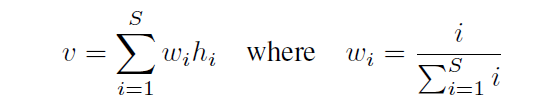论文标题:
Self-Supervised Geometry-Guided Initialization for Robust Monocular Visual Odometry
论文作者:
Takayuki Kanai, Igor Vasiljevic, Vitor Guizilini, Kazuhiro Shintani
导读:
本文提出了一种用于单目视觉里程计的自监督几何引导初始化方法(SG-Init),旨在提高自主系统中的鲁棒性和准确性,有效解决了动态环境和大运动场景下的视觉SLAM问题。作者不仅诊断了现有方法的不足,还提出了SG-Init方案,显著提升了在复杂实际环境中的定位精度和鲁棒性(该研究将在文章正式出版后发布相关代码及预训练模型)。©️【深蓝AI】编译
1. 摘要
单目视觉里程计是各种自主系统中的一项关键技术。相对于传统的基于特征的方法,由于光照不足、纹理不足、运动大等原因而失败,基于学习的SLAM方法利用迭代密集束调整来解决这些失败情况,并在各种真实环境中实现鲁棒准确定位,而不依赖于特定领域的训练数据。尽管如此,基于学习的SLAM仍然在涉及大运动和动态对象的场景中挣扎。该研究通过分析户外测试中的主要故障案例,指出了基于学习的SLAM模型(DROID-SLAM)的主要缺陷,并揭示了其优化过程中存在的不足,并再此基础上提出使用自监督先验,利用冻结的大规模预训练的单目深度估计来初始化密集束调整过程,从而在不需要微调SLAM主干的情况下实现鲁棒视觉里程计。该方法在KITTI与DDAD测试中都有显著的改进。
本文的主要贡献如下:
●SG-Init方法提出:提出了一种新颖的初始化策略,名为Self-Supervised Geometry-Guided Initialization(SG-Init),用于增强单目视觉里程计的鲁棒性;
●自监督学习结合zero-shot深度估计:利用自监督学习的原则与大规模预训练的zero-shot深度估计器相结合,来初始化密集的束调整过程,从而提升视觉里程计的性能;
●无需微调SLAM主干:所提出的方法不需要对SLAM系统的主干网络进行微调,即可实现准确的轨迹估计,这一点对于通用性和实用性至关重要;
●深度和自我运动的联合优化:通过同时优化深度估计和自我运动估计,SG-Init能够提供更加稳定和准确的初始化,这对于后续的迭代优化过程至关重要。
2. SG-Init核心介绍
SG-Init是一种通过自监督几何模型初始化基于学习的单目SLAM的方法,以增强迭代深度和姿态优化的鲁棒性。SG-Init结合于DROID-SLAM,使用的自监督深度和自运动学习,以促进稠密束调整。其完整流程如图1所示。从自监督学习中学习到的DepthNet和PoseNet分别为光流校正估计器(UpdateModule)和光流校正层(DBA)提供初始猜想,并结合本构函数k对目标变量进行递归更新,得到最终输出。

图1|SG-Init流程图©️【深蓝AI】编译
2.1 密集束调整与DROID-SLAM
DROID-SLAM是一种视觉SLAM方法,通过计算密集光流图,并利用估计的流量递归地获得逆深度( d d d)和相机姿态( G G G)。给定共享共可见区域的一对图像 ( I i , I j ) (I_i,I_j) (Ii,Ij),由神经网络(参数化 θ \theta θ)建模的学习流量更新器预测光流估计 r i j ( k ) r_{ij}(k) rij(k)对当前估计流量 p i j ( k ) p_{ij}(k) pij(k)的修正,如下式所示:
r i j ( k ) = UpdateModule θ ( I i , I j , G ( k ) , d ( k ) ∣ K ) \mathbf{r}_{ij}(k)=\text{UpdateModule}_\theta(I_i,I_j,\mathbf{G}(k),\mathbf{d}(k)|\mathbf{K}) rij(k)=UpdateModuleθ(Ii,Ij,G(k),d(k)∣K)
其中, K K K是用于重投影操作的相机内参模型, k k k表示循环神经网络模型的迭代步长。为了简化,后面省略了步长 k k k。将获取的稠密光流 p i j ∗ = r i j + p i j \mathbf{p}_{ij}^{*}=\mathbf{r}_{ij}+\mathbf{p}_{ij} pij∗=rij+pij代入密集束调整层,使以下代价函数最小化:
E ( G ′ , d ′ ) = ∑ ( i , j ) ∈ E ∥ p i j ∗ − Π c ( G i j ′ ∘ Π c − 1 ( p i , d i ′ ) ) ∥ Σ i j 2 E(\mathbf{G}',\mathbf{d}')=\sum_{(i,j)\in\mathcal{E}}\left\|\mathbf{p}_{ij}^*-\Pi_c(\mathbf{G}'_{ij}\circ\Pi_c^{-1}(\mathbf{p}_i,\mathbf{d}'_i))\right\|_{\Sigma_{ij}}^2 E(G′,d′)=(i,j)∈E∑ pij∗−Πc(Gij′∘Πc−1(pi,di′)) Σij2
其中索引 ( i , j ) ∈ E (i, j)∈\mathcal{E} (i,j)∈E描述共视关键帧对, G i j ′ \mathbf{G}_{ij}^{\prime} Gij′给出 G j ′ ∘ G i ′ − 1 \mathbf{G}_j^{\prime}\circ\mathbf{G}_i^{\prime-1} Gj′∘Gi′−1计算得到的相对摄像机变换, ∥ ⋅ ∥ Σ \left\|\cdot\right\|_{\Sigma} ∥⋅∥Σ为马氏距离, w i j w_{ij} wij是用于捆绑调整过程的权重,这些权重是从UpdateModule的另一个输出层预测的,与 r i j r_{ij} rij同时生成。
2.2 深度获取与自我运动初始化器
深度和自我运动估计器的自监督学习被表述为通过比较两帧来同时优化深度和姿态神经网络(以下简称PoseNet和DepthNet)。下面的代价函数将学习信号传播到整个架构:
L p ( I t , I ^ t ) = α 1 − S S I M ( I t , I ^ t ) 2 + ( 1 − α ) ∥ I t − I ^ t ∥ \mathcal{L}_{p}(I_{t},\hat{I}_{t})=\alpha \frac{1-\mathrm{SSIM}(I_{t},\hat{I}_{t})}{2}+(1-\alpha) \|I_{t}-\hat{I}_{t}\| Lp(It,I^t)=α21−SSIM(It,I^t)+(1−α)∥It−I^t∥
其中, I t I_t It是目标图像;是通过光度扭曲操作合成的图像,该操作由以下四个部分组成:
1)来自DepthNet的预测深度;
2)来自PoseNet的帧间运动,表示从目标帧 ID t \text{ID t} ID t到上下文帧 ID c \text{ID c} ID c的相机运动;
3)上下文图像 I c I_c Ic;
4)预校准的相机内参 ( K K K)。超参数 α \alpha α定义了SSIM和损失项 L 1 L_1 L1的混合比。由于公式在假设环境中无动态变化、亮度变化、遮挡等情况下最小化 I t I_t It和 I c I_c Ic之间的光度误差,因此在学习过程中仍然存在不适定性。我们通过利用大规模预训练模型的zero-shot能力,同时确保DepthNet和PoseNet之间的尺度一致性来应对这一问题。
2.3 用于先验学习的zero-shot深度引导
zero-shot单目深度估计器通常是一种计算代价高但功能强大的模型,损失函数描述如下:
L = α L P M + β L G + γ L N + δ L C D R + ϵ L E R N L=\alpha L_{P}^{M}+\beta L_{G}+\gamma L_{N}+\delta L_{\mathrm{CDR}}+\epsilon L_{\mathrm{ERN}} L=αLPM+βLG+γLN+δLCDR+ϵLERN
其中,带有下标的 L L L是自监督方案的损失项, α \alpha α到 ϵ ϵ ϵ是用于权衡优化的常数: L p M L_p^M LpM是 L p L_p Lp的扩展版本,其中深度不一致像素被掩盖在深度预测中; L G L_G LG是深度不一致像素的惩罚; L N L_N LN、 L C D R L_{CDR} LCDR和 L E R N L_{ERN} LERN分别表示学习深度估计器与zero-shot单目深度估计器的伪深度标签之间的差异,涉及表面法线(N)、深度排名(CDR),特别是动态区域,以及边缘区域周围的表面法线(ERN),其中主要关注最后两个损失项。尽管在这些边缘和动态区域上进行像素级深度预测很难通过自监督学习获得,但精确几何的观察能够提供额外的有效信息,以实现更准确的视觉里程计。此外,可靠的几何信息被带入深度估计器的训练中,保证了帧间一致性,而这种一致性对于当前的zero-shot模型是难以获得的。同时,在这种优化中还获取了PoseNet,因此密集束调整可以由PoseNet和DepthNet完全初始化。
2.4 自监督几何引导初始化
通过结合zero-shot模型的第一阶段自监督获得深度和姿态先验,这两个网络会同时估计它们,以在第二阶段稳定密集束调整层。为实现这一点,深度估计被简单地取反以输入到更新模块(UpdateModule)。另一方面,相机姿态 G ∣ t = τ ∈ G G|_{t=\tau}\in\mathbf{G} G∣t=τ∈G通过从相机位置原点 G ∣ t = T G|_{t=T} G∣t=T链接PoseNet输出的相对姿态估计 X ^ t → t + 1 \hat{\mathbf{X}}^{t\to t+1} X^t→t+1进行计算,如下所示:
G ∣ t = τ = X ^ τ − 1 → τ ⋯ X ^ T → T + 1 ∘ G ∣ t = T G|_{t=\tau}=\hat{\mathbf{X}}^{\tau{-}1\to\tau}\cdots\hat{\mathbf{X}}^{T\to T+1}\circ G|_{t=T} G∣t=τ=X^τ−1→τ⋯X^T→T+1∘G∣t=T
在这个设置中,一个单位矩阵被赋值为 G ∣ t = 0 G|_{t=0} G∣t=0。最后,将得到的深度和姿态预测输入到UpdateModule 和密集束调整层中。尽管在每一帧中提供预测的深度输入,但当关键帧的累积数量达到给定阈值(在图1中称为“初始BA”)时,我们仅为首次束调整提供PoseNet的姿态预测。
3. 实验
该研究使用evo中计算的轨迹均方根误差(RMSE),使用的指标在仅应用尺度版本时称为ATE,在同时应用正确尺度和对齐版本时称为ATE†。在深度估计任务中,除非另有说明,否则展示中值缩放应用结果,并且没有后处理。从理论上讲,任意的zero-shot模型选择均可,但其仍可能会显示轻微的性能差异。该研究报告了两种模型的实验结果:LeReS引导学习(描述为(L)),Omnidata V2引导学习(O)。该研究进行实验的数据集有DDAD和KITTI。
3.1 DDAD数据集表现

表1|DDAD数据集轨迹估计实验结果©️【深蓝AI】编译
表1总结了DDAD序列的轨迹估计结果。利用自监督初始化(Init.)和zero-shot制导(ZG),相对于现成的DROID-SLAM和无zero-shot深度制导(注意为N/A)显着提高了估计性能,尽管它们都依赖于相同的学习SLAM主干。请注意,ORB-SLAM3具有估计的随机性;因此,选择五次试验中的最小误差作为每个序列的分数,然后取平均值以得到表中所述的结果。在所有序列中均未出现故障的情况下,我们的方案显示出最好的精度。
图2说明了通过zero-shot制导提高深度精度的好处:在观察动态移动车辆的情况下(seq:000187),传统特征提取方法提取关键帧容易失败的情况下(seq:000161),以及需要通过急转弯估计大光流的情况下(seq:000198),zero-shot制导的贡献很大。

图2|DDAD数据集上视觉里程计方法的输入/输出©️【深蓝AI】编译
从上述结果看,仅提供zero-shot深度估计用于初始化即可提高DROID-SLAM的性能。因此,我们将我们的提案与几种zero-shot深度估计模型进行比较,但仅有深度就足够了吗?在表2中,实验结果显示了深度和姿态初始化的重要性,同时提供两者的性能显著更好。该研究认为,仅靠精确的深度输入进行初始化是不足的,结合共享尺度的姿态输入能显著提高性能,因为密集束调整本质上是光流的迭代优化:即深度和姿态的结合。

表2|不同深度初始化器对轨迹估计性能的影响(DDAD数据集;缩放表示:MD中位数缩放;SS移位缩放)©️【深蓝AI】编译
为了量化PoseNet对初始化的贡献,将PoseNet消融并将其与姿态估计方法的变体进行比较。表3显示了轨迹估计的结果以及与深度估计性能的关系。其中,SG-Init+D为“SG-Init + DROID”,SG-Init+D†为SG-Init+D对PoseNet的消去(PoseNet描述了通过相对姿态估计链化获得的自监督学习的自我运动估计器的vanilla输出)。结果表明:
1)在不考虑深度精度的情况下,PoseNet初始化束平差可以提高轨迹估计精度;
2)使用更强深度估计量的模型可以提高轨迹估计精度。

表3|DDAD上的PoseNet消融实验(ZG表示自监督阶段的伪监督模型。SG-INIT+D表示本研究方案,版本“无PoseNet初始化”描述为SG-INIT+D †,而PoseNet是自运动估计器的直接结果)©️【深蓝AI】编译
3.2 KITTI数据集表现

表4|KITTI数据集轨迹估计实验结果©️【深蓝AI】编译
本研究的zero-shot深度指导方法在强基线方法上取得了较好结果。然而,与DDAD实验相反,轨迹估计的准确性并不完全遵循深度估计准确性的顺序,如表5所示。我们假设这是由于深度图中的误预测造成的,且该误预测无法进行地面实况评估。由于评估区域仅限于LiDAR记录的范围及其周围区域,无法完全量化深度图上所有像素的误差。定性结果表明,非评估区域的深度(图5)的影响:与“无零样本深度指导”模型相比,具有零样本指导的模型在天空和树木上的伪影较少。由于所有像素都被输入到稠密束调整模块,该区域可能会成为优化过程中的噪声。

表5|使用ResNet18s在KITTI标注测试集上的深度估计结果(对于真实标签,使用的是点云的标注版本)©️【深蓝AI】编译

图3|SG-Init的学习深度输入,使用zero-shot模型作为伪深度指导(上方显示的是seq:09的结果,下方是seq:10的结果。尽管在数量上N/A指导模型比“Omnidata V2”指导模型更准确,但前者显示出一些伪影,特别是在天空区域)©️【深蓝AI】编译
3.3 SLAM骨干网络之间的性能差异
本研究探究了所提出的初始化是否可以独立于主干所学的内容来增强所学的SLAM。在比较中,选择了VKITTI2学习后的主干。表6表明,无论使用何种数据集进行微调,都证明了本研究所提算法的有效性。此外,结果还表现出本研究在初始化所做贡献优于对主干微调的贡献,为此,与其在模拟真实环境领域的合成数据上进行微调,不如在这个基于学习的方案中高效利用大规模预训练的骨干网络更为可取。

表6|本研究方法在各种SLAM骨干网络上的改进情况©️【深蓝AI】编译
4. 结论
本研究实现效果如图4所示,探讨了基于学习的基于密集束调整的SLAM的优缺点,并评估了其在驾驶场景中的鲁棒性和泛化潜力。通过对故障案例的分析,研究发现,在这种情况下,大光流的估计和动态目标的正确处理对于准确估计轨迹至关重要。本研究提出了一种新的初始化策略SG-Init,它利用自监督深度和自我运动学习原理结合大规模预训练深度估计器来初始化密集束调整。并在真实的户外驾驶环境中对所提算法进行了全面分析,验证了其无需对SLAM主干进行任何进一步的训练,通过本研究的初始化操作使轨迹估计能够与在域内数据上训练的最先进的SLAM主干相竞争。

图4|SG-Init效果图©️【深蓝AI】编译
编译|唐僧洗头用飘柔
审核|Los
移步公众号【深蓝AI】,第一时间获取自动驾驶、人工智能与机器人行业最新最前沿论文和科技动态。