OpenAI近期召开了开发者大会,同时也发布和开放了一些新的功能特性,比如新版本GPT-4 Turbo,支持128k上下文,知识截止更新到2023年4月,视觉能力、DALL·E3,文字转语音TTS等等全都对API开放,GPTs商店已经对Plus账户开放。 本文将对OpenAI截止到目前的大部分开放API能力进行介绍,注意的是这里使用的账号必须是绑定了信用卡的正式账户,非正常渠道购买的账号不能调用大部分API。
图像
图像内容识别
带有视觉能力的 GPT-4,有时也称为 GPT-4V 或 gpt-4-vision-preview ,在 API 中,允许模型接收图像并回答有关它们的问题。 该模型最擅长回答有关图像中存在的内容的一般问题。虽然它确实了解图像中对象之间的关系,但它尚未优化以回答有关图像中某些对象位置的详细问题。 例如,你可以问它汽车是什么颜色的,或者根据冰箱里的东西,晚餐的一些想法可能是什么,但如果你给它看一个房间的图像,并问它椅子在哪里,它可能无法正确回答问题。
😝有需要的小伙伴,可以V扫描下方二维码免费领取🆓
 **注意事项**
**注意事项**
(1)通过控制 detail 参数(具有两个选项) low 或 high ,您可以控制模型如何处理图像并生成其文本理解。
- low 将禁用“高分辨率”模型。该模型将收到低分辨率 512 x 512 版本的图像,并以 65 个Token的预算表示图像。这允许 API 返回更快的响应,并为不需要高细节的用例使用更少的输入令牌。
- high 将启用“高分辨率”模式,该模式首先允许模型查看低分辨率图像,然后根据输入图像大小将输入图像的详细裁剪创建为 512px 正方形。每个详细的作物都使用两倍的Token预算(65 个Token),总共 129 个Token。
(2)聊天API 不是有状态的。这意味着必须自己管理传递给模型的消息(包括图像)。如果要多次将同一图像传递给模型,则必须在每次向 API 发出请求时传递图像。
(3)对于长时间运行的对话,我们建议通过 URL 而不是 base64 传递图像。还可以通过提前缩小图像大小以小于预期的最大大小来改善模型的延迟。对于低分辨率模式,我们期望图像为 512 像素 x 512 像素。对于高静止模式,图像的短边应小于 768 像素,长边应小于 2,000 像素。
视频理解实现可以参考这里:https://cookbook.openai.com/examples/gpt_with_vision_for_video_understanding
识别远程图片(URL形式)
通过给定图片的URL,分析图片中的内容,使用到的模型是gpt-4-vision-preview。该模型的效果总体上是非常不错的,可以很精确的识别图中的内容。
代码语言:javascript
复制
client = OpenAI(api_key=api_key)
def recognize_image():
response = client.chat.completions.create(
model="gpt-4-vision-preview",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "这个图片里面有什么"},
{
"type": "image_url",
"image_url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg",
},
],
}
],
max_tokens=300,
)
print(response.choices[0])
原文如下,返回的内容如下:

代码语言:javascript
复制
'这张图片展示了一个自然景观,中间有一条木制的栈道穿过一片绿色的草地。草地上有不同类型的草和植物,背景是树木和一片多云的天空。
整个场景给人一种宁静和平静的感觉,可能是一个适合散步的地方。图片的色彩鲜艳,天空的蓝色和草地的绿色形成了鲜明的对比。'
识别本地图片(Base64编码形式)
如果本地有一个图像或一组图像,则可以以 base 64 编码格式将它们传递给模型。这种方式识别图片的时间很久,图片编码后的字符很长,建议使用URL的方式。请求用到的还是/v1/chat/completions接口。
代码语言:javascript
复制
client = OpenAI(api_key=api_key)
def recognize_encode_image():
image_path = "img_2.png"
with open(image_path, "rb") as image_file:
base64_image = base64.b64encode(image_file.read()).decode('utf-8')
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}"
}
payload = {
"model": "gpt-4-vision-preview",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "What’s in this image?"
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
}
}
]
}
],
"max_tokens": 300
}
response = requests.post("https://api.openai.com/v1/chat/completions", headers=headers, json=payload)
print(response.json())
输入图像:

输出描述:
代码语言:javascript
复制
图片显示了一只猫和一只狗非常靠近,显得亲密和友好。猫的一只前爪伸出,爪子的粉红色肉垫清晰可见,它的眼神似乎透露出好奇或轻微的警惕。狗的表情则比较轻松,眼睛直视镜头。
背景因为焦距的原因变得模糊,无法分辨细节。这种画面很可能被用来表现动物之间的和谐共处或者强调它们可爱的一面。
识别多个图像
聊天 API 能够接收和处理 base64 编码格式或图像网址的多个图像输入。该模型将处理每张图像,并使用来自所有图像的信息来回答问题。
代码语言:javascript
复制
client = OpenAI(api_key=api_key)
def recognize_multiple_images():
response = client.chat.completions.create(
model="gpt-4-vision-preview",
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg",
},
{
"type": "text",
"text": "What’s in these images? Is there any difference between them?",
},
{
"type": "image_url",
"image_url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg",
},
],
}
],
max_tokens=300,
)
print(response.choices[0])
图像生成
OpenAI提供了基于文本提示生成图像,支持的底层模型可以是DALL·E 3 和 DALL·E 2。整体的效果也是比较非常不错,细节到位,图片质量高清。 默认情况下,图像是以 standard 质量生成的,但在使用 DALL·E 3 可以设置 quality: “hd” 以增强细节。方形、标准质量的图像生成速度最快。图像的大小可以是 1024x1024、1024x1792 或 1792x1024 像素。
代码语言:javascript
复制
client = OpenAI(api_key=api_key)
def generate_image():
response = client.images.generate(
model="dall-e-3",
pompt="一只柴犬趴在沙发上",
size="1024x1024",
quality="standard",
n=1,
)
image_url = response.data[0].url
print('image_url:', image_url)
生成的图像返回的URL格式类似该链接:https://oaidalleapiprodscus.blob.core.windows.net/private/xxx

编辑图像
除了生成图像,还可以通过让模型根据新的文本提示替换预先存在的图像的某些区域来创建图像的编辑版本,目前仅限于DALL· E 2模型。 图像编辑也称为“修复”,允许您通过上传图像和蒙版来编辑或扩展图像,并指示应替换哪些区域。蒙版的透明区域指示应编辑图像的位置,提示应描述完整的新图像,而不仅仅是擦除的区域。
代码语言:javascript
复制
client = OpenAI(api_key=api_key)
def edit_image():
response = client.images.edit(
model="dall-e-2", # only dall-e-2
image=open("img.png", "rb"),
mask=open("img_1.png", "rb"),
prompt="A sunlit indoor lounge area with a pool containing a flamingo",
n=1,
size="1024x1024"
)
image_url = response.data[0].url
print('image_url:', image_url)
Prompt:一个阳光明媚的室内休息区,有一个有火烈鸟的游泳池:

上传的图片和蒙版必须都是小于 4MB 的方形 PNG 图片,并且尺寸必须相同。生成输出时不使用蒙版的非透明区域,因此它们不一定需要像上面的示例那样与原始图像匹配。
图像变体
图像变体是基于现有图片中的主体内容生成主体不变的类似图像,目前仅限DALL· E2模型。
代码语言:javascript
复制
client = OpenAI(api_key=api_key)
def change_image():
response = client.images.create_variation(
image=open("img_2.png", "rb"),
n=2,
size="1024x1024"
)
image_url = response.data[0].url
print('image_url:', image_url)
输入和输出图像如下

与编辑类似,输入图像必须是大小小于 4MB 的方形 PNG 图像。
文本
OpenAI 的文本生成模型可以理解自然语言、代码和图像。模型提供文本输出以响应其输入。这些模型的输入也称为“Prompt提示”,通常是通过提供如何成功完成任务的说明或一些示例。
聊天
最常用的就是日常的文本对话功能,输入用户的需求,模型输出理解后的内容。目前gpt-4模型的效果是在众多模型中效果最佳的,费用也更加贵一点。
代码语言:javascript
复制
from openai import OpenAI
client = OpenAI(api_key=api_key)
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{"role": "user", "content": "Where was it played?"}
]
)
print('response:', response.choices[0].message.content)
相应的内容格式如下:
代码语言:javascript
复制
{
"choices": [
{
"finish_reason": "stop",
"index": 0,
"message": {
"content": "The 2020 World Series was played in Texas at Globe Life Field in Arlington.",
"role": "assistant"
}
}
],
"created": 1677664795,
"id": "chatcmpl-7QyqpwdfhqwajicIEznoc6Q47XAyW",
"model": "gpt-3.5-turbo-0613",
"object": "chat.completion",
"usage": {
"completion_tokens": 17,
"prompt_tokens": 57,
"total_tokens": 74
}
}
返回JSON内容
有时候需要模型返回JSON格式的内容,为了防止返回格式异常并提高模型性能,在调用 gpt-4-1106-preview 或 gpt-3.5-turbo-1106 时,可以将 response_format 参数设置为{ “type”: “json_object” } 以启用 JSON 模式。启用 JSON 模式后,模型被限制为仅生成解析为有效 JSON 的字符串。
代码语言:javascript
复制
client = OpenAI(api_key=api_key)
def return_json():
response = client.chat.completions.create(
model="gpt-4-1106-preview", # gpt-3.5-turbo-1106
messages=[
{"role": "system", "content": "You are a helpful assistant, return JSON format."}, # JSON is necessary
{"role": "user", "content": "谁赢了2020年的世界杯?"},
],
response_format={"type": "json_object"} # text default
)
print('response:', response.choices[0].message.content)
提问:谁赢了2022年的世界杯? 返回的内容如下:
代码语言:javascript
复制
{
"winner": "Argentina",
"event": "FIFA World Cup 2022",
"runner_up": "France",
"location": "Qatar",
"date": "December 18, 2022"
}
如果启用了response_format={“type”: “json_object”},但不在Message中加入json相关描述,就会强制报错,如下:
代码语言:javascript
复制
{'error': {'message': "'messages' must contain the word 'json' in some form, to use 'response_format' of type 'json_object'.", 'type': 'invalid_request_error', 'param': 'messages', 'code': None}}
重现结果
默认情况下,模型返回的聊天内容是不确定的(这意味着模型输出可能因请求而异)。现在OpenAI通过在请求中的seed参数和system_fingerprint响应字段来提供对确定性输出的一些控制。 将 seed 参数设置为选择的任何整数,并在希望确定性输出的请求中使用相同的值。确保所有其他参数(如 prompt 或 temperature )在请求之间完全相同。
代码语言:javascript
复制
client = OpenAI(api_key=api_key)
def reproduce_answer():
response = client.chat.completions.create(
model="gpt-3.5-turbo-1106", # gpt-3.5-turbo-1106
messages=[
{"role": "user", "content": "随机生成一个长度为10的字符串"},
],
seed=10086
)
print('system_fingerprint:', response) # 在 gpt-3.5-turbo-1106中有值输出
print('response:', response.choices[0].message.content)
有时,由于 OpenAI 对这边的模型配置进行了必要的更改,确定性可能会受到影响。为了帮助跟踪这些更改,公开了system_fingerprint字段。如果此值不同,则由于OpenAI对系统做了更改,可能会看到不同的输出。 gpt-3.5-turbo模型中system_fingerprint字段返回为None。 如下举例说明了两次随机生成一个长度为10的字符串的结果的一致的。

函数调用
并非所有模型版本都使用函数调用数据进行训练。以下模型支持函数调用:
- gpt-4
- gpt-4-1106-preview
- gpt-4-0613
- gpt-3.5-turbo
- gpt-3.5-turbo-1106
- gpt-3.5-turbo-0613
此外,以下型号还支持并行函数调用:
- gpt-4-1106-preview
- gpt-3.5-turbo-1106
示例如下,提问San Francisco, Tokyo, and Paris的天气情况,而天气的API接口是本地函数,返回的天气数据再传给OpenAI接口进行总结回答。这样就可以扩展模型的功能,将本地函数或接口与模型能力结合,实现更多复杂的需求。
代码语言:javascript
复制
import openai
import json
client = OpenAI(api_key=api_key)
# Example dummy function hard coded to return the same weather
# In production, this could be your backend API or an external API
def get_current_weather(location, unit="fahrenheit"):
"""Get the current weather in a given location"""
if "tokyo" in location.lower():
return json.dumps({"location": location, "temperature": "10", "unit": "celsius"})
elif "san francisco" in location.lower():
return json.dumps({"location": location, "temperature": "72", "unit": "fahrenheit"})
else:
return json.dumps({"location": location, "temperature": "22", "unit": "celsius"})
def run_conversation():
# Step 1: send the conversation and available functions to the model
messages = [{"role": "user", "content": "What's the weather like in San Francisco, Tokyo, and Paris?"}]
tools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]},
},
"required": ["location"],
},
},
}
]
response = client.chat.completions.create(
model="gpt-3.5-turbo-1106",
messages=messages,
tools=tools,
tool_choice="auto", # auto is default, but we'll be explicit
)
response_message = response.choices[0].message
tool_calls = response_message.tool_calls
# Step 2: check if the model wanted to call a function
if tool_calls:
# Step 3: call the function
# Note: the JSON response may not always be valid; be sure to handle errors
available_functions = {
"get_current_weather": get_current_weather,
} # only one function in this example, but you can have multiple
messages.append(response_message) # extend conversation with assistant's reply
# Step 4: send the info for each function call and function response to the model
for tool_call in tool_calls:
function_name = tool_call.function.name
function_to_call = available_functions[function_name]
function_args = json.loads(tool_call.function.arguments)
function_response = function_to_call(
location=function_args.get("location"),
unit=function_args.get("unit"),
)
messages.append(
{
"tool_call_id": tool_call.id,
"role": "tool",
"name": function_name,
"content": function_response,
}
) # extend conversation with function response
second_response = client.chat.completions.create(
model="gpt-3.5-turbo-1106",
messages=messages,
) # get a new response from the model where it can see the function response
return second_response
print(run_conversation())
返回内容如下,成功调用了本地的天气函数,返回了总结后的这几个地区的天气情况。
代码语言:javascript
复制
Currently, the weather in San Francisco is 72°F and partly cloudy. In Tokyo, the weather is 10°C and cloudy. In Paris, the weather is 22°C and partly cloudy.'
生成向量
支持文本生成向量,建议在几乎所有情况下使用 text-embedding-ada-002。因为它更好、更便宜、使用更简单。 示例如下
代码语言:javascript
复制
client = OpenAI(api_key=api_key)
def get_embedding(text, model="text-embedding-ada-002"):
text = text.replace("\n", " ")
return client.embeddings.create(input = [text], model=model)['data'][0]['embedding']
音频
文本生成语音
OpenAI提供了支持文本生成语音的接口。目前支持多种预设好的不同的声音(alloy 、 echo fable 、 onyx nova 、和 shimmer ),可以试听以找到符合想要的语气和听众的声音。 对于实时应用程序,标准 tts-1 模型提供最低的延迟,但质量低于 tts-1-hd 模型。由于音频的生成方式,在某些情况下可能会 tts-1 生成比 tts-1-hd 更静态的内容。 默认响应格式为“mp3”,但也可以使用其他格式,如“opus”、“aac”或“flac”。
注意的是:
- 没有直接的机制来控制所生成音频的情感输出。某些因素可能会影响输出音频,例如大小写或语法,但我们对这些因素的内部测试产生了不同的结果。
- 暂时也不支持自定义声音。
文本转语音的示例如下:
代码语言:javascript
复制
client = OpenAI(api_key=api_key)
def tts():
speech_file_path = Path(__file__).parent / "speech.mp3"
response = client.audio.speech.create(
model="tts-1", # tts-1-hd
voice="alloy", # alloy, echo, fable, onyx, nova, and shimmer
# input="Today is a wonderful day to build something people love!"
input="在海外游戏行业中,用户获取(User Acquisition,UA)通常是指通过购买效果广告来获取流量,类似于国内的买量。海外投放面临的主要挑战是如何选择适合的媒体和素材,以吸引有价值的用户,并评估广告投放的效果。"
)
response.stream_to_file(speech_file_path)
语音 API 支持使用区块传输编码的实时音频流式处理。这意味着在生成完整文件并使其可访问之前,可以播放音频。前提是需要安装FFmpeg相关可执行文件,下载:https://github.com/BtbN/FFmpeg-Builds/releases
代码语言:javascript
复制
client = OpenAI(api_key=api_key)
def stream_and_play():
text = '今天的天气怎么样?可以去公园玩吗?'
response = client.audio.speech.create(
model="tts-1",
voice="alloy",
input=text,
)
# Convert the binary response content to a byte stream
byte_stream = io.BytesIO(response.content)
# Read the audio data from the byte stream
audio = AudioSegment.from_file(byte_stream, format="mp3")
# Play the audio
play(audio)
语音转文字
默认情况下,响应类型将为包含原始文本的 json,也可以将 response_format 设置为 text(仅有音频的文本内容)。
代码语言:javascript
复制
client = OpenAI(api_key=api_key)
def stt():
audio_file = open("speech.mp3", "rb")
transcript = client.audio.transcriptions.create(
model="whisper-1",
file=audio_file,
# response_format="text"
)
print(transcript)
返回结果,语音识别的准确度还是非常高的。
代码语言:javascript
复制
# 原音频文案:
在海外游戏行业中,用户获取(User Acquisition,UA)通常是指通过购买效果广告来获取流量,类似于国内的买量。海外投放面临的主要挑战是如何选择适合的媒体和素材,以吸引有价值的用户,并评估广告投放的效果。
# 转文字后的内容:
在海外游戏行业中,用户获取User Acquisition UA,通常是指通过购买效果广告来获取流量,类似于国内的买量。 海外投放面临的主要挑战是如何选择适合的媒体和素材,以吸引有价值的用户并评估广告投放的效果。
翻译 API 将任何受支持语言的音频文件作为输入,并在必要时将音频转录为英语。这与上面的语音转文字不同,因为输出不是原始输入语言,而是翻译成英语文本。
代码语言:javascript
复制
client = OpenAI(api_key=api_key)
def tanslate_audio():
audio_file = open("speech.mp3", "rb")
transcript = client.audio.translations.create(
model="whisper-1",
file=audio_file
)
print(transcript)
输出内容:
代码语言:javascript
复制
# 原音频文案:
在海外游戏行业中,用户获取(User Acquisition,UA)通常是指通过购买效果广告来获取流量,类似于国内的买量。海外投放面临的主要挑战是如何选择适合的媒体和素材,以吸引有价值的用户,并评估广告投放的效果。
# 翻译后的文案:
In the overseas gaming industry, user acquisition, U.A., usually refers to the acquisition of traffic by purchasing effective advertising, similar to domestic purchasing.
The main challenge faced by overseas advertising is how to choose the right media and material to attract valuable users and assess the effect of advertising.
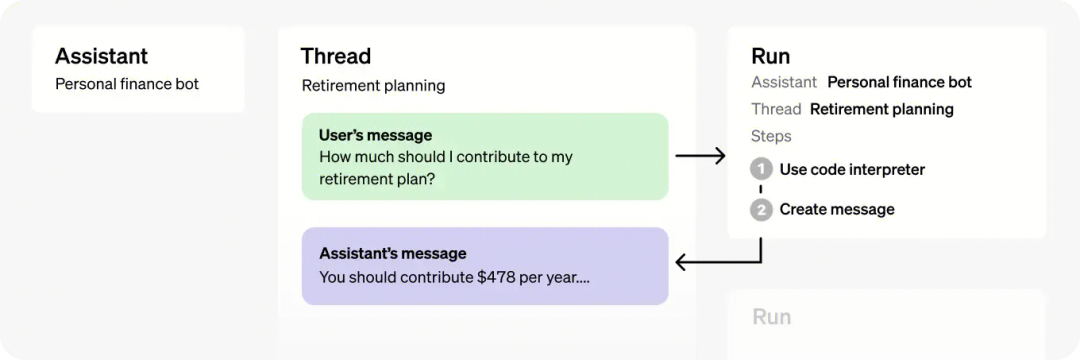
Assistants API
Assistants API 允许在自己的应用程序中构建 AI 助手。助手可以利用模型、工具和知识来响应用户查询。
助手 API 目前支持三种类型的工具:代码解释器、检索和函数调用。
调用 Assistants API 需要传递 beta 版 HTTP 标头。如果使用的是 OpenAI 的官方 Python 和 Node.js SDK,则会自动处理此问题。
代码语言:javascript
复制
OpenAI-Beta: assistants=v1
绝大部分情况下可以指定任何 GPT-3.5 或 GPT-4 模型,包括微调模型。检索工具需要 gpt-3.5-turbo-1106 和 gpt-4-1106-preview 模型。
使用步骤
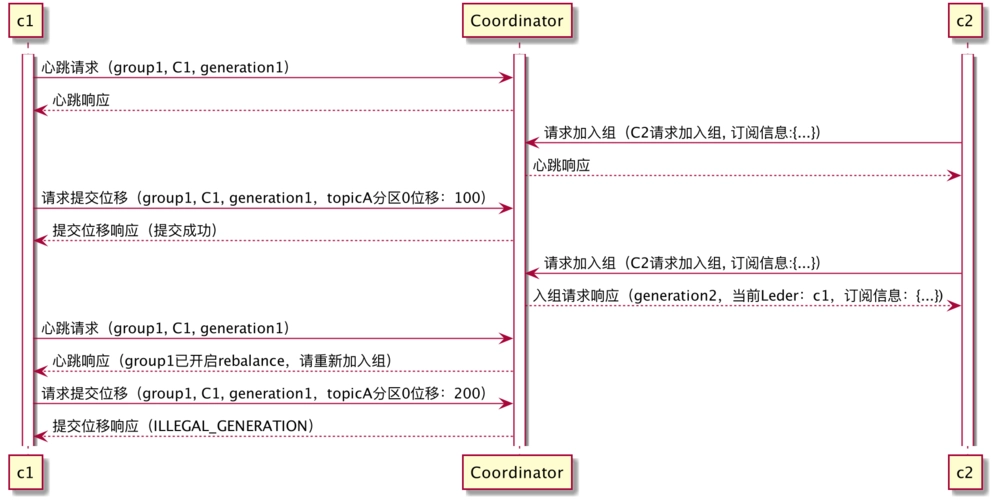
接下来介绍创建和使用 Code Interpreter 助手的关键步骤。涉及的几个关键对象的关系如下图,对象的含义和交互可以在下面的步骤中逐步理解。
第一步:创建助手
可以指定助手的名称,设定注助手的角色,以及助手的类型(如code_interpreter),设置tools字段。
代码语言:javascript
复制
assistant = client.beta.assistants.create(
name="Math Tutor",
instructions="You are a personal math tutor. Write and run code to answer math questions.",
tools=[{"type": "code_interpreter"}],
model="gpt-4-1106-preview"
)
第二步:创建线程
线程没有大小限制。可以根据需要将任意数量的消息传递给线程。API 将使用相关的优化技术(如截断)确保对模型的请求符合最大上下文窗口。
代码语言:javascript
复制
thread = client.beta.threads.create()
第三步:向线程添加消息
消息包含用户的文本(比如用户要计算一个一元一次方程),以及用户上传的任何文件(可选),目前不支持图像文件。
代码语言:javascript
复制
client.beta.threads.messages.create(
thread_id=thread.id,
role="user",
content="I need to solve the equation `3x + 11 = 14`. Can you help me?"
)
第四步:运行助手
要使 Assistant 响应用户消息,您需要创建一个 Run。这使得助手读取线程并决定是调用工具还是简单地使用模型来最好地回答用户查询。随着Run的进行,助手会将 Messages 追加到线程中,并带有 role="assistant"标识。
代码语言:javascript
复制
run = client.beta.threads.runs.create(
thread_id=thread.id,
assistant_id=assistant.id
)
第五步:查询运行结果
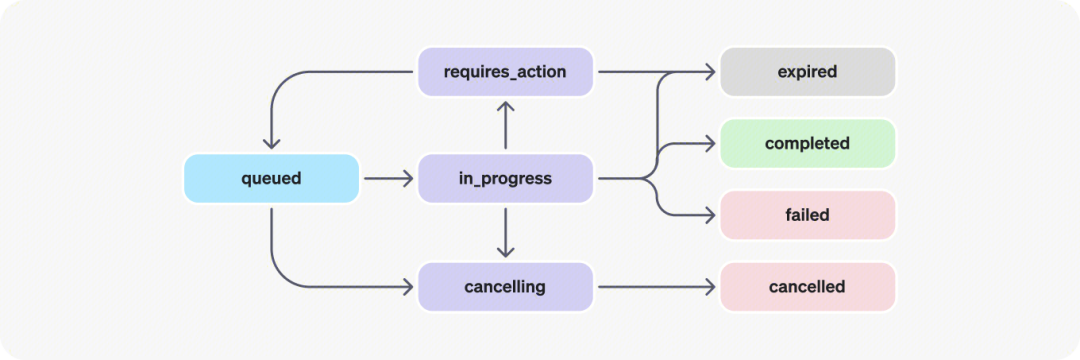
这将创建一个“运行状态”。您可以定期检索 Run 以检查其状态,以查看它是否已移动到 completed ,运行状态的生命周期如下。
- queued:首次创建“Run”或完成“Run”时, required_action 它们将移至排队状态。它们几乎应该立即移动到 in_progress .
- in_progress:运行中的状态,可以通过检查“Run Steps”接口来查看所取得的进度。
- completed:任务完成状态,可以查看助理添加到线程中的所有消息,以及运行所执行的所有步骤。还可以通过向线程添加更多用户消息并创建另一个运行来继续对话。
- requires_action:使用函数调用工具时,一旦模型确定要调用的函数的名称和参数,运行将进入状态 required_action 。然后,必须运行这些函数并提交输出,然后才能继续运行。如果在 expires_at 时间戳过去之前(大约在创建后 10 分钟)未提供输出,则运行将变为过期状态。
- expired:当函数调用(Function功能)输出在 expires_at 之前未提交且运行过期时,会发生这种情况。此外,如果运行时间过长,并且超出了 expires_at 中规定的时间,系统将使运行状态设置为过期。
- cancelling:您可以尝试使用“Cancel Run”接口取消 in_progress 运行。取消尝试成功后,in_progress的状态将变为 cancelled 。尝试取消,但不能保证。
- cancelled:任务已成功取消。
- failed:可以通过查看“Run”中的 last_error 对象来查看失败的原因。失败的时间戳将记录在 failed_at 字段。
在运行任务后,检查状态的代码如下:
代码语言:javascript
复制
while True:
run = client.beta.threads.runs.retrieve(
thread_id=thread.id,
run_id=run.id
)
if run.status == "completed":
break
time.sleep(2)
当状态是completed,就可以获取返回的消息,代码中对消息列表messages 进行逆序输出,是因为最新的消息在数组的最前面。
代码语言:javascript
复制
messages = client.beta.threads.messages.list(
thread_id=thread.id
)
for msg in reversed(messages.data):
if msg.content[0].type == "text":
print(f"{msg.role}:", msg.content[0].text.value)
else:
print(f"{msg.role}:", msg.content[0])
完整示例
创建助手并运行的完整代码示例如下,用户的需求是让助手生成代码并运行代码去解决用户的一个一元一次方程的问题。
代码语言:javascript
复制
def run_assistant():
# step 1: 创建助手
assistant = client.beta.assistants.create(
name="Math Tutor",
instructions="You are a personal math tutor. Write and run code to answer math questions.",
tools=[{"type": "code_interpreter"}],
model="gpt-4-1106-preview"
)
# step 2: 创建线程
thread = client.beta.threads.create()
# step 3: 创建消息
client.beta.threads.messages.create(
thread_id=thread.id,
role="user",
content="I need to solve the equation `3x + 11 = 14`. Can you help me?"
)
# step 4: 运行助手
run = client.beta.threads.runs.create(
thread_id=thread.id,
assistant_id=assistant.id
)
# step 5: 轮询运行结果
while True:
run = client.beta.threads.runs.retrieve(
thread_id=thread.id,
run_id=run.id
)
if run.status == "completed":
break
time.sleep(2)
# step 6: 输出运行结果
messages = client.beta.threads.messages.list(
thread_id=thread.id
)
for msg in reversed(messages.data):
if msg.content[0].type == "text":
print(f"{msg.role}:", msg.content[0].text.value)
else:
print(f"{msg.role}:", msg.content[0])
运行的结果如下:
代码语言:javascript
复制
user: I need to solve the equation `3x + 11 = 14`. Can you help me?
assistant: Of course. To solve the equation `3x + 11 = 14` for x, you would follow these steps:
1. Subtract 11 from both sides of the equation to get `3x = 14 - 11`.
2. Simplify the right-hand side of the equation.
3. Divide both sides by 3 to isolate x.
Let's do that calculation.
assistant: The solution to the equation `3x + 11 = 14` is \( x = 1 \).
支持的工具
CodeInterpreter
上述举例创建助手就是典型的CodeInterpreter用法,模型根据用户请求的性质决定何时在运行中调用代码解释器。 可以通过在助手中提示 instructions 来提升此行为(例如,“编写代码来解决此问题”)。code_interpreter 传入 Assistant 对象的 tools 参数以启用 Code Interpreter
代码语言:javascript
复制
assistant = client.beta.assistants.create(
instructions="You are a personal math tutor. When asked a math question, write and run code to answer the question.",
model="gpt-4-1106-preview",
tools=[{"type": "code_interpreter"}]
)
输入
Code Interpreter 可以分析文件中的数据。当希望向助理提供大量数据或允许用户上传自己的文件进行分析时,此功能非常有用。 在助手级别传递的文件可由使用此助手的所有Run访问,即在创建助手时把文件id传递给file_ids字段。
代码语言:javascript
复制
# Upload a file with an "assistants" purpose
file = client.files.create(
file=open("speech.py", "rb"),
purpose='assistants'
)
# Create an assistant using the file ID
assistant = client.beta.assistants.create(
instructions="You are a personal math tutor. When asked a math question, write and run code to answer the question.",
model="gpt-4-1106-preview",
tools=[{"type": "code_interpreter"}],
file_ids=[file.id]
)
文件也可以在线程级别传递。这些文件只能在特定线程中访问,即在创建线程时把文件id传递给file_ids字段, 作为消息创建请求的一部分传递:
代码语言:javascript
复制
thread = client.beta.threads.create(
messages=[
{
"role": "user",
"content": "I need to solve the equation `3x + 11 = 14`. Can you help me?",
"file_ids": [file.id]
}
]
)
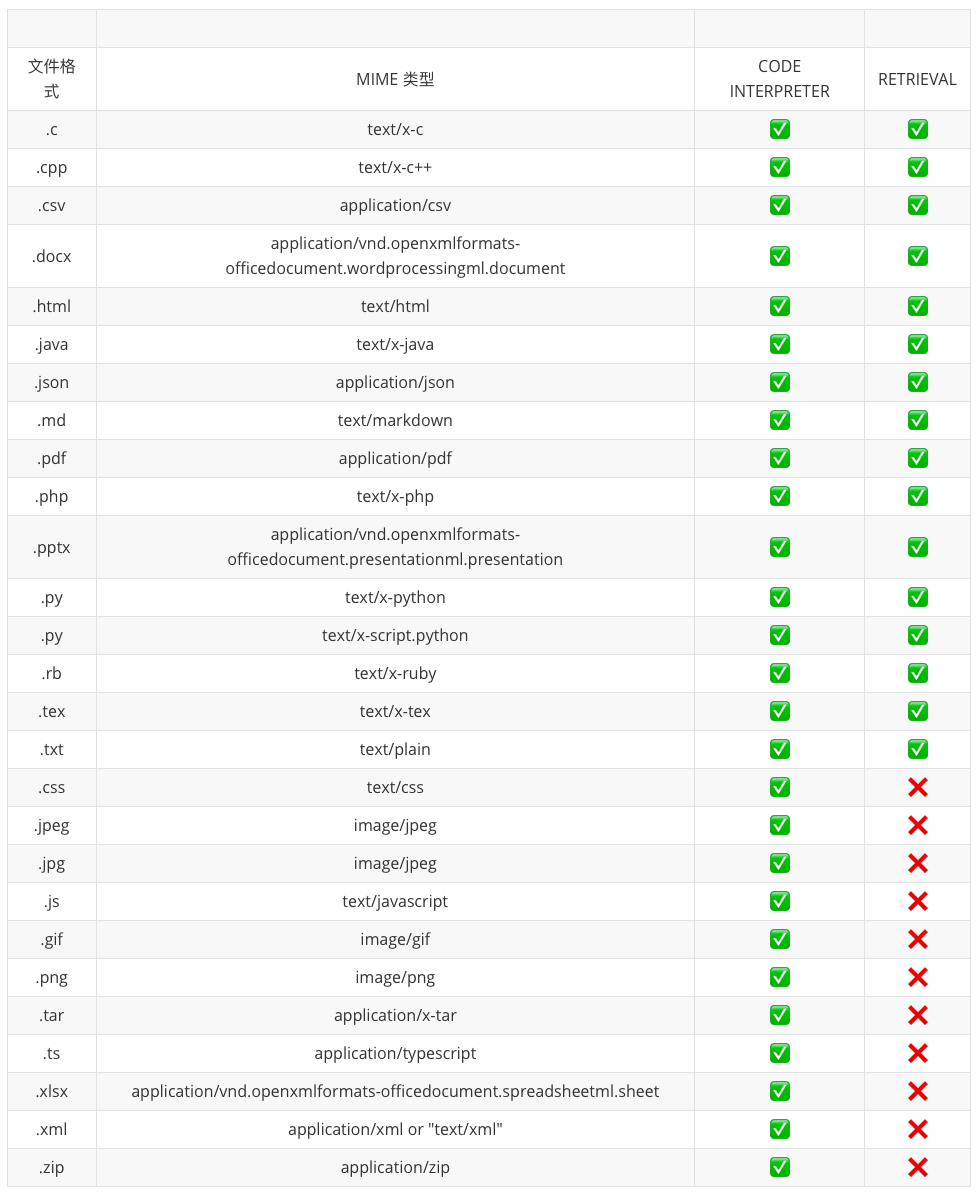
文件的最大大小为 512 MB。 Code Interpreter 支持多种文件格式,包括 .csv 、 .pdf 等等 .json 。有关支持的文件扩展名(及其相应的MIME类型)的更多详细信息,请参阅下面的“支持的文件”部分。 要从助手中删除文件,您可以将文件与助手分离:
代码语言:javascript
复制
file_deletion_status = client.beta.assistants.files.delete(
assistant_id=assistant.id,
file_id=file.id
)
输出
API 中的Code Interpreter支持输出文件,例如生成图像图、CSV 和 PDF。 当 Code Interpreter 生成图像时,您可以在 Assistant 消息响应 file_id 的字段中查找并下载此文件:
代码语言:javascript
复制
{
"id": "msg_OHGpsFRGFYmz69MM1u8KYCwf",
"object": "thread.message",
"created_at": 1698964262,
"thread_id": "thread_uqorHcTs46BZhYMyPn6Mg5gW",
"role": "assistant",
"content": [
{
"type": "image_file",
"image_file": {
"file_id": "file-WsgZPYWAauPuW4uvcgNUGcb"
}
}
]
# ...
}
然后,可以通过将文件 ID 传递给文件 API 来下载文件内容:
代码语言:javascript
复制
content = client.files.with_raw_response.retrieve_content(file.id)
日志
可以检查 Code Interpreter 运行过程中的细节,打印出 input 和 outputs 日志:
代码语言:javascript
复制
run_steps = client.beta.threads.runs.steps.list(
thread_id=thread.id,
run_id=run.id
)
输出内容示例
代码语言:javascript
复制
{
"object": "list",
"data": [
{
"id": "step_DQfPq3JPu8hRKW0ctAraWC9s",
"object": "thread.run.step",
"type": "tool_calls",
"run_id": "run_kme4a442kme4a442",
"thread_id": "thread_34p0sfdas0823smfv",
"status": "completed",
"step_details": {
"type": "tool_calls",
"tool_calls": [
{
"type": "code",
"code": {
"input": "# Calculating 2 + 2\nresult = 2 + 2\nresult",
"outputs": [
{
"type": "logs",
"logs": "4"
}
...
}
完整示例
上传一个包含两列数据的商品销量excel文件(尽量是csv文件后缀,xlsx文件后缀有时候识别失败),让模型分析并画图,示例如下:
代码语言:javascript
复制
def run_assistant_code_interpreter():
# step 1: 上传文件
file = client.files.create(
file=open("data.xlsx", "rb"),
purpose='assistants'
)
# step 2: 创建助手
assistant = client.beta.assistants.create(
name="data analyst",
instructions="You are a personal data analyst. Write and run code to answer data questions.",
tools=[{"type": "code_interpreter"}],
model="gpt-4-1106-preview",
file_ids=[file.id]
)
# step 3: 创建线程
thread = client.beta.threads.create()
# step 4: 添加用户问题
client.beta.threads.messages.create(
thread_id=thread.id,
role="user",
content="帮忙分析最近的商品销量,画一个折线图,并且根据图表内容给出相关的产品建议,生成图表的时候要注意中文需要正常显示。"
)
# step 5: 运行助手
run = client.beta.threads.runs.create(
thread_id=thread.id,
assistant_id=assistant.id,
instructions="生成图表的时候要注意中文需要正常显示。"
)
# step 6: 查询运行结果
while True:
run = client.beta.threads.runs.retrieve(
thread_id=thread.id,
run_id=run.id
)
print("status:", run.status)
if run.status == "completed":
break
if run.status == "failed":
print("failed error:", run.last_error)
time.sleep(2)
# step 7: 展示结果消息列表
messages = client.beta.threads.messages.list(
thread_id=thread.id
)
for msg in reversed(messages.data):
if msg.content[0].type == "text":
print(f"{msg.role}:", msg.content[0].text.value)
elif msg.content[0].type == "image_file":
print(f"{msg.role}: file id is", msg.content[0].image_file.file_id)
# see issue: https://github.com/openai/openai-python/issues/699
file_content = client.files.with_raw_response.retrieve_content(file_id=msg.content[0].image_file.file_id)
with open(f"test_{msg.content[0].image_file.file_id}.png", "wb") as f:
f.write(file_content.content)
else:
print(f"{msg.role}:", msg.content[0])
# step 8(可选): 展示中间步骤
run_steps = client.beta.threads.runs.steps.list(
thread_id=thread.id,
run_id=run.id
)
i = 0
for run_step in reversed(run_steps.data):
if run_step.step_details.type == "tool_calls":
i += 1
for tool_call in run_step.step_details.tool_calls:
print(f"step {i} input<<<<<<<<<<<<<<<:\n", tool_call.code_interpreter.input)
if tool_call.code_interpreter.outputs[0].type == "logs":
print(f"step {i} outputs>>>>>>>>>>>>>>>>>>:\n", tool_call.code_interpreter.outputs[0].logs)
elif tool_call.code_interpreter.outputs[0].type == "image":
print(f"step {i} outputs>>>>>>>>>>>>>>>>>>:\n", tool_call.code_interpreter.outputs[0].image.file_id)
else:
print(f"step {i} outputs>>>>>>>>>>>>>>>>>>:\n", tool_call.code_interpreter.outputs[0])
elif run_step.step_details.type != "message_creation":
print(f"other middle step:", run_step.step_details)
Excel原始数据如下:
| 时间 | 销量 |
| 2023/11/1 | 50 |
| 2023/11/2 | 70 |
| 2023/11/3 | 60 |
| 2023/11/4 | 80 |
| 2023/11/5 | 40 |
| 2023/11/6 | 36 |
| 2023/11/7 | 90 |
| 2023/11/8 | 100 |
| 2023/11/9 | 150 |
输出内容:
代码语言:javascript
复制
user: 帮忙分析最近的商品销量,画一个折线图,并且根据图表内容给出相关的产品建议。
assistant: 首先,我将打开和检查你上传的文件,以了解其中的数据结构,然后我们可以进一步分析商品销量,并尝试绘制折线图来表示数据。接下来,我将根据图表的结果给出一些建议。现在我将打开这个文件。
assistant: 文件已成功读取,数据看起来包含两列:一列是日期("时间"),另一列是对应的销量("销量")。看起来像是每日销量的时间序列数据。接下来,我将使用这些数据来绘制折线图。这将有助于我们更好地理解销量随时间的变化趋势。现在我来绘制这个折线图。
assistant: file id is file-QPltLMyDx4RWUzt59PD72oY9
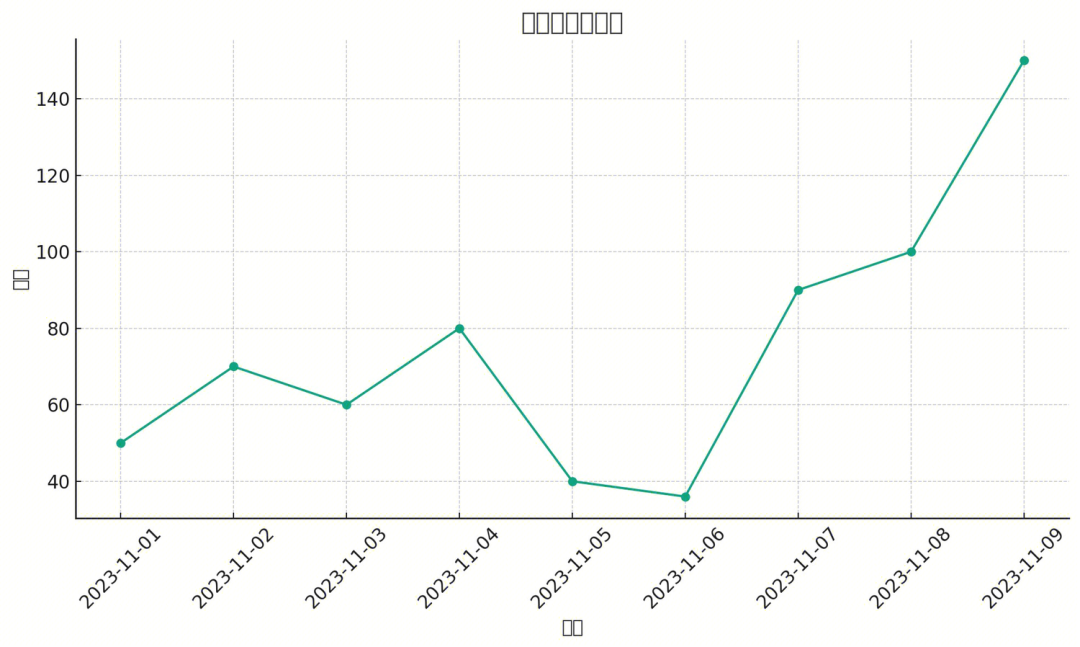
画图时图中的中文经常显示异常,即使在prompt提示要在图中正常显示中文,也没有效果。 在画图结束后,也没有对数据进行总结和建议,这是一个需要关注的地方,应该可以在后续的对话中继续让模型基于历史聊天记录进行分析,此处就不再演示。
中间步骤的输出内容如下,可以查看step 1 ~ step 3的输入和输出过程。
代码语言:javascript
复制
step 1 input<<<<<<<<<<<<<<<:
import pandas as pd
# Load the uploaded file to see its content and structure
file_path = '/mnt/data/file-oxr4e1AhUQcmRScQYlg1wVY9'
# We'll try to read the file with pandas assuming it might be a CSV or Excel file
# If this fails, we might need additional context or information about the file format
# First, let's try to read it as a CSV
try:
sales_data = pd.read_csv(file_path)
except Exception as e:
print(f"Error reading as CSV: {e}")
# Next, we'll try to read it as an Excel file
try:
sales_data = pd.read_excel(file_path)
except Exception as e:
print(f"Error reading as Excel: {e}")
# If successfully read, let's check the first few rows of the file
if 'sales_data' in locals():
preview = sales_data.head()
else:
preview = "Unable to read the file. It may not be a CSV or Excel file, or it could have a different structure."
preview
step 1 outputs>>>>>>>>>>>>>>>>>>:
Error reading as CSV: 'utf-8' codec can't decode byte 0x82 in position 16: invalid start byte
时间 销量
0 2023-11-01 50
1 2023-11-02 70
2 2023-11-03 60
3 2023-11-04 80
4 2023-11-05 40
step 2 input<<<<<<<<<<<<<<<:
# Check the entire dataset for missing values or anomalies
sales_data_info = sales_data.info()
missing_values = sales_data.isnull().sum()
# Preparing data for plotting
# Ensuring the '时间' column is parsed as datetime if it isn't already
sales_data['时间'] = pd.to_datetime(sales_data['时间'])
# Sorting the data according to the '时间' to ensure correct plotting
sales_data_sorted = sales_data.sort_values('时间')
# Displaying data information and missing value count
sales_data_info, missing_values, sales_data_sorted.head()
step 2 outputs>>>>>>>>>>>>>>>>>>:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 9 entries, 0 to 8
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 时间 9 non-null datetime64[ns]
1 销量 9 non-null int64
dtypes: datetime64[ns](1), int64(1)
memory usage: 272.0 bytes
(None,
时间 0
销量 0
dtype: int64,
时间 销量
0 2023-11-01 50
1 2023-11-02 70
2 2023-11-03 60
3 2023-11-04 80
4 2023-11-05 40)
step 3 input<<<<<<<<<<<<<<<:
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
# Configuring matplotlib to display Chinese characters properly
plt.rcParams['font.sans-serif'] = ['SimHei'] # Or another font that supports Chinese
plt.rcParams['axes.unicode_minus'] = False
# Plotting the sales data
plt.figure(figsize=(10, 6))
plt.plot(sales_data_sorted['时间'], sales_data_sorted['销量'], marker='o')
# Formatting the plot
plt.title('商品销量趋势图')
plt.xlabel('时间')
plt.ylabel('销量')
plt.grid(True)
plt.xticks(rotation=45)
plt.gca().xaxis.set_major_locator(mdates.DayLocator(interval=1)) # Ensure every day is marked
plt.gca().xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m-%d'))
# Showing the plot
plt.tight_layout()
plt.show()
step 3 outputs>>>>>>>>>>>>>>>>>>:
file-q2LglNbwgnM7VHc9PjxlgslD
知识检索
检索功能会利用助手模型之外的知识(例如专有产品信息或用户提供的文档)来增强助手。一旦文件上传并传递给助手,OpenAI 将自动对您的文档进行分块,索引和存储嵌入,并实施矢量搜索以检索相关内容以回答用户查询。 retrieval 传入 Assistant 的 tools 参数以启用 Retrieval
代码语言:javascript
复制
assistant = client.beta.assistants.create(
instructions="You are a customer support chatbot. Use your knowledge base to best respond to customer queries.",
model="gpt-4-1106-preview",
tools=[{"type": "retrieval"}]
)
模型根据用户消息决定何时检索内容。助手 API 会自动在两种检索技术之间进行选择:
- 短文档:提示中传递文件内容
- 较长的文档:执行矢量搜索
与 Code Interpreter 类似,文件可以在 Assistant 级别或线程级别传递。其它操作和Code Interpreter 也是类似,参考即可。
完整示例
参考Code Interpreter 的完整示例。
函数调用
与聊天API 类似,助手 API 支持函数调用。函数调用允许您向助手描述函数,并让它智能地返回需要调用的函数及其参数。助手 API 在调用函数时将在 Run 期间暂停执行,您可以提供函数回调的结果以继续执行 Run。
定义函数
创建 Assistant 时定义函数:
代码语言:javascript
复制
assistant = client.beta.assistants.create(
instructions="You are a weather bot. Use the provided functions to answer questions.",
model="gpt-4-1106-preview",
tools=[{
"type": "function",
"function": {
"name": "getCurrentWeather",
"description": "Get the weather in location",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string", "description": "The city and state e.g. San Francisco"},
"unit": {"type": "string", "enum": ["c", "f"]}
},
"required": ["location", "unit"]
}
}
}, {
"type": "function",
"function": {
"name": "getNickname",
"description": "Get the nickname of a city",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string", "description": "The city and state e.g. San Francisco"},
},
"required": ["location"]
}
}
}]
)
读取助手返回的函数信息
当启动助手并触发该函数时,将进入 requires_action 状态,会暂停等待用户提交函数的调用结果,此时读取线程线程中的消息时会返回如下格式的内容:
代码语言:javascript
复制
{
"id": "run_3HV7rrQsagiqZmYynKwEdcxS",
"object": "thread.run",
"assistant_id": "asst_rEEOF3OGMan2ChvEALwTQakP",
"thread_id": "thread_dXgWKGf8Cb7md8p0wKiMDGKc",
"status": "requires_action",
"required_action": {
"type": "submit_tool_outputs",
"submit_tool_outputs": {
"tool_calls": [
{
"id": "call_Vt5AqcWr8QsRTNGv4cDIpsmA",
"type": "function",
"function": {
"name": "getCurrentWeather",
"arguments": "{\"location\":\"San Francisco\"}"
}
},
{
"id": "call_45y0df8230430n34f8saa",
"type": "function",
"function": {
"name": "getNickname",
"arguments": "{\"location\":\"Los Angeles\"}"
}
}
]
}
},
...
提交函数输出
然后根据返回的函数名称和参数值,本地调用函数,并将函数的返回结果提交给助手,来继续运行助手, tool_call_id 以将输出匹配到每个函数调用。
代码语言:javascript
复制
run = client.beta.threads.runs.submit_tool_outputs(
thread_id=thread.id,
run_id=run.id,
tool_outputs=[
{
"tool_call_id": call_ids[0],
"output": "22C",
},
{
"tool_call_id": call_ids[1],
"output": "LA",
},
]
)
完整示例
创建助手并运行函数调用的完整代码示例如下,用例是让模型返回San Francisco and Paris的天气和城市别名,天气函数和别名查询函数均在本地函数,此处也可以是调用其它第三方API,以此来增强模型能力,函数的调用结果需要再次提交给模型进行总结。
代码语言:javascript
复制
def run_assistant_function_call():
# step 1: 创建助手,并添加函数定义
assistant = client.beta.assistants.create(
instructions="You are a weather bot. Use the provided functions to answer questions.",
model="gpt-4-1106-preview",
tools=[{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the weather in location",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string", "description": "The city and state e.g. San Francisco"},
"unit": {"type": "string", "enum": ["c", "f"]}
},
"required": ["location", "unit"]
}
}
}, {
"type": "function",
"function": {
"name": "get_nickname",
"description": "Get the nickname of a city",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string", "description": "The city and state e.g. San Francisco"},
},
"required": ["location"]
}
}
}]
)
# step 2: 创建线程
thread = client.beta.threads.create()
# step 3: 添加问题消息
client.beta.threads.messages.create(
thread_id=thread.id,
role="user",
content="What's the weather and nickname like in San Francisco and Paris?"
)
# step 4: 运行助手
run = client.beta.threads.runs.create(
thread_id=thread.id,
assistant_id=assistant.id
)
# step 5: 本地函数实现,实际情况中可以调用外部函数或接口
# 参数名与 tools声明的名称要一致,不然自动填充参数会失败
def get_current_weather(location: str, unit: str):
if "paris" in location.lower():
return json.dumps({"location": location, "temperature": "10", "unit": unit})
elif "san francisco" in location.lower():
return json.dumps({"location": location, "temperature": "72", "unit": unit})
else:
return json.dumps({"location": location, "temperature": "22", "unit": unit})
def get_nickname(location: str):
if "paris" in location.lower():
return json.dumps({"location": location, "nickname": "City of Light"})
elif "san francisco" in location.lower():
return json.dumps({"location": location, "nickname": "City by the Bay"})
else:
return json.dumps({"location": location, "nickname": "Nice City"})
available_functions = {
"get_current_weather": get_current_weather,
"get_nickname": get_nickname
}
# step 6: 查询结果
while True:
# step 6.1: 查询结果状态
run = client.beta.threads.runs.retrieve(
thread_id=thread.id,
run_id=run.id
)
print("status:", run.status)
# step 6.2 如果状态转为requires_action,则获取GPT初步返回的函数名称和输入
if run.status == "requires_action" and run.required_action.type == "submit_tool_outputs":
tool_calls = run.required_action.submit_tool_outputs.tool_calls
tool_outputs = []
for tool_call in tool_calls:
# step 6.2.1 获取每个函数信息
function_name = tool_call.function.name
function_to_call = available_functions[function_name]
function_args = json.loads(tool_call.function.arguments)
# step 6.2.2 自动填充参数并调用函数
# **function_args会根据function_args字典中的键值对自动填充函数的参数。
function_response = function_to_call(**function_args)
# step 6.2.3 将函数返回结果保存
tool_outputs.append({
"tool_call_id": tool_call.id,
"output": function_response
}
)
# step 6.2.4 将所有函数返回结果提交给GPT,继续运行助手,状态变为in_progress
client.beta.threads.runs.submit_tool_outputs(
thread_id=thread.id,
run_id=run.id,
tool_outputs=tool_outputs
)
if run.status == "completed":
break
time.sleep(2)
# step 7: 展示结果
messages = client.beta.threads.messages.list(
thread_id=thread.id
)
for msg in reversed(messages.data):
if msg.content[0].type == "text":
print(f"{msg.role}:", msg.content[0].text.value)
else:
print(f"{msg.role}:", msg.content[0])
输出的内容如下:
代码语言:javascript
复制
user: What's the weather and nickname like in San Francisco and Paris?
assistant: In San Francisco, the current weather is 72°F, and it is nicknamed the "City by the Bay". In Paris, the current weather is 10°C, and it is known as the "City of Light".
支持的文件
对于 text/ MIME 类型,编码必须是 utf-8 、 utf-16 或 ascii 之一。
收费
1,000 tokens大概是 750 单词。 Token在线计算:https://platform.openai.com/tokenizer
GPT-4 Turbo
| Model | Input | Output |
| gpt-4-1106-preview | 0.03 / 1K tokens | |
| gpt-4-1106-vision-preview | 0.03 / 1K tokens |
GPT-4
| Model | Input | Output |
| gpt-4 | 0.06 / 1K tokens | |
| gpt-4-32k | 0.12 / 1K tokens |
GPT-3.5 Turbo
| Model | Input | Output |
| gpt-3.5-turbo-1106 | 0.0020 / 1K tokens | |
| gpt-3.5-turbo-instruct | 0.0020 / 1K tokens |
Fine-tuning models
| Model | Training | Input usage | Output usage |
| gpt-3.5-turbo | 0.0030 / 1K tokens | $0.0060 / 1K tokens | |
| davinci-002 | 0.0120 / 1K tokens | $0.0120 / 1K tokens | |
| babbage-002 | 0.0016 / 1K tokens | $0.0016 / 1K tokens |
Assistants API
| Tool | Input |
| Code interpreter | $0.03 / session (free until 11/17/2023) |
| Retrieval | $0.20 GB assistant / day (free until 11/17/2023) |
Embedding models
| Model | Usage |
| ada v2 | $0.0001 / 1K tokens |
Base models
| Model | Usage |
| davinci-002 | $0.0020 / 1K tokens |
| babbage-002 | $0.0004 / 1K tokens |
资源分享

大模型AGI学习包


资料目录
- 成长路线图&学习规划
- 配套视频教程
- 实战LLM
- 人工智能比赛资料
- AI人工智能必读书单
- 面试题合集
《人工智能\大模型入门学习大礼包》,可以扫描下方二维码免费领取!

1.成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。
2.视频教程
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,其中一共有21个章节,每个章节都是当前板块的精华浓缩。
3.LLM
大家最喜欢也是最关心的LLM(大语言模型)
《人工智能\大模型入门学习大礼包》,可以扫描下方二维码免费领取!