1.背景
最近在做一个AI项目,需要用到yolov8的实例分割功能来确定一个不规则区域,从而找出不规则区域的坐标完成大致定位,以前有用过yolov8的目标检测功能,实际上yolov8的分割功能和检测功能大同小异。本博客将仔细分享使用yolov8图像分割的详细流程。
2.流程介绍
流程包括如下:环境配置、数据集制作、训练、测试
3.环境配置
certifi 2023.7.22
charset-normalizer 3.3.0
contourpy 1.1.1
cycler 0.12.1
fonttools 4.43.1
idna 3.4
importlib-resources 6.1.0
kiwisolver 1.4.5
matplotlib 3.7.3
numpy 1.24.4
opencv-python 4.8.1.78
packaging 23.2
pandas 2.0.3
Pillow 10.1.0
pip 20.0.2
pkg-resources 0.0.0
psutil 5.9.6
py-cpuinfo 9.0.0
pyparsing 3.1.1
python-dateutil 2.8.2
pytz 2023.3.post1
PyYAML 6.0.1
requests 2.31.0
scipy 1.10.1
seaborn 0.13.0
setuptools 44.0.0
six 1.16.0
torch 1.8.0+cu111
torchaudio 0.8.0
torchvision 0.9.0+cu111
tqdm 4.66.1
typing-extensions 4.8.0
tzdata 2023.3
ultralytics 8.0.150
urllib3 2.0.7
zipp 3.17.0 4.数据集制作
建立一个datasets文件夹,在文件夹下面分别建立images好labels文件夹,在images文件夹下可以分别建立train、val、test文件夹,然后在labels里面也建立train、val、test文件夹,将相应的图片和txt标签档房间去即可。然后写一个后缀为.yaml的配置文件即可。yaml文件参考结构如下:
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
# COCO128 dataset https://www.kaggle.com/ultralytics/coco128 (first 128 images from
# COCO train2017) by Ultralytics
# Example usage: python train.py --data coco128.yaml
# parent
# ├── yolov5
# └── datasets
# └── coco128 ← downloads here (7 MB)
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: C:\Users\admin\Desktop\yolov8\datasets # dataset root dir
train: images/train2017 # train images (relative to 'path') 128 images
val: images/train2017 # val images (relative to 'path') 128 images
test: # test images (optional)
# Classes
names:
0: outside
# Download script/URL (optional)
download: https://ultralytics.com/assets/coco128.zip实际使用的时候,主要是修改数据集的path路径即可。
5.训练
自己是在linux服务器上跑的,因为以前跑过目标检测,所以在将数据集和配置文件写好上传之后,直接修改了任务命令参数运行以下命令试跑的:
yolo train task = segmentation model = yolov8n-seg.pt data =outside.yaml epochs = 20 batch=2
结果报错:
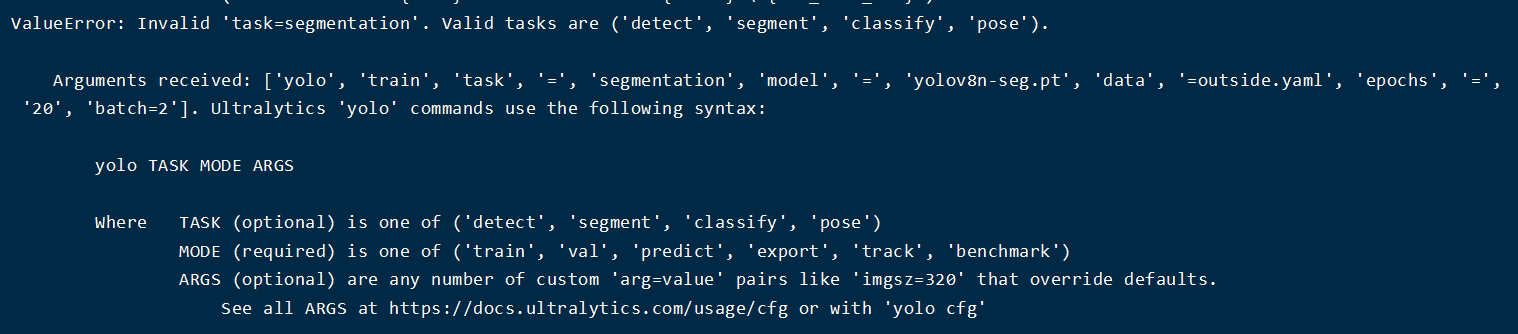 根据错误提示可以知道,应该是自己的参数设置错误了,提示中给出了yolov8支持的任务参数。同时也给出了如下的相关信息提示:
根据错误提示可以知道,应该是自己的参数设置错误了,提示中给出了yolov8支持的任务参数。同时也给出了如下的相关信息提示:
1. Train a detection model for 10 epochs with an initial learning_rate of 0.01
yolo train data=coco128.yaml model=yolov8n.pt epochs=10 lr0=0.01
2. Predict a YouTube video using a pretrained segmentation model at image size 320:
yolo predict model=yolov8n-seg.pt source='https://youtu.be/Zgi9g1ksQHc' imgsz=320
3. Val a pretrained detection model at batch-size 1 and image size 640:
yolo val model=yolov8n.pt data=coco128.yaml batch=1 imgsz=640
4. Export a YOLOv8n classification model to ONNX format at image size 224 by 128 (no TASK required)
yolo export model=yolov8n-cls.pt format=onnx imgsz=224,128
5. Run special commands:
yolo help
yolo checks
yolo version
yolo settings
yolo copy-cfg
yolo cfg
Docs: https://docs.ultralytics.com
Community: https://community.ultralytics.com
GitHub: https://github.com/ultralytics/ultralytics
最终自己通过提示进行了命令修改,顺利完成了训练。最终命令如下:
yolo train task=segment model=yolov8n-seg.pt data=outside.yaml epochs = 20 batch=2
训练成功提示的参数如下:
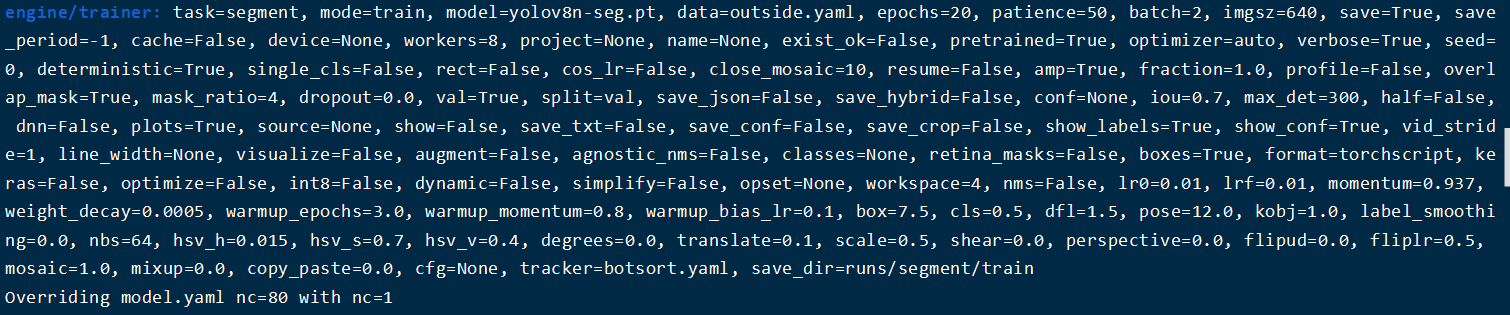
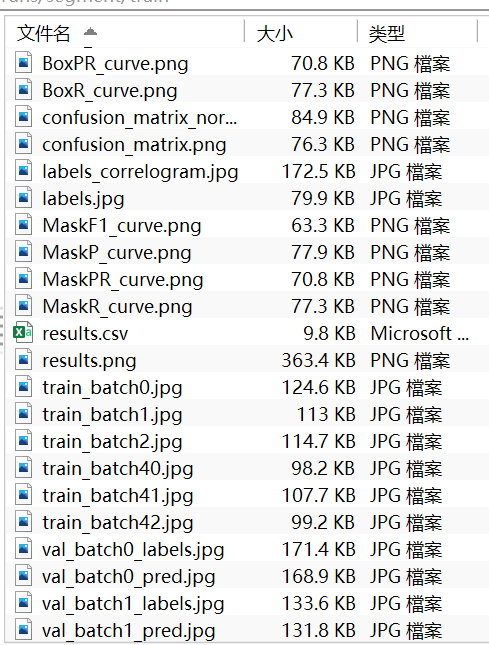
训练完成后会在run文件下生成对应的模型权重及相关图片。
6.测试
yolo segment predict model=PME_best_n.pt source=test.jpg
也可以使用代码测试:
from ultralytics import YOLO
# Load a model
model = YOLO("best.pt") # load a custom model
# Predict with the model
results = model("test.jpg") # predict on an image
print(results)



![[Redis]持久化机制](https://img-blog.csdnimg.cn/direct/869dc989f3364f158d5b249e2728db9b.png)



![.[nicetomeetyou@onionmail.org].faust深入剖析勒索病毒及防范策略](https://img-blog.csdnimg.cn/direct/0a1cae07f2f94d57a93ebed134d50e64.jpeg)