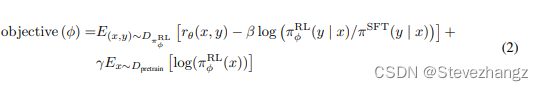本节及后续章节将介绍深度学习中的几种聚类算法,所选方法都在Sklearn库中聚类模块有具体实现。本节为上篇,将介绍几种相对基础的聚类算法,包括K-均值算法和均值漂移算法。
目录
10.1 聚类概述
10.1.1 聚类的种类
10.1.2 Sklearn聚类子模块
10.2 K均值聚类
10.2.1 原理
10.2.2 算法流程
10.2.3 Sklearn库函数说明
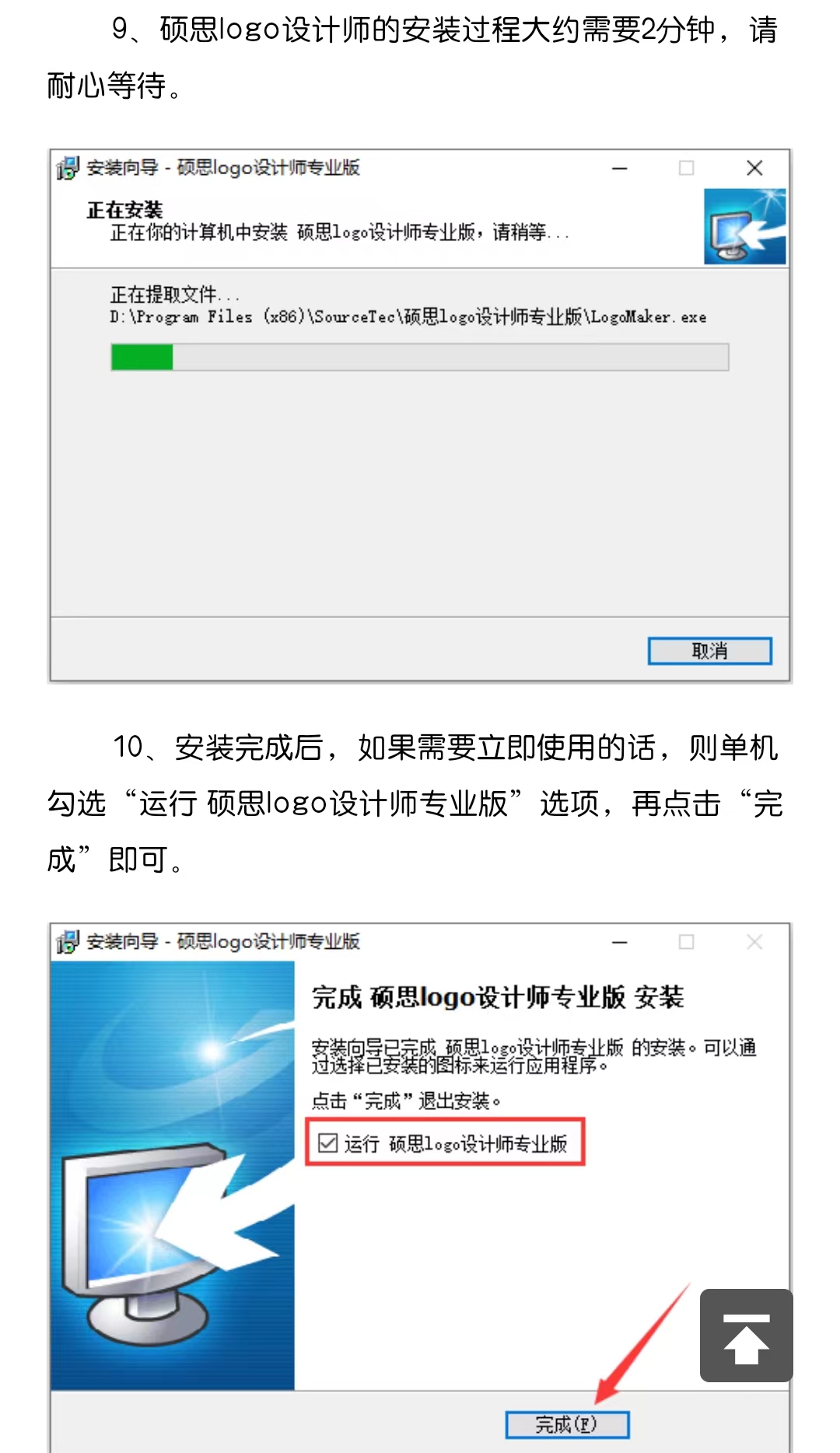
10.2.4 实例
10.2.5 讨论
10.1 聚类概述
聚类(Clustering)是机器学习中的一类无监督学习方法。它是按照某个特定标准(如距离)把一个数据集分割成不同的类或簇(cluster),使得同一个簇内的数据对象的相似性尽可能大,同时不在同一个簇中的数据对象的差异性也尽可能地大。也即聚类后同一类的数据尽可能聚集到一起,不同类数据尽量分离。
10.1.1 聚类的种类
按照策略不同,传统的聚类方法主要可以分为三类:划分式聚类方法(Partition-based Methods)、基于密度的聚类方法(Density-based methods)和层次化聚类方法(Hierarchical Methods)等。
- 划分式聚类方法:该类方法需要事先指定簇类的数目或者聚类中心,通过反复迭代,直至最后达到"簇内的点足够近,簇间的点足够远"的目标。经典的划分式聚类方法有K-means(K-均值)等。
- 基于密度的聚类方法:基于密度的聚类方法可以在有噪音的数据中发现各种形状和各种大小的簇。其核心思想就是先发现密度较高的点,然后把相近的高密度点逐步都连成一片,进而生成各种簇。经典的基于密度的聚类方法有mean-shift(均值漂移)、DBSCAN算法等。
- 层次化聚类方法: 层次聚类算法(Hierarchical clustering)将数据集划分为一层一层的 clusters,后面一层生成的 clusters 基于前面一层的结果。层次聚类算法一般分为两类:Agglomerative 层次聚类:又称自底向上(bottom-up)的层次聚类,以及Divisive 层次聚类: 又称自顶向下(top-down)的层次聚类。经典的基于密度的聚类方法有BIRCH算法等。
除此之外,还有一些高级的方法,如谱聚类(Spectral Clustering ):其主要思想是把所有的数据看做空间中的点,这些点之间可以用边连接起来。距离较远的两个点之间的边权重值较低,而距离较近的两个点之间的边权重值较高,通过对所有数据点组成的图进行切图,让切图后不同的子图间边权重和尽可能的低,而子图内的边权重和尽可能的高,从而达到聚类的目的。
10.1.2 Sklearn聚类子模块
在Sklearn的cluster(聚类)子模块中,提供了上述几种典型的聚类算法,具体函数名称见下表:

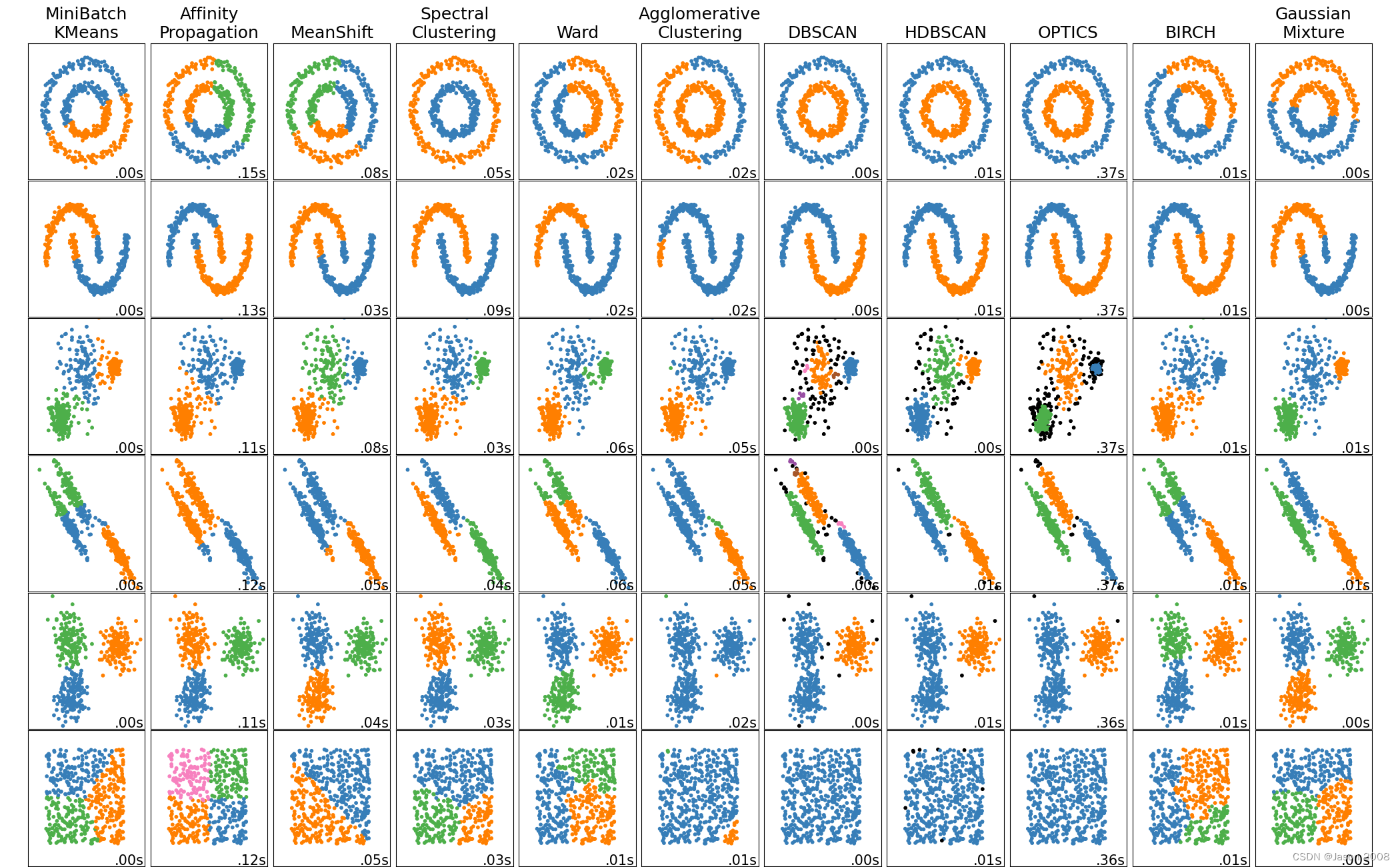
上表列出的是Sklearn实现的几种主要聚类算法,在sklearn_cluster子库中,一共实现了12种聚类方法,官网用表格的形式列出了方法对比。下图是官网给出的使用不同算法对不同种类分别的数据进行聚类的结果对比图,每种算法的性能特点可见一斑。
10.2 K均值聚类
10.2.1 原理
K均值是一种非常基础的划分式聚类算法,它的主要思想是:在给定K值(与类的数目对应)和K个初始类簇中心点的前提下,把每个样本点分到离其最近的类簇中心点所代表的类簇中,所有点分配完毕之后,根据一个类簇内的所有点重新计算该类簇的中心点,然后再迭代的进行分配点和更新类簇中心点的步骤,直至类簇中心点的变化很小,或者达到指定的迭代次数。
10.2.2 算法流程
参考周志华老师的《机器学习》一书中有关K均值的算法流程。如下图所示:

从流程来看K均值算法计算步骤包括两个核心步骤:一是计算每一个样本点到类簇中心的距离;二是根据类簇内的各点计算新的簇类中心。简单而言,就是如何计算各样本点与类心的距离,以及如何根据分类结果更新类心。
10.2.3 Sklearn库函数说明
在SKlearn中,使用sklearn.cluster.KMeans函数,实现K均值算法。
以下是该函数的声明:
看一下histogram函数的声明:
class sklearn.cluster.KMeans(n_clusters=8, *, init='k-means++', n_init='auto', max_iter=300, tol=0.0001, verbose=0, random_state=None, copy_x=True, algorithm='lloyd')
部分参数说明:
- image:输入图像。
- nbins:用于计算直方图的bin的数目。
- source_range:待补充。
- normalize:待补充 。
- channel_axis:待补充。
返回值:
- hist:灰度直方图的数值,数组类型。如果通道数不止一个,则hist是二维数组。
- cluster_centers:Coordinates of cluster centers. If the algorithm stops before fully converging (see tol and max_iter), these will not be consistent with labels_.
- labels:Labels of each point
- inertia:Sum of squared distances of samples to their closest cluster center, weighted by the sample weights if provided.
- n_iter:Number of iterations run.
- n_features_in:Number of features seen during fit.
- feature_names_in_:Names of features seen during fit. Defined only when X has feature names that are all strings.
10.2.4 实例
本节将介绍如何使用Kmean函数实现对IRIS数据集的聚类。
import matplotlib.pyplot as plt
import mpl_toolkits.mplot3d # noqa: F401
import numpy as np
from sklearn import datasets
from sklearn.cluster import KMeans
np.random.seed(5)
iris = datasets.load_iris()
X = iris.data
y = iris.target
estimators = [
("k_means_iris_8", KMeans(n_clusters=8)),
("k_means_iris_3", KMeans(n_clusters=3)),
("k_means_iris_bad_init", KMeans(n_clusters=3, n_init=1, init="random")),
]
fig = plt.figure(figsize=(10, 8))
titles = ["8 clusters", "3 clusters", "3 clusters, bad initialization"]
for idx, ((name, est), title) in enumerate(zip(estimators, titles)):
ax = fig.add_subplot(2, 2, idx + 1, projection="3d", elev=48, azim=134)
est.fit(X)
labels = est.labels_
ax.scatter(X[:, 3], X[:, 0], X[:, 2], c=labels.astype(float), edgecolor="k")
ax.xaxis.set_ticklabels([])
ax.yaxis.set_ticklabels([])
ax.zaxis.set_ticklabels([])
ax.set_xlabel("Petal width")
ax.set_ylabel("Sepal length")
ax.set_zlabel("Petal length")
ax.set_title(title)
# Plot the ground truth
ax = fig.add_subplot(2, 2, 4, projection="3d", elev=48, azim=134)
for name, label in [("Setosa", 0), ("Versicolour", 1), ("Virginica", 2)]:
ax.text3D(
X[y == label, 3].mean(),
X[y == label, 0].mean(),
X[y == label, 2].mean() + 2,
name,
horizontalalignment="center",
bbox=dict(alpha=0.2, edgecolor="w", facecolor="w"),
)
ax.scatter(X[:, 3], X[:, 0], X[:, 2], c=y, edgecolor="k")
ax.xaxis.set_ticklabels([])
ax.yaxis.set_ticklabels([])
ax.zaxis.set_ticklabels([])
ax.set_xlabel("Petal width")
ax.set_ylabel("Sepal length")
ax.set_zlabel("Petal length")
ax.set_title("Ground Truth")
plt.subplots_adjust(wspace=0.25, hspace=0.25)
plt.show()K-means Clustering — scikit-learn 1.5.0 documentation
10.2.5 讨论
K均值算法比较简单,但有几个方面需要注意。
- 必须提前确定K的取值
- 必须实现确定K个初始类簇中心点初始值。目前最常用的方法是随机产生数据大小范围内的K个点作为初始的簇类中心点。