文章目录
- 1. 题目链接
- 2. 题目代码
- 3. 题目总结
- 4. 代码分析
1. 题目链接
Arrival of the General
2. 题目代码
#include<iostream>
using namespace std;
int heightOfSoldier[110];
int main(){
int numberOfSoldier;
cin >> numberOfSoldier;
int maxHeight = -1;
int minHeight = 101;
int positionOfMaxHeight;
int positionOfMinHeight;
for(int positionOfSoldier = 1; positionOfSoldier <= numberOfSoldier; positionOfSoldier ++){
cin >> heightOfSoldier[positionOfSoldier];
if(heightOfSoldier[positionOfSoldier] > maxHeight){
maxHeight = heightOfSoldier[positionOfSoldier];
positionOfMaxHeight = positionOfSoldier;
}
if(heightOfSoldier[positionOfSoldier] <= minHeight){
minHeight = heightOfSoldier[positionOfSoldier];
positionOfMinHeight = positionOfSoldier;
}
}
if(positionOfMaxHeight == 1 && positionOfMinHeight == numberOfSoldier){
cout << 0;
}else{
if(positionOfMaxHeight < positionOfMinHeight){
cout << positionOfMaxHeight - 1 + numberOfSoldier - positionOfMinHeight;
}else{
cout << positionOfMaxHeight + numberOfSoldier - positionOfMinHeight - 2;
}
}
return 0;
}
3. 题目总结
用时:31min
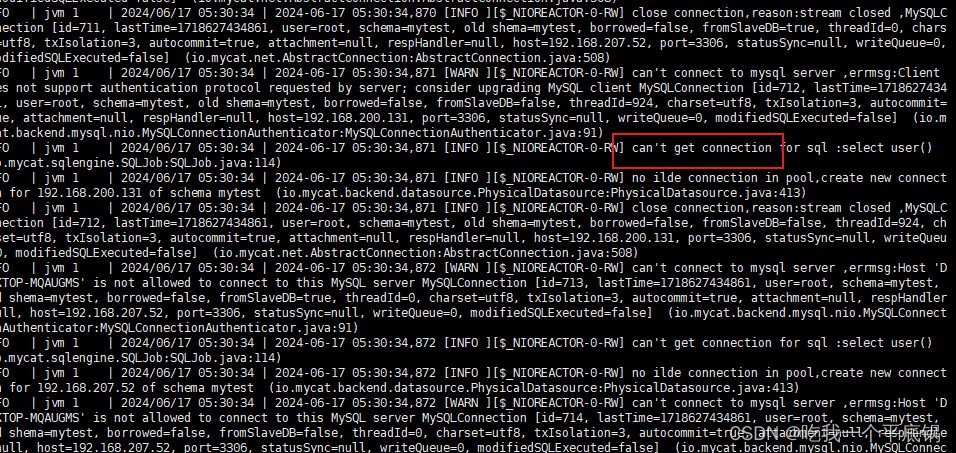
耗时原因:梳理了一下数据的移动过程,发现第二个样例不只有下述一种移动方式。总之就是,不管怎么移动,只要最后能保证最高的的在开头,最矮的在末尾就行。除此之外还应该注意,最高的和最矮的不能同时移动。
4. 代码分析
参考代码来源:

#include <bits/stdc++.h>
using namespace std;
using ll = long long;
using ull = unsigned long long;
using uint = unsigned int;
void solve() {
int n;cin>>n;
vector<int> v(n);
for(auto&i:v) cin >>i;
int mx = 0,mxind = 0;
int mn = 101,mnind = 0;
for(int i =0;i<n;++i){
if (v[i]>mx){mx = v[i],mxind = i;}
if (v[i]<=mn) mn = v[i],mnind =i;
}
cout<< mxind + n-1-mnind -(mxind>mnind?1:0);
}
int main() {
ios::sync_with_stdio(false);
cin.tie(nullptr);
cout.tie(nullptr);
solve();
}
我的代码耗时:124ms
内存占用:0KB
两端代码运行时间上存在差异的原因(回复来自gpt):
① 输入/输出效率:
参考代码:使用cin进行输入,使用cout进行输出。它还通过ios::sync_with_stdio(false)关闭了与stdio的同步,以便进行更快的输入输出操作。
我的代码:同样使用cin和cout,但没有显式地管理输入输出的同步。
差异:参考代码显式地管理了输入输出的同步,并且利用向量操作效率高,这样可以减少多次输入输出操作的开销。这使得参考代码通常比我的代码更快,特别是在处理较大输入时更为显著。
② 数据结构和访问模式:
参考代码:使用向量存储士兵的身高,并直接访问向量元素(v[i]),由于内存连续访问和潜在的编译器优化,这是高效的。
我的代码:使用固定大小的数组(heightOfSoldier),并通过索引访问元素(heightOfSoldier[positionOfSoldier])。数组访问通常比向量访问稍快,因为内存管理更简单(无需动态调整大小)。
差异:虽然两段代码都使用数组(参考代码使用向量),但参考代码中向量的使用可能被编译器或标准库实现更好地优化,从而提高性能。
③控制流和分支逻辑:
两段代码都涉及查找士兵身高的最大值和最小值的类似逻辑。然而,参考代码中计算结果的逻辑(mxind + n - 1 - mnind - (mxind > mnind ? 1 : 0))可能在分支逻辑上更为优化。
差异:参考代码中的分支逻辑(mxind > mnind ? 1 : 0)比我的代码中的条件检查(positionOfMaxHeight < positionOfMinHeight)更为简单直接,这可能更容易让编译器进行优化。
总结来说,参考代码通常由于更高效的输入输出处理、向量操作的优化以及更简洁的分支逻辑,而表现更好。这些优化共同导致参考代码在运行时相比我的代码更为快速,特别是在处理较大输入时表现更为明显。