文章目录
- 前言
- 一、追踪代码
- 二、源码分析
- 三、详解kb_faiss_pool类的load_vector_store
- 1. 方法定义
- 2. 方法实现
- 3. 优点
- 4. 再看看self.new_vector_store
- 总结
前言
上一篇文章,我们追到了这里,了解了kb是通过KBServiceFactory产生的一个对象,而且这个对象根据类型不同,分别会实例化出类似 FaissKBService和ChromaKBService这样的向量数据库对象。

之前在向量索引的文章里,我们讲过Faiss和Chroma这两种向量数据库,并且简易写了运用他们的代码。今天我们看看langchain-chatchat是 怎么封装的
一、追踪代码
沿着kb_doc_api.py 的update_docs 往下,我们可以看到如图所示的地方在使用kb里的方法

追踪kb.update_doc(kb_file, not_refresh_vs_cache=True) ,点进去

可以看到,实际上是调用了 FaissKBService继承的KBService里的 update_doc方法,它往下会调用 FaissKBService继承的KBService的add_doc
继续追踪,可以看到这个方法调用了 do_add_doc
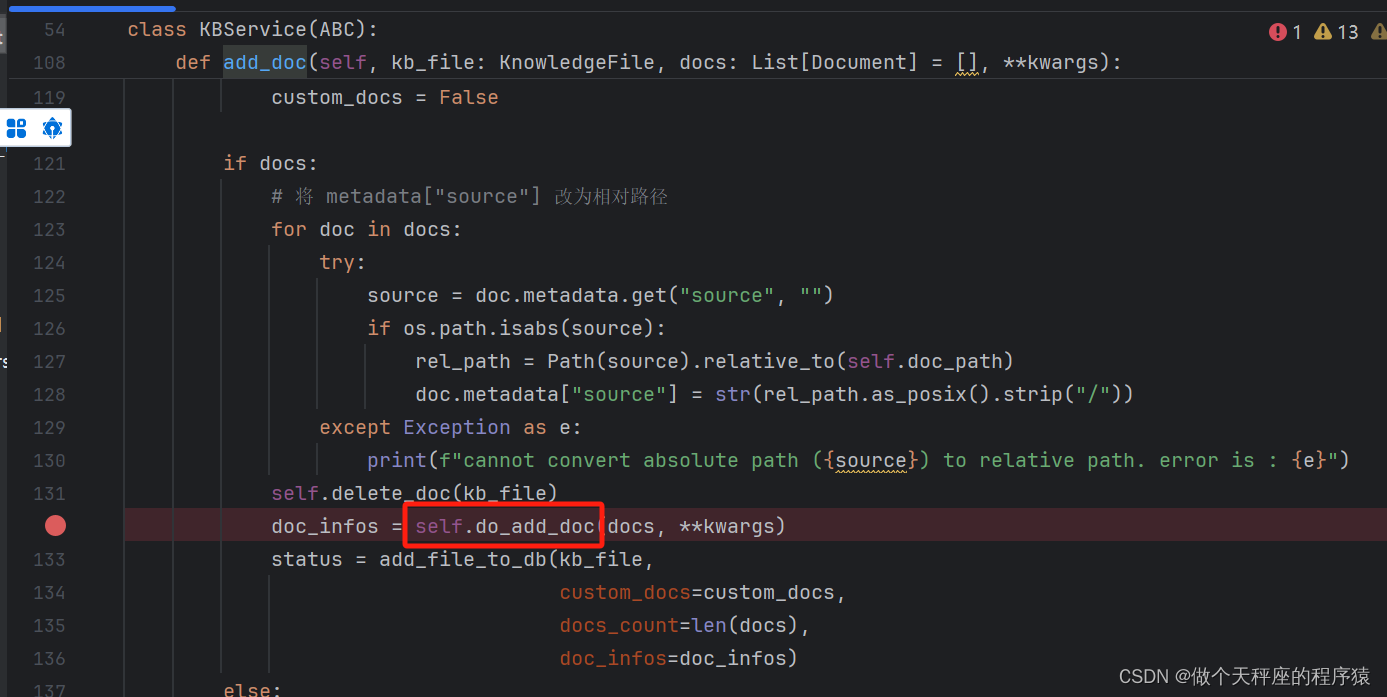
do_add_doc 是 一个抽象方法,它需要被实现。那么我们进入FaissKBService 看看是怎么实现它的
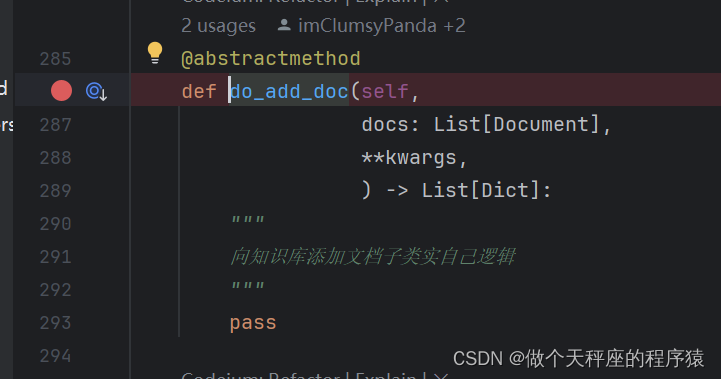
我们选择方框所示的一条

二、源码分析
根据上面的步骤,我们可以看到如下的代码
def do_add_doc(self,
docs: List[Document],
**kwargs,
) -> List[Dict]:
data = self._docs_to_embeddings(docs) # 将向量化单独出来可以减少向量库的锁定时间
with self.load_vector_store().acquire() as vs:
ids = vs.add_embeddings(text_embeddings=zip(data["texts"], data["embeddings"]),
metadatas=data["metadatas"],
ids=kwargs.get("ids"))
if not kwargs.get("not_refresh_vs_cache"):
vs.save_local(self.vs_path)
doc_infos = [{"id": id, "metadata": doc.metadata} for id, doc in zip(ids, docs)]
torch_gc()
return doc_infos
1. 把文档制作成向量
data = self._docs_to_embeddings(docs)
这一步,调用选择的embedding模型,将docs转换成向量数据
2.with self.load_vector_store().acquire() as vs:
这一段就很眼熟了,我们之前研究过with的用法,它的主要作用就是可以让某些操作,例如清零缓存关闭连接的操作可以在后续自动执行。
这里的self.load_vector_store 是用来创建或读取向量对象的。
它的代码如下,调用了kb_faiss_pool的load_vector_store
def load_vector_store(self) -> ThreadSafeFaiss:
return kb_faiss_pool.load_vector_store(kb_name=self.kb_name,
vector_name=self.vector_name,
embed_model=self.embed_model)
acquire()里有with需要的try和finally,还记得吗?with代码块会让代码阻塞在yield 这一行,finally就是with代码块执行完成之后要做的事情。这里就是 先把对象给到 vs变量,然后在代码块执行之后做一个解锁的操作。
................
yield self._obj
finally:
if log_verbose:
logger.info(f"{owner} 结束操作:{self.key}。{msg}")
self._lock.release()
3. vs.add_embeddings
将上面将转换成向量数据的知识存入向量数据库里
三、详解kb_faiss_pool类的load_vector_store
KBFaissPool 是一个继承自 _FaissPool 的类,用于处理知识库中的向量存储操作。它的主要功能是加载或创建特定知识库的向量存储。
1. 方法定义
load_vector_store 方法的定义如下:
def load_vector_store(
self,
kb_name: str,
vector_name: str = None,
create: bool = True,
embed_model: str = EMBEDDING_MODEL,
embed_device: str = embedding_device(),
) -> ThreadSafeFaiss:
这个方法接受五个参数:
kb_name: 知识库的名称,是一个必需的字符串参数。vector_name: 向量存储的名称,是一个可选字符串参数。如果未提供,则使用embed_model作为默认值。create: 一个布尔值,指示是否在向量存储不存在时创建一个新的向量存储,默认值为True。embed_model: 嵌入模型的名称,默认值为EMBEDDING_MODEL。embed_device: 嵌入设备,默认值为调用embedding_device()的结果。
2. 方法实现
方法实现的主要步骤如下:
1) 获取互斥锁:
python self.atomic.acquire()
这是为了确保在多线程环境下对共享资源的安全访问。
2) 确定 vector_name:
python vector_name = vector_name or embed_model
如果 vector_name 未提供,则使用 embed_model 作为默认值。
3) 检查缓存:
python cache = self.get((kb_name, vector_name)) if cache is None:
检查是否已有对应的向量存储。如果没有,则创建一个新的 ThreadSafeFaiss 对象。
4) 初始化向量存储:
python item = ThreadSafeFaiss((kb_name, vector_name), pool=self) self.set((kb_name, vector_name), item) with item.acquire(msg="初始化"): self.atomic.release() logger.info(f"loading vector store in '{kb_name}/vector_store/{vector_name}' from disk.") vs_path = get_vs_path(kb_name, vector_name)
创建并设置一个新的 ThreadSafeFaiss 对象,并记录日志。
5) 加载或创建向量存储:
python if os.path.isfile(os.path.join(vs_path, "index.faiss")): embeddings = self.load_kb_embeddings(kb_name=kb_name, embed_device=embed_device, default_embed_model=embed_model) vector_store = FAISS.load_local(vs_path, embeddings, normalize_L2=True, distance_strategy="METRIC_INNER_PRODUCT") elif create: if not os.path.exists(vs_path): os.makedirs(vs_path) vector_store = self.new_vector_store(embed_model=embed_model, embed_device=embed_device) vector_store.save_local(vs_path) else: raise RuntimeError(f"knowledge base {kb_name} not exist.")
- 如果向量存储文件存在,加载现有的向量存储。
- 如果向量存储文件不存在且 create 为 True,则创建一个新的向量存储。
- 如果向量存储文件不存在且 create 为 False,则抛出错误。
6) 设置和完成加载:
python item.obj = vector_store item.finish_loading()
设置向量存储对象,并标记加载完成。
7) 返回结果:
python return self.get((kb_name, vector_name))
返回相应的向量存储对象。
3. 优点
load_vector_store 方法的设计非常合理,确保了在多线程环境下对向量存储的安全加载和创建。它通过检查缓存来避免重复加载,并提供了创建新向量存储的功能。该方法对于需要高效管理大规模知识库向量存储的应用场景非常适用。
4. 再看看self.new_vector_store
这句话的 self指代的是如下一段
class _FaissPool(CachePool):
def new_vector_store(
self,
embed_model: str = EMBEDDING_MODEL,
embed_device: str = embedding_device(),
) -> FAISS:
embeddings = EmbeddingsFunAdapter(embed_model)
doc = Document(page_content="init", metadata={})
vector_store = FAISS.from_documents([doc], embeddings, normalize_L2=True,distance_strategy="METRIC_INNER_PRODUCT")
ids = list(vector_store.docstore._dict.keys())
vector_store.delete(ids)
return vector_store
这里面最重要的就是 下面这一句
vector_store = FAISS.from_documents([doc], embeddings, normalize_L2=True, distance_strategy="METRIC_INNER_PRODUCT")
这句话的作用是利用 FAISS 库创建一个新的向量存储,并将一个文档的向量嵌入存储在其中。
关键组成部分
1) FAISS.from_documents:
- 这是 FAISS 库中的一个方法,用于从文档创建向量存储。
- FAISS(Facebook AI Similarity Search)是一种高效的相似度搜索库,广泛应用于向量搜索和相似度匹配任务。
2) [doc]:
- 这是一个包含单个文档的列表。
doc通常是一个表示文本或其他信息的对象。 - 通过将文档放入列表中,可以传递一个或多个文档以创建向量存储。
3) embeddings:
- 这是用于将文档转换为向量的嵌入模型。
- 嵌入模型可以将文本或其他信息表示为高维向量,便于进行相似度计算和搜索。
4) normalize_L2=True:
- 这是一个参数,指示是否对向量进行 L2 正则化。
- L2 正则化可以将向量的长度归一化,使得向量的范数为 1,有助于提高相似度计算的准确性。
5) distance_strategy="METRIC_INNER_PRODUCT":
- 这是一个参数,指定向量之间距离的计算策略。
"METRIC_INNER_PRODUCT"表示使用内积作为相似度度量方式,内积可以高效计算向量之间的相似度。
总结
通过上面的封装,我们可以大致了解到langchain-chatchat的封装风格,因为代码呈树状分支一层一层的往下调用,所以不太容易看明白。大家可以多看几次





![[Linux] 文件系统](https://img-blog.csdnimg.cn/direct/5473e625e9c14caf8a26c998b1c211c6.png)