文章目录
12.3.5 Caffe有哪些接口
12.4 网络搭建有什么原则
12.4.1 新手原则
12.4.2 深度优先原则
12.4.3 卷积核size一般为奇数
12.4.4 卷积核不是越大越好
12.5 有哪些经典的网络模型值得我们去学习的
12.6 网络训练有哪些技巧
12.6.1 合适的数据集
12.6.2 合适的预处理方法
12.6.3 网络的初始化
12.6.4 小规模数据训练
12.6.5 设置合理Learning Rate
12.6.6 损失函数
12.3.5 Caffe有哪些接口
Caffe深度学习框架支持多种编程接口,包括命令行、Python和Matlab,下面将介绍如何使用这些接口。
1. Caffe Python接口
Caffe提供 Python 接口,即Pycaffe,具体实现在caffe、python文件夹内。在Python代码中import caffe,可以load models(导入模型)、forward and backward (前向、反向迭代)、handle IO(数据输入输出)、visualize networks(绘制net)和instrument model solving(自定义优化方法)。所有的模型数据、计算参数都是暴露在外、可供读写的。
(1)caffe.Net 是主要接口,负责导入数据、校验数据、计算模型。
(2)caffe.Classsifier 用于图像分类。
(3)caffe.Detector 用于图像检测。
(4)caffe.SGDSolver 是露在外的 solver 的接口。
(5)caffe.io 处理输入输出,数据预处理。
(6)caffe.draw 可视化 net 的结构。
(7)caffe blobs 以 numpy ndarrys 的形式表示,方便而且高效。
2. Caffe MATLAB接口
MATLAB接口(Matcaffe)在 caffe/matlab 目录的 caffe 软件包。在 matcaffe 的基础上,可将Caffe整合到MATLAB代码中。
MATLAB接口包括:
(1)MATLAB 中创建多个网络结构。
(2)网络的前向传播(Forward)与反向传播(Backward)计算。
(3)网络中的任意一层以及参数的存取。
(4)网络参数保存至文件或从文件夹加载。
(5)blob 和 network 形状调整。
(6)网络参数编辑和调整。
(7)创建多个 solvers 进行训练。
(8)从solver 快照(Snapshots)恢复并继续训练。
(9)访问训练网络(Train nets)和测试网络(Test nets)。
(10)迭代后网络交由 MATLAB 控制。
(11)MATLAB代码融合梯度算法。
3. Caffe命令行接口
命令行接口 Cmdcaffe 是 Caffe 中用来训练模型、计算得分以及方法判断的工具。Cmdcaffe 存放在 caffe/build/tools 目录下。
caffe train
caffe train 命令用于模型学习,具体包括:
(1)caffe train 带 solver.prototxt 参数完成配置。
(2)caffe train 带 snapshot mode_iter_1000.solverstate 参数加载 solver snapshot。
(3)caffe train 带 weights 参数 model.caffemodel 完成 Fine-tuning 模型初始化。
caffe test
caffe test 命令用于测试运行模型的得分,并且用百分比表示网络输出的最终结果,比如 accuracyhuoloss 作为其结果。测试过程中,显示每个 batch 的得分,最后输出全部 batch 的平均得分值。
caffe time
caffe time 命令用来检测系统性能和测量模型相对执行时间,此命令通过逐层计时与同步,执行模型检测。
参考文献: 1.深度学习:Caffe之经典模型讲解与实战/ 乐毅,王斌
12.4 网络搭建有什么原则
12.4.1 新手原则
刚入门的新手不建议直接上来就开始搭建网络模型。比较建议的学习顺序如下:
- 1.了解神经网络工作原理,熟悉基本概念及术语。
- 2.阅读经典网络模型论文+实现源码(深度学习框架视自己情况而定)。
- 3.找数据集动手跑一个网络,可以尝试更改已有的网络模型结构。
- 4.根据自己的项目需要设计网络。
12.4.2 深度优先原则
通常增加网络深度可以提高准确率,但同时会牺牲一些速度和内存。但深度不是盲目堆起来的,一定要在浅层网络有一定效果的基础上,增加深度。深度增加是为了增加模型的准确率,如果浅层都学不到东西,深了也没效果。
12.4.3 卷积核size一般为奇数
卷积核为奇数有以下好处:
- 1 保证锚点刚好在中间,方便以 central pixel为标准进行滑动卷积,避免了位置信息发生偏移 。
- 2 保证在填充(Padding)时,在图像之间添加额外的零层,图像的两边仍然对称。
12.4.4 卷积核不是越大越好
AlexNet中用到了一些非常大的卷积核,比如11×11、5×5卷积核,之前人们的观念是,卷积核越大,感受野越大,看到的图片信息越多,因此获得的特征越好。但是大的卷积核会导致计算量的暴增,不利于模型深度的增加,计算性能也会降低。于是在VGG、Inception网络中,利用2个3×3卷积核的组合比1个5×5卷积核的效果更佳,同时参数量(3×3×2+1=19<26=5×5×1+1)被降低,因此后来3×3卷积核被广泛应用在各种模型中。
12.5 有哪些经典的网络模型值得我们去学习的
提起经典的网络模型就不得不提起计算机视觉领域的经典比赛:ILSVRC .其全称是 ImageNet Large Scale Visual Recognition Challenge.正是因为ILSVRC 2012挑战赛上的AlexNet横空出世,使得全球范围内掀起了一波深度学习热潮。这一年也被称作“深度学习元年”。而在历年ILSVRC比赛中每次刷新比赛记录的那些神经网络也成为了人们心中的经典,成为学术界与工业届竞相学习与复现的对象,并在此基础上展开新的研究。
| 序号 | 年份 | 网络名称 | 获得荣誉 |
|---|---|---|---|
| 1 | 2012 | AlexNet | ILSVRC图像分类冠军 |
| 2 | 2014 | VGGNet | ILSVRC图像分类亚军 |
| 3 | 2014 | GoogLeNet | ILSVRC图像分类冠军 |
| 4 | 2015 | ResNet | ILSVRC图像分类冠军 |
| 5 | 2017 | SeNet | ILSVRC图像分类冠军 |
1. AlexNet
- 论文:ImageNet Classification with Deep Convolutional Neural Networks
- 代码实现:tensorflow
- 主要特点:
1.第一次使用非线性激活函数ReLU。
2.增加防加过拟合方法:Droupout层,提升了模型鲁棒性。
3.首次使用数据增强。
4.首次使用GPU加速运算。
2. VGGNet
- 论文:Very Deep Convolutional Networks for Large-Scale Image Recognition
- 代码实现:tensorflow
- 主要特点:
1.网络结构更深。
2.普遍使用小卷积核。
3. GoogLeNet
- 论文:Going Deeper with Convolutions
- 代码实现:tensorflow
- 主要特点:
1.增强卷积模块功能。 主要的创新在于他的Inception,这是一种网中网(Network In Network)的结构,即原来的结点也是一个网络。Inception一直在不断发展,目前已经V2、V3、V4。其中1*1卷积主要用来降维,用了Inception之后整个网络结构的宽度和深度都可扩大,能够带来2-3倍的性能提升。
2.连续小卷积代替大卷积,保证感受野不变的同时,减少了参数数目。
4. ResNet
- 论文:Deep Residual Learning for Image Recognition
- 代码实现:tensorflow
- 主要特点:
解决了“退化”问题,即当模型的层次加深时,错误率却提高了。
5. SeNet
- 论文:Squeeze-and-Excitation Networks
- 代码实现:tensorflow
- 主要特点:
提出了feature recalibration,通过引入 attention 重新加权,可以得到抑制无效特征,提升有效特征的权重,并很容易地和现有网络结合,提升现有网络性能,而计算量不会增加太多。
CV领域网络结构演进历程:
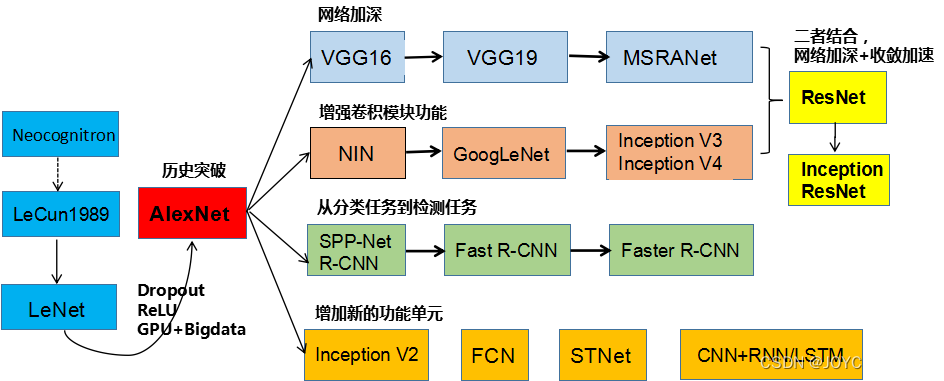
ILSVRC挑战赛历年冠军:
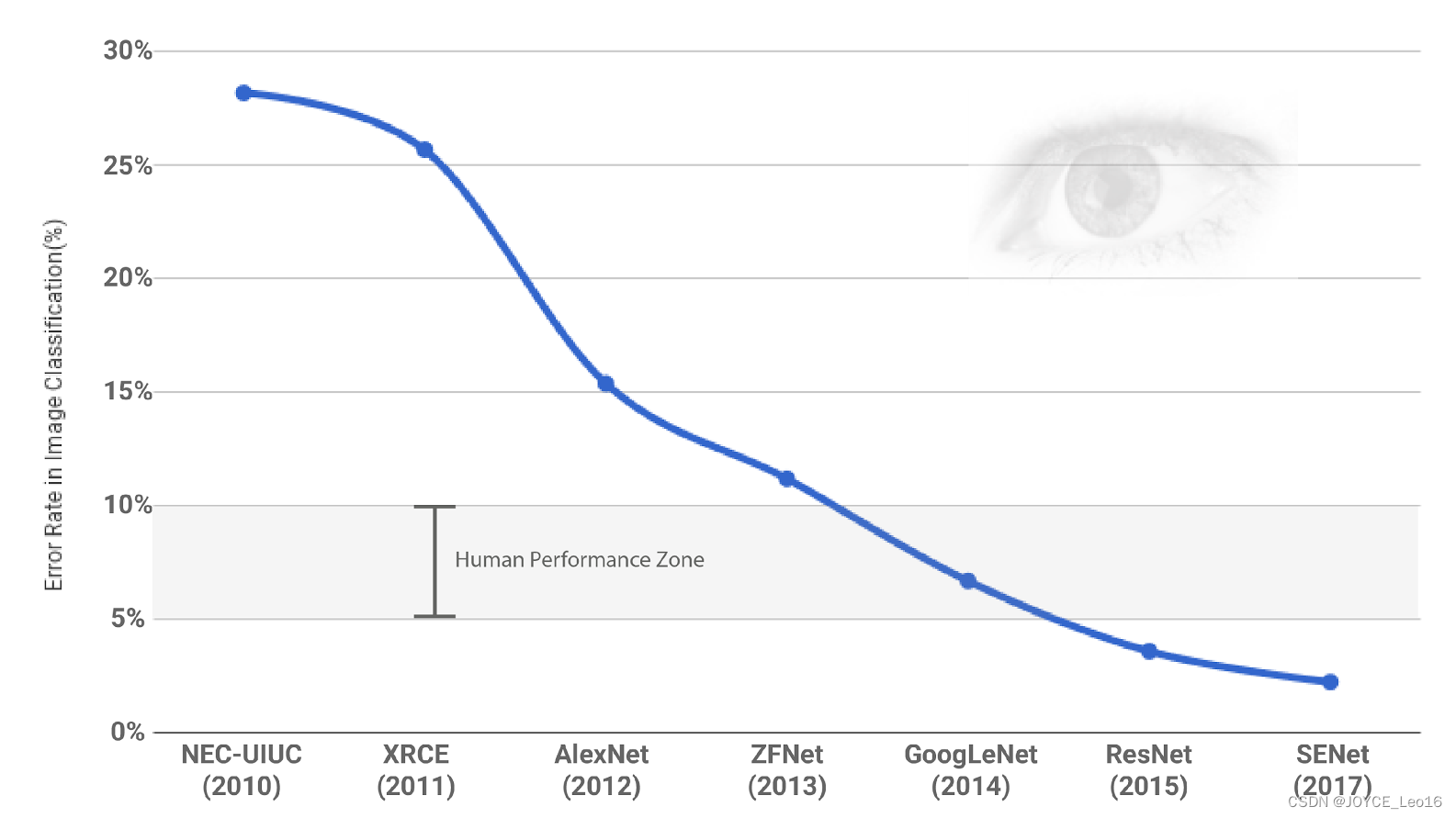
此后,ILSVRC挑战赛的名次一直是衡量一个研究机构或企业技术水平的重要标尺。 ILSVRC 2017 已是最后一届举办.2018年起,将由WebVision竞赛(Challenge on Visual Understanding by Learning from Web Data)来接棒。因此,即使ILSVRC挑战赛停办了,但其对深度学习的深远影响和巨大贡献,将永载史册。
12.6 网络训练有哪些技巧
12.6.1 合适的数据集
1 没有明显脏数据(可以极大避免Loss输出为NaN)。
2 样本数据分布均匀。
12.6.2 合适的预处理方法
关于数据预处理,在Batch Normalization未出现之前预处理的主要做法是减去均值,然后除去方差。在Batch Normalization出现之后,减均值除方差的做法已经没有必要了。对应的预处理方法主要是数据筛查、数据增强等。
12.6.3 网络的初始化
网络初始化最粗暴的做法是参数赋值为全0,这是绝对不可取的。因为如果所有的参数都是0,那么所有神经元的输出都将是相同的,那在back propagation的时候同一层内所有神经元的行为也是相同的,这可能会直接导致模型失效,无法收敛。吴恩达视频中介绍的方法是将网络权重初始化均值为0、方差为1符合的正态分布的随机数据。
12.6.4 小规模数据训练
在正式开始训练之前,可以先用小规模数据进行试练。原因如下:
- 1 可以验证自己的训练流程对否。
- 2 可以观察收敛速度,帮助调整学习速率。
- 3 查看GPU显存占用情况,最大化batch_size(前提是进行了batch normalization,只要显卡不爆,尽量挑大的)。
12.6.5 设置合理Learning Rate
- 1 太大。Loss爆炸、输出NaN等。
- 2 太小。收敛速度过慢,训练时长大大延长。
- 3 可变的学习速率。比如当输出准确率到达某个阈值后,可以让Learning Rate减半继续训练。
12.6.6 损失函数
损失函数主要分为两大类:分类损失和回归损失:
1. 回归损失:
- 均方误差(MSE 二次损失 L2损失) 它是我们的目标变量与预测值变量差值平方。
- 平均绝对误差(MAE L1损失) 它是我们的目标变量与预测值变量差值绝对值。 关于MSE与MAE的比较。MSE更容易解决问题,但是MAE对于异常值更加鲁棒。更多关于MAE和MSE的性能,可以参考L1vs.L2 Loss Function
2.分类损失:
- 交叉熵损失函数。 是目前神经网络中最常用的分类目标损失函数。
- 合页损失函数 合页损失函数广泛在支持向量机中使用,有时也会在损失函数中使用。缺点:合页损失函数是对错误越大的样本施以更严重的惩罚,但是这样会导致损失函数对噪声敏感。