作为C++开发者,我们对键值容器非常熟悉,例如std::set、std::map、std::unordered_map等。这些容器以其强大的功能和高效的性能,成为我们处理数据存储和检索任务时的得力助手。但是你用过多键容器(MultiIndex)吗?
在某些复杂的应用场景中,我们可能需要根据不同的属性来检索同一组数据。传统的容器如std::map只能让我们根据单一键来进行排序和查找,但Boost库中的Boost.MultiIndex容器则允许我们定义多个索引,使得我们可以像使用多个std::map一样,但在同一个容器实例中根据不同的键来管理和查询数据。
Boost.MultiIndex是Boost C++ Libraries的一部分,它提供了一个强大的数据结构,允许在同一个集合中为元素建立多种索引。这意味着我们可以根据不同的键来排序和访问集合中的元素,同时保持对数据的高效管理和快速访问。在本篇文章中,我们将介绍Boost.MultiIndex的基本概念、特性和使用方法。
基本概念
Boost.MultiIndex容器是一个模板类,可以在同一个数据结构中维护多个索引视图。这些索引视图可以是有序的,也可以是无序的,甚至可以是非唯一的。每个索引都可以独立地对数据进行排序和访问,使得该数据结构非常适合于需要多重排序和检索条件的复杂查询操作。
特性
- 多重索引:可以根据不同的键(如ID、名称、日期等)对同一数据集建立多个索引。
- 灵活性:支持有序索引(如基于红黑树的索引)和无序索引(如基于哈希表的索引)。
- 性能优化:尽管维护了多个索引,但通过精心的设计和模板元编程技术,Boost.MultiIndex能够提供高效的运行时性能。
- 数据一致性:无论通过哪个索引进行操作,容器中的数据都将保持同步,确保数据的一致性。
- 迭代器稳定性:即使在容器修改(如插入或删除操作)后,现有迭代器也仍然有效。
使用方法
为了说明如何使用Boost.MultiIndex,我们将创建一个简单的示例,其中包含一个人员信息的集合,并为其建立两个索引:按姓名排序和按年龄排序。
首先,您需要包含Boost.MultiIndex库头文件:
#include <boost/multi_index_container.hpp>
#include <boost/multi_index/ordered_index.hpp>
#include <boost/multi_index/member.hpp>
using namespace boost::multi_index;
接着定义数据结构和容器:
// 定义人员信息结构体
struct person {
int id;
std::string name;
int age;
person(int id, const std::string& name, int age) : id(id), name(name), age(age) {}
};
// 定义标签,用于识别索引
struct id{};
struct name{};
struct age{};
// 定义multi_index_container
typedef multi_index_container<
person,
indexed_by<
// 根据ID排序的唯一索引
ordered_unique<tag<id>, member<person, int, &person::id>>,
// 根据姓名排序的非唯一索引
ordered_non_unique<tag<name>, member<person, std::string, &person::name>>,
// 根据年龄排序的非唯一索引
ordered_non_unique<tag<age>, member<person, int, &person::age>>
>
> person_multi;
// 创建multi_index_container实例
person_multi persons;
现在,我们向容器中插入一些数据:
persons.insert(person(1, "Alice", 30));
persons.insert(person(2, "Bob", 25));
persons.insert(person(3, "Charlie", 35));
要通过特定的索引来访问数据,可以使用get函数,并传入标签:
// 按名称索引访问
const auto& name_index = persons.get<name>();
for(const auto& entry : name_index) {
std::cout << entry.name << std::endl;
}
// 按年龄索引访问
const auto& age_index = persons.get<age>();
for(const auto& entry : age_index) {
std::cout << entry.age << std::endl;
}
// find:
auto&& view = persons.get<name>();
auto it = view.find("Bob");
Boost库的特点:
Boost库是一组广泛使用的C++库,它提供了程序员在标准C++库之外所需要的许多功能。Boost库以其高质量、广泛的适用性和对最新C++标准的支持而著称。Boost库在C++社区中享有很高的声誉,并且其部分库最终成为了C++标准库的一部分。
Boost库的一些重要组件:
- Smart Pointers:提供智能指针,如
shared_ptr、weak_ptr、unique_ptr等,用于自动内存管理。 - Asio:提供了一个跨平台的异步I/O库,用于网络编程和低级文件操作。
- MultiIndex:允许开发人员为同一组数据创建多个索引的容器。
- Graph:提供了图数据结构及其相关算法的实现。
- Regex:提供了正则表达式处理功能。
- Algorithm:提供了各种数据结构和算法,如排序、搜索等。
- Thread:提供了处理线程的库,包括互斥锁、线程局部存储等。
- 更多信息 :请参考boost官网文档。
Boost库与C++标准的关系:
Boost库与C++标准的发展密切相关,许多Boost库的功能最终被纳入C++标准库中。例如,C++11标准中的智能指针和线程支持在很大程度上是基于Boost的对应组件。因此,学习和使用Boost库不仅可以提升当前的开发效率,也对理解和掌握未来C++标准的发展有着重要意义。
结语
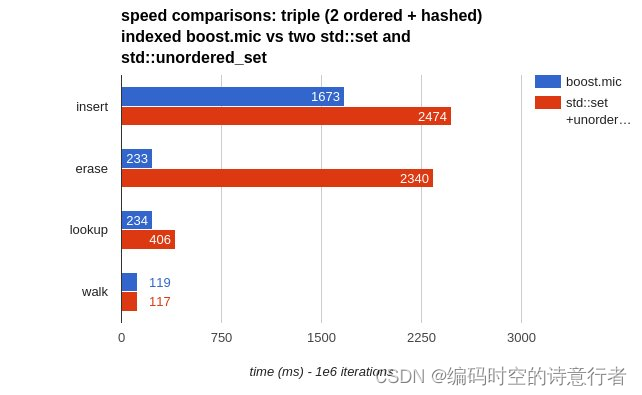
使用Boost.MultiIndex,可以创建一个容器,定义多个索引,每个索引可以是唯一的或非唯一的,并且可以是有序的或无序的。除了多重索引的便利性,Boost.MultiIndex还提供了迭代器的稳定性。即使在数据的插入或删除操作之后,现有迭代器仍然指向正确的元素,这在普通的std::map或std::set中是无法保证的。
那么问题来了,你用过Boost.MultiIndex容器吗?如果你曾经面临过需要多种方式排序或检索数据的挑战,那么使用Boost.MultiIndex可能会是一个非常适合的选择。不仅仅因为它的多重索引能力,也因为它在性能和灵活性方面的表现。尽管有一定的学习曲线,但一旦你掌握了它的使用,你会发现它在处理复杂数据结构时的巨大优势。
扩展阅读:
为什么要使用 Boost.MultiIndex 上
为什么要使用 Boost.MultiIndex 下
如果遇到了需要多维度查询的数据问题,不妨尝试一下Boost.MultiIndex,让代码更加高效和优雅。通过不断学习和尝试新的工具和库,将会让我们在C++的世界里走得更远。