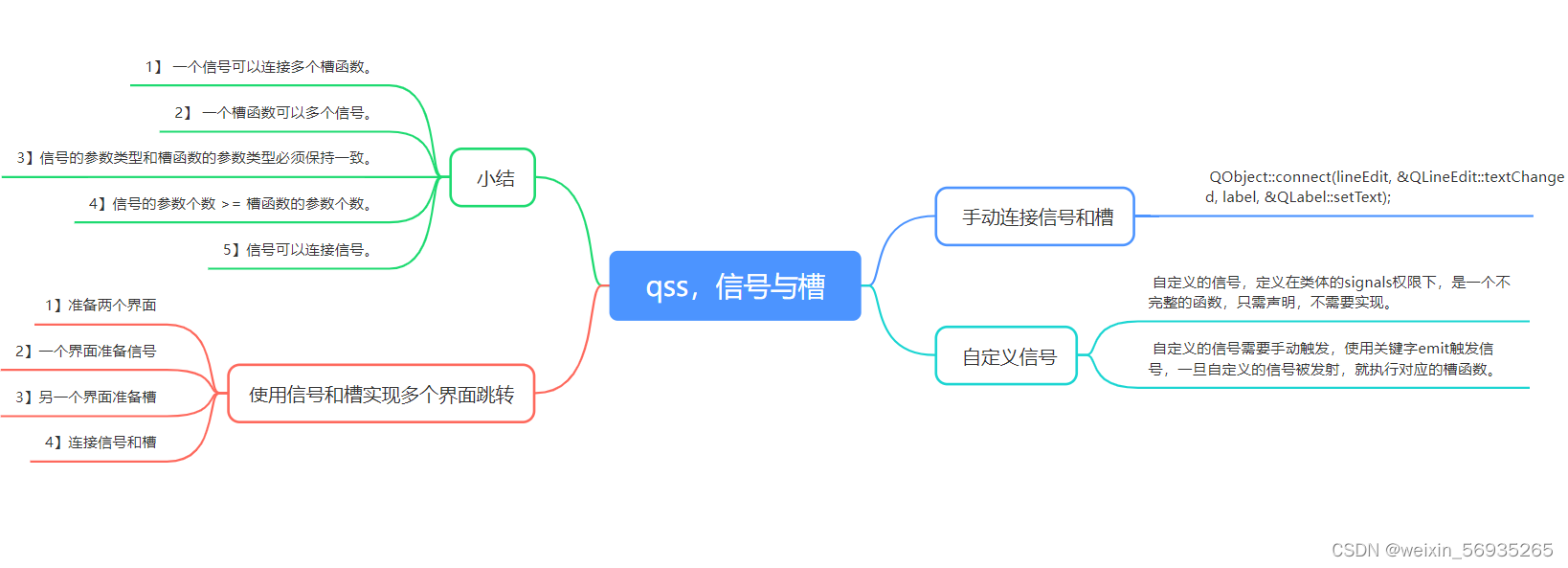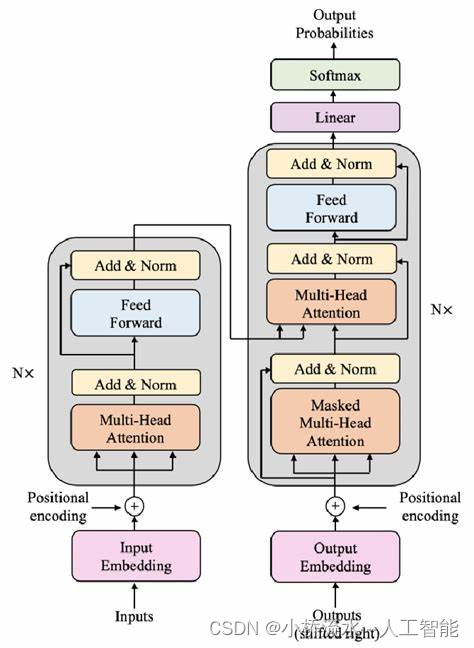
自注意力机制已经在捕捉序列内部依赖关系方面表现出色,但是引入多头自注意力机制的主要原因是为了进一步提升模型的表达能力和性能。这种机制的设计和应用基于以下几个关键考虑:
1. 增加模型的复杂性和多样性
单一的自注意力机制虽然有效,但在处理复杂数据时可能存在一定的局限性。多头自注意力通过在同一层内并行使用多个自注意力模块(即“头”),每个头从不同的表示子空间学习信息,这样可以从多个抽象层次捕获数据的内部特征。这种多角度学习使得模型能更全面地理解数据。
2. 提升模型的关注范围
在传统的自注意力机制中,单个注意力集中可能只能捕捉到一部分相关特征,例如,某些特征可能是局部的,而其他特征可能跨越长距离。多头自注意力允许模型在不同的“头”中关注序列的不同部分,比如一个头专注于近距离的交互,而另一个头可能捕捉更长范围的依赖关系。这种能力对于复杂问题,如风电机组故障诊断中的模式识别尤为重要,因为故障征兆可能在数据中的多个维度和尺度上表现出来。
3. 改善信息整合能力
每个头学习到的表示可以视为捕获输入数据的不同方面或特征,多头自注意力结构通过聚合这些多样化的表示,可以获得更加丰富和全面的输出表示。这有助于模型在进行决策或分类时,综合多维度的信息,从而提高准确性和鲁棒性。
4. 优化学习动态
使用多头自注意力机制还可以帮助模型在训练过程中更有效地进行梯度传播和参数更新。不同的头可能会在学习过程中展现出不同的学习动态,这种多样性有助于避免模型陷入局部最优,并增强模型的泛化能力。
结论
综上所述,多头自注意力机制的引入是为了使模型能够更全面、更有效地处理各种复杂的数据关系,尤其是在风电机组故障诊断这类要求高度准确性和复杂数据处理能力的应用中。通过并行处理多种注意力动态,这种机制不仅提高了模型的表达能力,还增强了其对不同数据模式的适应性和解释性。