【Apache Doris】如何实现高并发点查?(原理+实践全析)
- 一、背景说明
- 二、原理介绍
- 三、环境信息
- 四、Jmeter初始化
- 五、参数预调
- 六、用例准备
- 七、高并发实测
- 八、影响因素
- 九、总结
本文主要分享 Apache Doris 是如何实现高并发点查的,以及如何实测单节点上万QPS。
一、背景说明
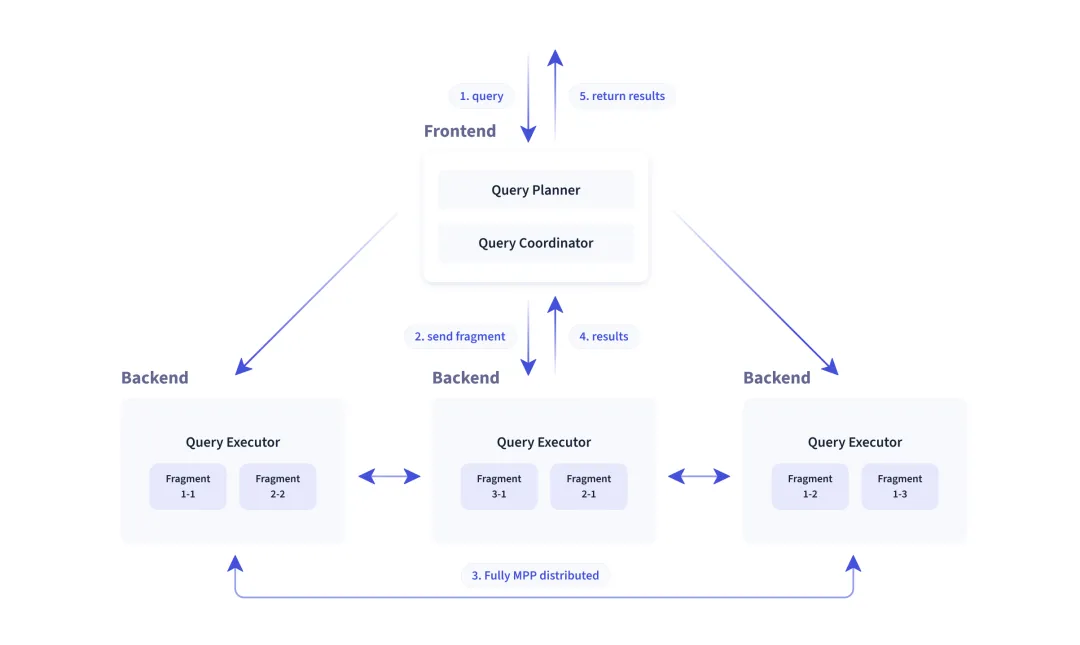
Apache Doris 是一款基于 MPP 架构的高性能、实时的分析型数据库。它可以在多个节点上并行处理查询,显著提高查询效率,且默认以列存格式引擎构建。这种格式非常适合进行数据分析,因为它可以有效地压缩数据,并且在执行查询时只需要读取相关的列。但有些高并发服务场景中,用户需要频繁获取整行数据,如果表较宽时,列存的IO也随之被放大。
Apache Doris 中 FE 是 SQL 查询的访问层服务,使用 Java 编写,分析和解析 SQL 也会导致高并发查询的高 CPU 开销,且其查询引擎和计划对于某些简单的查询(例如点查询)而言太重了。
那么,Apache Doris 是如何实现高并发查询以及如何实现高并发点查的呢?
二、原理介绍
Apache Doris 能够实现高并发查询的能力主要是通过以下几个方面:
- MPP架构
基于大规模并行处理(Massively Parallel Processing, MPP)架构设计,它可以将查询分解为多个任务,在多个节点上并行执行这些任务,使得系统可以通过增加更多的计算资源来线性扩展其查询处理能力。
- 列式存储
使用列式存储格式,这意味着对于任何给定的查询,它只需要读取涉及到的列,而不是整行数据。这减少了磁盘I/O压力,因为只有必需的数据被加载到内存中。
- 数据分片
分区和分桶裁剪在 Apache Doris 中也是实现高并发查询的重要机制。这两种技术可以帮助更有效地组织数据,提高查询效率,尤其是在面对大规模数据集时。
- 向量化查询执行
Apache Doris 实现了向量化查询处理,这意味着在执行操作时,它可以一次处理数据列的一整块,而不是逐行处理。这样可以大大提高CPU的利用率,降低每个数据点的处理开销。
- 索引和物化视图
Apache Doris 支持创建索引和物化视图来加速查询,减少扫描行数和避免了大量的现场计算,例如倒排、ZoneMap、Bloom Filter和Bitmap 等索引和预计算物化。
- 统计信息和成本基准优化
Apache Doris 会收集表和列的统计信息,并使用这些信息来优化查询计划,选择最佳的执行路径。
… 此处省略上万字
基于【背景说明】和上述内容,Apache Doris 可实现单节点上千 QPS 的并发支持。但在一些超高并发要求(例如上万 QPS)的 Data Serving 场景中,仍然存在瓶颈。
因此,Apache Doris 引入了如下几个2.0新特性 从降低 SQL 内存 IO 开销、提升点查执行效率以及降低 SQL 解析开销这三个设计点出发,进行一系列优化:
- 行式存储格式(Row Store Format)
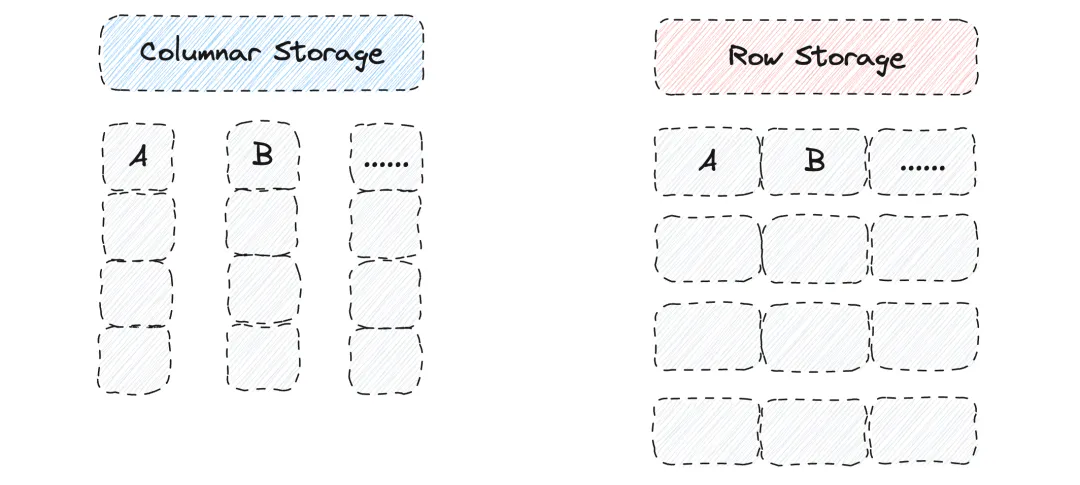
Apache Doris 支持用户在建表时,通过 store_row_column 表属性另存一份行数据(列存+行存)。在单次检索整行数据时效率更高,减少磁盘访问次数 。
- 行存缓存(Row Cache)
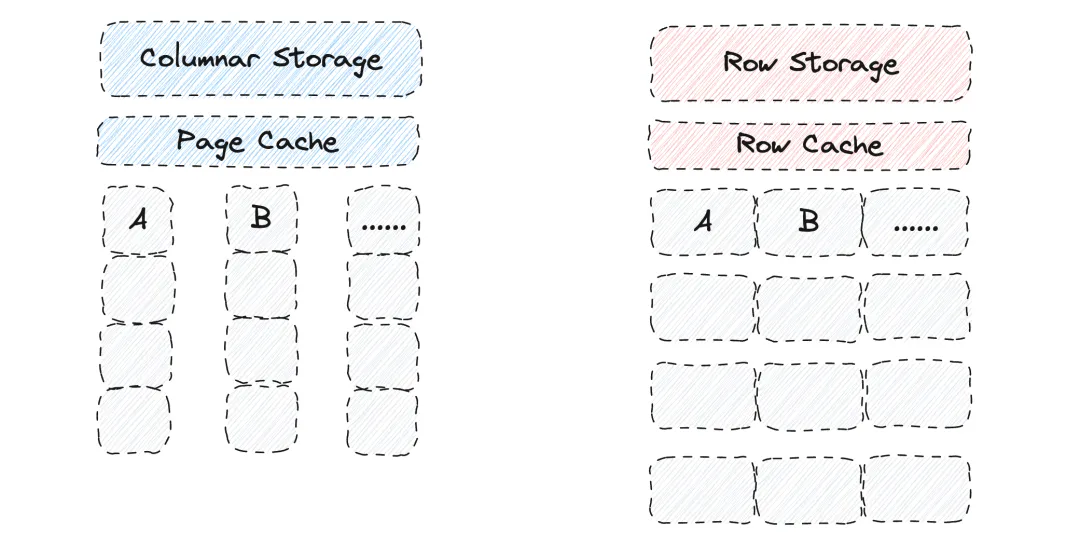
Apache Doris 有针对列数据的Page Cache。但如果一行包括多列数据,这类缓存可能会被大查询给刷掉,为了增加缓存命中率、提升点查询的性能,Apache Doris 引入了行存缓存(Row Cache)。
- 点查询短路径优化(Short-Circuit)
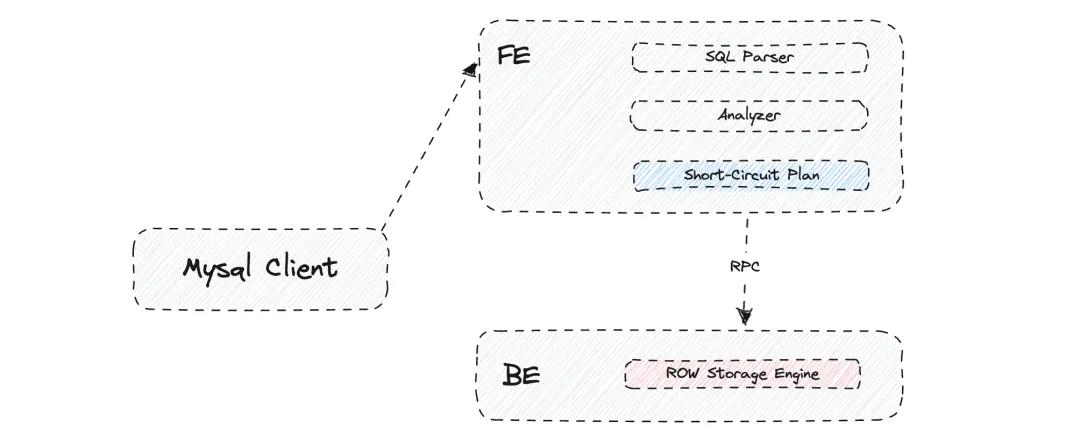
通常而言,一个查询会在 FE 端进行SQL语句解析、生成执行计划后下发到 BE 进行计算获取结果。但对于高并发点查场景,则不适合这个长流程。
因此,Apache Doris 实现了点查询的短路径优化。当FE接收到此类查询时,会在规划器中生成轻量级的 Short-Circuit Plan,避免生成复杂的 Fragment Plan 并消除了在 MPP 查询框架下执行调度的性能开销。
- 预处理语句优化(Prepared Statement)
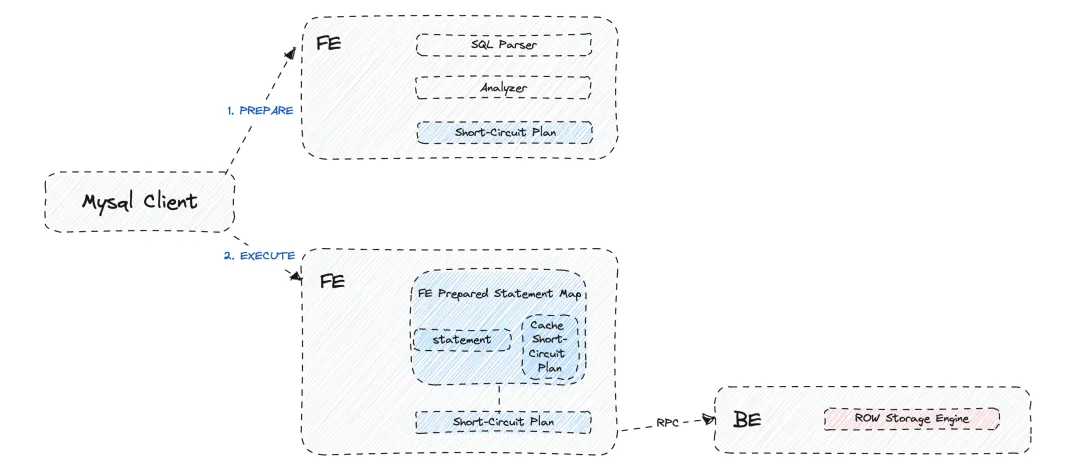
高并发查询中的 CPU 开销可以部分归因于 FE 层分析和解析 SQL 的 CPU 计算,为了解决这个问题,Apache Doris 在 FE 端提供了与 MySQL 协议完全兼容的预处理语句(Prepared Statement)。
通过在 Session 内存 HashMap 中缓存预先计算好的 SQL 和表达式,在后续查询时直接复用缓存对象,避免这些结构在序列化和反序列化时造成CPU热点。
基于以上一系列优化,帮助 Apache Doris 在 Data Serving 场景的性能得到进一步提升。下面就来实测一把吧。
三、环境信息
- 硬件信息
- 内存:32G
- CPU:16C
- CPU架构:X86_64
- 硬盘:SSD单盘
- 节点数:1
- 软件信息
- Doris版本:2.0.3
- Manager版本:23.10.3
- Jmeter版本:5.6
- JDK版本:1.8
- Mysql Driver版本:8.0
- 系统:CentOS
四、Jmeter初始化
本文基于Jmeter进行高并发实测。
- 安装部署
非GUI使用模式。
# 官方下载包
wget https://dlcdn.apache.org/jmeter/binaries/apache-jmeter-5.6.tgz
# 解压包 tar -zvf apache-jmeter-5.6.tgz
# 解压后目录结构和本地UI模式一

上传mysql-connector包到lib目录下。
- 参数说明
命令模版和参数说明,详情可阅:
https://jmeter.apache.org/usermanual/get-started.html#non_gui
jmeter -n -t <脚本文件名>.jmx -l <本不存在的结果文件名>.jtl -e -o <存放html报告的空目录>
-h 帮助
-n 非GUI模式
-t 测试脚本.jmx的路径和文件名称
-l 测试结果存放的路径和文件名称 (要确保之前没有运行过,即xxx.jtl不存在,不然报错),会自动创建
-r 启动jmeter.properties文件中指定的所有远程服务器
-e 在脚本运行结束后生成html报告
-o 用于存放html报告的目录(目录要为空,不然报错),会自动创建
五、参数预调
- fe.conf
-- 每个 FE 的最大连接数,默认值:1024
qe_max_connection=10240
- be.conf
为了增加行缓存命中率,Doris单独引入了行存缓存;行缓存复用了 Doris 中的 LRU Cache 机制来保障内存的使用。
-- 是否开启行缓存, 默认不开启
disable_storage_row_cache=false
-- 指定 Row cache 占用内存的百分比, 默认 20% 内存
row_cache_mem_limit=40%
- 表属性
建表时调整即可。
-- 必须为Unique Key表
-- 开启行存
"store_row_column" = "true"
-- 开启mow模式
"enable_unique_key_merge_on_write" = "true"
-- 开启light
schema change: "light_schema_change" = "true"
- 会话参数
-- 查看新优化器是否开启
show variables like '%enable_nereids_planner%';
-- 非必选,jdbc链接配置 useServerPrepStmts=true时,会自动走短路径优化、即不走旧优化器
-- 如:jdbc:mysql://127.0.0.1:9030/ycsb?useServerPrepStmts=true
set global experimental_enable_nereids_planner=false;
- 用户参数
-- 查看用户连接数
SHOW PROPERTY FOR 'root' LIKE '%max_user_connections%';
-- 设置连接数
SET PROPERTY FOR 'root' 'max_user_connections' = '10000';
六、用例准备
- 测试表创建
基于Star Schema Benchmark的part零件信息表调整创建,共9个字段、2个联合Key。
CREATE TABLE `row_part` (
`p_partkey` int(11) NULL,
`p_name` varchar(69) NULL,
`p_mfgr` varchar(21) NULL,
`p_category` varchar(24) NULL,
`p_brand` varchar(30) NULL,
`p_color` varchar(36) NULL,
`p_type` varchar(78) NULL,
`p_size` int(11) NULL,
`p_container` varchar(33) NULL
) ENGINE=OLAP
Unique KEY(`p_partkey`, `p_name`)
COMMENT 'OLAP'
DISTRIBUTED BY HASH(`p_partkey`, `p_name`) BUCKETS 10
PROPERTIES (
"replication_allocation" = "tag.location.default: 1",
"light_schema_change" = "true",
"store_row_column" = "true" ,
"enable_unique_key_merge_on_write" = "true"
);
- 测试表数据生成
测试表最终为3200万数据。
-- 源表为明细模型,目标表为开启了行存、mow和light_schema_change的unique模式表
-- 通过对字段+数字等方式去重快速造数
insert into row_part -- 目标测试表
select
`p_partkey`+1,
concat(`p_name`, '1'),
`p_mfgr` ,
`p_category`,
`p_brand`,
`p_color`,
`p_type`L,
`p_size`,
`p_container`
from part; -- 源表
- 测试SQL
测试SQL如下。
select * from ssb_test.row_part
where p_partkey = ? and p_name = ?
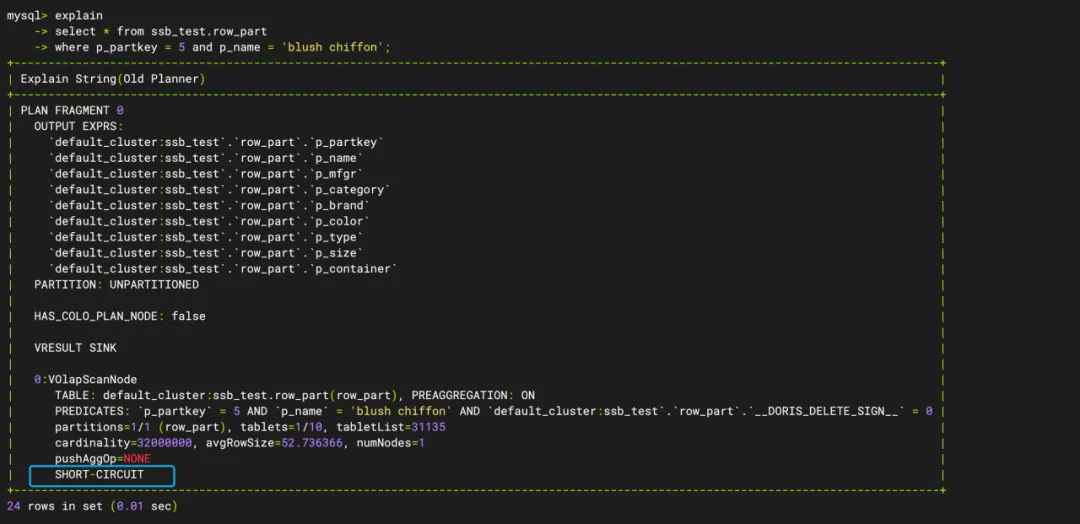
确认是否符合高并发点查条件,即该SQL是否走短路径(当前版本需要where带上所有key才可触发)。
-- 本地client查验需要先关闭新优化器
set experimental_enable_nereids_planner=false;
-- ScanNode中是否有SHORT-CIRCUIT标识
explain
select * from ssb_test.row_part
where p_partkey = 5 and p_name = 'blush chiffon';
如下图所示,ScanNode中有SHORT-CIRCUIT标识,符合高并发点查条件。
- prepare参数生成
获取prepare的csv参数数据。
--
select
p_partkey,
p_name
from ssb_test.row_part
limit 3000;
导出查询结果集(通过dbeaver自身的功能导出csv数据作为prepare参数)。
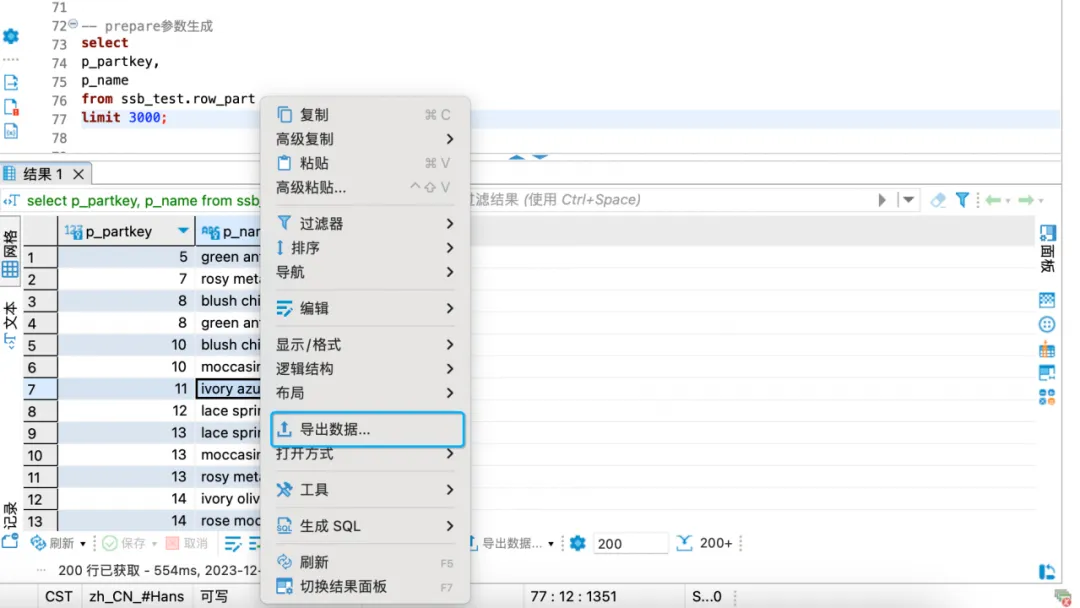
导出后会在相应目录生成对应文件(需要手动去除第一行的字段名)。
上传至jmeter的home目录下。
- JMX脚本准备
可以在本地jmeter客户端配置后保存生成.jmx再上传至jmeter的home目录下。
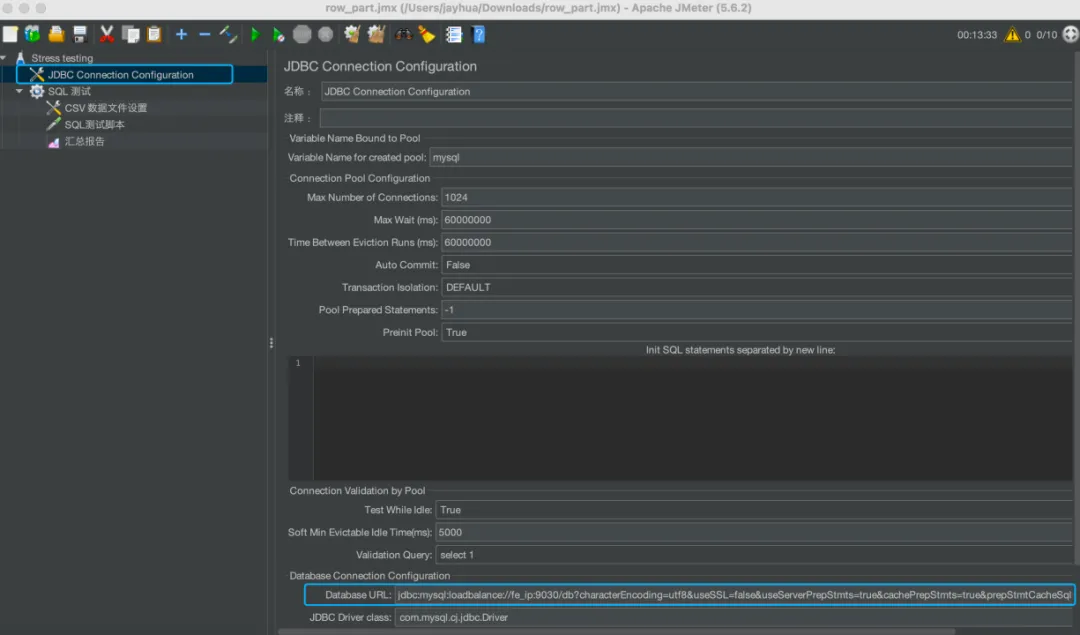
① JDBC连接管理器
jdbc:mysql:loadbalance://fe_ip:9030/db?characterEncoding=utf8&useSSL=false&useServerPrepStmts=true;cachePrepStmts=true&prepStmtCacheSqlLimit=1024
直接影响效率的参数:
- useServerPrepStmts = true
- cachePrepStmts = true
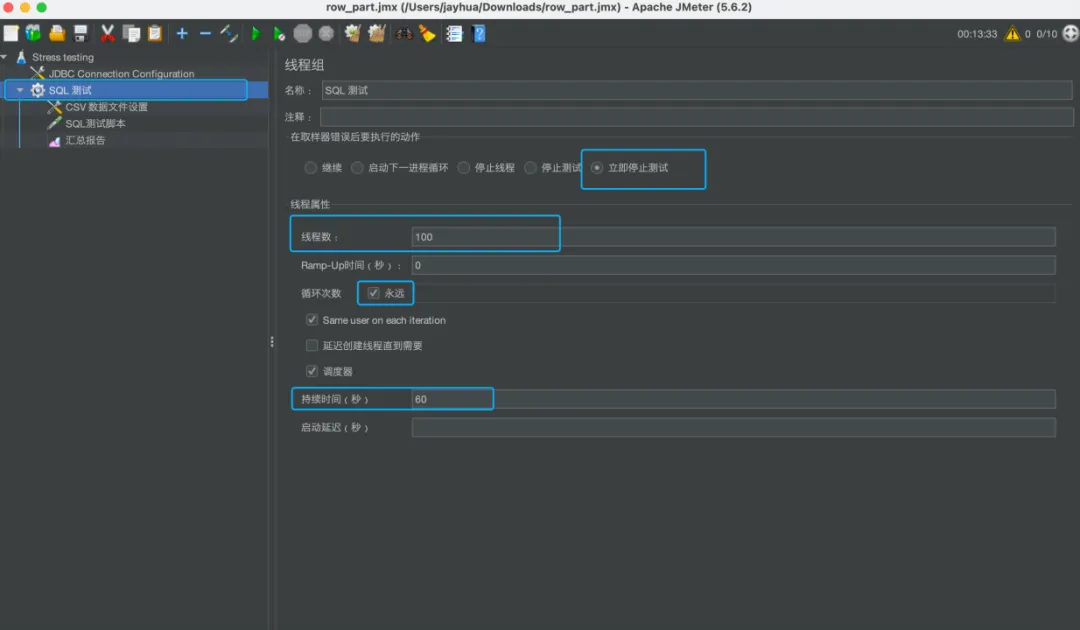
② 线程组
主要用于控制压测的循环测试、线程数和压测时间等;本文默认设置的是100线程数压60秒。
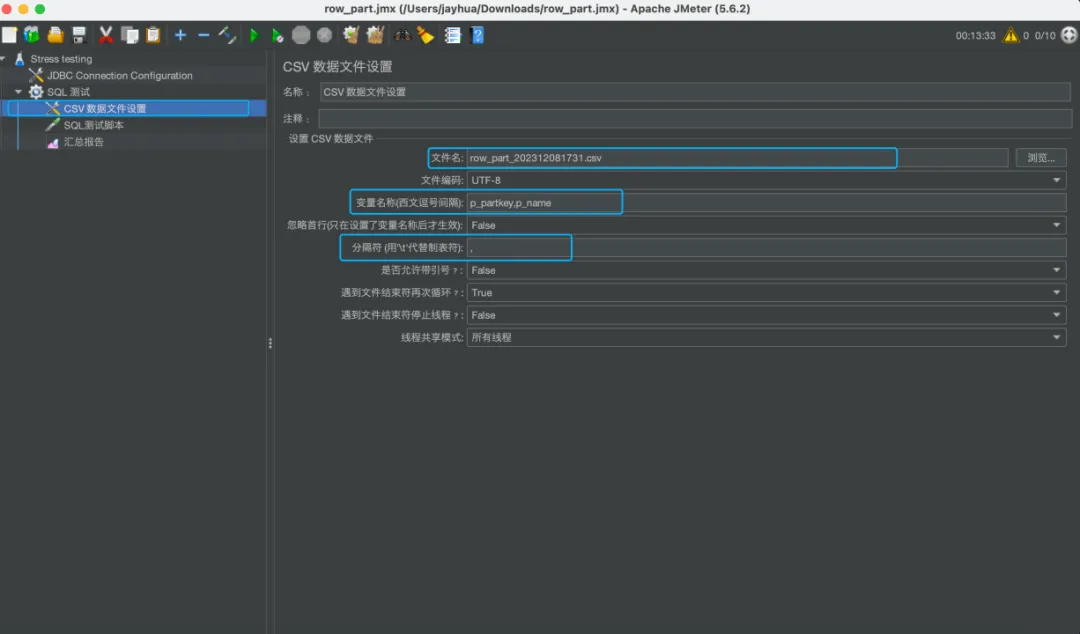
③ CSV数据文件设置
需要注意文件名、即对应 [prepare参数生成] 的csv文件存放路径, 以及csv列对应的字段名称和分隔符的填写。
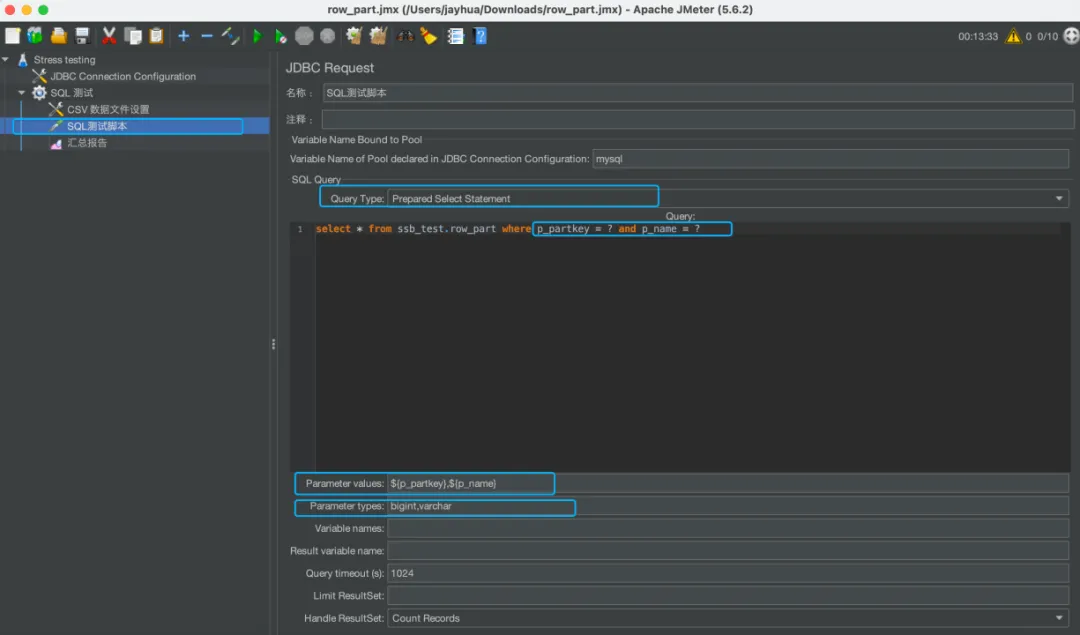
④ SQL测试脚本
选择Prepare模式随机传参,其中[Parameter values]和[Parameter types]需要和SQL中的[?]缺省值完全对齐。
七、高并发实测
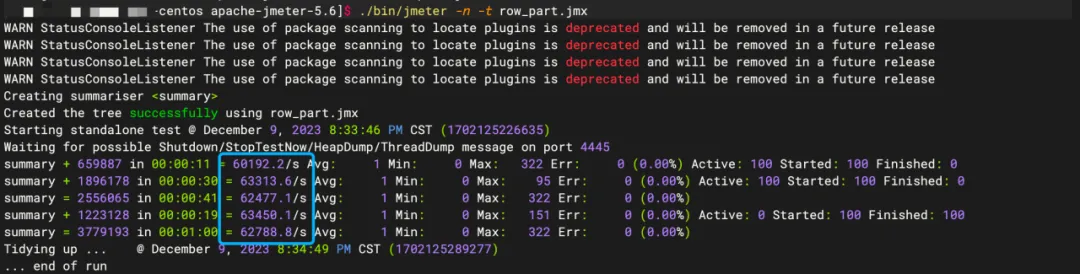
Jmeter执行脚本(简易模式)。
./bin/jmeter -n -t row_part.jmx
最终随机压测结果的平均QPS为6W+/S。
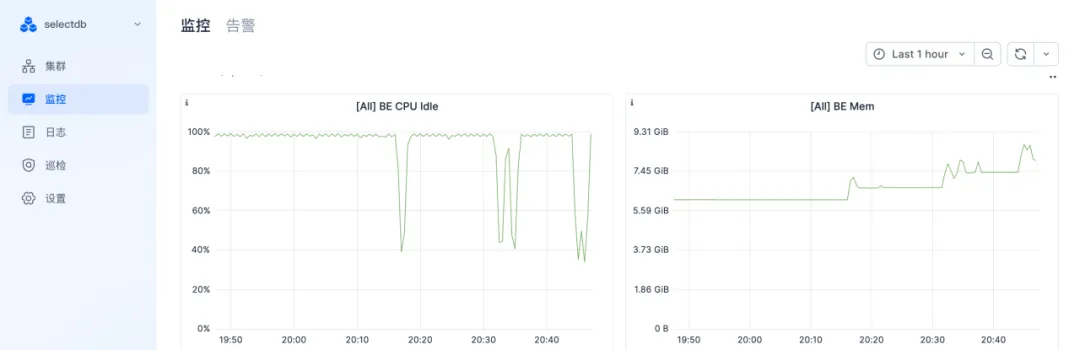
压测过程中,BE的CPU大致使用50%(其中包括Jmeter进程的),内存使用率较低。
八、影响因素
- 常规配置
- 未按【参数预调】进行调整
- 未按【JMX脚本准备】进行合理设置
- 数据分区分桶太大(并行度过高)或太小(并发过小)都会影响效率
- jdbc参数
仅去除 jdbc url 中的useServerPrepStmts=true; 参数时降为3W+/S。
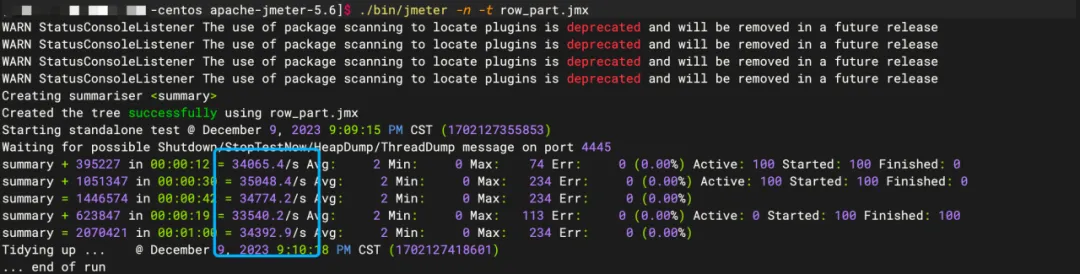
仅去除 jdbc url 中的cachePrepStmts=true; 参数时降为2W/S。
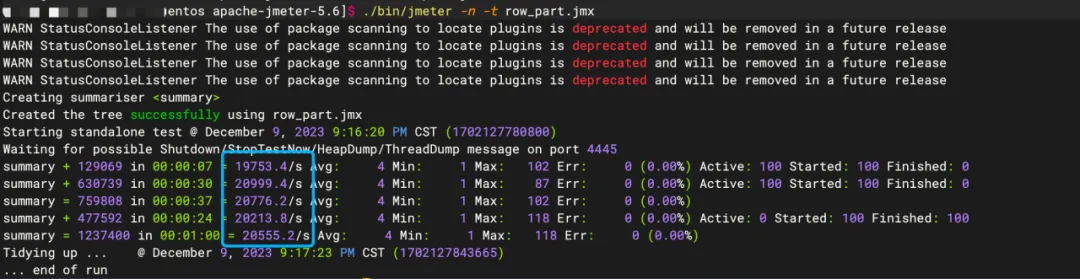
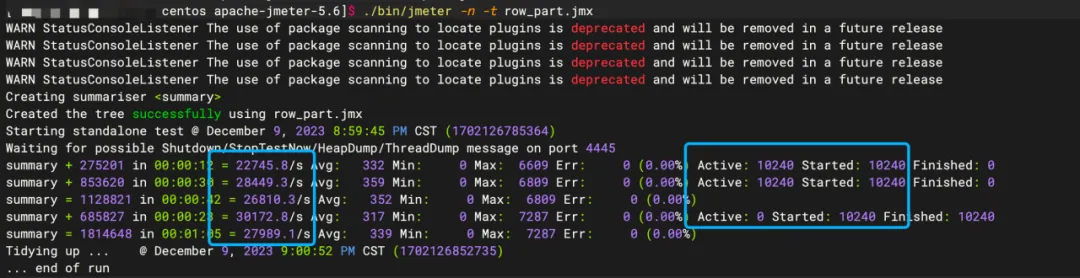
- 线程数
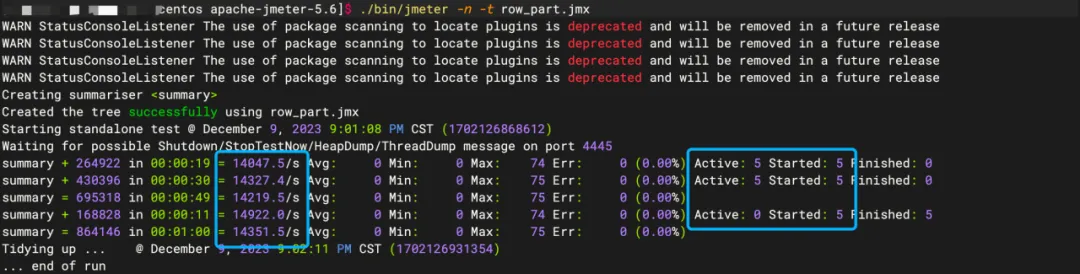
不宜过高,例如> 1W线程数时,降为2W+/S。
不宜过少,例如5个线程数时,降为1W+/S。
具体线程数设置需要根据【环境信息】进行对比调整。
- fe个数
合理范围内,1个fe可提高一定的并发量。如果多加fe、QPS都没有增长,需要定位是否存在其它影响因素。
- prepare参数分布
【prepare参数生成】过于集中、可能导致集中查某几台be影响效率,需要足够分散。
- 资源瓶颈
如果上述原因都符合预期,且CPU还相对空闲的情况下,QPS依旧无法提升,需要排查网络或IO等资源是否遇到了瓶颈。
- 其它
欢迎各位看官补充。
九、总结
Apache Doris 基于MPP架构、列存、分区分桶、向量化引擎、索引视图和基准优化等方面实现了高性能并发查询。在此基础上引入了行存、短查询路径和Prepared Statement特性实现了高并发点查询,效果俱佳。如果有相关场景的同学,欢迎实测交流。
至此,【Apache Doris】如何实现高并发点查 分享结束,查阅过程中若遇到问题欢迎留言交流。