上篇分享了如何从0到1搭建一套语音交互系统。
其中,大语言模型(LLM)是实现智能对话的关键所在。
很多小伙伴反应:本地部署 LLM 还是有门槛,本文将系统盘点:目前市面上都有哪些可以免费调用的云端API?
方便大家开发基于LLM的应用,快速实现自己的想法,让创意起飞~🚀
什么是 LLM?
相信看到这里的你,对 LLM 已经有所了解了,考虑到还有不了解 LLM 的小伙伴,猴哥再啰嗦几句。
LLM,也就是大型语言模型,就像是一个超级学霸,它通过阅读海量的书本、文章、对话等资料,学习到了人类语言的很多规则和习惯。这个学霸不仅学得快,而且还特别聪明,能够用学到的知识来回答问题、写文章,把它当成你的全能小助手完全没问题。
随着2023年 OpenAI 的 ChatGPT 横空出世,海内外各大 LLM 厂商都推出了自家的大语言模型,与此同时,所有厂商都提供了 API 访问,让开发者可以轻松使用自家的LLM,开发出更多有创意的应用。
不过,绝大部分 API 都是需要付费的。对于绝大部分 API 而言,一般都采用按 token 收费,token 可以简单理解为LLM处理的字数,对于中文而言,token 和字数的换算比例约为1:1.6。
对于个人开发者和初创企业而言,想简单进行 demo 测试,验证产品可行性,如果能有一些免费的 API,自然是再香不过的了。
免费调用的LLM API
1. GPT 系列
GPT 系列是 LLM 界当仁不让的大网红,也是 OpenAI 的印钞机,如果你想调用官网提供的 API,那付费是免不了的。
接下来,猴哥将介绍三款免费的 API,让你直达GPT。
尽管都有一些次数限制,不过对于简单做个小demo,完全够用了。
1.1 GPT_API_free
基本信息:
地址:https://github.com/chatanywhere/GPT_API_free
限制:
- 免费 API 100请求/天/IP&Key调用频率(gpt和embedding分开计算,各100次)
- 免费 API 限制使用gpt-3.5-turbo,gpt-4 和 embeddings模型
使用步骤:
- 申请领取内测免费API Key (需要你的 github 账号授权)
![[图片]](https://img-blog.csdnimg.cn/direct/53a6a590db174f158440e6fcb6d3f08d.png)
- 保存 API key:sk-CsUwFWsagU5IwyAcZhPBKs3ks1TcOlLUXgoBl9FoXB7KKW
- 保存代理 url:下面二选一
- https://api.chatanywhere.tech (国内中转,延时更低,host1和host2二选一)
- https://api.chatanywhere.com.cn (国内中转,延时更低,host1和host2二选一)
- 调用测试:
- 模型列表:查看支持哪些模型
import os
import requests
from openai import OpenAI
api_key = os.getenv("OPENAI_API_KEY", "sk-CsUwFWsagU5IwyAcZhPBKs3ks1TcOlLUXgoBl9FoXB7KKW")
base_urls = ["https://api.chatanywhere.tech/v1", "https://api.chatanywhere.com.cn/v1"]
client = OpenAI(api_key=api_key, base_url=base_urls[0])
def get_model_list():
url = base_urls[0] + "/models"
headers = {
'Authorization': f'Bearer {api_key}',
'User-Agent': 'Apifox/1.0.0 (https://apifox.com)'
}
response = requests.request("GET", url, headers=headers)
data = response.json()['data']
models = [model['id'] for model in data]
print(models)
- 多轮对话生成:
因为免费 API 无法使用 “text-davinci-003” 模型,所以无法调用文本补全方法:client.completions.create
# 非流式响应
def chat(model="gpt-3.5-turbo", messages=[], temperature=0.7):
completion = client.chat.completions.create(
model=model,
messages=messages,
temperature=temperature,
)
return completion.choices[0].message.content
# 流式响应
def chat_stream(model="gpt-3.5-turbo", messages=[], temperature=0.7):
completion = client.chat.completions.create(
model=model,
messages=messages,
temperature=temperature,
stream=True,
)
for chunk in completion:
if chunk.choices[0].delta.content is not None:
yield chunk.choices[0].delta.content
if __name__ == '__main__':
messages = [
{'role': 'system', 'content': '你是百科全书'}, # 人设提示词,可以不添加
{'role': 'user','content': '鲁迅和周树人的关系'},
]
res = chat(model="gpt-3.5-turbo", messages=messages)
print(res)
for text in chat_stream(model="gpt-3.5-turbo", messages=messages):
print(text, end='')
- 文本向量
def get_embedding(model="text-embedding-ada-002", input_text="hello world"):
embedding = client.embeddings.create(
model=model,
input=input_text,
)
return embedding.data[0].embedding
- 更多参数设置,可查看api文档:https://chatanywhere.apifox.cn/,或者 OpenAI官方文档
1.2 GPT4free
基本信息:
地址:https://github.com/xtekky/gpt4free
简介:可以直接安装python调用,也可以docker部署到本地。很容易封IP,不建议使用。
使用步骤:
- 安装最新版的g4f:pip install -U g4f
- 调用测试:
- 对话生成:
from g4f.client import Client
client = Client()
def text_generation(model="gpt-3.5-turbo", messages=[], temperature=0.7):
completion = client.chat.completions.create(
model=model,
messages=messages,
temperature=temperature,
)
return completion.choices[0].message.content
if __name__ == '__main__':
messages = [{'role': 'user','content': '你是谁'}]
print(text_generation(messages=messages))
1.3 Coze
基本信息:
API文档:https://www.coze.com/docs/developer_guides/coze_api_overview?_lang=zh
简介:海外版Coze,封装了对 GPT 的调用。(PS:不了解 Coze 的小伙伴,可以看这里:一文搞清:Coze、扣子和GPTs的区别)
限制:每个注册用户只有 100 次免费调用额度
调用示例:
import requests
import json
url = "https://api.coze.com/open_api/v2/chat"
headers = {
'Authorization': 'Bearer your_token',
'Content-Type': 'application/json',
'Accept': '*/*',
'Host': 'api.coze.com',
'Connection': 'keep-alive'
}
query =""""
你了解遥远的救世主这本书么,结合搜索结果来回答
"""
# user 标识用户 conversation_id 标识哪一次会话 chat_history 用于输入历史对话
data = {
"bot_id": "7370949251666477072",
"user": "0",
"conversation_id": "123",
"query": query,
"stream": False,}
response = requests.post(url, headers=headers, data=json.dumps(data))
print(response.text)
2. LLaMA3-70B
基本信息:
地址:https://build.nvidia.com/explore/discover#llama3-70b
限制:每个注册用户只有 1000 次免费调用额度
使用步骤:
由于和OpenAI API类似,参考 GPT_API_free 使用即可,下面给出一个调用示例:
from openai import OpenAI
client = OpenAI(
base_url = "https://integrate.api.nvidia.com/v1",
api_key = "$API_KEY_REQUIRED"
)
completion = client.chat.completions.create(
model="meta/llama3-70b-instruct",
messages=[{"role":"user","content":"xxx"}],
temperature=0.5,
top_p=1,
max_tokens=1024,
stream=True
)
for chunk in completion:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="")
3. DeepSeek
基本信息:
API 文档:https://platform.deepseek.com/api-docs/zh-cn/
限制:新注册用户,有免费额度,一个月有效期
使用步骤:
和OpenAI API类似,参考 GPT_API_free 使用即可
4. Kimi
基本信息:
API 文档:Moonshot AI - 开放平台
API Key:https://platform.moonshot.cn/console/api-keys
限制:
- 新注册有免费额度,领取到 15 元的 token 的试用量
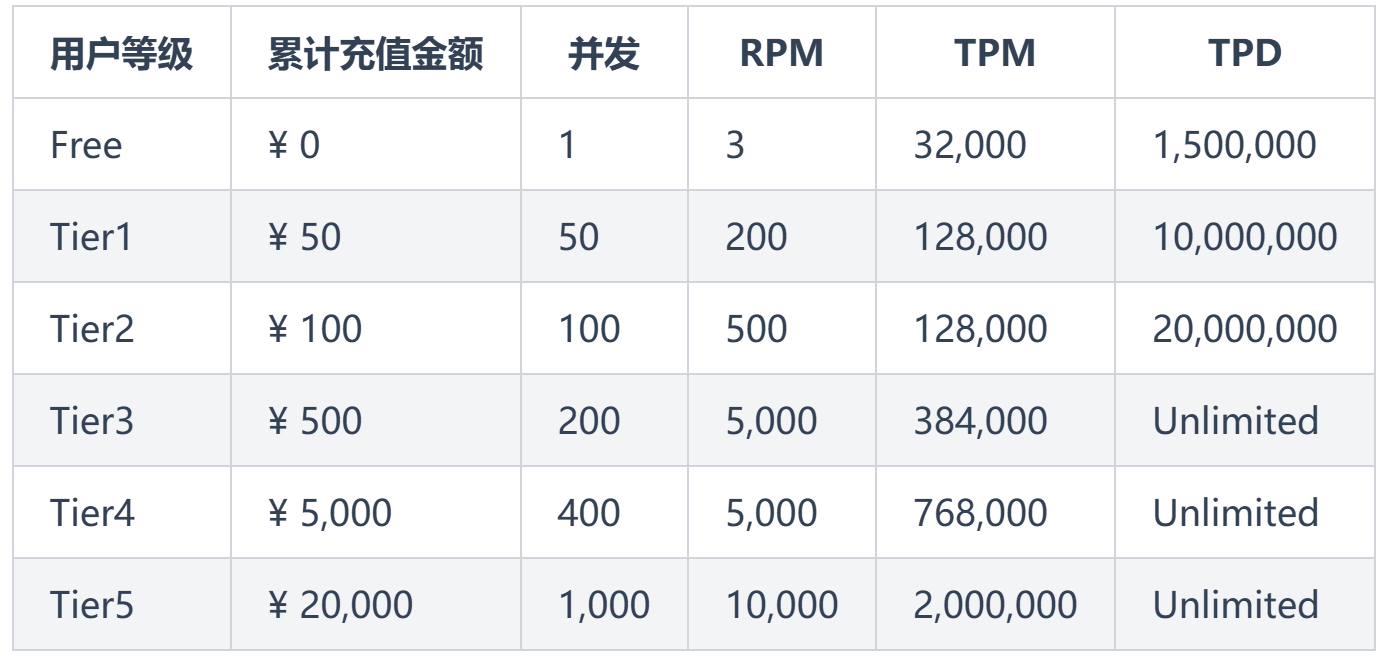
- 速率限制:4种方式:并发、RPM(每分钟请求数)、TPM(每分钟 Token 数)、TPD(每天 Token 数)其中任何一种选项达到,立即执行限制。
支持的模型:
- moonshot-v1-8k: 它是一个长度为 8k 的模型,适用于生成短文本。
- moonshot-v1-32k: 它是一个长度为 32k 的模型,适用于生成长文本。
- moonshot-v1-128k: 它是一个长度为 128k 的模型,适用于生成超长文本。
使用步骤:
和OpenAI API类似,参考 GPT_API_free 使用即可
调用示例:
- 对话生成接口:
from openai import OpenAI
client = OpenAI(
api_key = "$MOONSHOT_API_KEY",
base_url = "https://api.moonshot.cn/v1",
)
completion = client.chat.completions.create(
model = "moonshot-v1-8k",
messages = [
{"role": "system", "content": "你是 Kimi,由 Moonshot AI 提供的人工智能助手。"},
{"role": "user", "content": "你好,我叫李雷,1+1等于多少?"}
],
temperature = 0.3,
)
print(completion.choices[0].message.content)
- 文件相关(文件内容抽取/文件存储)接口:限时免费
注:单个用户最多只能上传 1000 个文件,单文件不超过 100MB,同时所有已上传的文件总和不超过 10G 容量。如果您要抽取更多文件,需要先删除一部分不再需要的文件。
# 文档读取
from pathlib import Path
from openai import OpenAI
client = OpenAI(
api_key = "$MOONSHOT_API_KEY",
base_url = "https://api.moonshot.cn/v1",
)
# xlnet.pdf 是一个示例文件, 支持 pdf, doc 以及图片等格式, 对于图片和 pdf 文件,提供 ocr 相关能力
file_object = client.files.create(file=Path("xlnet.pdf"), purpose="file-extract")
# 获取结果
file_content = client.files.content(file_id=file_object.id).text
# 把它放进对话请求中
messages = [
{
"role": "system",
"content": "你是 Kimi,由 Moonshot AI 提供的人工智能助手,你更擅长中文和英文的对话。",
},
{
"role": "system",
"content": file_content,
},
{"role": "user", "content": "请简单介绍 xlnet.pdf 讲了啥"},
]
# 然后调用 chat-completion, 获取 Kimi 的回答
completion = client.chat.completions.create(
model="moonshot-v1-32k",
messages=messages,
temperature=0.3,
)
print(completion.choices[0].message)
# 列出文件列表
file_list = client.files.list()
for file in file_list.data:
print(file) # 查看每个文件的信息
# 删除
client.files.delete(file_id=file_id)
# 获取指定文件信息
client.files.retrieve(file_id=file_id)
# FileObject(
# id='clg681objj8g9m7n4je0',
# bytes=761790,
# created_at=1700815879,
# filename='xlnet.pdf',
# object='file',
# purpose='file-extract',
# status='ok', status_details='') # status 如果为 error 则抽取失败
5. ChatGLM
基本信息:
API 文档:https://open.bigmodel.cn/dev/api#overview
API Key:https://open.bigmodel.cn/overview
支持的模型:
- 通用大模型:glm-4, glm-4v, glm-3-turbo
- 图像大模型:cogview-3
- 向量模型:embedding-2
限制:新注册有免费额度,领取到 18 元的 token 的试用量
使用步骤:
- 安装:
# 安装最新版,支持 GLM-4、GLM-3-Turbo,支持System Prompt、FunctionCall、Retrieval、Web_Search等新功能
pip install --upgrade zhipuai
调用示例:
- 官方 SDK 调用:
from zhipuai import ZhipuAI
client = ZhipuAI(api_key="") # 请填写您自己的APIKey
# 同步调用 - 直接返回结果
response = client.chat.completions.create(
model="glm-4", # 填写需要调用的模型名称
messages=[
{"role": "system", "content": "你是一个乐于解答各种问题的助手。"},
{"role": "user", "content": "你好!你叫什么名字"},
],
stream=False,
)
print(response.choices[0].message)
# 异步调用 - 调用后会立即返回一个任务 ID,然后用任务ID查询调用结果
response = client.chat.asyncCompletions.create(
model="glm-4", # 填写需要调用的模型名称
messages=[
{
"role": "user",
"content": "请你作为童话故事大王,写一篇短篇童话故事,故事的主题是要永远保持一颗善良的心,要能够激发儿童的学习兴趣和想象力,同时也能够帮助儿童更好地理解和接受故事中所蕴含的道理和价值观。"
}
],
)
print(response)
# 流式调用 - 打字机式返回
response = client.chat.completions.create(
model="glm-4", # 填写需要调用的模型名称
messages=[
{"role": "system", "content": "你是一个乐于解答各种问题的助手。"},
{"role": "user", "content": "你好!你叫什么名字"},
],
stream=True,
)
for chunk in response:
print(chunk.choices[0].delta, end="")
- OpenAI SDK 调用
from openai import OpenAI
client = OpenAI(
api_key="your api key",
base_url="https://open.bigmodel.cn/api/paas/v4/"
)
completion = client.chat.completions.create(
model="glm-4",
messages=[
{"role": "system", "content": "你是一个聪明且富有创造力的小说作家"},
{"role": "user", "content": "请你作为童话故事大王,写一篇短篇童话故事,故事的主题是要永远保持一颗善良的心,要能够激发儿童的学习兴趣和想象力,同时也能够帮助儿童更好地理解和接受故事中所蕴含的道理和价值观。"}
],
top_p=0.7,
temperature=0.9
)
print(completion.choices[0].message)
6. Spark
基本信息:
API 文档:https://xinghuo.xfyun.cn/sparkapi
限制:
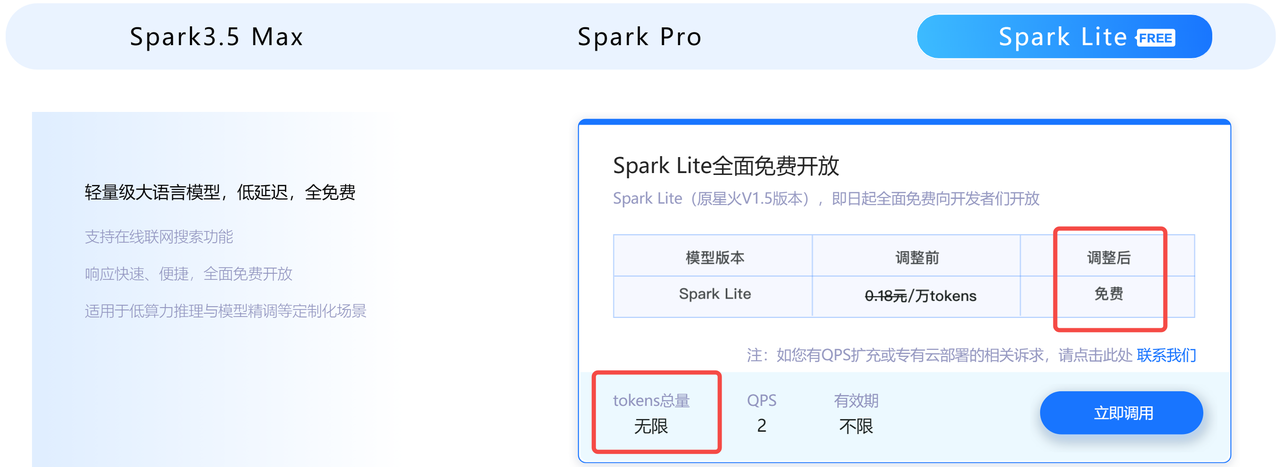
- Spark3.5 Max 和 Spark Pro, 分别有免费的 200万 token,有效期1年
- Spark Lite 完全免费
- 和 OpenAI API 不一样,必须使用OpenAI API 的场景可能无法使用,或者可以自己封装成 OpenAI API 。
使用步骤:
- 安装:
pip install --upgrade spark_ai_python
- 查看并保存自己的接口认证信息:https://console.xfyun.cn/services/cbm
- 调用测试:
参考:星火认知大模型Web API文档 | 讯飞开放平台文档中心
from sparkai.llm.llm import ChatSparkLLM, ChunkPrintHandler
from sparkai.core.messages import ChatMessage
# 注意 替换为自己的接口认证信息
SPARKAI_APP_ID = 'xxx'
SPARKAI_API_SECRET = 'xxx'
SPARKAI_API_KEY = 'xxx'
model = 'spark lite'
if model =='spark lite':
SPARKAI_URL = 'wss://spark-api.xf-yun.com/v1.1/chat'
SPARKAI_DOMAIN = 'general'
elif model =='spark pro':
SPARKAI_URL = 'wss://spark-api.xf-yun.com/v3.1/chat'
SPARKAI_DOMAIN = 'generalv3'
elif model =='spark max':
SPARKAI_URL = 'wss://spark-api.xf-yun.com/v3.5/chat'
SPARKAI_DOMAIN = 'generalv3.5'
spark = ChatSparkLLM(
spark_api_url=SPARKAI_URL,
spark_app_id=SPARKAI_APP_ID,
spark_api_key=SPARKAI_API_KEY,
spark_api_secret=SPARKAI_API_SECRET,
spark_llm_domain=SPARKAI_DOMAIN,
streaming=False,
)
if __name__ == '__main__':
messages = [
ChatMessage(role="user", content='你好呀'),
]
handler = ChunkPrintHandler()
a = spark.generate([messages], callbacks=[handler])
print(a.generations[0][0].text)
LLM API - All in One
考虑到大部分 API 都提供了兼容OpenAI API的形式,我们可以把所有服务封装成一个类,实现一套代码调用任意想用的模型,开箱即用👇
from openai import OpenAI
# 枚举所有可用的模型服务
model_dict = {
'gpt-3.5-turbo': {
'api_key': 'sk-CsUwFWsagU5IwyAcZhPBKs3ks1TcOlLUXgoBl9FoXB7wKW',
'base_url': 'https://api.chatanywhere.tech',
},
'gpt-4': {
'api_key': 'sk-CsUwFWsagU5IwyAcZhPBKs3ks1TcOlLUXgoBl9FoXaKwKW',
'base_url': 'https://api.chatanywhere.tech',
},
}
# 设置人设提示词,根据需要进行修改
prompt_dict = {
'gpt-3.5-turbo': [
{"role": "system", "content": "你是 gpt-3.5"},
],
'gpt-4': [
{"role": "system", "content": "你是 gpt-4"},
],
}
class LLM_API:
def __init__(self, api_key, base_url, model):
self.client = OpenAI(
api_key=api_key,
base_url=base_url,
)
self.model = model
def __call__(self, messages, temperature=0.7):
completion = self.client.chat.completions.create(
model=self.model,
messages=messages,
temperature=temperature,
)
return completion.choices[-1].message.content
if __name__ == '__main__':
model = 'gpt-3'
llm = LLM_API(model_dict[model]['api_key'], model_dict[model]['base_url'], model)
user_question = "你是谁"
messages = prompt_dict[model] + [{"role": "user", "content": user_question},]
print(llm(messages))
写在最后
看到这里,你已经手握 LLM 开发的生产资料,祝大家都能借助这些免费的 API 玩转大模型,开发出更多 AI 创意应用。
如果还有本文没有收集到的 API,欢迎评论区告诉我~
如果本文对你有帮助,欢迎点赞收藏备用!
猴哥一直在做 AI 领域的研发和探索,会陆续跟大家分享路上的思考和心得。
最近开始运营一个公众号,旨在分享关于AI效率工具、自媒体副业的一切。用心做内容,不辜负每一份关注。
新朋友欢迎关注 “猴哥的AI知识库” 公众号,下次更新不迷路。