从而提高了模型的精度和泛化能力。此外,该方法还加入了梯度匹配损失Lgm,可以提高深度的锐度。
👩🏻💻 方法
- 教师模型训练:基于DINOv2-G的教师模型在高质合成图像上进行训练。
- 深度标签生成:教师模型在大规模未标记的真实图像上产生精确的伪深度。
- 学生模型训练:使用伪标签真实图像训练最终的学生模型以实现稳健的一般化(即合成图像在此步骤中不再需要),以增强模型的鲁棒性和泛化能力。
🔬 实验
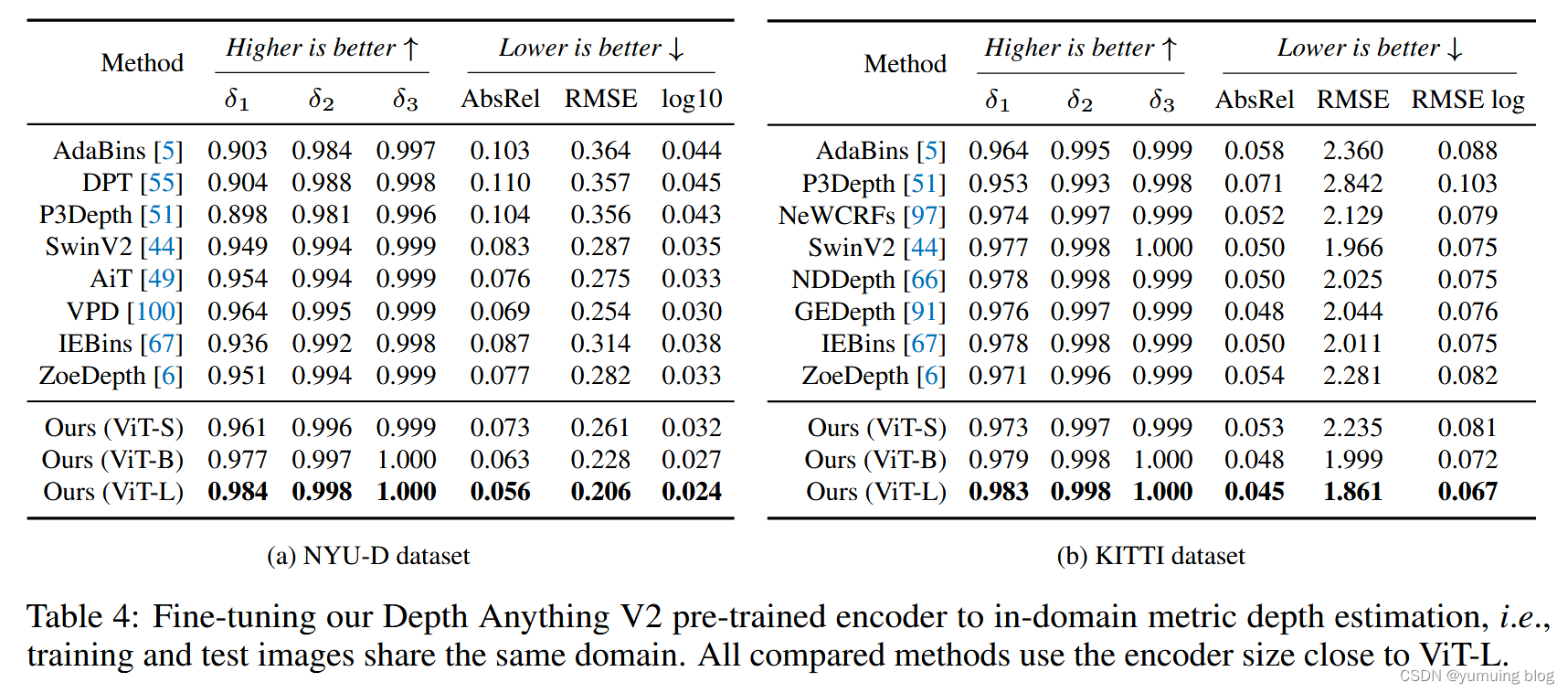
实验验证:通过与V1、Marigold等模型的对比,展示了Depth Anything V2在精度、速度和参数量方面的优势。特别是在透明表面挑战中的零样本测试中,V2取得了83.6%的高分,远超MiDaS的25.9%和V1的53.5%。

📜 结论
Depth Anything V2在不牺牲速度和效率的情况下,显著提高了深度预测的精度和细节质量,证明了其在单目深度估计领域的先进性。
🤔 总结卡
研究团队成功地揭示了数据质量和多样性对于提升单目深度估计模型性能的关键作用,特别是通过创新地结合高质量合成数据与大规模无标签真实数据的伪标签策略。然而,未来工作可以探索如何进一步增强模型对真实世界复杂性和多样性场景的理解,比如通过更先进的合成数据生成技术或者在模型设计中融入更多自适应机制来应对未知环境的挑战。同时,持续优化评估基准以更全面地反映模型在实际应用中的表现也是必要的。
文章特别点
- 提出了DA-2K(Diverse Applications Dataset for Monocular Depth Estimation),一个更加多样化且高分辨率的基准数据集,用于评估相对单目深度估计模型。
- 使用稀疏深度标签而非密集像素级深度标签来构建基准数据集,提高了效率并减少了人工标注的工作量。
- 通过两个不同的管道选择像素对,并引入了挑战性的图像手动识别过程,确保了数据集的多样性和精确性。
- 实验结果表明,该基准数据集能够覆盖广泛的场景,并提供更高质量的数据以支持各种应用。
方法创新点
- 利用自动预测对象掩模的方法(SAM)和关键点来选取稀疏深度标签,提高数据集的多样性。
- 通过与人类注释者一起检查每个注释,确保了数据集的准确性。
- 通过使用深度学习技术,将编码器预训练在大型合成数据集上,然后将其转移到下游任务中,实现了良好的泛化能力。
未来展望
- 进一步扩大DA-2K数据集的规模,以更好地满足实际应用场景的需求。
- 研究如何处理透明物体等复杂情况下的深度估计算法,提高模型的鲁棒性和精度。
- 探索如何利用多模式信息(如RGB、红外线、激光雷达等)来进一步提升深度估计算法的效果。