(2024)豆瓣电影详情页内容爬虫详解和源码
这是一个Python爬虫程序,用于抓取豆瓣电影详情页面如
https://movie.douban.com/subject/1291560/的数据。它首先发送GET请求,使用PyQuery解析DOM,然后根据<br>标签分割HTML内容,提取电影信息如导演、演员、类型等,并将中文键转换为英文键存储在字典中。完整代码包括请求、解析、数据处理和测试部分。当运行时,会打印出电影详情,如导演、演员列表、类型、时长等。
爬虫目的
获取 https://movie.douban.com/subject/1291560/ 电影详情的所有电影的属性。
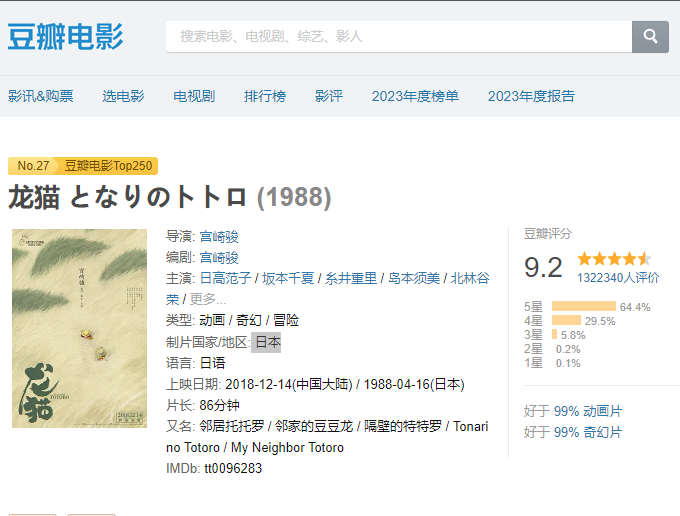
爬虫思路
- 第一步,请求详情页面拿到响应
- 第二步, 根据响应 + pyquery 解析dom拿到对应节点文本
- 第三步,处理文本为想要的数据形式。
函数:getMovieInfoByUrl
分析dom
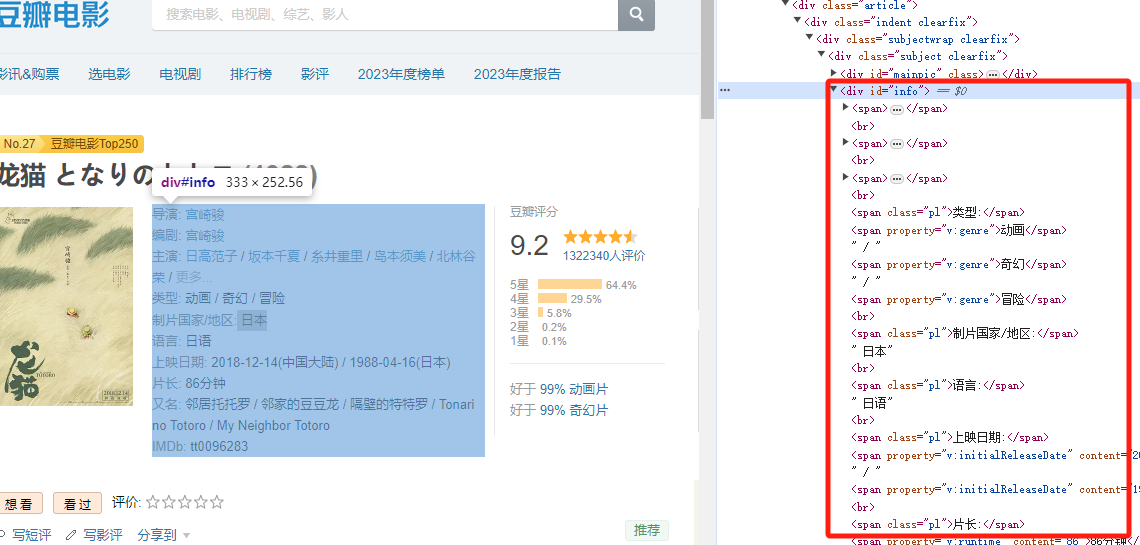
OK,经过分析,我们找到了,使用jquery 获取电影信息dom的方式,但是没什么清晰的规律。所以需要特殊处理
- 第一步:获取电影info的HTML
info_items_doc = doc("#content #info")
info_items_html_content = info_items_doc.html()
- 第二步:根据br 标签划分为多个HTML片段,然后组成新的dom节点,再获取其文本,最后通过正则对文本处理,提取数据。
# 根据<br>标签划分内容
content_list = re.split(r'<br/>', info_items_html_content)
extracted_info = {}
# 定义正则表达式模式
regex_pattern = re.compile(r'(.*?):\s(.*?)(?:\n|$)')
# 输出划分后的内容
for content in content_list:
info_item_doc = pq(f'<div>{content}<div>')
info_item_text = info_item_doc.text()
match = regex_pattern.match(info_item_text)
if match:
extracted_info[match.group(1)] = match.group(2)
print("extracted_info",extracted_info)
输出
extracted_info {'导演': '宫崎骏', '编剧': '宫崎骏', '主演': '日高范子 / 坂本千夏 / 糸井重里 / 岛本须美 / 北林谷荣 / 高木均 / 雨笠利幸 / 丸山裕子 / 广濑正志 / 鹫尾真知子 / 铃木玲子 / 千叶繁 / 龙田直树 / 鳕子 / 西村朋纮 / 石田光子 / 神代知衣 / 中村大树 / 水谷优子 / 平松晶子 / 大谷育江', '类型': '动画 / 奇幻 / 冒险', '制片国家/地区': '日本', '语言': '日语', '上映日期': '2018-12-14(中国大陆) / 1988-04-16(日本)', '片长': '86分钟', '又名': '邻居托托罗 / 邻家的豆豆龙 / 隔壁的特特罗 / Tonari no Totoro / My Neighbor Totoro', 'IMDb': 'tt0096283'}
完整代码
# 豆瓣电影详情也爬数据
# https://movie.douban.com/subject/1291560/
import requests
from pyquery import PyQuery as pq
import re
from pprint import pprint
# 第一步,请求详情页面拿到响应
# 第二步, 根据响应 + pyquery 解析dom拿到对应节点文本
# 第三步,处理文本为想要的数据形式。
def getMovieInfoByUrl(detailUrl):
movieInfo = {}
# 定义请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
# 其他需要的请求头...
}
# 发送 GET 请求并获取响应内容
response = requests.get(detailUrl, headers=headers)
# 确保请求成功
if response.status_code == 200:
doc = pq(response.text)
movieInfo['release_year'] = re.findall(r'\d+', doc("#content h1 .year").text())[0]
#======处理 info 标签信息
info_items_doc = doc("#content #info")
info_items_html_content = info_items_doc.html()
# 根据<br>标签划分内容
content_list = re.split(r'<br/>', info_items_html_content)
extracted_info = {}
# 定义正则表达式模式
regex_pattern = re.compile(r'(.*?):\s(.*?)(?:\n|$)')
# 输出划分后的内容
for content in content_list:
info_item_doc = pq(f'<div>{content}<div>')
info_item_text = info_item_doc.text()
match = regex_pattern.match(info_item_text)
if match:
extracted_info[match.group(1)] = match.group(2)
print("extracted_info",extracted_info)
# 映射中文键到英文键
key_mapping = {
'主演': 'leading_actor',
'制片国家/地区': 'release_region',
'导演': 'director',
'片长': 'duration',
'类型': 'genre',
}
for key,value in extracted_info.items():
if key in key_mapping:
movieInfo[key_mapping[key]] = value
movieInfo['duration'] = int(movieInfo['duration'].split('分钟')[0])
#======处理 info 标签信息
pprint(movieInfo)
else:
# 我的联系方式:wx: Wusp1994 企鹅号: 812190146
print(f"请求失败,状态码:{response.status_code}")
return movieInfo
测试代码
if __name__ == "__main__":
call_me = "卫星:Wusp1994 企鹅: 812190146"
movie_url = 'https://movie.douban.com/subject/1291560/'
getMovieInfoByUrl(movie_url)
输出结果
最后得到电影信息的字典,如果有缺失信息,可以联系我交流。